Transformer提效之路干货笔记——一文梳理各种魔改版本Transformer
每天给你送来NLP技术干货!
来自:圆圆的算法笔记
Transformer目前已经成为NLP领域的主流模型,Bert、GPT都是基于Transformer模型结构。同时,Transformer在CV领域也逐渐取得大范围的应用。对Transformer模型结构的深入细致了解非常必要。然而,Transformer的Attention计算代价较高,随着序列长度的增加计算量显著提升。因此,业内出现了很多Transformer魔改工作,以优化Transformer的运行效率。本文首先介绍了Transformer模型的基本结构,然后详细介绍了9篇针对Transformer效率优化、长序列建模优化的顶会论文。
Transformer基本原理
Transformer是由Attention Is All You Need(NIPS 2017)这篇论文中提出的,这篇论文提出的原始模型是一个Encoder-Decoder结构,后来的GPT等模型沿用了该结构,而Bert只用了Encoder部分。下面我们对这篇文章介绍的基础Transformer结构进行详细介绍。如果对Transformer结构已经非常了解的同学,可以直接看第二节对Transformer效率优化工作的汇总。
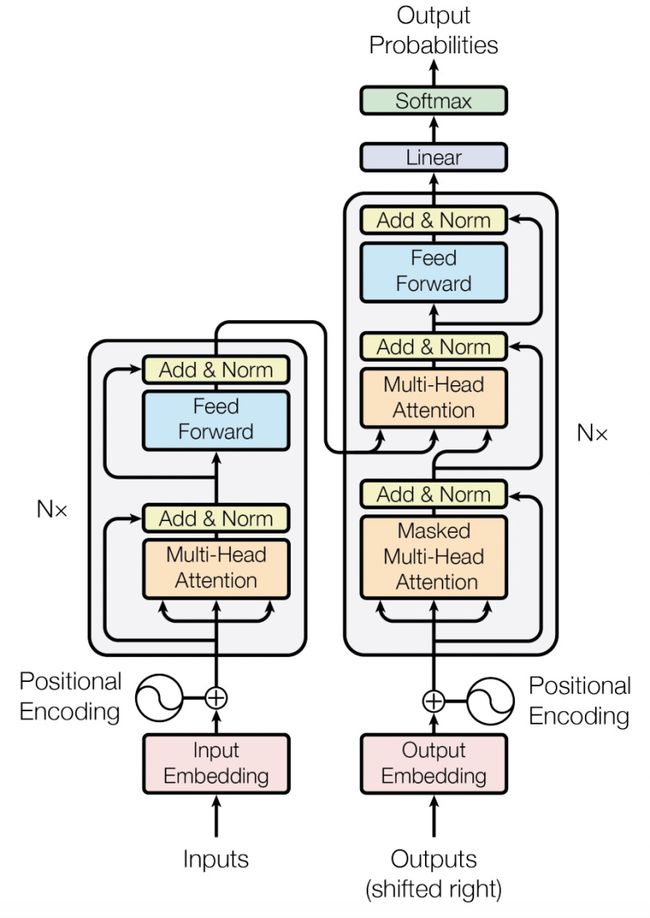
Transformer的整体结构如下图所示,分为Encoder、Decoder两个部分。我们来看一下输入数据是怎么在模型中流转的。
输入:假设输入序列长度为T,则Encoder输入的维度为[batch_size, T],经过embedding层、position encoding等流程后,生成[batch_size, T, D]的数据,D表示模型隐层维度;
Encoder:这个数据会经过N个模块,每个模块的结构都是相同的,为Multi-head Attention->Add->LayerNorm->Feed Forward->Add->LayerNorm。Multi-head Attention在T这个维度上,计算每两个位置元素的Attention值,会汇聚再次得到每个位置的Embedding,输出维度仍然为[batch_size, T, D]。Add层将Multi-head Attention的输出结果和输入结果相加,类似于一个残差网络。Feed Forward会用一个比较大的中间层维度将上一层的隐藏维度扩大,然后再缩小,如用一个全连接从[batch_size, T, D]变为[batch_size, T, 4*D],再变回到[batch_size, T, D],主要为了增加模型容量。最终经过N个模块,Encoder的输出维度仍然为[batch_size, T, D]。
Decoder:Decoder的输入也经过类似的变换得到[batch_size, T', D],T'是Decoder输入长度。之后会进入多个相同结果的模块,每个模块为Self Multi-head Attention->Add->LayerNorm->Cross Multi-head Attention->Add->LayerNorm->Feed Forward->Add Norm。Self Multi-head Attention,表示Decoder序列上的元素内部做Attention,和Encoder是一样的。Cross Multi-head Attention,是Decoder每个位置和Encoder各个位置进行Attention,类似于传统的seq2seq中的Attention,用来进行Decoder和Encoder的对齐。
下面我们重点介绍一下Transformer结构的核心部分:多头注意力机制。其实多头注意力机制并不复杂,主要就是下面这个公式:
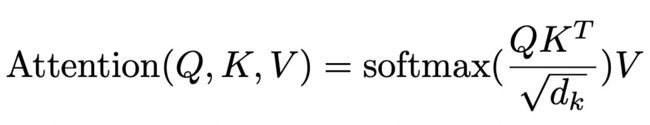
输入假设是[batch_size, T, D],首先将它用3个不同的全连接映射成Q、K、V三个不同的向量,维度仍然为[batch_size, T, D]。然后假设有k个head,那么我们将向量转换维度:[batch_size, T, D] -> [batch_size, T, k, D/k] -> [batch_size, k, T, D/k],这相当于把后续的Attention分别做k次,同时又没有增加模型的隐藏维度带来计算开销增大。然后就套用上面的公式,pair对进行Q和K的点积计算+softmax得到attention分,再和V相乘得到每个位置元素的结果。我们来看一下代码的实现,传入的是经过全连接和head变化处理好的Q、K、V,维度都是[batch_size, k, T, D/k]。另外一个需要注意的点为什么要除以根号dk,因为Q和K的内积结果,随着其维度变大,方差会变大,进而可能会出现很大的值,除以根号dk保证输出结果的不会出现过大值,这个在原论文中是有说明注解的。
def scaled_dot_product_attention(q, k, v, mask):
matmul_qk = tf.matmul(q, k, transpose_b=True)
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.sqrt(dk)
if mask is not None:
scaled_attention_logits += (mask * -1e9)
attention_weights = tf.nn.softmax(scaled_attention_logits)
output = tf.matmul(attention_weights, v)
return output, attention_weights了解了Transformer基本结构之后,我们下面通过9篇顶会文章,进一步深入学习Transformer模型如果进行效率优化,以及如果适用于长序列、长文本建模。
稀疏Attention提升运行效率
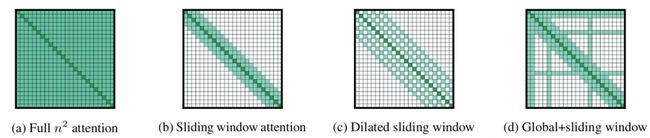
Longformer: The Long-Document Transformer(2020)提出了另一种思路,它们关注于如何让Transformer的时间复杂度随序列长度指数增长转换为线性增长。Longformer的主要思路是设计稀疏的Attention,包括下图三种形式。其中sliding wondow attention表示每个token只跟附近窗口内的w个token进行attention;diliated sliding wondow类似于空洞卷积,和附近w个token进行attention时会每隔几个元素进行一次attention;global attention用于某些特殊token如Bert中的[CLS],或人工先验确定的。通过综合这三种Attention方式,实现了最大程度保证Attention质量,同时又将Transformer时间复杂度转换为和序列长度线性相关的。
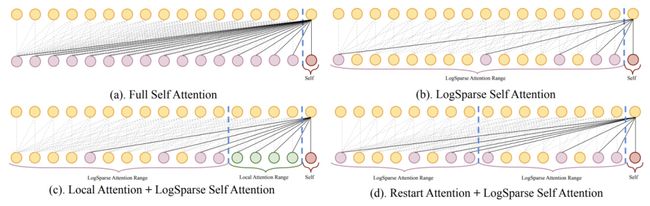
