python pandas库统计分析基础必备知识汇总
文章目录
-
1.Series
-
- 1.1创建一个Series
-
1.2创建Series并设置索引
-
1.3索引
-
- 1.3.1一个标签索引
-
1.3.2多个标签索引
-
1.3.3一个位置索引
-
1.3.4多个位置索引
-
1.4切片
-
- 1.4.1标签切片
-
1.4.2位置切片
-
1.5Series的index和values属性
-
2.DataFrame
-
- 2.1创建一个DataFrame对象
-
- 2.1.1不指定index和columns
-
2.1.2指定index和columns
-
2.1.3使用字典创建DataFrame
-
2.2遍历DataFrame对象数据的每一列
-
2.3索引与切片
-
- 2.3.1 loc标签索引
-
- 2.3.1.1获取单行数据
-
2.3.1.2获取多行数据
-
2.3.1.3切片连续多行数据
-
2.3.2iloc位置索引
-
- 2.3.2.1获取某行数据
-
2.3.2.2获取多行数据
-
2.3.2.3切片连续多行数据(左闭右开)
-
2.3.3直接获取指定列数据
-
- 2.3.3.1获取单列
-
2.3.3.2获取多列
-
2.3.4获取指定行、列数据
-
- 2.3.4.1 loc标签索引
-
2.3.4.2 iloc位置索引
-
2.3.5 按指定条件获取(布尔索引)
-
2.4 增加数据
-
- 2.4.1 按列增加数据
-
- 2.4.1.1 直接添加
-
使用insert()方法添加
-
2.4.2 按行增加数据
-
- 2.4.2.1 增加一行
-
2.4.2.2 增加多行数据
-
2.5 修改列名&索引
-
- 2.5.1修改列名
-
2.5.1.1 通过DataFrame的columns属性
-
- 2.5.1.2 通过DataFrame的rename()方法
-
2.5.2 修改索引(index)
-
- 2.5.2.1 通过index属性
-
2.5.2.2通过rename方法
-
2.6 修改数据
-
-
- 2.6.1 使用loc
-
-
- 修改整行数据
-
修改整列数据
-
修改指定某一数据
-
2.6.2 使用iloc
-
- 修改整行数据
-
修改整列数据
-
修改指定某一数据
-
2.7 删除数据
-
- 2.7.1 删除某列
-
2.7.2 删除某行
-
2.7.3删除特定条件的行
-
2.8 打印DataFrame的简短摘要
-
2.9 处理缺失值与重复值
-
- 2.9.1处理缺失值
-
- 2.9.1.1 准备缺失值
-
2.9.1.2 删除该缺失值所在行
-
2.9.1.3获取某字段没有缺失值 的行
-
2.9.1.4 填充缺失值
-
- 2.9.1.4.1 填充所有缺失值
-
2.9.1.4.2 填充局部缺失值
-
2.9.2 处理重复值
-
- 2.9.2.1准备数据
-
2.9.2.2 判断重复值
-
- 2.9.2.2.1 判断整行数据是否重复
-
2.9.2.2.2 判断某字段数据是否重复
-
2.9.2.3 去重
-
- 2.9.2.3.1 删除整行重复值
-
2.9.2.3.2 删除某字段重复 的行
-
2.10设置索引
-
- 2.10.1 reindex
-
- 缺失值以0填充
-
缺失值向前/向后填充
-
重新设置行索引、列索引和行列索引
-
2.10.2 set_index
-
- 2.10.2.1 设置某列为index
-
2.10.2.2 设置drop=True
-
2.11排序
-
- 2.11.1 sort_values()单列排序
-
2.11.2 sort_values()多列排序
-
2.11.3 group_by()对统计结果排序
-
2.11.4横向排序 axis=1
-
2.11.5 排名 rank()
-
3.pandas读取文件
-
- 3.1read_excel()
-
- 3.1.1准备数据
-
3.1.2默认方式读取
-
3.1.3设置index_col参数
-
3.1.4设置header参数
-
3.1.5设置usecols参数
-
3.1.6设置sheet_name参数以指定工作簿
-
3.1.7解决数据输出时列名不对齐的问题
-
3.2read_csv()
-
- 3.2.1设置encoding参数
-
3.2.2设置sep参数指定分隔符
-
3.3read_html()小案例
-
- 3.3.1pd.read_html()方法
-
3.3.2DataFrame的append()方法
-
3.3.3pd.to_csv()方法
1.Series
==============================================================================
1.1创建一个Series
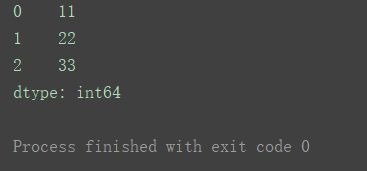
s1 = pd.Series([11, 22, 33])
print(s1)
索引默认为0,1,2
1.2创建Series并设置索引
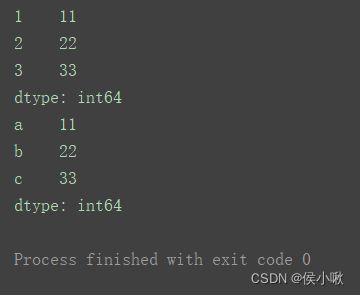
s2 = pd.Series([11, 22, 33], index=[1, 2, 3])
s3 = pd.Series([11, 22, 33], index=[‘a’, ‘b’, ‘c’])
print(s2)
print(s3)
1.3索引
索引方式默认优先标签索引,如果标签不存在,则尝试位置索引。
如果位置也不存在(out of bounds),则报错IndexError。
1.3.1一个标签索引
print(s2[1])

1.3.2多个标签索引
print(s2[[‘a’, ‘b’]])

1.3.3一个位置索引
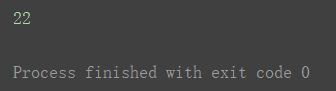
print(s3[1])
1.3.4多个位置索引
print(s3[[0, 2]])

1.4切片
1.4.1标签切片
切片方式为左闭右闭([,]),即两个边界值都可取。
print(s3[‘a’: ‘c’])

1.4.2位置切片
同样优先视为标签,如果标签不存在则视为位置。当Series索引默认为0,1,2…时不用考虑该区分。
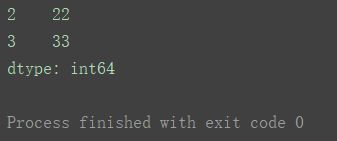
s4 = pd.Series([70, 82, 69, 90, 64])
位置索引做切片
print(s4[1:4])
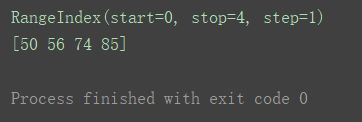
1.5Series的index和values属性
Series对象有index和value属性,可直接调用进行查看。
import pandas as pd
s1 = pd.Series([50, 56, 74, 85])
print(s1.index)
print(s1.values)
2.DataFrame
=================================================================================
2.1创建一个DataFrame对象
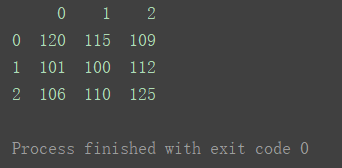
2.1.1不指定index和columns
当不指定index和columns时,默认为0, 1, 2。
import pandas as pd
data = [[120, 115, 109], [101, 100, 112], [106, 110, 125]]
df = pd.DataFrame(data=data)
print(df)
2.1.2指定index和columns
import pandas as pd
data = [[120, 115, 109], [101, 100, 112], [106, 110, 125]]
index = [0, 1, 2]
columns = [‘AAA’, ‘BBB’, ‘CCC’]
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)

2.1.3使用字典创建DataFrame
键为列名,值为该列数据组成的列表。值也可以是单个元素,表示该列都取该值。
import pandas as pd
df = pd.DataFrame({
‘AAA’: [120, 101, 106],
‘BBB’: [115, 100, 110],
‘CCC’: [109, 112, 125],
‘DDD’: ‘ABCDEFG’
}, index=[0, 1, 2])
print(df)

2.2遍历DataFrame对象数据的每一列
for col in df.columns:
series = df[col]
print(series)

2.3索引与切片
2.3.1 loc标签索引
2.3.1.1获取单行数据
import pandas as pd
df = pd.DataFrame({
‘AAA’: [120, 101, 106, 117, 114, 122],
‘BBB’: [115, 100, 110, 125, 123, 120],
‘CCC’: [109, 112, 125, 120, 116, 115],
‘DDD’: ‘ABCDEFG’
}, index=[1, 2, 3, 4, 5, 6])
print(df)
print("=======================")
print(df.loc[1])
df.loc[1]获取到标签索引为1的数据,在这里即第一行的。

2.3.1.2获取多行数据
print(df)
print("=======================")
print(df.loc[[1, 3]])
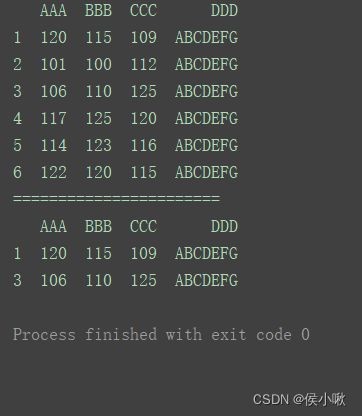
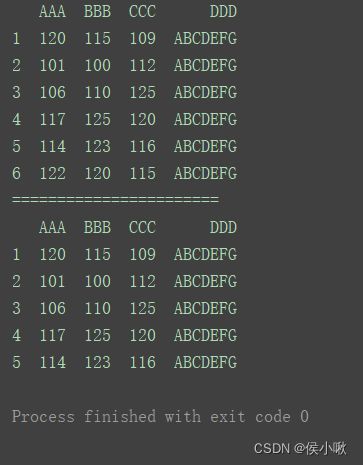
2.3.1.3切片连续多行数据
标签索引切片时左右边界的值都可以取。
print(df)
print("=======================")
print(df.loc[1:5])
2.3.2iloc位置索引
2.3.2.1获取某行数据
import pandas as pd
df = pd.DataFrame({
‘AAA’: [120, 101, 106, 117, 114, 122],
‘BBB’: [115, 100, 110, 125, 123, 120],
‘CCC’: [109, 112, 125, 120, 116, 115],
‘DDD’: ‘ABCDEFG’
}, index=[1, 2, 3, 4, 5, 6])
print(df)
print("=======================")
print(df.iloc[1])
df.iloc[1]获取到第二行(下标为1)数据

2.3.2.2获取多行数据
print(df)
print("=======================")
print(df.iloc[[0, 2]])

2.3.2.3切片连续多行数据(左闭右开)
遵照左闭右开
print(df)
print("=======================")
print(df.iloc[1: 4])
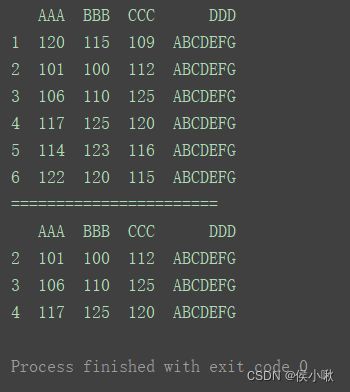
某行(第二行)至最后一行
print(df)
print("=======================")
print(df.iloc[1:])

(或df.iloc[1::]写法也可)
2.3.3直接获取指定列数据
- 直接传入列名即可获取
2.3.3.1获取单列
获取单列有两种写法如下,结果有所不同
print(df)
print("=======================")
print(df[‘AAA’])
print(type(df[‘AAA’]))

print(df)
print("=======================")
print(df[[‘AAA’]])
print(type(df[[‘AAA’]]))
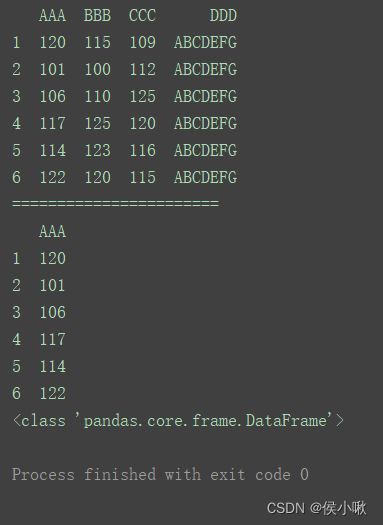
根据程序运行结果,df[‘AAA’]得到的是一个Series,而df[[‘AAA’]]得到的结果是一个DataFrame。
2.3.3.2获取多列
print(df)
print("=======================")
print(df[[‘AAA’, ‘CCC’]])

2.3.4获取指定行、列数据
通过以下几个示例,来熟悉loc和iloc同时指定行和列时的用法。
对于loc和iloc,只有标签和位置索引的区别。同时指定行和列时,如果某个维度(行或列)的索引为离散的单个或多个元素,则需要额外加上方括号(loc[[2,4],[‘a’,‘c’]] 或 iloc[[5,8],[2,6]]);如果是切片形式的(形如a:b, a,b也可省略),则不需要额外的方括号(loc[2:4,‘a’:‘c’] 或 iloc[5:8,2:6])。
2.3.4.1 loc标签索引
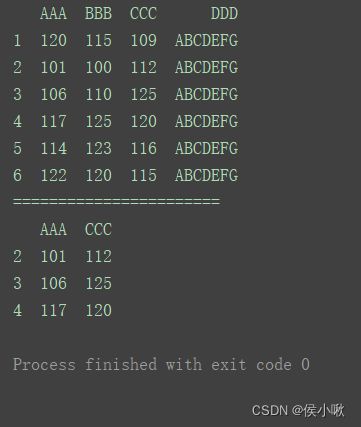
获取索引为2的行到索引为4的行(两端都取),与列名为"AAA"的列和列名为"CCC"的列交叉的部分
print(df)
print("=======================")
print(df.loc[2:4, [‘AAA’, ‘CCC’]])
获取所有行中,列明为"AAA"和列明为“CCC”的部分
print(df)
print("=======================")
print(df.loc[:, [‘AAA’, ‘CCC’]])

获取所有行中,列名“BBB”及其后边的列的部分
print(df)
print("=======================")
print(df.loc[:, ‘BBB’:])
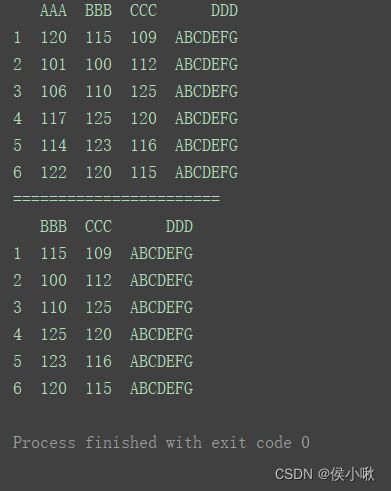
print(df)
print("=======================")
print(df.loc[[1, 3], [‘BBB’, ‘DDD’]])

2.3.4.2 iloc位置索引
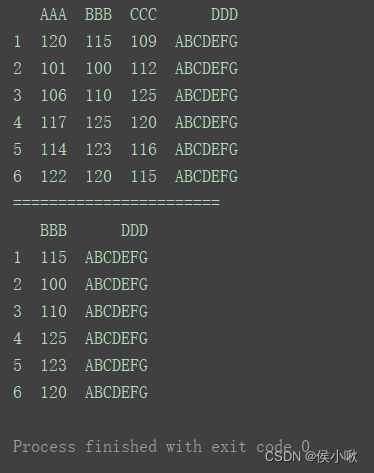
print(df)
print("=======================")
print(df.iloc[:, [1, 3]])
print(df)
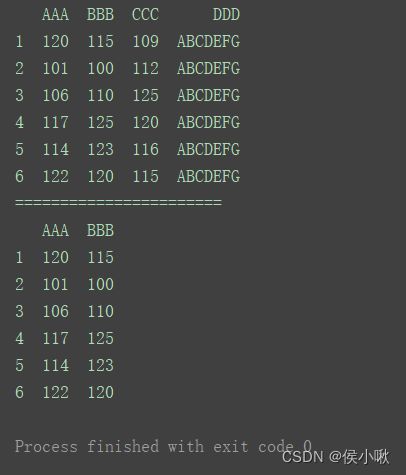
print("=======================")
print(df.iloc[:, :2])
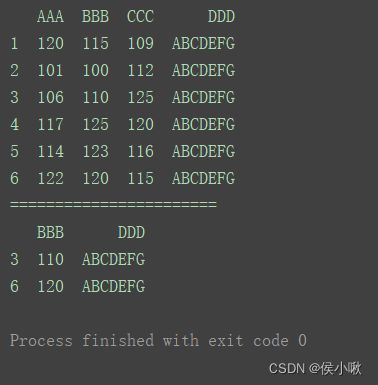
print(df)
print("=======================")
print(df.iloc[[2, 5], [1, 3]])
2.3.5 按指定条件获取(布尔索引)
使用loc还可以进行指定条件的筛选获取
执行以下代码
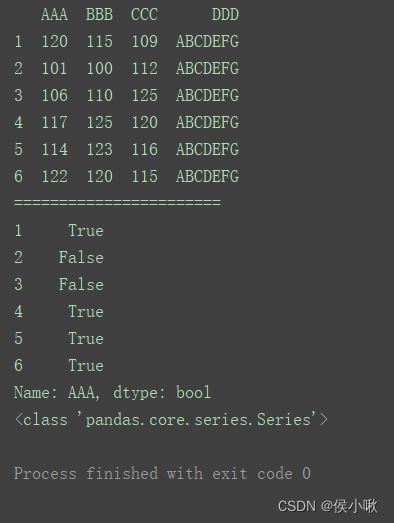
print(df)
print("=======================")
print(df[‘AAA’] > 110)
print(type(df[‘AAA’] > 110))
如图,输出了一个value为bool类型数据的Series对象。
可以使用该种形式的Series对DataFrame进行筛选
print(df)
print("=======================")
print(df.loc[df[‘AAA’] > 110])

也可以传入多个条件进行筛选。每个条件需要使用括号()括起来。
以获取’AAA’大于110且’CCC’大于115的为例:
print(df)
print("=======================")
print(df.loc[(df[‘AAA’] > 110) & (df[‘CCC’] > 115)])

2.4 增加数据
2.4.1 按列增加数据
2.4.1.1 直接添加
print(df)
print("=======================")
df[‘EEE’] = [140, 133, 145, 125, 126, 133]
print(df)

也可以使用loc添加
添加一整列时行索引必须是所有行,列索引是一个新的列名。添加的数据个数必须等于总行数。插入的数据在最后一列。
print(df)
print("=======================")
df.loc[:, ‘FFF’] = [84, 99, 76, 50, 20, 66]
print(df)
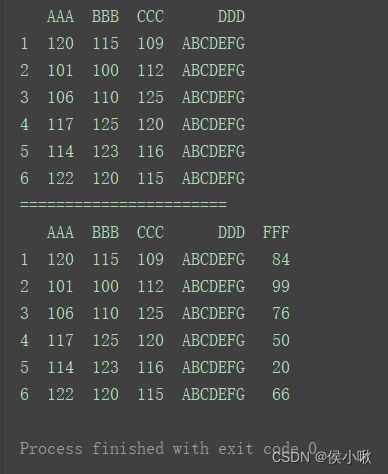
如果行索引是部分行,且列索引已存在于原数据中,则效果为修改局部数据。
print(df)
print("=======================")
df.loc[1:4, ‘CCC’] = [99, 76, 50, 20]
print(df)

