Performer带头反思Attention,大家轻拍!丨ICLR2021
AMiner平台由清华大学计算机系研发,拥有我国完全自主知识产权。平台包含了超过2.3亿学术论文/专利和1.36亿学者的科技图谱,提供学者评价、专家发现、智能指派、学术地图等科技情报专业化服务。系统2006年上线,吸引了全球220个国家/地区1000多万独立IP访问,数据下载量230万次,年度访问量超过1100万,成为学术搜索和社会网络挖掘研究的重要数据和实验平台。
AMiner平台:https://www.aminer.cn
Transformer-based模型在众多领域已取得卓越成果,包括自然语言、图像甚至是音乐。然而,Transformer架构一直以来为人所诟病的是其注意力模块的低效,即长度二次依赖限制问题。随着输入序列长度的增加,注意力模块的问题也越来越突出,算力和内存消耗是输入序列长度的平方。这还怎么和长输入序列愉快玩耍?
那么先(大)贤(佬)们是怎么让Transformer-based模型应对长输入序列的呢?
今天,和大家分享一篇来自谷歌、剑桥大学、DeepMind、阿兰 · 图灵研究所投稿于ICLR 2021的论文《Rethinking Attention with Performers》。

论文地址:https://www.aminer.cn/pub/5f75feb191e0111c1eb4dbb2/rethinking-attention-with-performers
论文代码:https://github.com/google-research/google-research/tree/master/performer
如何让Transformer-based模型应对长输入序列的呢?
比较早期的是从内存方面入手,Transformer-XL和内存压缩的Transformer,再到近年来频频上头条的各种稀疏注意力机制。稀疏注意力机制不再暴力地计算所有token之间的注意力,而仅仅计算出有限token对之间的相似度得分。这些需要重点attend的稀疏注意力项可以是人工指定,也可以是通过优化方法找到的,还可以是通过学习学到的,甚至可以是随机的。
稀疏注意力派系的取名都比较中规中矩,要么是是X Transformers要么是X-former。来一波名字赏析:Sparse Transformers,Set Transformer, Routing Transformers, Axial Transformer, Sparse Sinkhorn Transformer, Linformer, Longformers, Extended Transformer Construction(ETC) 等。一个取名较为另类的是Big Bird,强行凑芝麻街的梗,忍不住吐槽下。
目前的这些稀疏注意力方法仍然有以下局限:
(1)需要高效的稀疏矩阵乘法运算,而这些运算并不是所有加速器都能提供。比如Longformer的实现采用TVM技术将计算自注意力的代码编译为CUDA核。
(2)通常缺乏严格的理论保证。这点Big Bird是有的。
(3)主要针对Transformer模型和生成式预训练进行优化。
(4)通常需要堆叠更多的注意力层来补偿稀疏表征,这使得它们很难与其他预训练模型一起使用,因此需要进行再训练,这就很费时费力。完全不符合低碳的主流。。。
除了上述这些缺点之外,稀疏注意机制往往还无法解决常规注意方法所应用的全部问题,比如如 Pointer Networks。此外,还有一些操作是无法进行稀疏化的,比如softmax操作。
为此,文章提出 Performer。
Performer
Performer是一个Transformer架构,其注意力机制可线性扩展,一方面可以让模型训练得更快,另一方面也能够让模型处理更长的输入序列。这对于某些图像数据集(如ImageNet64)和文本数据集(如PG-19)来说定然是很香的。Performer使用了一个高效的(线性)通用注意力框架,在框架中使用不同的相似度测量(即各种核方法)可以实现各种注意力机制。该框架由FAVOR+(Fast Attention Via Positive Orthogonal Random Features,通过正交随机特征实现快速注意力)算法实现,该算法提供了可扩展、低方差、无偏估计的注意力机制,可以通过随机特征图分解来表达。该方法一方面确保了线性空间和时间复杂度,另一方面也保障了准确率。此外,该方法可以单独用于softmax 运算,还可以和可逆层等其他技术进行配合使用。
通用注意力机制
常规的注意力机制中,对应矩阵行与列的 query 和 key 相乘,再通过 softmax 计算出注意力得分矩阵。但是这种方法,不能将query-key传递到非线性 softmax 操作之后的结果分解回原来的key和query,但是可以将注意力矩阵分解为原始query和key的随机非线性函数的乘积,也就是所谓的随机特征(random features),这样就可以更有效地对相似性信息进行编码。