与Longformer类似的一篇文章是Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting(NIPS 2019)。这篇工作也是设计稀疏的Attention。本文提出了LogSparse Attention,每个元素和之前元素Attention的时候,只选择间隔1、2、4、8等的元素。同时增加了Local Attention和Restart,前者指的是对于附近的几个元素不用LogSparse,增强附近元素对当前点的影响(因为这篇工作主要应用于时间序列,因此着重考虑了附近时间的值对当前的影响),Restart指的是每隔一定长度就重新进行LogSparse的间隔计算。
Adaptive Attention Span in Transformers(2019)提出使用模型来学习每个元素的attention窗口范围。一种基本的方法是,当Q和K进行attention时,传入Q和K的位置差,然后根据这个位置差计算这两个元素Attention的权重,基本思路是离当前元素越近,权重越大,函数形式和图像如下:

其中,z可以根据每个元素个性化的计算,即每个位置的元素都会计算一下从哪个元素开始attention的权重递减。可以使用一个NN网络,输入当前元素的特征,拟合z的值。本文针对不同的head、不同位置的输入,都进行了个性化的attention权重生成,并通过后面实验验证了这种方法实现了稀疏attention,提升运行效率。
针对长文本的Transformer应用
由Transformer运行开销随着序列长度增加而指数增长,因此如果想将Transformer应用到长文本上,直接对全部整体计算Attention是不现实的。假设输入序列长度为T,则模型每层的时间复杂度和存储使用量都是O(L*L)。一种简单的做法是,在训练阶段将长文本分割成一些符合要求的短文本,对每个短文本分别建模,实现运行效率提升;在预测阶段,每次传入一个固定长度的序列,并一个一个step向后移动,预测多次,如下图所示。
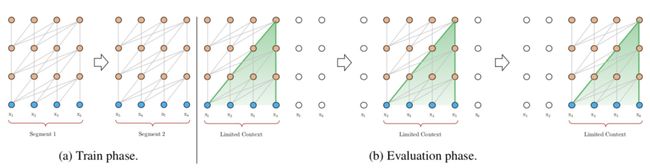
然而,这种方法忽略了长文本中不同片段之间的关系,也限制了Attention所能建模的最大长度,必然会影响模型效果。同时在预测阶段,运算量非常大,因为每次要移动一个元素重新计算,每一个位置的元素都要在多个片段内倍计算多次,效率很低。为了让Transformer更好的应用到长文本中,Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context(ACL 2019)提出了Transformer-XL模型,其主要思路是在下一个片段的预测会依赖上一个片段的编码结果,建立了片段之间的信息交互。这个过程可以用下面的公式和示意图表示,公式中的第一行表示使用上一个segment的信息和当前segment信息拼接,同时上一个segment的信息不会进行梯度更新。这样当前片段在计算Q、K、V的时候就会考虑上一个片段的信息了。
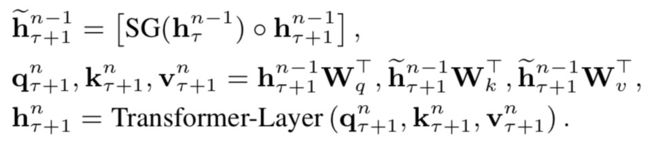
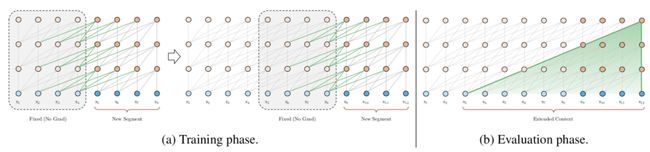
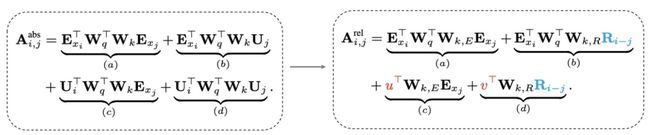
