python :jieba库的使用大全
安装
jieba 是一个第三方库,所有需要我们在本地进行安装。
Windows 下使用命令安装:在联网状态下,在anaconda命令行下输入 pip install jieba 进行安装,安装完成后会提示安装成功 .
分词使用
分词的语法就不讲解啦,什么前向匹配,逆向匹配,还需要一个足够大的本地词典。自己构造挺麻烦的。
直接使用包吧。
直接使用jieba.cut
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author: yudengwu(余登武)
# @Date : 2020/9/10
#@email:[email protected]
import jieba
sentence="《乘风破浪的姐姐》现在已经播出到了第2期节目,在初舞台之后,现在大家都对姐姐们的实力是有所了解的了。"
c=jieba.cut(sentence)
print(c)
d=[i for i in c]
print(d)
直接使用jieba.cut()返回的是一个对象。
我们更多需要用一个迭代器是结果显示出来。[i for i in c]

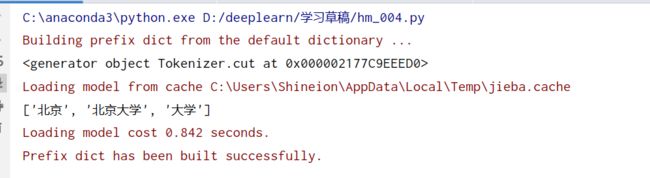
全模式分词
如输入北京大学
jieba.cut(sentence,cut_all=True)
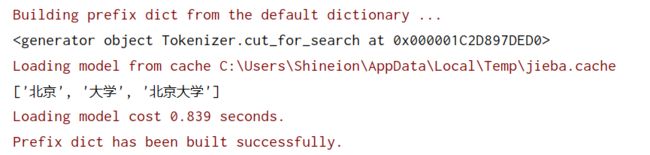
搜索引擎分词
c=jieba.cut_for_search(sentence)
使用jieba.lcut分词`
jieba.lcut()也可以使用全模式搜索,添加参数cut_all=True
import jieba
sentence="《乘风破浪的姐姐》现在已经播出到了第2期节目,在初舞台之后,现在大家都对姐姐们的实力是有所了解的了。"
c=jieba.lcut(sentence)
print(c)
分词结果是一个数组,非对象。

修改词典
在现实生活中,有时候我们希望一个词不被分开,可以修改jieba的词典。
add_word(word, freq=None, tag=None) 和 del_word(word) #动态修改
import jieba
jieba.add_word('乘风破浪的姐姐',freq = 20000, tag = None)
sentence="《乘风破浪的姐姐》现在已经播出到了第2期节目,在初舞台之后,现在大家都对姐姐们的实力是有所了解的了。"
c=jieba.lcut(sentence)
print(c)
我们将乘风破浪的姐姐固定为一个词语,就不会被分开啦。
往jieba里添加自定义词是临时的,不会存在下一个事务中。

统计词频
import jieba
sentence="《乘风破浪的姐姐》现在已经播出到了第2期节目,在初舞台之后,现在大家都对姐姐们的实力是有所了解的了。"
words = jieba.lcut(sentence) # 使用精确模式对文本进行分词
counts = {} # 通过键值对的形式存储词语及其出现的次数
for word in words:
if len(word) == 1: # 单个词语不计算在内
continue
else:
counts[word] = counts.get(word, 0) + 1 # 遍历所有词语,每出现一次其对应的值加 1
items = list(counts.items())
print(items)
items.sort(key=lambda x: x[1], reverse=True) # 根据词语出现的次数进行从大到小排序
for i in range(3):
word, count = items[i]
print("{0}:{1}".format(word, count))

使用CountVectorizer统计词频
import jieba
sentence="《乘风破浪的姐姐》现在已经播出到了第2期节目,在初舞台之后,现在大家都对姐姐们的实力是有所了解的了。"
words = jieba.lcut(sentence) # 使用精确模式对文本进行分词
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()#创建词袋数据结构
cv_fit=cv.fit_transform(words)
#上述代码等价于下面两行
#cv.fit(texts)
#cv_fit=cv.transform(texts)
print(cv.get_feature_names()) #列表形式呈现文章生成的词典
#['之后', '乘风破浪', '了解', '大家', '姐姐', '实力', '已经', '播出', '有所', '现在', '舞台', '节目']
print(cv.vocabulary_ )#{词:词频}
#{'乘风破浪': 1, '姐姐': 4, '现在': 9, '已经': 6, '播出': 7, '节目': 11, '舞台': 10, '之后': 0, '大家': 3, '实力': 5, '有所': 8, '了解': 2}
词性标注
jieba分词的词性标注过程非常类似于jieba分词的分词流程,同时进行分词和词性标注。
在词性标注的时候,首先基于正则表达式(汉字)进行判断,1)如果是汉字,则会基于前缀词典构建有向无环图,然后基于有向图计算最大概率路径,同时在前缀词典中查找所分出的词的词性,如果没有找到,则将其词性标注为“x”(非语素字 非语素字只是一个符号,字母x通常用于代表未知数、符号);如果HMM标志位置位,并且该词为未登录词,则通过隐马尔科夫模型对其进行词性标注;2)如果是其它,则根据正则表达式判断其类型,分别赋予“x”,“m”(数词 取英语numeral的第3个字母,n,u已有他用),“eng”(英文)。流程图如下所示。
大白话讲解就是:先根据分词结果查找词典词性,给大多数词打上词性,未打上词性的单词再根据HMM模型打上词性。
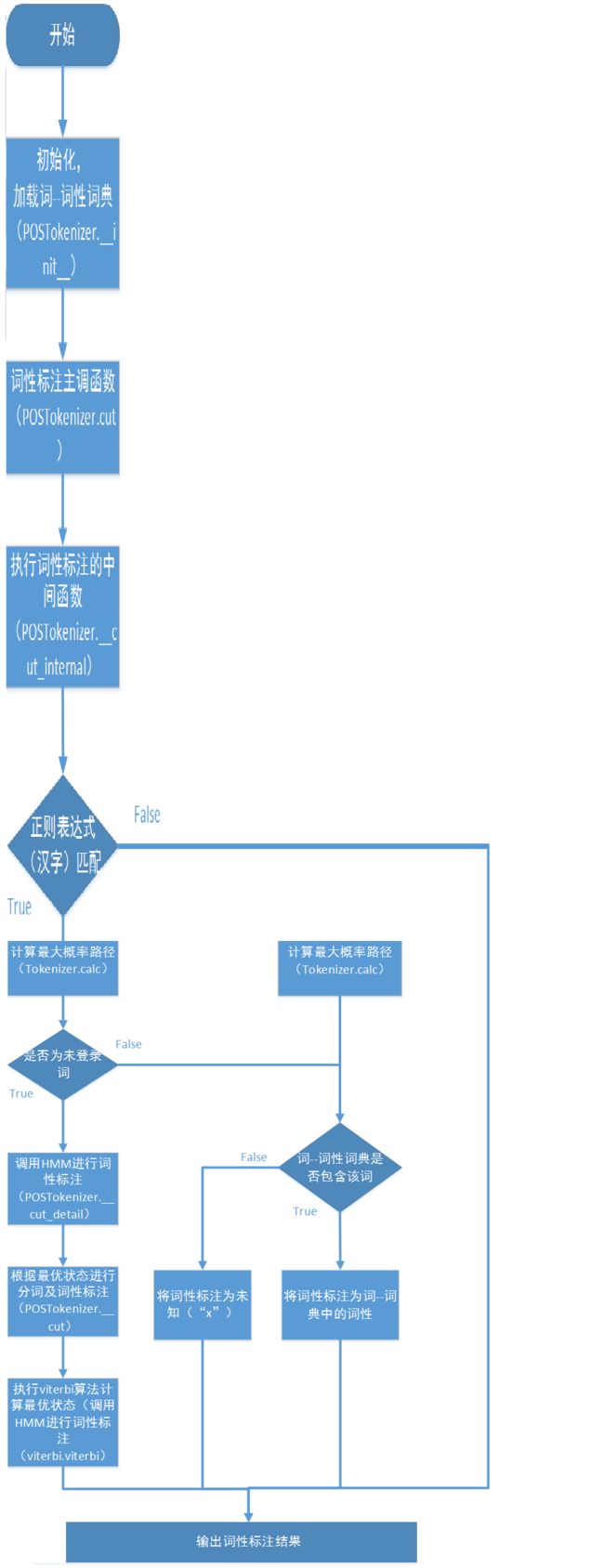
jieba词性表,概括了绝大部分
| 英文简写 | 中文 | 例子 |
|---|---|---|
| a | 形容词 | 很贵 挺好用 |
| ad | 副形词 | 努目 完全 |
| ag | 形语素 | 详 笃 睦 |
| an | 名形词 | 困苦 危难 |
| b | 区别词 | 超常规 同一性 |
| c | 连词 | 以外 换句话 |
| d | 副词 | 幸免 四顾 绝对 |
| dg | 副语素 | 俱 辄 |
| e | 叹词 | 好哟 嗄 |
| f | 方位词 | 内侧 以来 |
| h | 前接成分 | 非 超低 |
| i | 成语 | |
| j | 简称略语 | 交警 中低收入 四个现代 |
| k | 后接成分 | 型 者 式 们 |
| l | 习用语 | 由下而上 十字路口 |
| m | 数词 | 九六 十二 |
