Hadoop---(2)MapReduce(分布式计算编程模型)
2. MapReduce
MapReduce:是一种分布式计算编程模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题。
MR由两个阶段组成:MapReduce,用户只需要实现map()和reduce()两个函数几科实现分布式计算。
这两个函数的形参是key,value对,表示函数的输入信息。
2.1MapReduce的构架
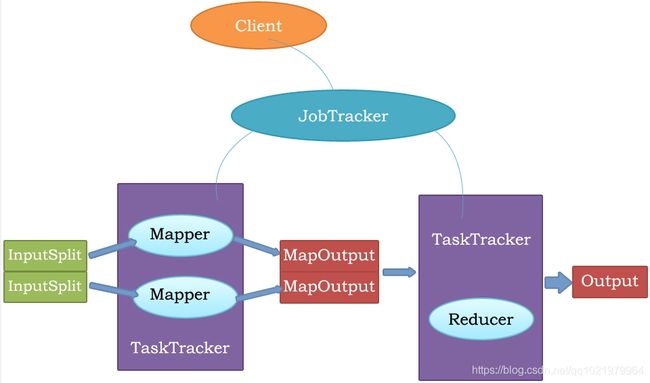
主从结构:
主节点,只有一个:JobTracker
从节点,有很多个:TaskTracker
JobTracker负责:
接收客户提交的计算任务
把计算任务分给TaskTracker执行
监控TaskTracker
TaskTracker负责:
执行JobTracker分配的计算任务
2.2 MapReduce执行流程
2.3 MapReduce原理

执行步骤:
- map任务处理
- 读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数。
- 写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
- 对输出的key、value进行分区。
- 对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中。
- (可选)分组后的数据进行归约,使用Combiner。
- Reduce任务处理
- 对多个map任务的输出,按照不同的分区,通过网络copy到不用的reduce节点。
- 对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value。
- 把reduce的输出保存到文件中。
MapReduce键值对格式

2.4 JobTracker
JobTracker负责接收用户提交的作业,负责启动弄、跟踪任务执行。
JobSubmissionProtocol是JobClient与JobTracker通信的接口。
InterTrackerProtocol是TaskTracker与JobTracker通信的接口。
2.5 TaskTracker
TaskTracker负责执行任务。
2.6 JobClient
是用户作业与JobTracker交互的主要接口。
负责提交作业的,负责启动、跟踪任务执行、访问任务状态和日志等。

2.7 最小的MapReduce驱动
Configuration configuration = new Configuration();
Job job = new Job(configuration, "HelloWorld");
job.setInputFormat(TextInputFormat.class);
job.setMapperClass(IdentityMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setPartitionerClass(HashPartitioner.class);
job.setNumReduceTasks(1);
job.setReducerClass(IdentityReducer.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class);
job.setOutputFormat(TextOutputFormat.class);
job.waitForCompletion(true);
2.8 MapReduce驱动默认的设置

2.9 序列化
2.9.1 序列化概念
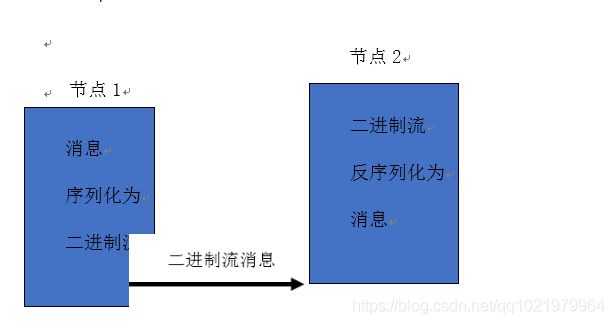
序列化(Serizlization)是指把结构化对象转化为字节流。
反序列化(Deserialization)是序列化的逆过程。即把字节流转回结构化对象。
Java序列化(java.io.Serializable)
2.9.2 Hadoop序列化的特点
序列化格式特点:
- 紧凑:高效实用存储空间。
- 快速:读写数据的额外开销小。
- 可扩展:可透明地读取老格式的数据。
- 互操作:支持多语言的交互。
Hadoop的序列化格式:Writable
2.9.3 Hadoop序列化的作用
Hadoop序列化的作用:序列化在分布式环境的两大作用:进程间通信,永久存储。
Hadoop节点间通信。
2.10 Writable接口
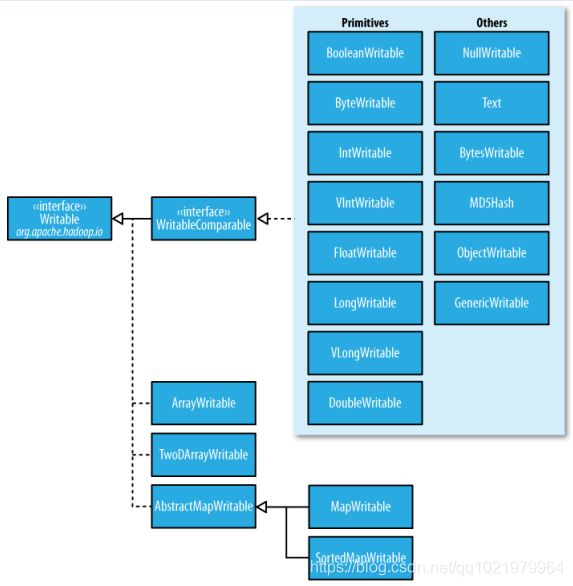
Writable接口,是根据DataInput和DataOutput实现的简单、有效的序列化对象。
MR的任意Key和Value必须实现Writable接口。
MR的任意key必须实现WritableComparable接口
2.10.1 常用的Writable实现类
Text一般认为它等价于java.lang.String的Writable。针对UTF-8序列。
例如:
Text t = new Text(“t”);
IntWritable one = new IntWritable(1);

Writable
- Write是把每个对象序列化到输出流
- readFields是把输入流字节反序列化
实现WritableComparable
Java值对象的比较:一般需要重写toString(),hashCode(),equals()方法
2.10.2 实现Writable示例
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
/**
* 示例:
*
* @author caonanqing
*
*/
public class DataBean implements Writable {
private String telNo;
private long upPayLoad;
private long downPayLoad;
private long totalPayLoad;
public DataBean() {
}
public DataBean(String telNo, long upPayLoad, long downPayLoad) {
super();
this.telNo = telNo;
this.upPayLoad = upPayLoad;
this.downPayLoad = downPayLoad;
this.totalPayLoad = upPayLoad + downPayLoad;