另一个需要解决的问题是,如果让两个segment进行信息交互,但是这两个segment对应的position embedding对应位置都是一样的,这显然是不合理的,第二个segment和第一个segment是存在位置差异的。为了解决这个问题,Transformer-XL提出了一种新的相对位置编码方法。在Transformer核心公式中,QK^T可以表示为如下形式:

下图中,当xi作为query去索引作为key的xj时候,左侧为传统Transformer计算attention score的分解结果(E是embedding,W是q、k对应的全连接映射,U是position embedding)。本文将其进行了一个转换,首先用R代替了U,U固定位置embedding,而R是衡量i和j距离的相对embedding,比如i和j距离5,那么i和j的相对位置embedding就用5对应的embedding值。同时,本文认为query去索引的时候,query向量本身是相同的,因此无论query位置如何,对不同词的注意偏差都保持一致。
Transformer的运行效率优化
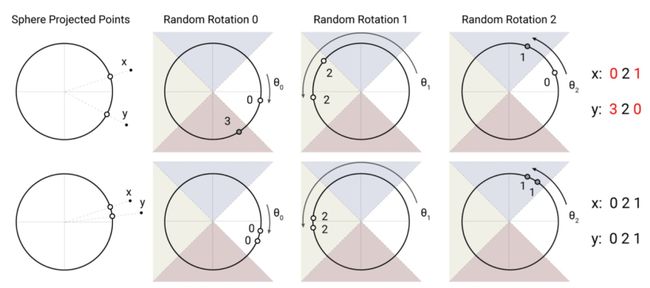
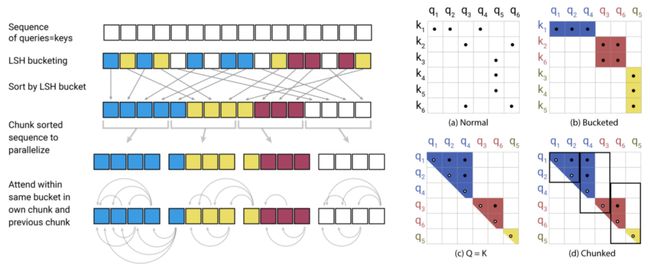
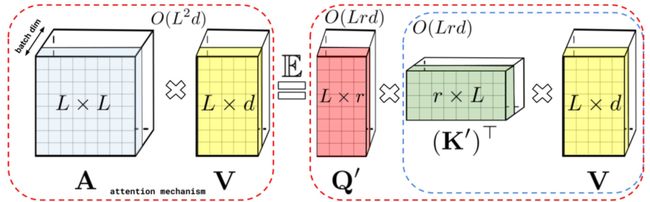
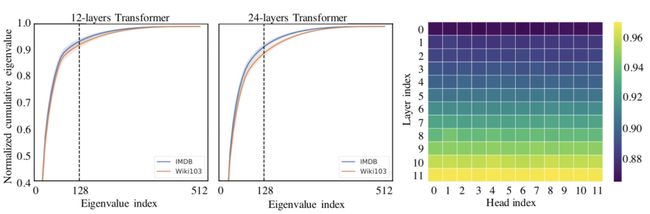
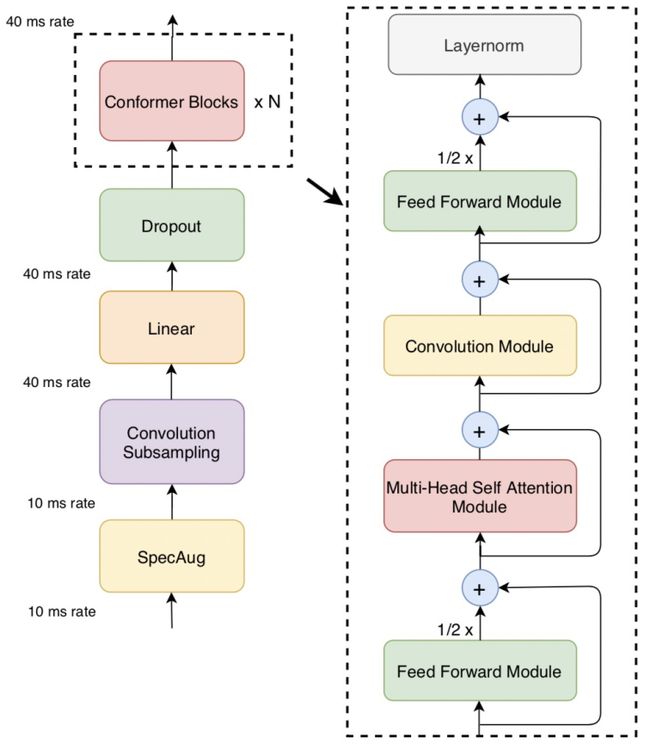
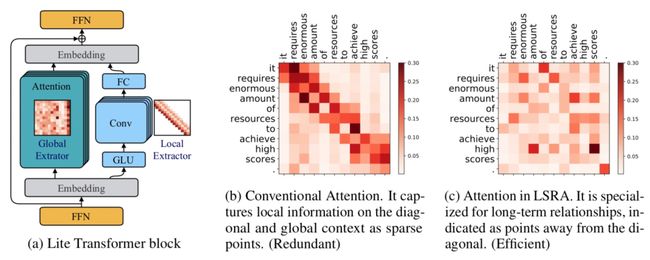
REFORMER: THE EFFICIENT TRANSFORMER(ICLR 2020)提出了采用局部敏感哈希的方法提升Transformer效率。当序列较长时,QK^T的维度[batch_size, L, L]的计算量和存储开销会非常大,但是由于我们关注的是softmax后的结果,并不关注QK^T本身是什么,而softmax只关注值最大的几个元素,因此我们可以只选择k< 本文采用的拒不敏感哈希如下图,进行多次旋转后,如果两个点离得很近,那么大概率多次旋转后都在同一个区域;如果两个点离得很远,那么在多次旋转后所在的区域大概率不会完全一致。 局部敏感哈希Attention的一个过程图如下,首先利用局部敏感哈希对序列进行分桶,然后将同一个桶内的元素重新排列顺序,在桶内进行正常的Attention。此外,Reformer还将Q和K的全连接映射函数共享,进一步减小了模型参数量,同时发现模型效果并没有因此降低。 RETHINKING ATTENTION WITH PERFORMERS(ICLR 2021)提出了Performer模型,通过改变Attention部分的计算方式来提升计算效率。如下图,在一般的Attention中,首先要进行Q和K的矩阵运算得到A,时间复杂度为O(L*L),然后再和V相乘,时间复杂度总共为O(L*L*d)。本文提出,将A近似映射成一个Q'和K'的乘积,然后先计算K'和V的矩阵乘法,在计算Q'和前者的乘法,这样时间复杂度就变成O(L*r*d)了。那么问题的关键就是如何寻找Q'和K’了。 文中寻找到了映射方法,如下图,矩阵A中的第(i, j)个元素可以表示成相应q和k的内积,而之前的一篇研究中有将这种形式的函数变成两个向量内积的形式,进而就找到了对应的映射函数,文中后续又对这个近似进行了一些稳定性优化。 Linformer: Self-Attention with Linear Complexity(2020)提出了一种线性时间复杂度和空间复杂度的Transformer模型。首先,本文利用奇异值分解对Roberta中各个层的Attention矩阵进行分析,发现特征值是非常明显的长尾分布,值比较大的特征值只有几个,大部分特征值都很小。这表明,只需要用少数的最大的特征值就能近似还原Attention矩阵中的大部分信息。此外,越接近输出的层,前128、512个奇异值的和占比越大。这个分析的结果如下图。 一种方法是使用SVD分解,取前k个最大的特征值对应的特征向量组成Attention矩阵的近似,如下: 但是这种方法的问题在于需要进行额外的SVD计算,增加的计算复杂度。因此,本文提出将K和V进行一步映射后再进行Attention。将原来的Attention计算方法使用两个映射E、F转换成如下形式: 其中E、F分别将K、V从[T, d]映射拆成[k, d]。这样计算复杂度从原来的O(T*T)下降为O(k*T),当k远小于T的时候即近似为线性时间和空间复杂度。 卷积与Attention的融合 Conformer: Convolution-augmented Transformer for Speech Recognition(2020)提出用卷积来提升Transformer效果,融合卷积提取局部信息的优势和Transformer提取全局信息的优势。具体的做法也比较直观,利用一层Multi-head Attention加上一层卷积的嵌套方式来实现,具体结构如下图。 LITE TRANSFORMER WITH LONG-SHORT RANGE ATTENTION(ICLR 2020)提出了另一个融合卷积和Attention的工作。通过Attention的热力图发现,Attention矩阵的结构具有稀疏性,并且对角线附近的分值较高。前者表明Attention会学习一些global的稀疏关系,后者表示Attention会学习local的关系。本文提出,可以让原来的Transformer专注于提取全局关系,而增加一个卷积模块,并行提取局部关系。FFN的输出会被分成两半,一半输入到原来的Transfomer中(提取global信息),另一半输入到一个卷积层(提取local信息),这样Transformer部分的计算复杂度缩小了一半。同时让卷积部分可以提取local信息,让Transformer部分专注于提取global信息。从下图中的c也可以看出,增加了卷积模块后,Transformer的attention矩阵没有了对角线附近的local信息提取,而是侧重于global信息的提取。 总结 本文介绍了Transformer的基本原理,随后深入介绍了9篇近年来顶会对Transformer的改进,帮助大家全方位了解Transformer模型原理和最近业内的针对Transformer的改进工作。 !!!轻松找工作 - 建立了一个专门找工作的内推群 最近文章 EMNLP 2022 和 COLING 2022,投哪个会议比较好? 一种全新易用的基于Word-Word关系的NER统一模型,刷新了14种数据集并达到新SoTA 阿里+北大 | 在梯度上做简单mask竟有如此的神奇效果 投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。 方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。 记得备注呦
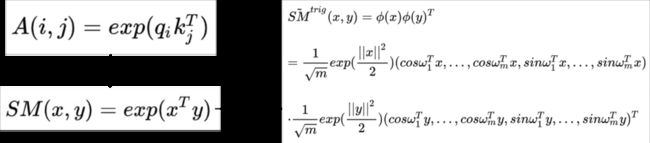


下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】

整理不易,还望给个在看