尚硅谷大数据---06---hive01
文件:warehouse指的是仓库。
hive官方文档:https://hive.apache.org/
hadoop入门:https://www.jianshu.com/p/0d4a365ef350

hive的介绍:
一、Hive的介绍
1. Hive是一个数据仓库软件
Hive可以使用SQL来促进对已经存在在分布式设备中的数据进行读,写和管理等操作!
Hive在使用时,需要对已经存储的数据进行结构的投影(映射)
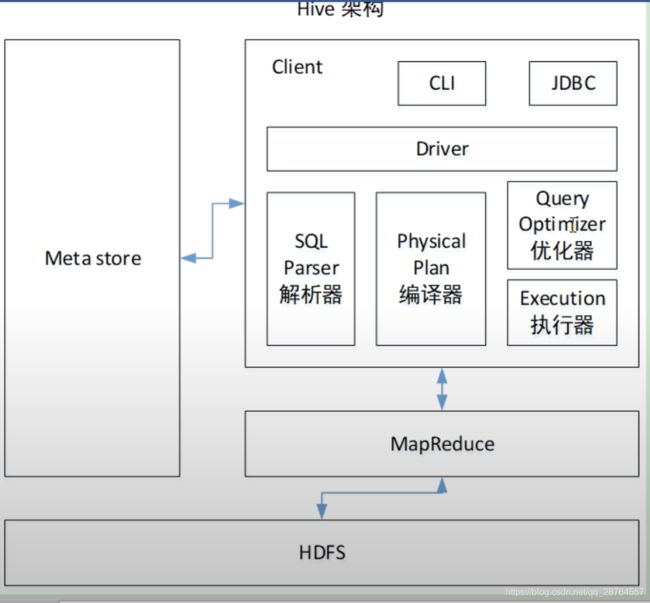
Hive提供了一个命令行和JDBC的方式,让用户可以连接到hive!
注意:Hive只能分析结构化的数据!
Hive在Hadoop之上,使用hive的前提是先要安装Hadoop
2. Hive的特点
①Hive并不是一个关系型数据库,不是关系型数据库,hive只是分析更多的是查询的操作。
②不是基于OLTP(在线事务处理)设计
OLTP设计的软件: 侧重点在事务的处理,和在线访问。一般RDMS都是基于OLTP设计
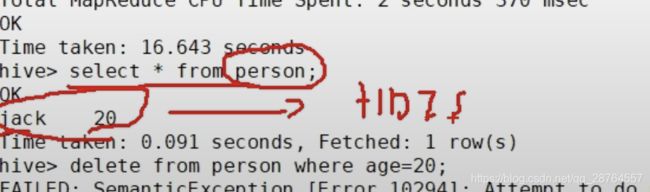
③Hive无法做到实时查询,不支持行级别更新(update,delete),hive是不支持随机写的,是存在hdfs上的,可以insert。
④Hive要分析的数据存储在HDFS,hive为数据创建的表结构(schema),存储在RDMS
⑤Hive基于OLAP(在线分析处理)设计
OLAP设计的软件:侧重点在数据的分析上,不追求分析的效率!
⑥Hive使用类SQL,称为HQL对数据进行分析
⑦Hive容易使用,可扩展,有弹性
---02---
---03---
和数据库的对比:
---04---
hive查询wordCount:
3. WordCount
如何用hive实现wordcount?
源文件:
hadoop hive hadoop
hadoop hive
...
将源文件转为结构化的数据,交给etl
hadoop 1
hive 1
hadoop 1
...
①建表
表需要根据存储的数据的结构创建!
表要映射到数据的结构上
create table a(word string,totalCount int)
②写HQL:
select word,sum(totalCount)
from a
group by word
---05---
etl作用:https://blog.csdn.net/qq_41946557/article/details/102996488
hive和hadoop安装在192.168.244.133这台机器上。
安装hive。
不支持更新和删除的:

