Optuna参数调优Sklearn模型可视化+Roc分层抽样性能分析
目录
1.数据集的选用和导入部分
2. Optuna调参部分
3.ROC图线绘制部分
1.数据集的选用和导入部分
本次文章的数据集选用经典的病马数据集,当然这个数据集都是可以替换的,可以用其他的二分类数据,数据导入部分没有做很多特殊的处理,做了一个基本的归一化处理,相关的代码如下:
# --------------病马预测------------------
# 文件解析函数,将文件数据转化为特征矩阵,标签矩阵
def file2matrix(filename):
fr = open(filename)
arrayOLines = fr.readlines()
numberOfLines = len(arrayOLines)
returnMat = np.zeros((numberOfLines, 21))
classLabelVector = [] # 标签矩阵
index = 0
for line in arrayOLines:
line = line.strip() # 去除文本文件中的回车符'\n'
listFromLine = line.split('\t') # 根据tab符进行划分,返回的是列表
returnMat[index, :] = listFromLine[0:21]
x = int(float(listFromLine[-1]))
if x == 1:
classLabelVector.append(1)
elif x == 0:
classLabelVector.append(0)
# classLabelVector.append(int(float(listFromLine[-1])))
index += 1
return returnMat, classLabelVector
# 将数据进行归一化处理
def autoNorm(dataSet): # 归一化处理
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = np.zeros(np.shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - np.tile(minVals, (m, 1))
normDataSet = normDataSet / np.tile(ranges, (m, 1))
return normDataSet2. Optuna调参部分
optuna是一个很棒的数据调参工具,相比于GridSearch网格搜索,它这个搜索是只用给定其要调参系数的大致范围,而不用自己特定限定参数值,是一个很智能化的调参工具,同时也可以为像一些比较热门的LGBT,XGBOST,NN等模型进行调参具有很不错的效果,这里主要是学习使用,就选择调节一些Sklearn常见的基础模型,进行调优.相关代码如下:
# --------opetuna调参模块-------------
def objective(trial):
classifier_name = trial.suggest_categorical("classifier", ["SVC","RandomForest","Ridge","KNN"])
# 设置想要调优的模型与模块
if classifier_name == "SVC":
# 设置分类向量机的一些参数如核函数,gamma值,C容忍度.
kernel = trial.suggest_categorical('kernel', ['linear', 'rbf', 'sigmoid'])
gamma = trial.suggest_float('gamma', 1e-5, 1e5)
svc_c = trial.suggest_float("svc_c", 1e-10, 1e-2, log=True)
classifier_obj = SVC(C=svc_c, kernel=kernel, gamma=gamma)
elif classifier_name == "RandomForest":
# 设置随机森林的深度,决策树的个数
rf_max_depth = trial.suggest_int("rf_max_depth", 2, 32, log=True)
rf_n_estimators=trial.suggest_int("rf_n_estimators",3,15)
classifier_obj = RandomForestClassifier(max_depth=rf_max_depth, n_estimators=rf_n_estimators)
elif classifier_name == "Ridge":
# 设置岭回归的学习率,权重值
C = trial.suggest_loguniform('alpha', 1e-7, 1e-2)
b = trial.suggest_int('b', 1, 32)
classifier_obj = RidgeClassifier(alpha=C, class_weight={0: 1, 1: b}, random_state=0)
elif classifier_name == "KNN":
# 设置kNN的邻居数量,第四个参数代表是步长为2,也就是都是奇数的邻居个数
n_num = trial.suggest_int('n_neighbors', 1, 15,2)
classifier_obj = KNeighborsClassifier(n_neighbors=n_num)
return cross_val_score(
# 根据交叉验证的平均值作为调优模型的调优方向,这里设置为五折的交叉验证
classifier_obj , X_train, y_train, n_jobs=-1, cv=5).mean()或者你想要使用Optuna剪枝的话只需要将返回值改为:
for step in range(100):
classifier_obj.fit(x_train, x_test)
intermediate_value = classifier_obj.score(y_train, y_test)
trial.report(intermediate_value, step)
if trial.should_prune():
raise optuna.TrialPruned()
return intermediate_value或者你可以使用lgbm的模型进行调参可以试一下这个:
def objective_lgb(trial):
dtrain = lgb.Dataset(x_train, label=y_train)
param = {
"objective": "binary",
"metric": "binary_logloss",
"verbosity": -1,
"boosting_type": "gbdt",
"lambda_l1": trial.suggest_float("lambda_l1", 1e-8, 10.0, log=True),
"lambda_l2": trial.suggest_float("lambda_l2", 1e-8, 10.0, log=True),
"num_leaves": trial.suggest_int("num_leaves", 2, 256),
"feature_fraction": trial.suggest_float("feature_fraction", 0.4, 1.0),
"bagging_fraction": trial.suggest_float("bagging_fraction", 0.4, 1.0),
"bagging_freq": trial.suggest_int("bagging_freq", 1, 7),
"min_child_samples": trial.suggest_int("min_child_samples", 5, 100),
}
gbm = lgb.train(param, dtrain)
preds = gbm.predict(x_test)
pred_labels = np.rint(preds)
accuracy = sklearn.metrics.accuracy_score(y_test, pred_labels)
return accuracy本次文章主要还是以使用Skelarn+交叉验证的值为准也就是第一个,那么通过主函数就可以直接调用这个代码了
if __name__ == "__main__":
# -------optuna调优以及可视化显示--------
study = optuna.create_study(direction="maximize")
#首先使用optuna进行参数调参来找到最好的模型
study.optimize(objective, n_trials=200)
# n_trials:测试200次找到最佳参数
print("最佳参数:", study.best_params)
# 最佳参数: {'classifier': 'RandomForest', 'rf_max_depth': 15, 'rf_n_estimators': 14}
print("最佳trial:", study.best_trial)
# optuna的可视化
optuna.visualization.plot_optimization_history(study).show()
# 使用最佳的参数去训练模型,然后获取其相关的性能指标
best_param=study.best_params
clf= RandomForestClassifier(max_depth=15, n_estimators=14)
# 最佳trial: FrozenTrial(number=79, values=[0.7857062146892655]
clf.fit(X_train,y_train)
predicted=clf.predict(X_test)
print(
f"Classification report for classifier {study}:\n"
f"{classification_report(y_test, predicted)}\n"
)
# -------------------------------------
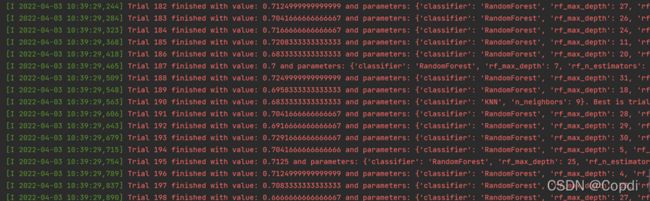
运行过程截图,可以看到整个调参过程中所选择的模型,和对应的参数和值
optuna的可视化展示图,单纯的用pycharm运行可能会出现绘制不出来的问题,可以使用jupyter进行绘制,如果jupyter无法绘制的话,可以参考官方文档上面的解决办法,GitHub - plotly/plotly.py: The interactive graphing library for Python (includes Plotly Express)

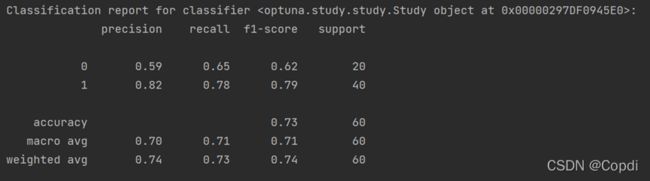
后面那个打印参数主要是输出我们模型的性能指标等,这些指标都是很经典来判断整个的预测模型好坏,比如我们对于标签0(活着)预测的准确率和召回率都不是很理想,而对于1可能要病死的马预测的效果很好.这是一些常用的指标性能.
3.ROC图线绘制部分
那么就此我们在去绘制一下它所对应的roc分层抽样的曲线图
# ---K折交叉验证创建的不同数据集的ROC曲线,同时显示AUC面积---
# 使用分层K折交叉验证
cv = StratifiedKFold(n_splits=5, shuffle=False)
# plot arrows
fig1 = plt.figure(figsize=[12, 12])
ax1 = fig1.add_subplot(111, aspect='equal')
ax1.add_patch(
patches.Arrow(0.45, 0.5, -0.25, 0.25, width=0.3, color='green', alpha=0.5)
)
ax1.add_patch(
patches.Arrow(0.5, 0.45, 0.25, -0.25, width=0.3, color='red', alpha=0.5)
)
tprs = []
aucs = []
mean_fpr = np.linspace(0, 1, 100)
i = 1
fig, ax = plt.subplots()
# 显示ROC是几折,AUC的值
for i, (train, test) in enumerate(cv.split(X, y)):
clf.fit(X[train], y[train])
viz = plot_roc_curve(clf, X[test], y[test],
name='ROC fold {}'.format(i),
alpha=0.3, lw=1, ax=ax)
interp_tpr = np.interp(mean_fpr, viz.fpr, viz.tpr)
interp_tpr[0] = 0.0
tprs.append(interp_tpr)
aucs.append(viz.roc_auc)
# 画出随机
ax.plot([0, 1], [0, 1], linestyle='--', lw=2, color='r',
label='Chance', alpha=.8)
# 求tpr和auc的均值
mean_tpr = np.mean(tprs, axis=0)
mean_tpr[-1] = 1.0
mean_auc = auc(mean_fpr, mean_tpr)
std_auc = np.std(aucs)
# 根据上述值,画出平均ROC曲线,对所有ROC曲线的走向进行可视化
ax.plot(mean_fpr, mean_tpr, color='b',
label=r'Mean ROC (AUC = %0.2f $\pm$ %0.2f)' % (mean_auc, std_auc),
lw=2, alpha=.8)
# 求tpr的最大值和最小值(根据tpr均值加减偏差)
# 求tpr的标准偏差(分布分布的度量)
std_tpr = np.std(tprs, axis=0)
tprs_upper = np.minimum(mean_tpr + std_tpr, 1)
tprs_lower = np.maximum(mean_tpr - std_tpr, 0)
# 根据均值、最大值和最小值,进行区域画图,画出ROC曲面
ax.fill_between(mean_fpr, tprs_lower, tprs_upper, color='grey', alpha=.2,
label=r'$\pm$ 1 std. dev.')
ax.set(xlim=[-0.05, 1.05], ylim=[-0.05, 1.05],
title="Receiver operating characteristic example")
# ROC Receiver operating characteristic example
# ax.legend(loc="lower right")
plt.show()绘制的效果如下:
可以看到我们整体的模型还是一个很不错的,曲线下方的面积占据大部分,AUC平均值在0.82左右,这也表示预测准确性高。
最后给出所有代码供大家学习
# -*- coding:utf-8 -*-
# @Time : 2022/4/3 0:01
# @Author :Copdi
# @Software : PyCharm
# 导包模块
# ---optuna调优以及其相关的包---
import optuna
from sklearn.svm import SVC
from sklearn.linear_model import RidgeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
#-------------------------
# roc画图以及数据导入的相关模块
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from sklearn.metrics import classification_report, plot_roc_curve, auc
from sklearn.model_selection import train_test_split, StratifiedKFold, cross_val_score
from bingma_loader import bingma_loader
import numpy as np
# 忽略一roc里面的报错
import warnings
warnings.filterwarnings("ignore")
# --------导数据模块-----------
X, y = bingma_loader("data/horseColicTraining.txt", 1)
# 导入病马数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10)
# 使用train_test_split划分数据集和测试集
X = np.array(X)
y = np.array(y)
# 将数据集和测试集转换为numpy数组形式,方便后面画图
# --------------------------
# --------opetuna调参模块-------------
def objective(trial):
classifier_name = trial.suggest_categorical("classifier", ["SVC", "RandomForest", "Ridge", "KNN"])
# 设置想要调优的模型与模块
if classifier_name == "SVC":
# 设置分类向量机的一些参数如核函数,gamma值,C容忍度.
kernel = trial.suggest_categorical('kernel', ['linear', 'rbf', 'sigmoid'])
gamma = trial.suggest_float('gamma', 1e-5, 1e5)
svc_c = trial.suggest_float("svc_c", 1e-10, 1e-2, log=True)
classifier_obj = SVC(C=svc_c, kernel=kernel, gamma=gamma)
elif classifier_name == "RandomForest":
# 设置随机森林的深度,决策树的个数
rf_max_depth = trial.suggest_int("rf_max_depth", 2, 32, log=True)
rf_n_estimators = trial.suggest_int("rf_n_estimators",3,15)
classifier_obj = RandomForestClassifier(max_depth=rf_max_depth, n_estimators=rf_n_estimators)
elif classifier_name == "Ridge":
# 设置岭回归的学习率,权重值
C = trial.suggest_loguniform('alpha', 1e-7, 1e-2)
b = trial.suggest_int('b', 1, 32)
classifier_obj = RidgeClassifier(alpha=C, class_weight={0: 1, 1: b}, random_state=0)
elif classifier_name == "KNN":
# 设置kNN的邻居数量,第四个参数代表是步长为2,也就是都是奇数的邻居个数
n_num = trial.suggest_int('n_neighbors', 1, 15,2)
classifier_obj = KNeighborsClassifier(n_neighbors=n_num)
return cross_val_score(
# 根据交叉验证的平均值作为调优模型的调优方向,这里设置为五折的交叉验证
classifier_obj, X_train, y_train, n_jobs=-1, cv=5).mean()
if __name__ == "__main__":
# -------optuna调优以及可视化显示--------
study = optuna.create_study(direction="maximize")
# 首先使用optuna进行参数调参来找到最好的模型
study.optimize(objective, n_trials=200)
# n_trials:测试200次找到最佳参数
print()
print("最佳参数:", study.best_params)
# 最佳参数: {'classifier': 'RandomForest', 'rf_max_depth': 15, 'rf_n_estimators': 14}
print("最佳trial:", study.best_trial)
# optuna.visualization.plot_optimization_history(study).show()
# optuna.visualization.plot_contour(study).show()
# optuna.visualization.plot_param_importances(study).show()
# 使用最佳的参数去训练模型,然后获取其相关的性能指标
best_param = study.best_params
clf = RandomForestClassifier(max_depth=15, n_estimators=14)
# 最佳trial: FrozenTrial(number=79, values=[0.7857062146892655]
# 填充所使用的训练数据的模型
clf.fit(X_train, y_train)
# 使用predict对测试数据进行预测
predicted = clf.predict(X_test)
print(
f"Classification report for classifier {study}:\n"
f"{classification_report(y_test, predicted)}\n"
)
# -------------------------------------
# ---K折交叉验证创建的不同数据集的ROC曲线,同时显示AUC面积---
# 使用分层K折交叉验证
cv = StratifiedKFold(n_splits=5, shuffle=False)
# plot arrows
fig1 = plt.figure(figsize=[12, 12])
ax1 = fig1.add_subplot(111, aspect='equal')
ax1.add_patch(
patches.Arrow(0.45, 0.5, -0.25, 0.25, width=0.3, color='green', alpha=0.5)
)
ax1.add_patch(
patches.Arrow(0.5, 0.45, 0.25, -0.25, width=0.3, color='red', alpha=0.5)
)
tprs = []
aucs = []
mean_fpr = np.linspace(0, 1, 100)
i = 1
fig, ax = plt.subplots()
# 显示ROC是几折,AUC的值
for i, (train, test) in enumerate(cv.split(X, y)):
clf.fit(X[train], y[train])
viz = plot_roc_curve(clf, X[test], y[test],
name='ROC fold {}'.format(i),
alpha=0.3, lw=1, ax=ax)
interp_tpr = np.interp(mean_fpr, viz.fpr, viz.tpr)
interp_tpr[0] = 0.0
tprs.append(interp_tpr)
aucs.append(viz.roc_auc)
# 画出随机
ax.plot([0, 1], [0, 1], linestyle='--', lw=2, color='r',
label='Chance', alpha=.8)
# 求tpr和auc的均值
mean_tpr = np.mean(tprs, axis=0)
mean_tpr[-1] = 1.0
mean_auc = auc(mean_fpr, mean_tpr)
std_auc = np.std(aucs)
# 根据上述值,画出平均ROC曲线,对所有ROC曲线的走向进行可视化
ax.plot(mean_fpr, mean_tpr, color='b',
label=r'Mean ROC (AUC = %0.2f $\pm$ %0.2f)' % (mean_auc, std_auc),
lw=2, alpha=.8)
# 求tpr的最大值和最小值(根据tpr均值加减偏差)
# 求tpr的标准偏差(分布分布的度量)
std_tpr = np.std(tprs, axis=0)
tprs_upper = np.minimum(mean_tpr + std_tpr, 1)
tprs_lower = np.maximum(mean_tpr - std_tpr, 0)
# 根据均值、最大值和最小值,进行区域画图,画出ROC曲面
ax.fill_between(mean_fpr, tprs_lower, tprs_upper, color='grey', alpha=.2,
label=r'$\pm$ 1 std. dev.')
ax.set(xlim=[-0.05, 1.05], ylim=[-0.05, 1.05],
title="Receiver operating characteristic example")
# ROC Receiver operating characteristic example
# ax.legend(loc="lower right")
plt.show()
# --------------------------------------------------------病马部分的数据集大家感兴趣可以找我要,或者你直接换成sklearn自带的乳腺癌数据集应该也是可以跑通的,loadbingma函数就是先执行上面写过的file2matrix和automated就行了,整个文章就是这样,欢迎大家进行学习交流.