inferno Pytorch: inferno.io.box.cifar下载cifar10 cifar100数据集 介绍及使用
inferno.io.box.cifar介绍及使用
- inferno简介
- inferno安装
- inferno.io.box.cifar
-
- 源码
- 使用示例(可以直接运行)
inferno简介
Inferno是一个库,提供了围绕PyTorch的实用程序和方便的函数/类,为深度学习和实现神经网络提供便利。关于inferno的其他模块介绍:
inferno Pytorch: inferno.extensions.layers.convolutional 介绍及使用
inferno Pytorch: inferno.io.box.cifar下载cifar10 cifar100数据集 介绍及使用
inferno Pytorch: inferno.io.transform 介绍及使用
inferno安装
pip install inferno-pytorch
inferno.io.box.cifar
inferno.io.box.cifar包含两个函数,分别用于下载cifar10和cifar100数据集(cifar数据集简单介绍),只需要一行代码即可下载。
源码
函数入口如下:
def get_cifar10_loaders(root_directory, train_batch_size=128, test_batch_size=256,
download=False, augment=False, validation_dataset_size=None):
def get_cifar100_loaders(root_directory, train_batch_size=128, test_batch_size=100,
download=False, augment=False, validation_dataset_size=None):
返回的是一个DataLoader.
具体源码:
import os
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data.sampler import SubsetRandomSampler
def get_cifar10_loaders(root_directory, train_batch_size=128, test_batch_size=256,
download=False, augment=False, validation_dataset_size=None):
# Data preparation for CIFAR10.
if augment:
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=(0.4914, 0.4822, 0.4465), std=(0.247, 0.2435, 0.2616)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.4914, 0.4822, 0.4465), std=(0.247, 0.2435, 0.2616)),
])
else:
transform_train = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.4914, 0.4822, 0.4465), std=(0.247, 0.2435, 0.2616)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.4914, 0.4822, 0.4465), std=(0.247, 0.2435, 0.2616)),
])
trainset = torchvision.datasets.CIFAR10(root=os.path.join(root_directory, 'data'),
train=True, download=download,
transform=transform_train)
if validation_dataset_size:
indices = torch.randperm(len(trainset))
train_indices = indices[:(len(indices) - validation_dataset_size)]
valid_indices = indices[(len(indices) - validation_dataset_size):]
validset = torchvision.datasets.CIFAR10(root=os.path.join(root_directory, 'data'),
train=True, download=download,
transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=train_batch_size,
pin_memory=True, num_workers=1,
sampler=SubsetRandomSampler(train_indices))
validloader = torch.utils.data.DataLoader(validset, batch_size=test_batch_size,
pin_memory=True, num_workers=1,
sampler=SubsetRandomSampler(valid_indices))
else:
trainloader = torch.utils.data.DataLoader(trainset, batch_size=train_batch_size,
shuffle=True, pin_memory=True, num_workers=1)
testset = torchvision.datasets.CIFAR10(root=os.path.join(root_directory, 'data'),
train=False, download=download,
transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=test_batch_size,
shuffle=False, pin_memory=True, num_workers=1)
if validation_dataset_size:
return trainloader, validloader, testloader
else:
return trainloader, testloader
def get_cifar100_loaders(root_directory, train_batch_size=128, test_batch_size=100,
download=False, augment=False, validation_dataset_size=None):
# Data preparation for CIFAR100. Adapted from
# https://github.com/kuangliu/pytorch-cifar/blob/master/main.py
if augment:
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5071, 0.4865, 0.4409), std=(0.2673, 0.2564, 0.2762)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5071, 0.4865, 0.4409), std=(0.2673, 0.2564, 0.2762)),
])
else:
transform_train = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5071, 0.4865, 0.4409), std=(0.2673, 0.2564, 0.2762)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5071, 0.4865, 0.4409), std=(0.2673, 0.2564, 0.2762)),
])
trainset = torchvision.datasets.CIFAR100(root=os.path.join(root_directory, 'data'),
train=True, download=download,
transform=transform_train)
if validation_dataset_size:
indices = torch.randperm(len(trainset))
train_indices = indices[:(len(indices) - validation_dataset_size)]
valid_indices = indices[(len(indices) - validation_dataset_size):]
validset = torchvision.datasets.CIFAR100(root=os.path.join(root_directory, 'data'),
train=True, download=download,
transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=train_batch_size,
pin_memory=True, num_workers=1,
sampler=SubsetRandomSampler(train_indices))
validloader = torch.utils.data.DataLoader(validset, batch_size=test_batch_size,
pin_memory=True, num_workers=1,
sampler=SubsetRandomSampler(valid_indices))
else:
trainloader = torch.utils.data.DataLoader(trainset, batch_size=train_batch_size,
shuffle=True, pin_memory=True, num_workers=1)
testset = torchvision.datasets.CIFAR100(root=os.path.join(root_directory, 'data'),
train=False, download=download,
transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=test_batch_size,
shuffle=False, pin_memory=True, num_workers=1)
if validation_dataset_size:
return trainloader, validloader, testloader
else:
return trainloader, testloader
使用示例(可以直接运行)
初次运行设置download=True
from inferno.io.box.cifar import get_cifar10_loaders
dataLoader = get_cifar10_loaders("./", train_batch_size=64, test_batch_size=64, download=True, augment=False, validation_dataset_size=None)
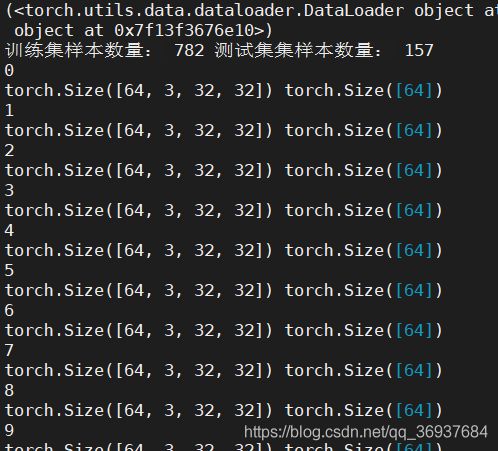
print(dataLoader)
train, test = dataLoader
print("训练集样本数量:",len(train),"测试集集样本数量:",len(test))
for k,v in enumerate(test):
print(k)
data, label = v
print(data.shape, label.shape)
结果: