语义分割常用网络
目录
0. 前言
1. FCN(2015)
2. Unet
2.1 原论文里的网络
2.2 后面改进的网络
3. DeepLab系列网络
3.1 DeeplabV1(2015年)
3.2 DeeplabV2(2016年)
3.3 DeeplabV3(2017年)
3.3 DeeplabV3+(2018年)
4. PSPnet(2017年)
5.Segnet(2015)
0. 前言
整理不是非常全面,仅整理了比较经典的一些网络。摆烂式学习。

1. FCN(2015)
地位:首个端到端的针对像素级预测的全卷积网络
参考:FCN网络解析_无码不欢的我的博客-CSDN博客_fcn
对于一般的分类CNN网络,如VGG和Resnet,网络的最后都会加入一些全连接层,经过softmax后就可以获得类别概率信息。但是这个概率信息是1维的,即只能标识整个图片的类别,不能标识每个像素点的类别,所以这种全连接方法不适用于图像分割
 图1 VGG16分类网络图
图1 VGG16分类网络图
FCN对图像进行像素级的分类,与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN提出可以把后面几个全连接都换成卷积(这样就可以接受任意尺寸的输入图像),这样就可以获得一张2维的feature map,然后采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上使用softmax进行逐像素分类。相对来说,FCN还是比较简单的,但胜在有效,原论文的Backbone用的是VGG16,Pytorch里面用的是resnet50.

图2 FCN网络结构图(32s)
若是直接上采样32倍至原图大小,效果不是很理想,我的理解是直接上采32倍,损失太多细节了,因此,还有上采样16倍和上采样8倍的,此时将上采样的结果和下采样时对应的特征层融合(如图1中的Maxpooling3 和Maxpooling4)

图2 FCN网络结构图(8s)
2. Unet
2.1 原论文里的网络
Unet可以分为两块:
① 特征提取:不断的卷积池化堆叠起来;
② 上采样及特征融合:上采样是通过转置卷积完成,特征融合是融合下采样过程中对应层级的特征(融合方法与FCN不同,这里是通过channel维度拼接在一起,形成更厚的特征)。
 图3 原论文Unet网络结构图
图3 原论文Unet网络结构图
2.2 后面改进的网络
① 原论文中没有padding,每次卷积之后宽和高都发生了变化,后面大家广泛使用的时候都使用了padding,保证每次卷积之后宽高不变;
② 利用双线性内插替代转置卷积进行上采(这个完全是个人喜好)
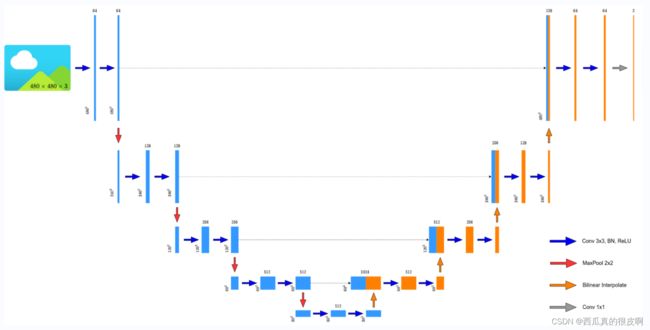
图4 改进后的Unet网络结构图
3. DeepLab系列网络
3.1 DeeplabV1(2015年)
论文名称:Semantic Image Segmentation with Deep Convolution Nets and Fully connected CRFs
(1)在这篇论文中,作者指出语义分割的两个问题:
① 下采样导致的图像分辨率降低
② 空间不敏感(例如通过简单的数据平移就可能导致分类结果不一致)
(2)解决方法
① 空洞卷积 ② fully-connected CRF
(3)网络优势
① 速度快(论文解释是采用膨胀卷积的原因,但fully-connected CRF 很耗时间)
② 准确率高
③ 模型简单,主要由DCNNs和CRF连级构成

图5 DeepLabV1网络结构图
3.2 DeeplabV2(2016年)
论文名称:DeepLab:Semantic Image Segmentation with Deep Convolution Nets, Atrous
Convolution, and Fully connected CRFs
V2是在V1的基础上进行改进。
- 在这篇论文中,作者指出语义分割的问题:
① 下采样导致的图像分辨率降低
② 目标的多尺度问题
③ DCNNs的不变性会降低定位精度
- 解决方法
① 针对上述问题①,一般将最后几个MaxPooling层的Stride=1,配合使用空洞卷积
②针对目标多尺度问题,提出了ASPP结构
② fully-connected pairwise CRF
- 网络优势
① 速度快 ② 准确率更高 ③ 模型简单,主要由DCNNs和CRF连级构成
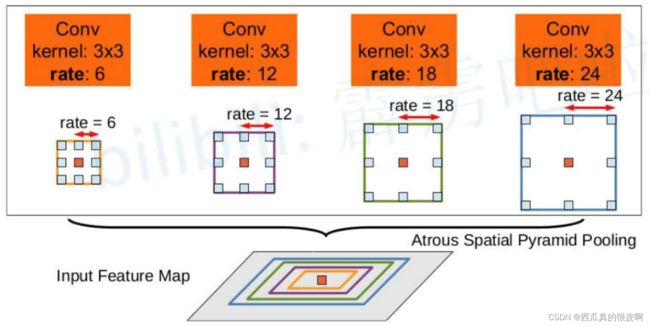
图6 DeepLabV2网络的ASPP模块 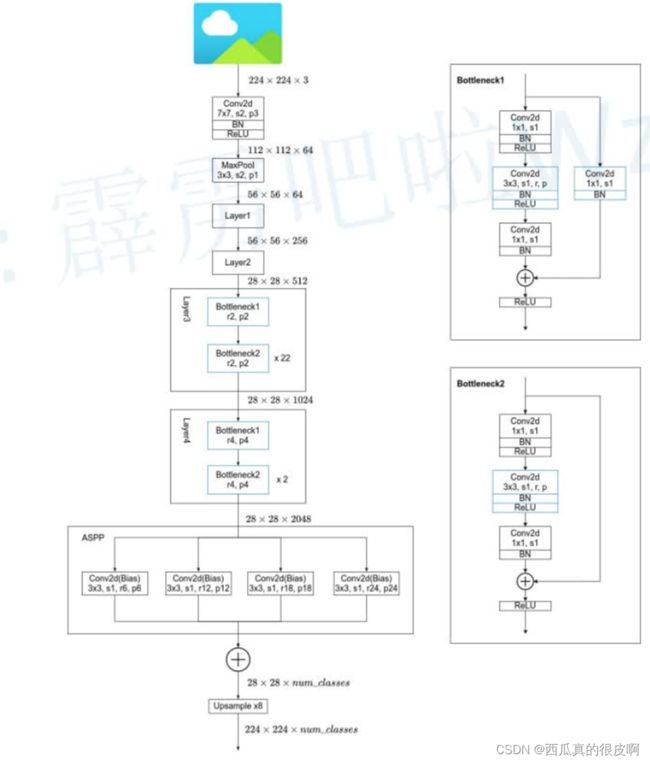
图7 DeepLabV2网络结构图
3.3 DeeplabV3(2017年)
原论文:Rethinking Atrous Convolution for Semantic Image Segmentation
- 改进
① 引入了Multi-grid
② 改进了ASPP结构
③ 移除CRFs后处理
- 关于Multi-grid(下图展示了最常用的多级金字塔方法)
 图7 多尺度
图7 多尺度
在DeepLabV3的原论文中,一共有两种模型,第一个是联级模型,第二个是我们常用的模型。在原论文的图中,有个小错误,就是下面那个4和8,因为DeepLabV3用的是Resnet作为backbone,在Resnet网络中,到conv_3之后对应下来其实是下图中block2之后才开始下采样。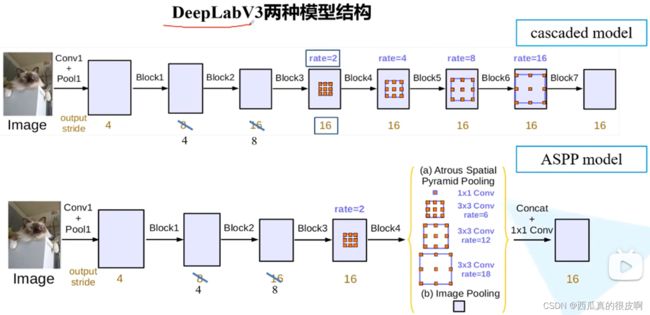
图8 DeepLabV3模型
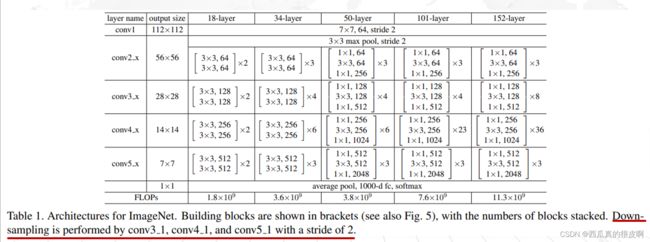 图9 Resnet网络结构
图9 Resnet网络结构
还有就是V3改进了ASPP模块,从下面对比图可以看出,V2中的ASPP模块真的非常简单了:
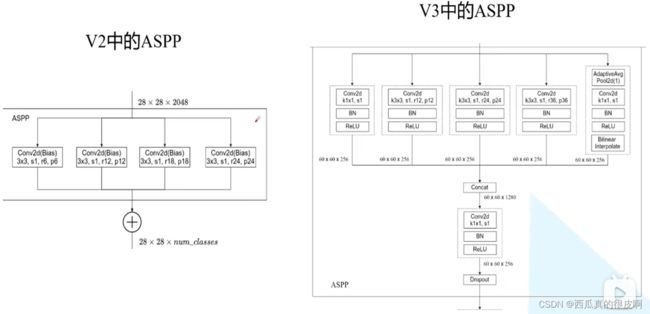 图10 V3的ASPP模块
图10 V3的ASPP模块
3.3 DeeplabV3+(2018年)
原论文:Encoder-Decoder with Separable Convolution for Semantic Image Segmentation
地位:DeepLabV3+被认为是语义分割的新高峰
DeeplabV3+将整个DeeplabV3模块作为它的backbone,并将其中的backbone替换为Xception,采用了encoder-decoder结构。简单易理解还好用!!!有兴趣的看原论文。
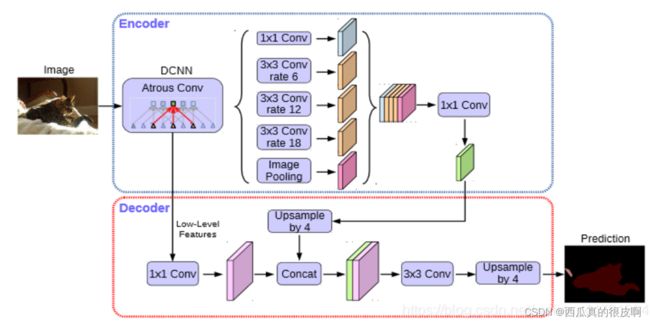 图11 V3+的网络结构图
图11 V3+的网络结构图
4. PSPnet(2017年)
原论文:Pyramid Scene Parsing Network
- 语义分割难点
① 语境关系不匹配:如“车”在河上
② 相近类别容易混淆:“墙”与“房子”
③ 不明显的类别:非常大或者非常小物体的识别能力,非常大物体可能超过神经网络感受野,而非常小的物体难以找到
【注】许多错误都与不同感受野获取的全局信息和语境关系有着部分甚至是完全的关联,因此,一个拥有适当场景级全局信息的深度网络可以大大提高场景解析的能力。
上述的错误分割可以体现在下图之中:
图12 语义分割中常见的错误
本文作者的做法:
- 引入更多上下文信息的方式
① 增大分割层感受野
1)空洞卷积:在deeplab上应用成功
2)全局平均池化:PSPnet
② 深层特征和浅层特征融合
- 该网络最大的特点是采用了PSP模块
该模型提出的金字塔池化模块(Pyramid Pooling Module)能够聚合不同区域的上下文信息,从而提高获取全局信息的能力。实验表明这样的先验表示(即指代PSP这个结构)是有效的,在多个数据集上展现了优良的效果。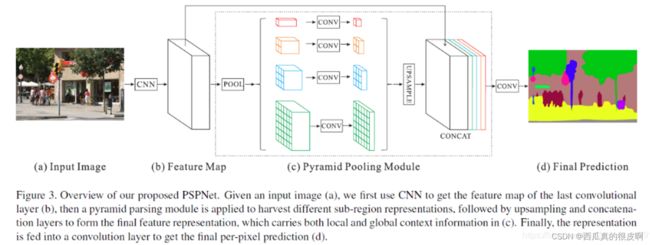
图13 PSPnet网络结构图
PSP结构典型情况下,会将输入进来的特征层划分成6x6,3x3,2x2,1x1的网格
红色(1x1):将输入进来的特征层整个进行平均池化。
橙色(2x2):将输入进来的特征层划分为2×2个子区域,然后对每个子区域进行平均池化。
蓝色(3x3):将输入进来的特征层划分为3×3个子区域,然后对每个子区域进行平均池化。
绿色(6x6):将输入进来的特征层划分为6×6个子区域,然后对每个子区域进行平均池化。
5.Segnet(2015)
原论文:Segnet:A Deep Convolution Encoder-Decoder Architecture for Image Segmentation
别人写的很详细,可以参考:【语义分割】--SegNet理解_灬Alex灬的博客-CSDN博客_segnet
(1)Segnet思路和FCN非常相似,Encoder和Decoder使用技术不一样。
(2)Encoder部分
① 选用VGG16的前13层卷积网络
② 在pooling层多了一个index功能(记录最大值的位置)
(3)Decoder部分
Upsampling是pooling的逆过程(前面记录的index在这里发挥作用),对比FCN,Segnet在上采样过程,根据记录的index直接将值放回到对应位置,其他位置填充为0,这个上采样过程不需要训练学习。

图13 Segnet网络结构图