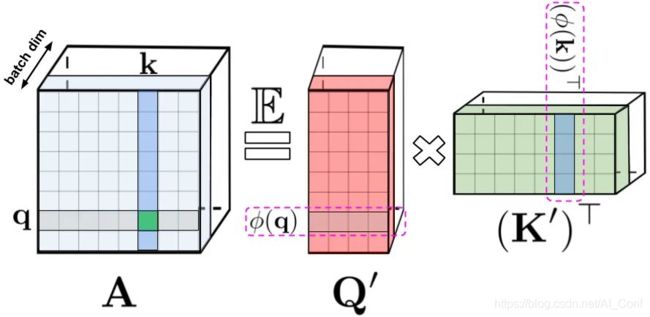
LHS:标准注意力矩阵,由 query(表示为q) 和 key(表示为k) 上的 softmax 计算组成,表示两两之间的相似得分。RHS:标准注意力矩阵可以通过低阶随机化矩阵Q′和K′来近似,行编码由随机化非线性函对原始query/key进行编码而得到。对于常规的softmax-attention,变换非常紧凑,涉及指数函数以及随机高斯投影。
常规的 softmax 注意力(softmax-attention)可以看作是由指数函数和高斯投影定义的非线性函数的一个特例。在这里也可以反向推理,首先实现一些更广义的非线性函数,在query-key 结果上隐式定义其他类型的相似性度量或核函数。文章中所定义的通用注意力(generalized attention)是基于早期的核方法(Random Features for Large-Scale Kernel Machines)。尽管大多核函数闭式解并不存在,但是由于Performer的使用并不依赖于闭式解,所以这一机制仍然适用。
文章首次证明了,在下游 Transformer 的应用中,任意注意力矩阵都可以通过随机特征实现有效近似。实现这一点的新机制使用positive random features(正向随机特征),即原始 query 和 key 的正值非线性函数。这避免了训练过程中的不稳定,并实现了对常规 softmax 注意力的更准确近似。
FAVOR+
通过上述的分解可以得到线性(而非二次)空间复杂度隐式注意力矩阵。同样,通过分解可以获得线性时间的注意力机制。原有的方式是注意力矩阵与value输入相乘得到最终结果,但在分解注意力矩阵之后,可以重新排列矩阵乘法来近似常规注意力机制的结果,而无需显式地构建二次方尺寸的注意力矩阵。最终生成了新算法 FAVOR+。
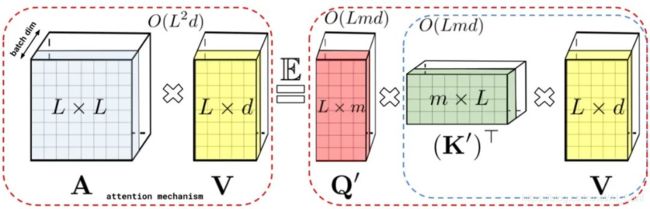
左:标准的注意力模块,最终结果是由注意力矩阵A和value向量进行矩阵乘法而得到。右:对注意力矩阵A低秩分解得到解耦矩阵Q′和K′,并按照虚线框表示的顺序进行矩阵乘法。如此可以得到线性的注意力机制,而无需明确地构造注意力矩阵A或其近似。
上述分析是双向注意力(即非因果注意力),并没有区分 past 和 future的部分。那么如何做到让输入序列中只注意到其中一部分,即单向的因果注意力?只需使用前缀和计算(prefix-sum computation),在计算过程只存储矩阵计算的运行总数,而不存储完整的下三角常规注意力矩阵。
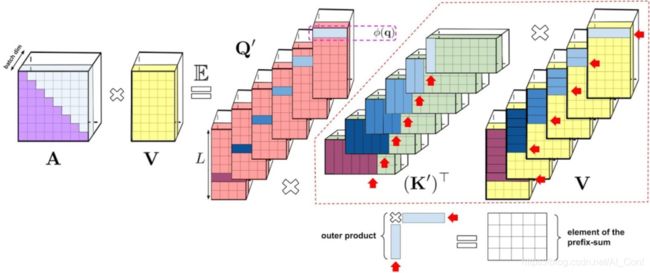
左:标准的单向注意机制,需要对注意矩阵进行mask操作来得到下三角部分矩阵。右:在LHS上的无偏近似可以通过前缀和来获得。key向量和value向量的随机特征映射进行外积,得到的前缀和,且这个过程是动态构建的。最后将随机特征向量与query左乘得到最终矩阵中的新行。
实验结果
对 Performer 的空间和时间复杂度进行基准测试,实验结果表明,注意力机制的加速比和内存减少在实证的角度上近乎最优,也就是说,这非常接近在模型中根本不使用注意力机制的情况。
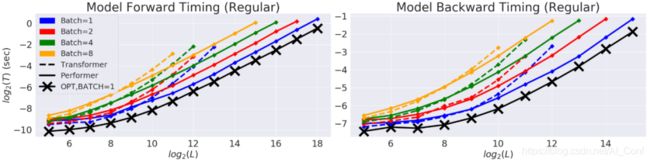
在以时间(T)和长度(L)为度量的双对数坐标轴中,常规 Transformer 模型的双向 timing。行方向的终点是GPU内存的极限。黑线(X)表示使用 "虚"注意力块时可能的最大内存压缩和加速,它基本上绕过了注意力计算,代表着模型可能的最大效率。Performer模型在注意力部分几乎能够达到这种最佳性能。
文章进一步证明使用无偏 softmax 近似的Performer 模型,在微调之后可以向后兼容预训练 Transformer 模型,从而在提升推理速度的同时降低能耗,且无需完全重新训练已有的模型。
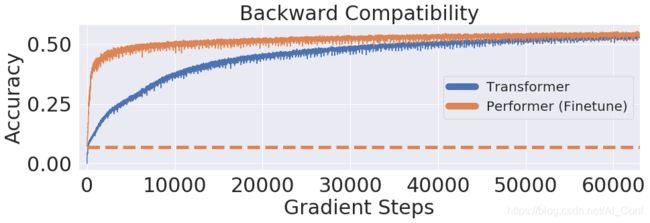
使用 One Billion Word Benchmark(LM1B)数据集,将原始预训练的Transformer权重直接迁移到Performer模型中,这个初始结果的精度是0.07(橙色虚线)。经过微调,Performer 的精度在很少的梯度步数之后就迅速恢复了。
至于Performer在蛋白质建模上的应用实例,感兴趣的读者可以继续翻阅原文。
总结
Performer有助于改进基于非稀疏注意力和基于核方法的Transformer,这种方法也可以与其他技术如可逆层一起搭配使用。研究人员不仅开放了Reformer的代码,还将[Reformer集成到FAVOR中,此外还提供了蛋白质语言模型的代码。Performer在Attention、Transformer架构甚至Kernel开辟了一条新的研究思路,对后续进一步的改进有巨大的启示作用。