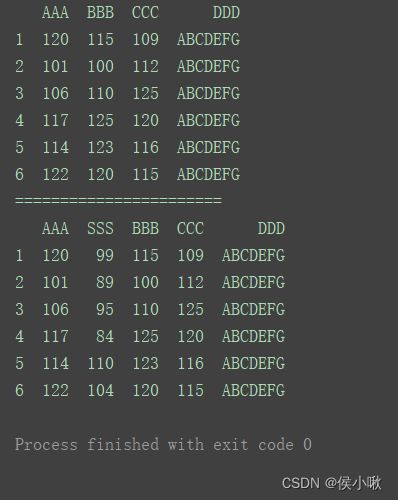
使用insert()方法添加
在第1列后添加一个名为’SSS’的列,数据为s1中的数据。
print(df)
print("=======================")
s1 = [99, 89, 95, 84, 110, 104]
df.insert(1, ‘SSS’, s1)
print(df)
2.4.2 按行增加数据
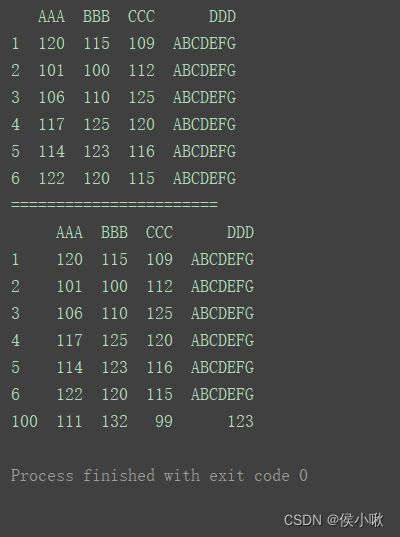
2.4.2.1 增加一行
print(df)
print("=======================")
df.loc[‘100’] = [111, 132, 99, 123]
print(df)
2.4.2.2 增加多行数据
将新数据创建一个格式一致的、新的DataFrame,然后使用append方法追加在原数据后边。
print(df)
print("=======================")
df_insert = pd.DataFrame({‘AAA’: [102, 124, 133, 120, 115, 121],
‘BBB’: [110, 125, 140, 111, 117, 126],
‘CCC’: [112, 118, 122, 114, 136, 125],
‘DDD’: ‘XYZ’}
, index=[10, 20, 30, 40, 50, 60])
df1 = df.append(df_insert)
print(df)
print("============================")
print(df1)

如图,使用append方法对一个DataFrame在后边追加一个DataFrame,不会改变原DataFrame,这一点不同于列表追加元素。
2.5 修改列名&索引
2.5.1修改列名
2.5.1.1 通过DataFrame的columns属性
print(df)
print("=======================")
df.columns = [‘A1’, ‘B2’, ‘C3’, ‘V4’]
print(df)

2.5.1.2 通过DataFrame的rename()方法
print(df)
print("=======================")
df.rename(columns={‘AAA’: ‘A1’, ‘BBB’: ‘B2’, ‘CCC’: ‘C3’}, inplace=True)
print(df)
inplace参数表示是否修改原DataFrame,默认False不修改。

2.5.2 修改索引(index)
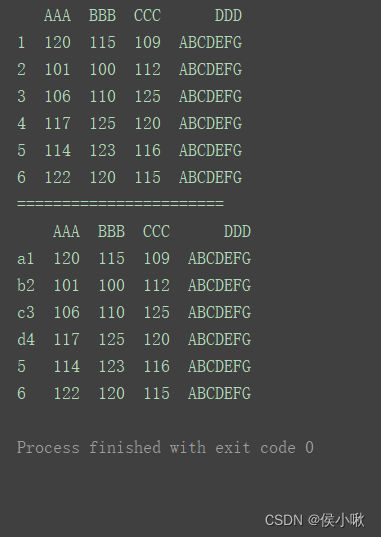
2.5.2.1 通过index属性
print(df)
print("=======================")
df.index = list(‘abcdef’)
print(df)

2.5.2.2通过rename方法
通过rename方法也可以实现对索引的修改。
参数axis默认为0,表示对index操作,(所以这里不设置axis也可)除非像上边的例子中传入有columns参数则表示对列操作。
print(df)
print("=======================")
df.rename({1: ‘a1’, 2: ‘b2’, 3: ‘c3’, 4: ‘d4’}, axis=0, inplace=True)
print(df)
2.6 修改数据
2.6.1 使用loc
修改整行数据
print(df)
print("=======================")
df.loc[3] = [111, 115, 109, 120]
print(df)
print("============================")
df.loc[3] = df.loc[3]+10
print(df)

修改整列数据
print(df)
print("=======================")
df.loc[:, ‘CCC’] = [116, 104, 115, 120, 125, 124]
print(df)

修改指定某一数据
print(df)
print("=======================")
df.loc[3, ‘BBB’] = 150
print(df)

2.6.2 使用iloc
修改整行数据
print(df)
print("=======================")
df.iloc[0, :] = [112, 120, 119, 126]
print(df)

修改整列数据
print(df)
print("=======================")
df.iloc[:, 0] = [111, 118, 114, 102, 125, 130]
print(df)

修改指定某一数据
print(df)
print("=======================")
df.iloc[0, 0] = 150
print(df)

2.7 删除数据
2.7.1 删除某列
print(df)
print("=======================")
df.drop([‘AAA’], axis=1, inplace=True)
print(df)
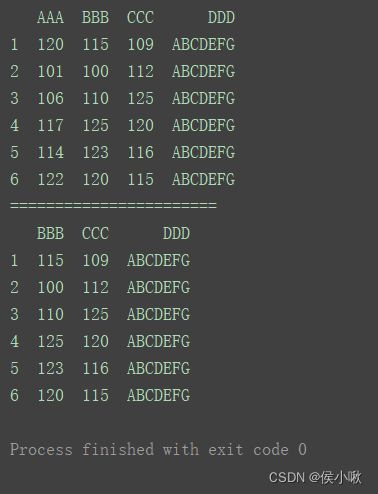
print(df)
print("=======================")
df.drop(columns=‘AAA’, inplace=True)
print(df)
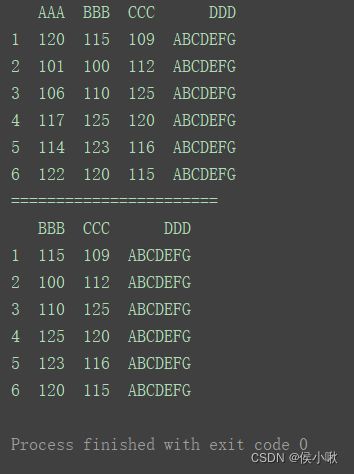
删除标签为’BBB’的,axis=1表示对列操作
print(df)
print("=======================")
df.drop(labels=‘BBB’, axis=1, inplace=True)
print(df)

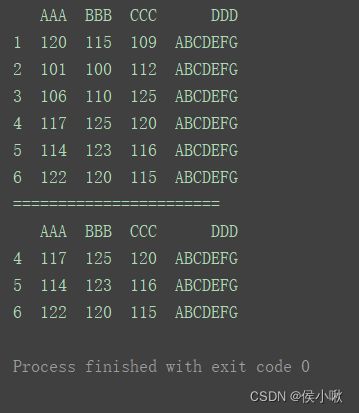
2.7.2 删除某行
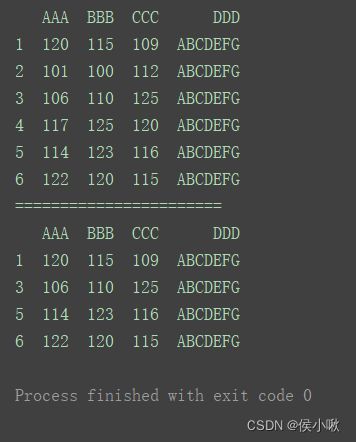
删除标签为2,4的行,axis默认为0,默认对行操作。
print(df)
print("=======================")
df.drop([2, 4], inplace=True)
print(df)
print(df)
print("=======================")
df.drop(index=3, inplace=True)
print(df)
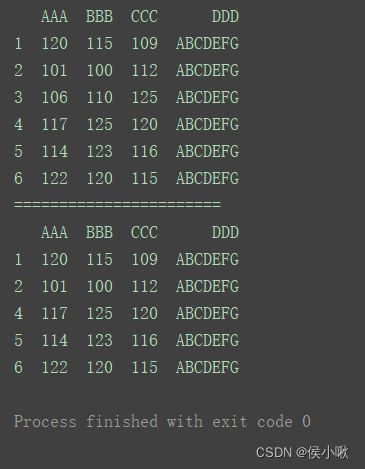
删除标签为4的,axis=0表示对行操作。
print(df)
print("=======================")
df.drop(labels=4, axis=0, inplace=True)
print(df)
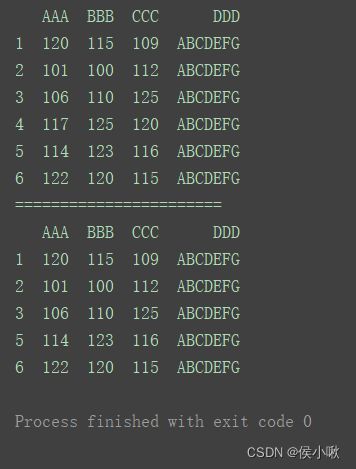
2.7.3删除特定条件的行
删除字段’AAA’为120,101或114的行。
print(df)
print("=======================")
df.drop(index=df[df[‘AAA’].isin([120, 101, 114])].index, inplace=True)
print(df)
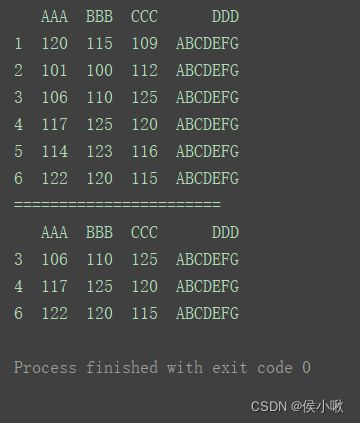
删除"BBB"字段小于120的行
print(df)
print("=======================")
df.drop(index=df[df[‘BBB’] < 120].index, inplace=True)
print(df)
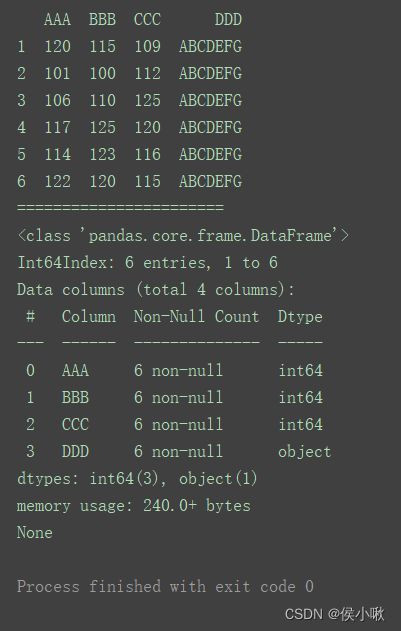
2.8 打印DataFrame的简短摘要
print(df)
print("=======================")
print(df.info())
2.9 处理缺失值与重复值
2.9.1处理缺失值
2.9.1.1 准备缺失值
准备两个缺失值
import numpy as np
df.iloc[0, 0] = np.NaN
df.iloc[2, 2] = np.NaN
print(df)
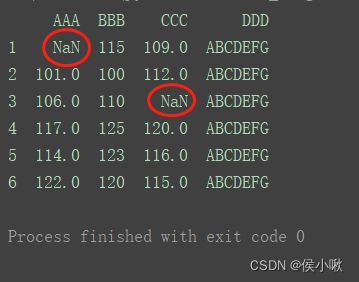
2.9.1.2 删除该缺失值所在行
print(df)
print("====================")
不修改原df的写法
df1 = df.dropna()
print(df1)
修改原df的写法
df.dropna(inplace=True)
print(df)

2.9.1.3获取某字段没有缺失值 的行
print(df)
print("=============================")
df2 = df[df[‘AAA’].notnull()]
print(df2)
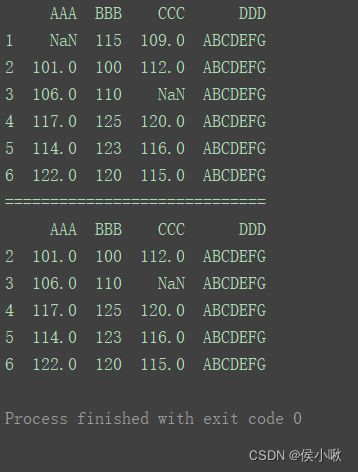
2.9.1.4 填充缺失值
以将缺失值填充为0为例
2.9.1.4.1 填充所有缺失值
print(df)
print("=============================")
df3 = df.fillna(0)
print(df3)

2.9.1.4.2 填充局部缺失值
print(df)
print("=============================")
df[‘AAA’] = df[‘AAA’].fillna(0)
print(df)

2.9.2 处理重复值
2.9.2.1准备数据
import pandas as pd
df = pd.DataFrame({
‘AAA’: [120, 101, 106, 101, 101, 122],
‘BBB’: [115, 100, 110, 100, 100, 120],
‘CCC’: [109, 112, 125, 112, 112, 115],
‘DDD’: ‘ABCDEFG’
}, index=[1, 2, 3, 4, 5, 6])
print(df)

2.9.2.2 判断重复值
2.9.2.2.1 判断整行数据是否重复
将一行完全相同的判断为重复值,第一次出现的行不会被判定为重复值,第二次及以上次数重复出现的才会。
print(df)
print("=============================")
print(df.duplicated())

2.9.2.2.2 判断某字段数据是否重复
以字段"AAA"为例。
print(df)
print("=============================")
print(df[‘AAA’].duplicated())
或者
print(df.duplicated([‘AAA’]))
print("=============================")
print(df.loc[df[‘AAA’].duplicated()])
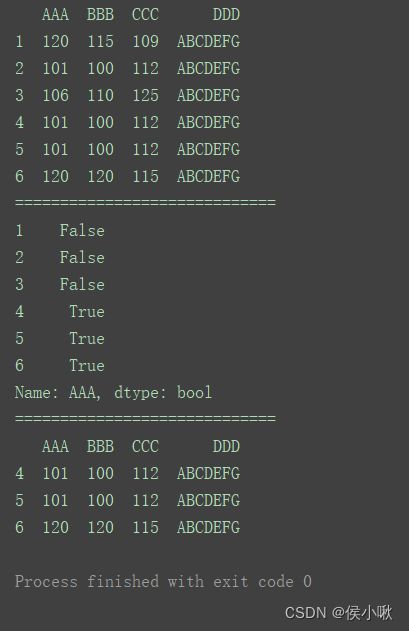
2.9.2.3 去重
2.9.2.3.1 删除整行重复值
不更改原df
print(df)
print("=============================")
df1 = df.drop_duplicates()
print(df1)
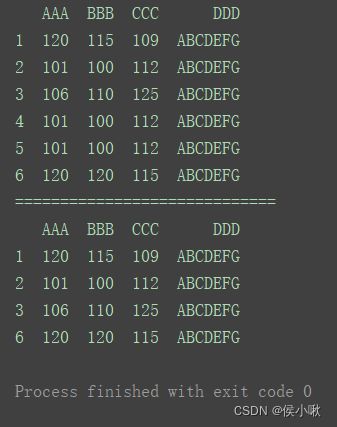 更改原df
更改原df
print(df)
print("=============================")
df.drop_duplicates(inplace=True)
print(df)

2.9.2.3.2 删除某字段重复 的行
print(df)
print("=============================")
print(df.drop_duplicates([‘AAA’]))
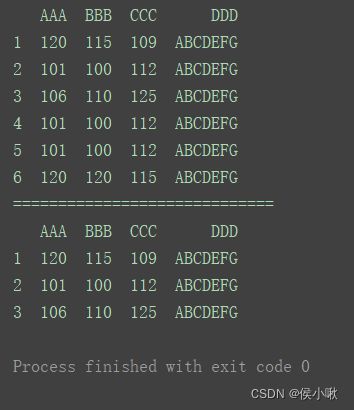
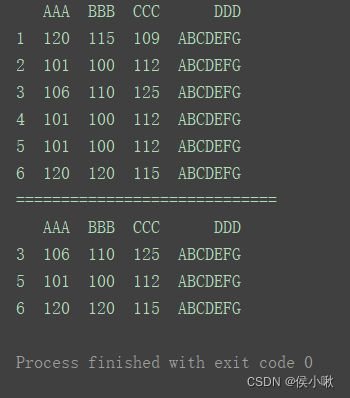
如果要保留重复行中的最后一行(默认是第一行),须将参数keep设置为’last’:
print(df)
print("=============================")
print(df.drop_duplicates([‘AAA’], keep=‘last’))
2.10设置索引
2.10.1 reindex
缺失值以0填充
from pandas import Series
s1 = Series([88, 60, 75], index=[1, 2, 3])
print(s1)
print("========================")
print(s1.reindex([1, 2, 3, 4, 5]))
print("========================")
重新设置索引,NaN以0填充
print(s1.reindex([1, 2, 3, 4, 5],fill_value=0))

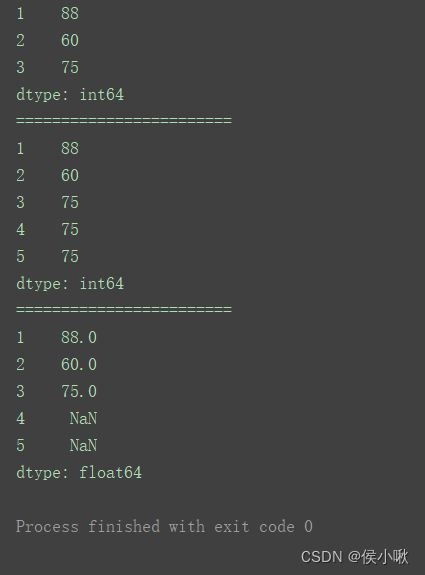
缺失值向前/向后填充
from pandas import Series
从pandas引入Series对象,就可以直接使用Series对象了,如Series([88,60,75],index=[1,2,3])
s1 = Series([88, 60, 75], index=[1, 2, 3])
print(s1)
print("========================")
print(s1.reindex([1, 2, 3, 4, 5], method=‘ffill’)) # 向前填充
print("========================")
print(s1.reindex([1, 2, 3, 4, 5], method=‘bfill’)) # 向后填充
重新设置行索引、列索引和行列索引
import pandas as pd
data = [[110, 105, 99], [105, 88, 115], [109, 120, 130]]
index = [‘001’, ‘003’, ‘005’]
columns = [‘语文’, ‘数学’, ‘英语’]
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
print("===============================================")
通过reindex()方法重新设置行索引、列索引和行列索引
print(df.reindex([‘001’, ‘002’, ‘003’, ‘004’, ‘005’]))
print("===============================================")
print(df.reindex(columns=[‘语文’, ‘物理’, ‘数学’, ‘英语’]))
print("===============================================")
print(df.reindex(index=[‘001’, ‘002’, ‘003’, ‘004’, ‘005’], columns=[‘语文’, ‘物理’, ‘数学’, ‘英语’]))

2.10.2 set_index
2.10.2.1 设置某列为index
设置"AAA"为index
import pandas as pd
df = pd.DataFrame({
‘AAA’: [120, 101, 106, 101, 101, 120],
‘BBB’: [115, 100, 110, 100, 100, 120],
‘CCC’: [109, 112, 125, 112, 112, 115],
‘DDD’: ‘ABCDEFG’
}, index=[1, 2, 3, 4, 5, 6])
print(df)
print("=============================")
设置“买家会员名”为行索引
df = df.set_index([‘AAA’])
print(df)

2.10.2.2 设置drop=True
设置drop=True,是把原来的索引index列去掉,重置index。不设置该参数则原index会作为一列保留。
import pandas as pd
df = pd.DataFrame({
‘AAA’: [120, 101, 106, 101, 101, 120],
‘BBB’: [115, 100, 110, 100, 100, 120],
‘CCC’: [109, 112, 125, 112, 112, 115],
‘DDD’: ‘ABCDEFG’
}, index=[101, 203, 304, 409, 511, 625])
print(df)
print("=============================")
df1 = df.dropna().reset_index()
print(df1)
print("=============================")
df2 = df.reset_index(drop=True)
print(df2)

2.11排序
2.11.1 sort_values()单列排序
ascending默认为True,表示升序。设置为False表示降序。
sort_values()也可以通过设定inplace参数来选择是否修改原df。
import pandas as pd
df = pd.DataFrame({
‘AAA’: [120, 101, 106, 101, 101, 120],
‘BBB’: [115, 100, 110, 100, 100, 120],
‘CCC’: [109, 112, 125, 112, 112, 115],
‘DDD’: ‘ABCDEFG’
}, index=[1, 2, 3, 4, 5, 6])
print(df)
print("=============================")
df1 = df.sort_values(by=‘BBB’, ascending=False)
print(df1)

2.11.2 sort_values()多列排序
多列排序按照给定列的先后顺序进行排序。
import pandas as pd
df = pd.DataFrame({
‘AAA’: [120, 101, 106, 101, 101, 120],
‘BBB’: [115, 100, 110, 100, 100, 120],
‘CCC’: [109, 112, 125, 112, 112, 115],
‘DDD’: ‘ABCDEFG’
}, index=[1, 2, 3, 4, 5, 6])
print(df)
print("=============================")
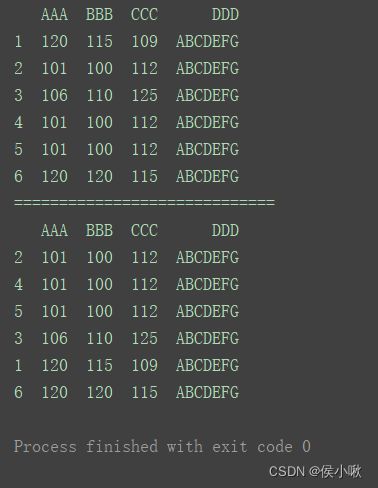
df1 = df.sort_values(by=[‘AAA’, ‘BBB’])
print(df1)
如图,先升序排列"AAA","AAA"值相同的用"BBB"升序排列。
2.11.3 group_by()对统计结果排序
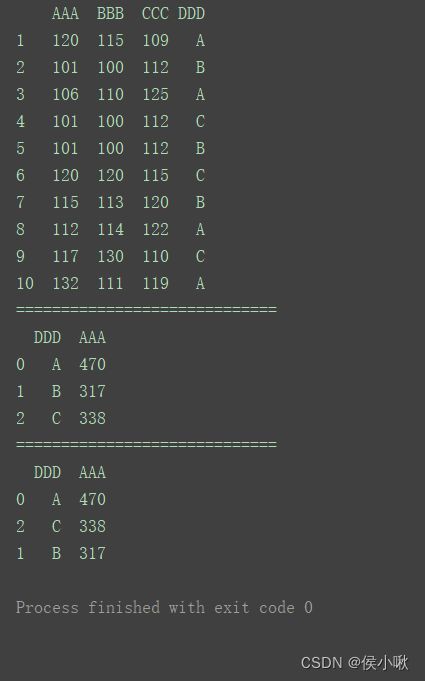
import pandas as pd
df = pd.DataFrame({
‘AAA’: [120, 101, 106, 101, 101, 120, 115, 112, 117, 132],
‘BBB’: [115, 100, 110, 100, 100, 120, 113, 114, 130, 111],
‘CCC’: [109, 112, 125, 112, 112, 115, 120, 122, 110, 119],
‘DDD’: [‘A’, ‘B’, ‘A’, ‘C’, ‘B’, ‘C’, ‘B’, ‘A’, ‘C’, ‘A’]
}, index=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
print(df)
print("=============================")
df1 = df.groupby([“DDD”])[“AAA”].sum().reset_index()
df2 = df1.sort_values(by=‘AAA’, ascending=False)
print(df1)
print("=============================")
print(df2)
2.11.4横向排序 axis=1
以索引的标签为1,升序,为例:
import pandas as pd
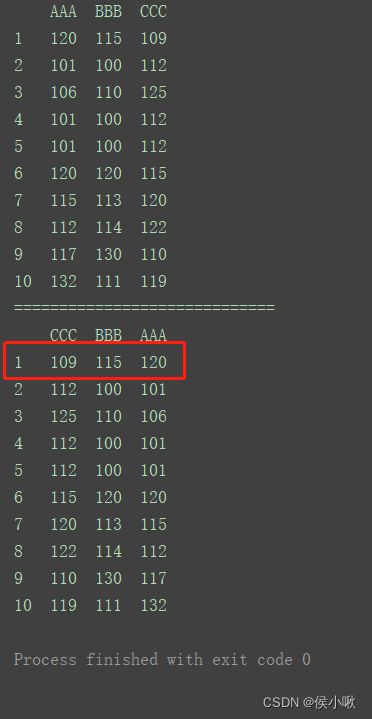
df = pd.DataFrame({
‘AAA’: [120, 101, 106, 101, 101, 120, 115, 112, 117, 132],
‘BBB’: [115, 100, 110, 100, 100, 120, 113, 114, 130, 111],
‘CCC’: [109, 112, 125, 112, 112, 115, 120, 122, 110, 119]
}, index=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
print(df)
print("=============================")
按照索引值(标签的值)为1的行,升序排序
df1 = df.sort_values(by=1, ascending=True, axis=1)
print(df1)
2.11.5 排名 rank()
method参数可以取的值有"average", “first”, “max”, “min”,默认为"average"。
-
average表示排名时如果出现数值相等,则取平均排名,如降序排名,如果第二三四名数值大小相等,则都标记为第(2+3+4)/3=3,即第3名。
-
first 表示排名时如果出现数值相等,则参考在原数据的顺序进行排名
-
max表示排名时如果出现数值相等,则取其最大排名,如降序排名,如果第二三四名数值大小相等,则都标记为第4名。
-
min表示排名时如果出现数值相等,则取其最小排名,如降序排名,如果第二三四名数值大小相等,则都标记为第2名。
import pandas as pd
df = pd.DataFrame({
‘AAA’: [120, 101, 106, 101, 101, 120, 115, 112, 117, 132],
‘BBB’: [115, 100, 110, 100, 100, 120, 113, 114, 130, 111],
‘CCC’: [109, 112, 125, 112, 112, 115, 120, 122, 110, 119]
}, index=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
print(df)
print("=============================")
按“销量”列降序排序
df1 = df.sort_values(by=‘AAA’, ascending=False)
顺序排名
df1[‘AAA_order’] = df1[‘AAA’].rank(method=“first”, ascending=False)
df2 = df1[[‘AAA’, ‘AAA_order’]]
print(df2)