---06---
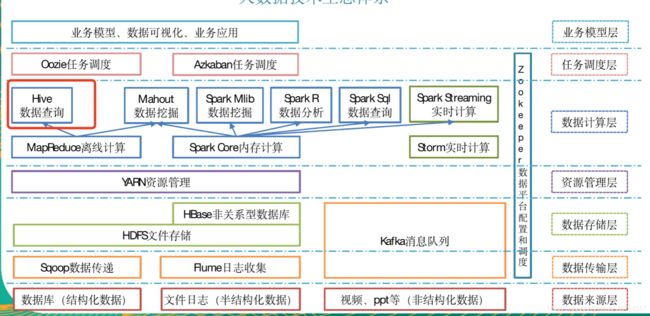
三部分:Hive hadoop 关系型数据库
分析的数据是存储在hdfs中的:
http://192.168.244.133:50070/dfshealth.html#tab-overview
http://192.168.244.133:8088/cluster
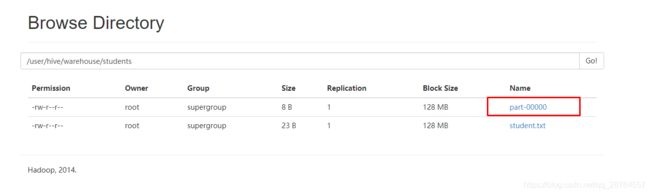
hive在hadoop的默认路径:/user/hive/warehouse/students
我们插入一条数据之后:
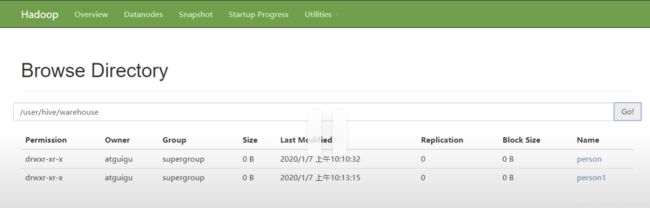
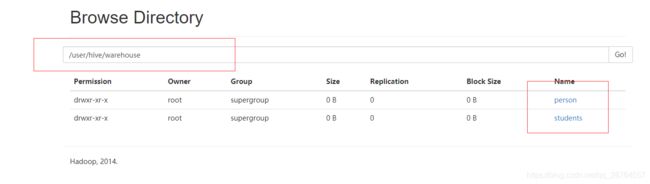
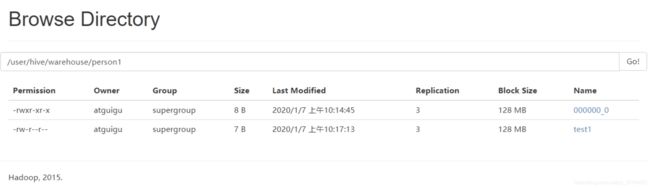
我们再建一个person1这个表:

插入一条数据则:

插入数据:
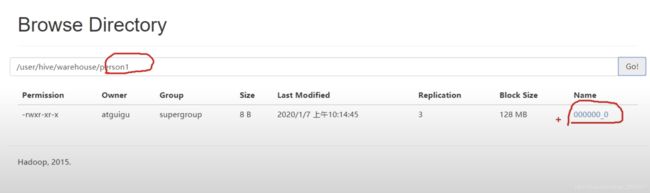
看下文件在那里:
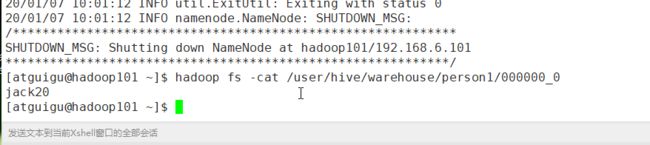
---
我们编辑一个文件上传到hadoop,注意语句是如何写的:

库和表都是文件夹,数据是文件。
1.Hive要分析的数据是存储在HDFS上
hive中的库的位置,在hdfs上就是一个目录!
hive中的表的位置,在hdfs上也是一个目录,在所在的库目录下创建了一个子目录!
hive中的数据,是存在在表目录中的文件!我自己的练习:

看下hdfs的网页:
我们在hive查询下:
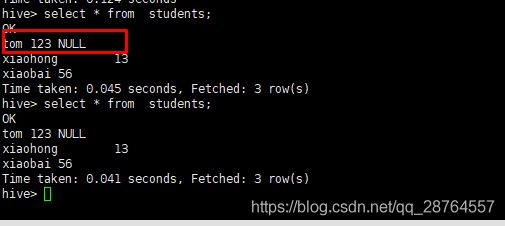
这个是因为没有指定分割符的原因。
如何修改呢?
在编辑模式不是插入模式,先按ctrl+v 再按crtl+a
查询:
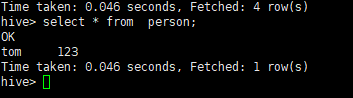
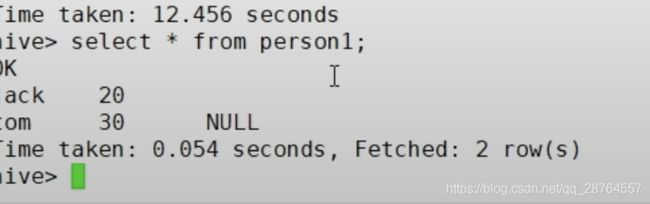
为什么是null,是因为没有分隔符的。
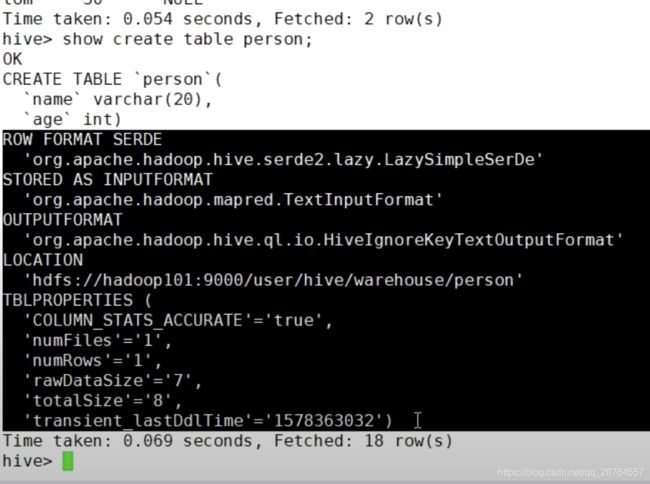
分隔符,注意主要有几个分隔符:
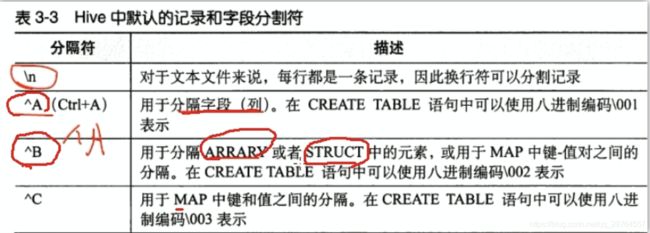
总结:
1.Hive要分析的数据是存储在HDFS上
hive中的库的位置,在hdfs上就是一个目录!
hive中的表的位置,在hdfs上也是一个目录,在所在的库目录下创建了一个子目录!
hive中的数据,是存在在表目录中的文件!
2. 在hive中,存储的数据必须是结构化的数据,而且
这个数据的格式要和表的属性紧密相关!
表在创建时,有分隔符属性,这个分隔符属性,代表在执行MR程序时,使用哪个分隔符去分割每行中的字段!
hive中默认字段的分隔符: ctrl+A, 进入编辑模式,ctrl+V 再ctrl+A
---07---
注意文件里面是不存储字段信息的,只是存储数据。
元数据的存储:
实验,首先退出quit
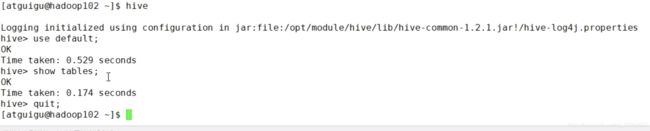
再次启动找不到表了。
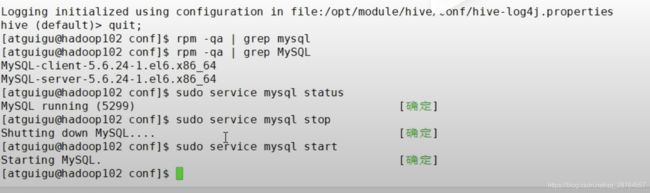
mysql主要是帮助hive去存储元数据的信息的,所以我们用mysql解决,我们首先要看下是不是有和mysql冲突的包:

卸载:
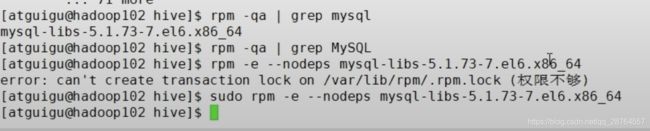
---08---
mysql安装
修改hive的配置,让其元数据配置到mysql中去。
按照文档倒入jar包和修改xml,此时我们在hive再创建一个数据库:

可以看到:


再次观察:
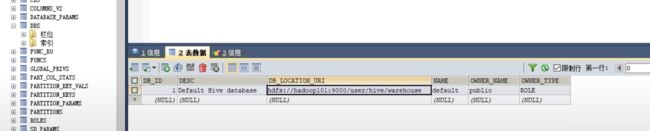
继续观察:
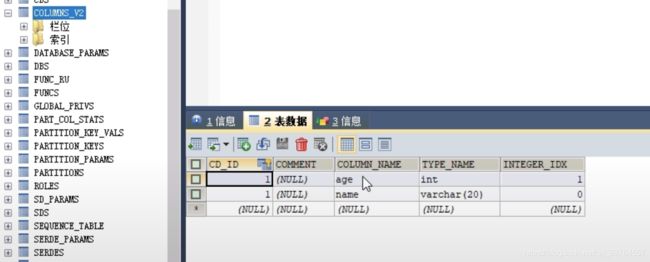
总结:
3. hive中的元数据(schema)存储在关系型数据库
默认存储在derby中!
derby是使用Java语言编写的一个微型,常用于内嵌在Java中的数据库!
derby同一个数据库的实例文件不支持多个客户端同时访问!
4. 将hive的元数据的存储设置存储在Mysql中!
Mysql支持多用户同时访问一个库的信息!
注意事项: ①metastore库的字符集必须是latin1
②5.5mysql,改 binlog_format=mixed | ro w
默认为statement
mysql的配置文件: /etc/my.cnf
①安装MySQL
卸载时: 使用rpm -e卸载后,需要删除 /var/lib/mysql目录!
检查:
5. 元数据的结构
表的信息都存储在tbls表中,通过db_id和dbs表中的库进行外键约束!
库的信息都存储在dbs表中!
字段信息存在在column_v2表中,通过CD_ID和表的主键进行外键约束!
---9---
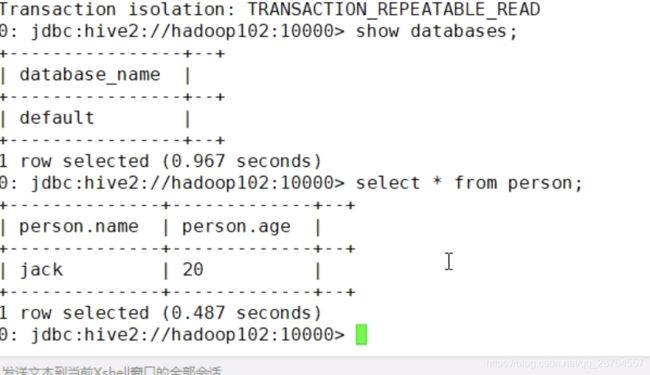
HiveJDBC的访问:用JDBC访问要有服务端和客户端的。
服务端:
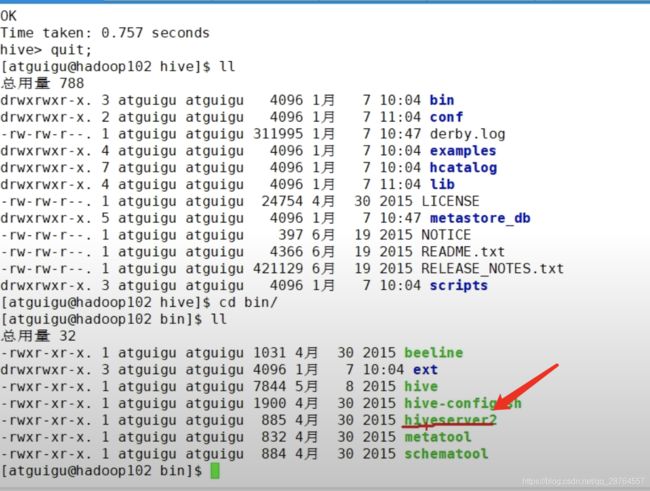
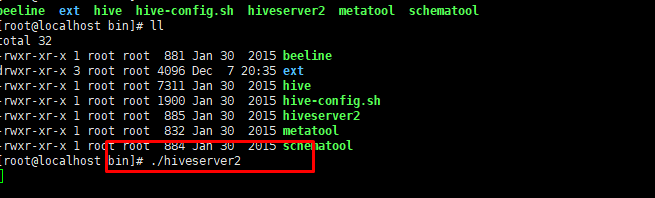
再换一个窗口,客户端:
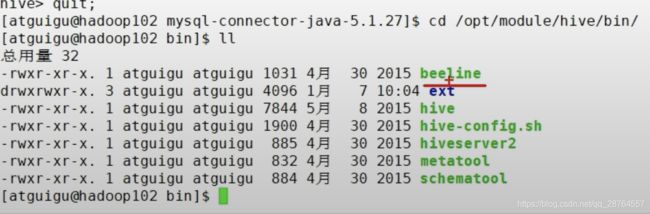
进入beeline:
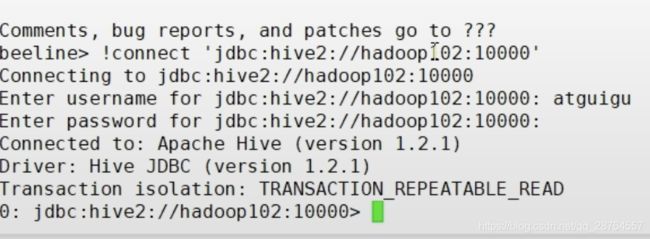
查询:
写程序访问:
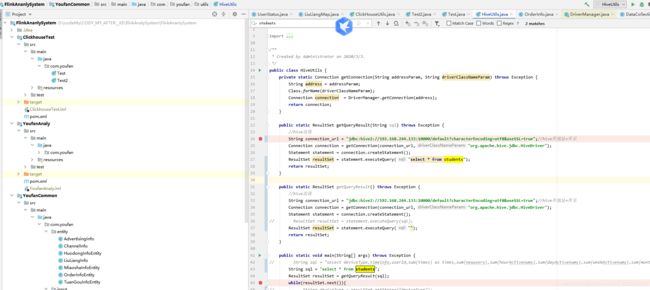
代码:
package com.atguigu.hive.jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class HiveJdbc {
public static void main(String[] args) throws Exception {
//①加载驱动
//Class.forName("org.apache.hive.jdbc.HiveDriver");
//②创建连接
Connection connection = DriverManager.getConnection("jdbc:hive2://hadoop102:10000", "atguigu", "");
// ③准备SQL
String sql="select * from default.person";
// ④预编译sql
PreparedStatement ps = connection.prepareStatement(sql);
// ⑤执行sql
ResultSet resultSet = ps.executeQuery();
while(resultSet.next()) {
System.out.println("name:"+resultSet.getString("name")+"---->age:"+
resultSet.getInt("age"));
}
}
}
这段代码是可以查到的:
---11---
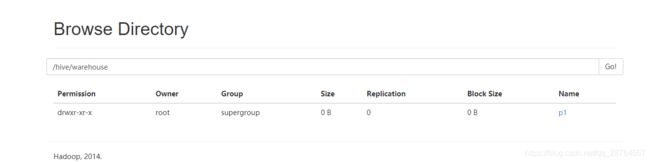
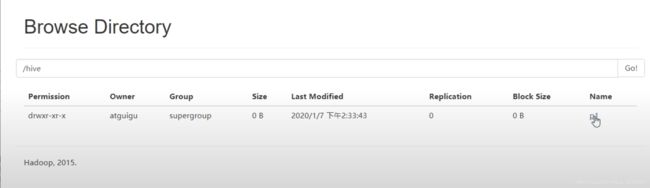
修改下默认的仓库:
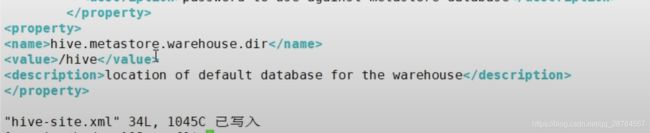
再次进入hive。
再次建表:

---12---
---13---
mysql的一些操作


hive的日志在哪里------------------没看?

---14---
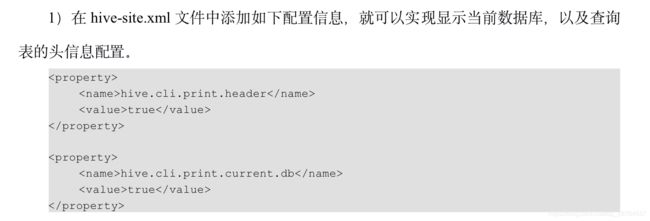
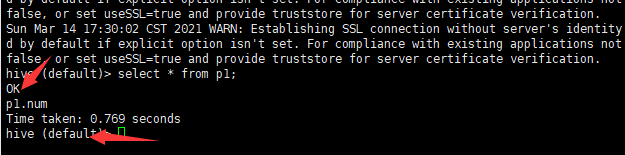
第一个参数配置:设置参数启动
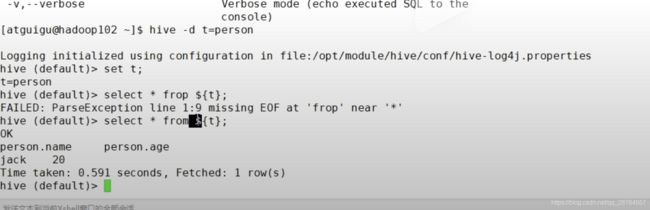
第二个参数配置:指定启动之后连接哪个数据库的。

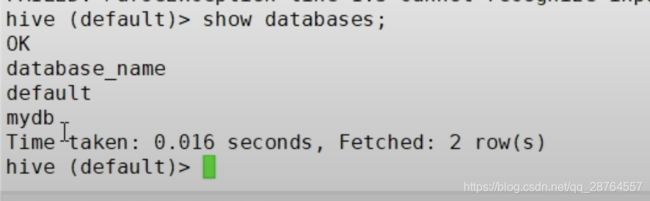
连接:

第三个参数配置:
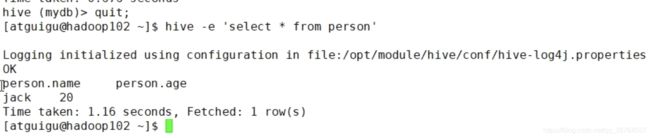
第四个参数配置:读取文件
第一步:新建一个文件

第二步:

第五个参数配置:

第六个参数配置,不退出cli:

第七个参数配置:
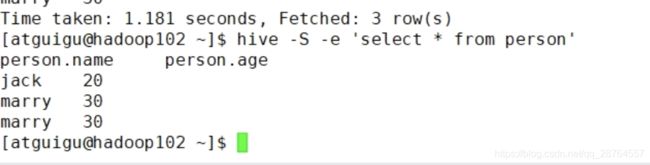
第八个参数配置:

总结:
6. hive常用的交互参数
usage: hive
-d,--define Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
定义一个变量,在hive启动后,可以使用${变量名}引用变量
--database Specify the database to use
指定使用哪个库
-e SQL from command line
指定命令行获取的一条引号引起来的sql,执行完返回结果后退出cli!
-f SQL from files
执行一个文件中的sql语句!执行完返回结果后退出cli!
-H,--help Print help information
--hiveconf Use value for given property
在cli运行之前,定义一对属性!
hive在运行时,先读取 hadoop的全部8个配置文件,读取之后,再读取hive-default.xml
再读取hive-site.xml, 如果使用--hiveconf,可以定义一组属性,这个属性会覆盖之前读到的参数的值!
--hivevar Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
作用和-d是一致的!
-i Initialization SQL file
先初始化一个sql文件,之后不退出cli
-S,--silent Silent mode in interactive shell
不打印和结果无关的信息
-v,--verbose Verbose mode (echo executed SQL to the
console) ---15---没看-----
其他的命令:

操作linux里面的东西:
---16---
hive的数据类型:
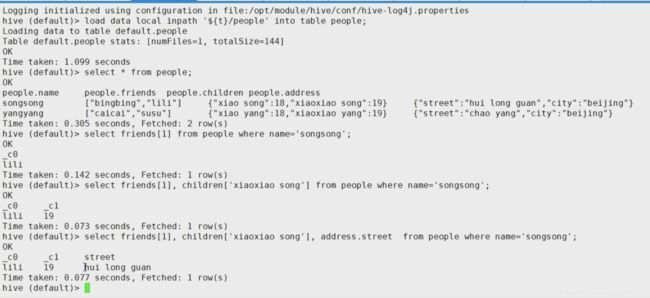
struct相当于java的对象,是那种只有属性的对象。
建表看文档。
如何查询:

---17---
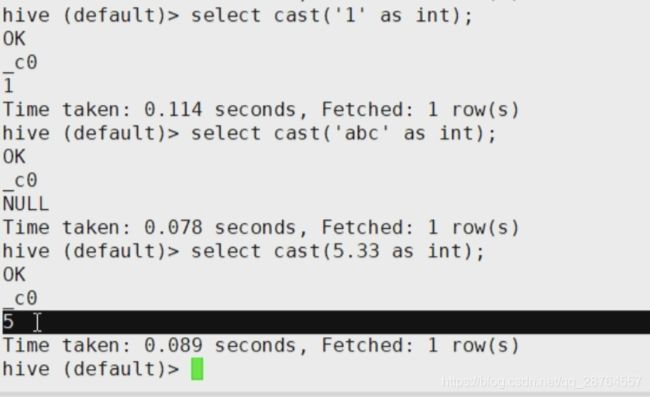
数据转换看文档。
---18---
如何操作hive:

建立数据库语句:

对库可以修改的东西:

总结:
一、库的常见操作
1.增
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment] // 库的注释说明
[LOCATION hdfs_path] // 库在hdfs上的路径
[WITH DBPROPERTIES (property_name=property_value, ...)]; // 库的属性
create database if not exists mydb2
comment 'this is my db'
location 'hdfs://hadoop101:9000/mydb2'
with dbproperties('ownner'='jack','tel'='12345','department'='IT');
2.删
drop database 库名: 只能删除空库
drop database 库名 cascade: 删除非空库
3.改
use 库名: 切换库
dbproperties: alter database mydb2 set dbproperties('ownner'='tom','empid'='10001');
同名的属性值会覆盖,之前没有的属性会新增
4.查
show databases: 查看当前所有的库
show tables in database: 查看库中所有的表
desc database 库名: 查看库的描述信息
desc database extended 库名: 查看库的详细描述信息---19---
表的操作:
查看表:
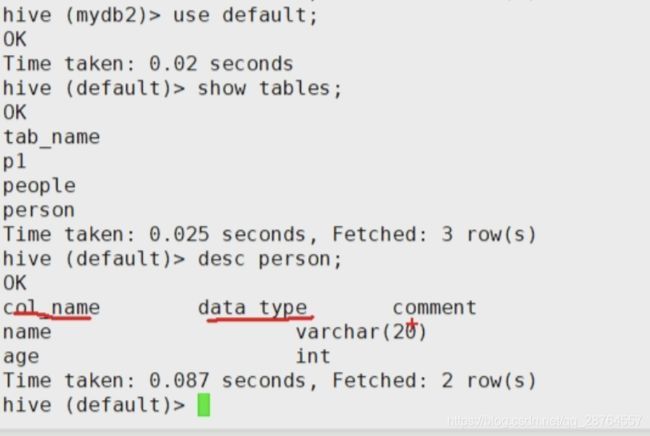
总结:
一、表操作
1.增
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)] //表中的字段信息
[COMMENT table_comment] //表的注释
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format] // 表中数据每行的格式,定义数据字段的分隔符,集合元素的分隔符等
[STORED AS file_format] //表中的数据要以哪种文件格式来存储,默认为TEXTFILE(文本文件)
可以设置为SequnceFile或 Paquret,ORC等
[LOCATION hdfs_path] //表在hdfs上的位置
①建表时,不带EXTERNAL,创建的表是一个MANAGED_TABLE(管理表,内部表)
建表时,带EXTERNAL,创建的表是一个外部表!
外部表和内部表的区别是:
内部表(管理表)在执行删除操作时,会将表的元数据(schema)和表位置的数据一起删除!
外部表在执行删除表操作时,只删除表的元数据(schema)
在企业中,创建的都是外部表!
在hive中表是廉价的,数据是珍贵的!
建表语句执行时:
hive会在hdfs生成表的路径;
hive还会向MySQl的metastore库中掺入两条表的信息(元数据)
管理表和外部表之间的转换:
将表改为外部表: alter table p1 set tblproperties('EXTERNAL'='TRUE');
将表改为管理表: alter table p1 set tblproperties('EXTERNAL'='FALSE');
注意:在hive中语句中不区分大小写,但是在参数中严格区分大小写!
2.删
drop table 表名:删除表
3.改
4.查
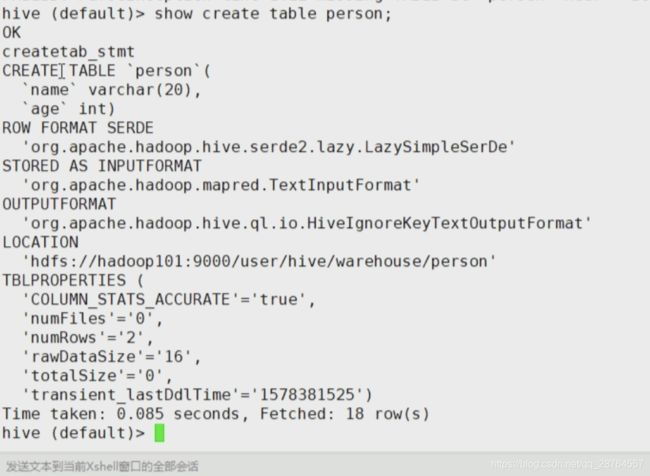
desc 表名: 查看表的描述
desc formatted 表名: 查看表的详细描述如何显示建标语句:
---20---

这里明天说
---21---
Hive和mysql:https://blog.csdn.net/seaReal1/article/details/80073931