| mg | 数语素 | 寅 巳 |
| mq | 数量词 | 半年度 四方面 |
| n | 名词 | 气压 写实性 |
| ng | 名语素 | 诀 卉 茗 鹊 娃 寨 酊 钬 |
| nr | 人名 | |
| nrfg | 古近代人名 | 张飞 赵云 任弼时 |
| nrt | 音译人名 | 米尔科 达尼丁 |
| ns | 地名 | |
| nt | 机构团体 | 浙江队 中医院 中华网 铁道部 |
| nz | 其他专名 | 培根 补丁 圣战士 英属 国药准字 |
| o | 拟声词 | 哈喇 咝 哗喇 咔喳 飕 哇哇 |
| p | 介词 | 顺当 顺着 借了 连着 |
| q | 量词 | 毫厘 盅 封 千瓦小时 |
| r | 代词 | 该车 这时 那些 |
| rg | 代语素 | 兹 |
| t | 时间词 | 新一代 清时 先上去 月初 昔年 无日 |
| tg | 时间语素 | 昔 晚 春 现 暮 夕 宵 |
| u | 助词 | 则否 等 恁地 等等 似的 来说 矣哉 来看 般 的话 |
| v | 动词 | |
| vd | 副动词 | |
| y | 语气词 | |
| z | 状态词 |
如何查看jieba的所有词性,见代码
import jieba, pandas as pd, os
jieba_dict = os.path.dirname(jieba.__file__) + '/dict.txt'
df_jieba = pd.read_table(jieba_dict, sep=' ', header=None)[[2, 0]]
dt = {k: set() for k in df_jieba[2].values}
for f, w in df_jieba.values:dt[f].add(w)
ls_of_ls = [(f, len(w), ' '.join(list(w)[:50])) for f, w in dt.items()]
pd.DataFrame(ls_of_ls, columns=['词性', '数量', '例子.']).sort_values('词性').to_csv('flag.csv', index=None)
生成的表格

词性我们一般关注 时间,地名,机构名。用于做命名实体识别。
命名实体识别:一般是词性标注加正则。
我是一个学电气的,我怎么懂得这些人工智能方面的知识。
词性标注
import jieba.posseg as pseg
words =pseg.cut("我爱北京天安门,我希望我以后的儿子能去清华大学读书")
for w in words:
print(w.word,w.flag)

词性标注 如果我们只想获得机构名
import jieba.posseg as pseg
words =pseg.cut("我爱北京天安门,我希望我以后的儿子能去清华大学读书")
c=[w.word for w in words if w.flag=='nt']
print(c)

![]()
电气工程的计算机萌新:余登武。写博文不容易。如果你觉得本文对你有用,请点个赞支持下,谢谢。
![]()