3.pandas读取文件
==================================================================================
3.1read_excel()
3.1.1准备数据
import pandas as pd
id = [‘xx1’, ‘xx2’, ‘xx3’, ‘xx4’, ‘xx5’]
df = pd.DataFrame({
‘name’: [‘aaa’, ‘bbb’, ‘ccc’, ‘ddd’, ‘eee’],
‘age’: [18, 20, 21, 22, 19],
‘gender’: [‘male’, ‘female’, ‘male’, ‘female’, ‘female’],
‘class’: [‘A’, ‘B’, ‘B’, ‘A’, ‘A’]
}, index=id)
保存为excel文件
df.to_excel(‘data.xlsx’)
3.1.2默认方式读取
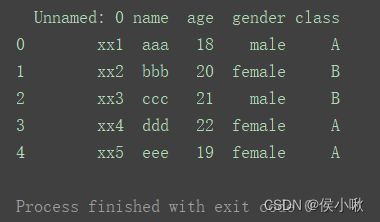
read_excel()读取excel文件得到的DataFrame,
-
index值默认为0,1,2,3…
-
列名默认为excel中的第一行数据
df = pd.read_excel(‘data.xlsx’)
print(df)
3.1.3设置index_col参数
df1 = pd.read_excel(‘data.xlsx’, index_col=0)
print(df1)
如图,通过index_col=0,将下标为0的列作为索引进行读取。

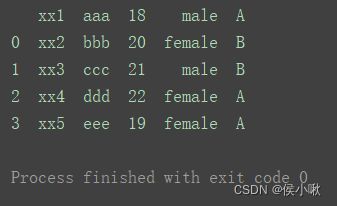
3.1.4设置header参数
header可以设置列名,默认为0表示首行即列名,
- 如图通过 header=1,将下标为1行作为了列名(第二行)
df2 = pd.read_excel(‘data.xlsx’, header=1) # 设置第1行为列索引
print(df2)
- 当header参数为None时,表示列名为数字0,1,2,3…
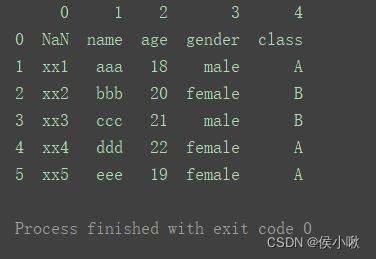
df3 = pd.read_excel(‘data.xlsx’, header=None)
print(df3)
3.1.5设置usecols参数
通过usecols参数,传入列位置或标签列表,可以导出指定列
- 传入一个位置
df1 = pd.read_excel(‘data.xlsx’, usecols=[1]) # 通过指定列索引号导入第1列
print(df1)

- 传入多个位置
df2 = pd.read_excel(‘data.xlsx’, usecols=[1, 3])
print(df2)

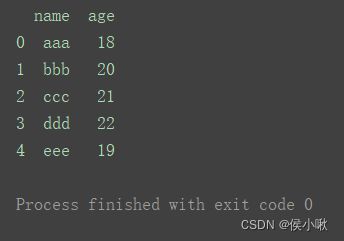
- 传入多个标签
df3 = pd.read_excel(‘data.xlsx’, usecols=[‘name’, ‘age’])
print(df3)
3.1.6设置sheet_name参数以指定工作簿
可以通过read_excel()的sheet_name参数传入工作簿名称。
如:
import pandas as pd
df = pd.read_excel(‘data_name.xlsx’, sheet_name=‘sheetA’)
df1 = df.head() # 输出前5条数据
3.1.7解决数据输出时列名不对齐的问题
使用命令
pd.set_option(‘display.unicode.east_asian_width’, True)
import pandas as pd
pd.set_option(‘display.unicode.east_asian_width’, True)
df = pd.read_excel(‘data.xlsx’)
3.2read_csv()
3.2.1设置encoding参数
设置encoding参数可以指定编码方式,默认为None。
出现乱码的时候可以使用。
import pandas as pd
df = pd.read_csv(‘data.csv’, encoding=‘gbk’) # 导入csv文件,并指定编码格式
print(df.head())
3.2.2设置sep参数指定分隔符
sep默认为",",表示分隔符默认为逗号。
根据数据的具体情形,设置不同的分隔符,下例中读取了分隔符为\t的txt文本文件。
import pandas as pd
df1 = pd.read_csv(‘1月.txt’, sep=’\t’, encoding=‘gbk’)
df1 = df1.head()
3.3read_html()小案例
3.3.1pd.read_html()方法
使用pandas的read_html()方法,只需要传入url,可以获取到相应的网页源码中的表格数据,返回的数据格式为一个列表。
3.3.2DataFrame的append()方法
此外可以对DataFrame对象使用append方法将满足一定格式(形似一个表格)的列表数据添加到其中,ignore_index=True可以忽略掉该list对象中数据的索引列,而将索引设为默认的0,1,2…,避免了多个list对象的索引重复的问题。以该案例为例:
以网站http://www.espn.com/nba/salaries/_/seasontype/4等为例,获取此网站及其他11页的表格数据,并保存为csv文件。
3.3.3pd.to_csv()方法
-
header 表头,传入形式为一个列表,默认为数据第一行
-
index=False 忽略索引

import pandas as pd
df = pd.DataFrame()
url_list = [‘http://www.espn.com/nba/salaries/_/seasontype/4’]
for i in range(2, 13):
url = ‘http://www.espn.com/nba/salaries/_/page/%s/seasontype/4’ % i
url_list.append(url)
遍历网页中的table读取网页表格数据
for url in url_list:
df = df.append(pd.read_html(url), ignore_index=True)
通过观察,df中第三个数据都是以 开 头 的 , 除 了 重 复 出 现 的 标 题 数 据 。 以 以 开头的,除了重复出现的标题数据。以以 开头的,除了重复出现的标题数据。以以开头为筛选条件,去除冗余数据。
df = df[[x.startswith(’$’) for x in df[3]]]
df.to_csv(‘NBA.csv’, header=[‘RK’, ‘NAME’, ‘TEAM’, ‘SALARY’], index=False)