}
@Override
public String toString() {
return this.upPayLoad + "\t" + this.downPayLoad + "\t" + this.totalPayLoad;
}
/**
* 序列化 注意:1.类型 2.顺序
*/
public void write(DataOutput out) throws IOException {
out.writeUTF(telNo);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
out.writeLong(totalPayLoad);
}
/**
* 反序列化
*/
public void readFields(DataInput in) throws IOException {
this.telNo = in.readUTF();
this.upPayLoad = in.readLong();
this.downPayLoad = in.readLong();
this.totalPayLoad = in.readLong();
}
public String getTelNo() {
return telNo;
}
public void setTelNo(String telNo) {
this.telNo = telNo;
}
public long getUpPayLoad() {
return upPayLoad;
}
public void setUpPayLoad(long upPayLoad) {
this.upPayLoad = upPayLoad;
}
public long getDownPayLoad() {
return downPayLoad;
}
public void setDownPayLoad(long downPayLoad) {
this.downPayLoad = downPayLoad;
}
public long getTotalPayLoad() {
return totalPayLoad;
}
public void setTotalPayLoad(long totalPayLoad) {
this.totalPayLoad = totalPayLoad;
}
}
基于文件的存储结构
SequenceFile:无序存储。
MapFile会对key建立索引文件,value按key顺序存储。
基于MapFile的结构有:
ArrayFile:像数组一样,key值为序列化的数字。
SetFile:只有key,value为不可变的数据。
BloomMapFile:在MapFile的基础上增加了一个/bloom文件,包含的是二进制的过滤表,在每一次写操作完成时,会更新这个过滤表。
2.11 MapReduce输入的处理类
2.11.1 FileInputFormat
FileInputFormat:是所有以文件作为数据源的InputFormat实现的基类,FileInputFormat保存作为job输入的所有文件,并实现了对输入文件计算splits的方法。至于获得记录的方法是有不同的子类--------TextInputFormat
2.11.2 InputFormat
InputFormat负责处理MR的输入部分。
有三个作用:
- 验证作业的输入是否规范。
- 把输入文件切分成InputSplit。
- 提供RecordReader的实现类,把InputSplit读到Mapper中进行处理。
- 在执行mapreduce之前,原始数据被分割成若干split,每个split作为一个mapr任务的输入,在map执行过程中split会被分解成一个个记录(key-value对),map会依次处理每一个记录。
- FileInputFormat只划分比HDFS block大的文件,所以FileInputFormat划分的结果是这个文件或者是这个文件中的一部分。
- 如果一个文件的大小比block小,将不会划分,这也是Hadoop处理大文件的效率要比处理很多小文件的效率高的原因。
- 当hadoop处理很多小文件(文件大小小于hdfs block大小)的时候,由于FileInputFormat不会对小文件进行划分,所以每个小文件都会被当做一个split并分配一个map任务,导致效率低下。
例如:1G的文件会被划分成16个64MB的split,并分配16个map任务处理,而10000个100kb的文件会被10000个map任务处理,所以不适合处理大量小文件的数据。
2.11.3 TextInputFormat
TextInputFormat是默认的处理类,处理普通的文本文件。
文件中每一行作为一个记录,他将每一行在文件中的起始偏移量作为key,每一行的内容作为value。
默认以\n或回车键作为一行记录。
TextInputFormat继承了FileInputFormat
2.11.4 InputFormat类的层次结构

2.11.5 其他输入类
CombineFileInputFormat
相对于大量的小文件来说,hadoop更加适合处理少量的大文件。
CombineFileInputFormat可以缓解这个问题,它是针对小文件而设计的。
KeyValueTextInputFormat
当输入数据的每一行是两列,并用tab分离的形式的时候,KeyValueTextInputFormat处理这种格式的文件非常适合。
NLineInputFormat
可以控制在每个split中数据的行数。
SequenceFileInputFormat
当输入文件格式是sequenceFile的时候,要使用SequenceFileInputFormat作为输入。
2.11.6 自定义输入格式
- 继承FileInputFormat基类
- 重写里面的getSplits(JobContext context)方法。
- 重写createRecordReader(InputSplit split,TaskAttemptContext context)方法
//案例:定义输入格式,作为二进制输入
//1.重写FileInputFormat
package com.saviation.mapreduce;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.mapred.FileSplit;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
/**
* 重写输入格式,作为二进制输入
* @author caonanqing
*
*/
public class TrackFileInputFormat extends FileInputFormat {
private static final double SPLIT_SLOP=1.1;
// 判断当前文件是否可以分块,ture为可以分块,false为不可以分块
protected boolean isSplitable(Configuration conf, Path path ){
return true;
}
/**
* MapReduce的客户端调用此方法得到的所有分块,然后将分块发送给MapReduce服务端,
* 注意,分块中不包含实际的信息,而只是对实际信息的分块信息。具体来说,每个分块中包含分块对应的文件路径,
* 当前分块在该文件中起始位置,当前分块的长度以及对应的实际数据所有的机器列表,在实现这个函数时,将这些信息填上即可。
* @param conf
* @return
* @throws IOException
*/
public List getSplits(Configuration conf) throws IOException {
List splits = new ArrayList();
long minSplitSize = conf.getLong("mapred.min.split.size", 1); // 最小切片
long maxSplitSize = conf.getLong("mapred.max.split.size", 1); // 最大切片
long blockSize = conf.getLong("dfs.block.size", 1); // block块大小
long splitSize = Math.max(minSplitSize, Math.min(maxSplitSize, blockSize)); // 切片大小
FileSystem fs = FileSystem.get(conf);
String path = conf.get(INPUT_DIR); // 获取路径
FileStatus[] files = fs.listStatus(new Path(path));
for(int fileIndex = 0; fileIndex < files.length; fileIndex++){
FileStatus file = files[fileIndex];
System.out.println("input file: " + file.getPath().toString());
long length = file.getLen();
FileSystem fsin = file.getPath().getFileSystem(conf);
BlockLocation[] blockLocations = fsin.getFileBlockLocations(file,0,length);
if((length!=0) && isSplitable(conf, file.getPath())){
long bytesRemaining = length;
while(((double)bytesRemaining/splitSize > SPLIT_SLOP)){
int blkIndex = getBlockIndex(blockLocations,length-bytesRemaining);
splits.add(new FileSplit(file.getPath(),length-bytesRemaining,splitSize,blockLocations[blkIndex].getHosts()));
bytesRemaining -= splitSize;
}
if(bytesRemaining != 0){
splits.add(new FileSplit(file.getPath(),length-bytesRemaining,bytesRemaining,blockLocations[blockLocations.length - 1].getHosts()));
}
}else if(length != 0){
splits.add(new FileSplit(file.getPath(),0,length,blockLocations[0].getHosts()));
}else{
splits.add(new FileSplit(file.getPath(),0,length, new String[0]));
}
}
return splits;
}
/**
* 类RecordReader是用来创建传给map函数的key-value序列,传给此类的参数有两个:一个分块split和作业的配置信息context
* 在mapper的run函数中可以看到mapreduce框架执行的map逻辑
* 调用recordReader方法中nextKeyValue,生成新的键值对。如果当前分块split中已经处理完毕,则nextKeyValue会返回false。退出run函数
*/
public RecordReader createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
TrackRecordReader reader = new TrackRecordReader();
reader.initialize(split, context);
return reader;
}
}
//2.重写RecordReader
package com.saviation.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
/**
* 打开文件,将文件字节存到value
* @author caonanqing
*
*/
public class TrackRecordReader extends RecordReader {
private FSDataInputStream inputStream = null; // 文件操作
private long start,end,pos; //起始位置,结束位置,使用长度
private Configuration conf;
private FileSplit fileSplit;
private Text key = null;
private BytesWritable value = null;
private boolean processed = false;
/**
* 进行初始化,打开文件流,根据分块信息设置起始位置,结束位置和长度等
*/
@Override
public void initialize(InputSplit inputSplit, TaskAttemptContext context)
throws IOException, InterruptedException {
fileSplit = (FileSplit)inputSplit;
conf = context.getConfiguration();
this.start = fileSplit.getStart(); // 设置起始位置
this.end = this.start + fileSplit.getLength(); // 设置结束位置
try{
//获取分片文件对应的完整文件
Path path = fileSplit.getPath();
FileSystem fs = path.getFileSystem(conf);
this.inputStream = fs.open(path); // 打开文件
inputStream.seek(this.start); // 设置已读取长度
this.pos = this.start;
}catch(IOException e ){
e.printStackTrace();
}
}
/**
* 生成下一个键对值
*/
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if(this.pos < this.end){
this.key = new Text(fileSplit.getPath().getName()); // 获取文件名称作为key
byte[] bytes = new byte[(int) fileSplit.getLength()];
IOUtils.readFully(this.inputStream, bytes, 0, bytes.length);
this.value = new BytesWritable(bytes);// 获取字节作为value
this.pos = inputStream.getPos();
return true;
}else{
processed = true;
return false;
}
}
/**
* 获取当前key
*/
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
return key;
}
/**
* 获取当前value
*/
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
return value;
}
/**
* 获取处理进度
*/
@Override
public float getProgress() throws IOException, InterruptedException {
return ((processed == true) ? 1.0f : 0.0f);
}
/**
* 关闭文件流
*/
@Override
public void close() throws IOException {
try{
if(inputStream != null){
inputStream.close();
}
}catch(IOException e){
e.printStackTrace();
}
}
}
//3.Mapper映射类
public class TrackMapper extends Mapper {
@Override
protected void map(Object key, BytesWritable value, Context context)
throws IOException, InterruptedException {
byte[] b2 = value.getBytes();
long len = b2.length; // 总的字节数
context.write(new Text(""),new Text(s));
}
}
//4.Reduce归约类
public class TrackReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Reducer.Context context) throws IOException, InterruptedException {
//普通解析
for(Text v : values){
System.out.println();
context.write(key, v);
}
}
}
//5.Driver驱动类
/**
* mapreduce主函数
* @author caonanqing
*
*/
public class TrackDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] newArgs = new String[]{"hdfs://namenode:9000/track/track_input/20180401.ZNDQ",
"hdfs://namenode:9000/track/track_out1"};
String[] otherArgs = new GenericOptionsParser(conf, newArgs).getRemainingArgs();
Job job = Job.getInstance(conf, "TrackDriver"); //启动job,并给job起个名称
job.setJarByClass(TrackDriver.class); //主函数
job.setInputFormatClass(TrackFileInputFormat.class); //重写输入格式
job.setMapOutputKeyClass(Text.class); //map输出key
job.setMapOutputValueClass(Text.class); //map输出value
job.setMapperClass(TrackMapper.class); //map函数
job.setCombinerClass(TrackCombiner.class); //combiner,本地合并
job.setReducerClass(TrackReducer.class); //reduce函数
job.setOutputKeyClass(Text.class); //reduce输出key
job.setOutputValueClass(Text.class); //redecu输出value
FileInputFormat.setInputPaths(job, new Path(newArgs[0])); //输入文件路径
FileOutputFormat.setOutputPath(job, new Path(newArgs[1])); //输出文件路径
if (!job.waitForCompletion(true))
return;
}
}
2.12 MapReduce输出的处理类
TextOutputFormat
默认的输出格式,key和value中间值用tab隔开的。
SequenceFileOutputFormat
将key和value以sequencefile格式输出
SequenceFileAsOutputFormat
将key和value以原始的二进制格式输出
MapFileOutFormat
将key和value写入MapFile中,由于MapFile中的key是有序的,都有写入的时候必须保证记录是按key值顺序写入的。
MultipleOutputFormat
默认情况下一个reduce会产生一个输出,但是有些时候我们想一个reduce产生多个输出,MultipleOutputFormat和MultipleOutputs可以实现这个功能。
2.13 计数器
Hadoop计数器:可以让开发人员以全局的视角来审查程序的运行情况以及各项指标,及时做出错误诊断并进行相应处理。
内置计数器(MapReduce相关、文件系统相关和作业调度相关)
可以通过Master:50030/jobdetails.jsp查看
例子:Hello you,hello me 的计数器信息
Counters: 19
File Output Format Counters
Bytes Written=19 //reduce输出到hdfs的字节数
FileSystemCounters
FILE_BYTES_READ=481
HDFS_BYTES_READ=38
FILE_BYTES_WRITTEN=81316
HDFS_BYTES_WRITTEN=19
File Input Format Counters
Bytes Read=19 //map从hdfs读取的字节数
Map-Reduce Framework
Map output materialized bytes=49
Map input records=2 //map读入的记录行数
Reduce shuffle bytes=0
Spilled Records=8
Map output bytes=35
Total committed heap usage (bytes)=266469376
SPLIT_RAW_BYTES=105
Combine input records=0
Reduce input records=4 //reduce从map端接收的记录行数
Reduce input groups=3 //reduce函数接收的key数量,即归并后的k2数量
Combine output records=0
Reduce output records=3 //reduce输出的记录行数
Map output records=4 //map输出的记录行数
2.13.1 自定义计数器与实现
Context类调用方法getCounter()
计数器声明
1.通过枚举声明
context.getCounter(Enum enum)
2.动态声明
context.getCounter(String groupName,String counterName)
计数器操作
counter.setValue(long value);//设置初始值
counter.increment(long incr);//增加计数
org.apache.hadoop.mapreduce.Counter
2.14 Combiners编程
每一个map可以会产生大量的输出,combiner的作用就是在map端对输出先做一次合并,以减少传输到Reduce的数据量。
Combiner最基本是实现本地key的归并,Combiner具有类似本地的Reduce功能。
如果不用Combiner,那么,所有的结果都是在Reduce完成,效率会相对低下。使用Combiner,先完成的map会在本地聚合,提升速度。
注意:Combiner的输出是Reduce的输入,Combiner决不能改变最终的计算结果,所以Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如:累加,最大值。
2.15 Partitioner编程
Partitioner是partitioner的基类,如果需要定制partitioner也需要继承该类。
HashPartitioner是MapReduce的默认Partitioner。计算方法是
which reduce= (key.hashCode() & Integer.Max_VALUE) % numReduceTasks
得到当前的数目的reduce。
2.16 排序和分组
在Map和Reduce阶段进行排序时,比较的是k2。v2是不参与排序比较的。如果要想让v2也进行排序,需要把k2和v2组装成新的类,作为k2,才能参与比较。
分组时也是按照k2进行比较的。
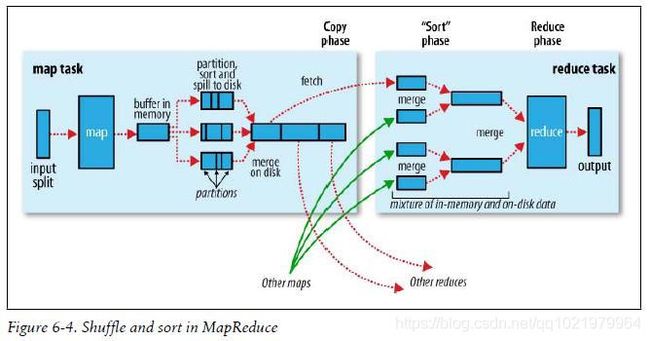
2.17 Shuffle
Map:
- 每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小为100MB(io.sort.mb),一旦达到阈值0.8(io.sort.spill.percent),一个后台线程把内容写到(spill)磁盘的指定目录,(mapred.local.dir)下的新建的一个溢出写文件。
- 写磁盘前,要partition,sort。如果有Combiner,Combiner排序后数据。
- 等最后记录写完,合并全部溢出写文件为一个分区且排序的文件。
Reduce:
- Reduce通过Http方式得到输出文件的分区。
- TaskTracker为分区文件运行Reduce任务。复制阶段吧Map输出复制到Reduce的内存或磁盘。一个Map任务完成,Reduce就开始复制输出。
- 排序阶段合并map输出,然后走Reduce阶段。
2.18 Hadoop的压缩codec
Codec为压缩,解压缩的算法实现。
在Hadoop中,codec有CompressionCode的实现来表示。下面是一些实现:

MapReduce的输出进行压缩
输出的压缩属性:

