Working with large lists in MOSS2007(四)
Analyzing the results
The test results in this white paper validate the fact that with proper testing in your own environment, it is quite possible that you can use more than 2,000 items in a container without an adverse impact on performance. The best results will be obtained if you write your own user interface to work with the data in the list, and make some carefully considered choices about what data access method works best for your requirements. The data access method you choose may very well impact other aspects of your site or list implementation.
本白皮书中通过恰当地测试,测试结果证实了环境中这样的事实:你很可能可以在容器中使用超过2000条项目,并且避免性能上的不利影响。使用你自己编写的处理列表数据接口并仔细考虑选择何种数据方法以适应你的需求一遍工作得最好,这样就可以获得最佳结果。你选择的数据访问方法将会影响到站点或列表实施的各个方面。
For example, using data access methods that require the SPList class will greatly benefit from indexing columns used in a WHERE clause. However, the benefit of indexing these columns is marginal if the data is retrieved using the Search service, the Lists Web service or the PortalSiteMapProvider class. Conversely, if you are not using the SPList class for data retrieval, data access will likely be much faster if you are able to retrieve data based on the ID of items, rather than the value of a specific column in a list.
比如,使用需要SPList类的数据访问方法在WHERE条件中使用索引列会有很大好处。然而,索引带来的检索数据的好处在使用Search服务、列表的Web service或者PortalSiteMapProvider类时却微乎其微。相反,你不使用SPList类检索数据,而是基于列表的ID字段检索数据而不是其它特定的列的值的话,数据访问可能更快。
Search
Search performed well across all of the scenarios. One drawback to using Search is that it cannot retrieve data until indexing has completed, so if immediate data retrieval is a requirement, Search may not be the best choice. You will probably also need to configure Search further to support your query requirements. For example, these tests required the ability to use a structured query language (SQL) statement that retrieved a very specific set of fields from a list, as well as use the ID and Expense Category field in the WHERE clause. For this solution to work, Managed Properties must be configured in Search to retrieve the custom properties from the list and to use criteria against them. Implementing Search as it was used in this testing requires Office SharePoint Server 2007.
使用搜索服务在大多数场合中都执行得不错。缺点是如果没有索引完的话是不能使用它来检索数据的。因此,如果你想检索实时数据,那么搜索就不是一个好的选择了。可能还需要进一步配置搜索以支持你的需求。比如,这些测试要求有能力使用SQL语句从列表中检索出特定的域,并且在WHERE中使用ID和Expense Category域作为检索条件。为使这个解决方案可行,托管属性必须在搜索中被配置以便从列表中检索自定义属性并以它们作为检索条件。此外,测试中的搜索要求在MOSS2007中进行。
PortalSiteMapProvider
The PortalSiteMapProvider class was one of the best performing data access methods in every scenario. However, there are a couple of limitations in using it. First, because of the way in which the data is cached, use of the PortalSiteMapProvider class is going to be most useful if the data you are retrieving is not significantly different over time. If you are trying to frequently retrieve different data sets, the PortalSiteMapProvider class will incur the overhead of constantly reading from the database, inserting data into the cache and then returning it from the method call. Clearly, the advantage of the PortalSiteMapProvider class is when it can read data directly from the cache.
PortalSiteMapProvider类也是在各场景中各数据访问方法中最好的方法之一。然而,在使用它时同样也有两点限制。首先是因为数据缓存时的方式 ,假如你的数据与过去没有明显变化时使用PortalSiteMapProvider类作用明显。但是如果你视图经常访问不用的数据集,那么PortalSiteMapProvider类会导致频繁地读取数据库,插入数据到缓存并返回结果到方法调用。显然,使用PortalSiteMapProvider类的好处在于当其可以直接从缓存中读取数据。
Also, the amount of memory the PortalSiteMapProvider class has available to use may be somewhat constrained. It uses the site collection object cache to store data; by default, the object cache is only 100 megabytes (MB). You can increase the size of the site collection object cache on the Object cache settings page for the site collection. You can change the Max. Cache Size (MB) value on that page. However, remember that whatever amount of memory you assign to the object cache comes out of the same shared memory available to the application pool. If you are running the 32-bit version of Office SharePoint Server 2007, the most memory you can assign to a single application pool is 2 GB, and you immediately lose roughly 500 MB when the .NET Framework and base Office SharePoint Server 2007 DLLs and assemblies are loaded. Therefore, you need to balance the object cache size with how much memory you have available on your Web servers in addition to the processor architecture, other loaded programs used by Office SharePoint Server 2007, etc. The PortalSiteMapProvider class is only available on Office SharePoint Server 2007.
同时,PortalSiteMapProvider类拥有的可用内存数量可能有某种程度的约束。默认地,它使用站点集对象缓存数据,该对象缓存仅有100MB。你可以通过在对象缓存设置页面中为站点集增加缓存大小。你可以在该页面上设置最大缓存值。然后,需要记住的是,无论你分配多大的内存给它,对应用程序池而言,对象缓存都只能产生同样大小的共享内存。假如你运行的是32-bit版本的MOSS2007,你为应用程序池可分配的最大内存是2GB,并且当.Net Framework和MOSS2007的DLL和程序集被加载后你马上就损失了500MB。因此,你需要根据你的WEB服务器有多少可用内存来平衡对象缓存的大小。此外,处理器架构以及加载MOSS2007使用的其它程序的情况等等也要考虑。PortalSiteMapProvider类只能在MOSS2007中使用。
SPList
Using the SPList class gives you several options to retrieve data — a For/Each enumeration, the Items collection, the GetDataTable method of an SPListItems collection, and using an SPQuery object to filter data. Some of those methods, specifically the GetListItems and GetDataTable from the results of GetListItems, routinely performed well in most scenarios. However, there are some limitations. For example, the GetListItems method won’t work across folders in a single list unless the ViewAttributes property of your SPQuery query class includes Scope="Recursive". For that matter, it won’t work across lists if you want to query data from multiple lists or subsites. It also requires that all code runs directly on the Office SharePoint Server 2007 computer. Other options, like the Lists Web service and the Search Web service (not the Search methodology that was used in these tests) can retrieve the data but run on remote servers.
使用SPList类提供了几种检索数据供选择:使用For/Each列举、使用列表项集、使用SPListItems集的GetDataTable方法以及使用SPQuery方法筛选数据。这些方法中的一些,特别是GetListItems和从GetListItems结果集获得数据的GetDataTable在大多数场合都执行得很好。然而也有一些局限。比如,GetListItems方法如果不将SPQuery查询的ViewAttributes属性包括Scope="Recursive"的话就无法在列表中透过文件夹获取数据。并且,它也无法从多个列表或者站点中查询数据。此外,它还必需直接运行在安装了MOSS2007的机器上。作为选择,比如列表的Web service和搜索Web service(不是测试中使用的搜索方法)可以在远程服务器上运行检索数据。
Data maintenance considerations
There are a few other issues to consider when creating lists with more than 2,000 items per container. One is the cost of other common operations such as adding or deleting items from the list. We did some additional tests to measure the impact of those kinds of operations against our very large list. The results show that as the list gets quite large, those operations begin to slow down considerably.
当在一个容器中创建超过2000条项目的列表时,这里还有一些问题需要考虑。一是一些常用操作比如从列表中添加或者删除项目的成本。我们做了一些额外测试来衡量在大列表上这些操作的影响。结果表明当列表变得非常大时,这些操作也开始明显地变慢。

The results show that when the site is not under load, adding a single new item does not have a significant impact on performance. However, although indexing a column improves query performance, it also may negatively impact the performance of adding new records. Also, performance would obviously degrade when multiple items are being added and the site is under load.
结果显示,当站点使用非加载方式,添加一个简单的项目并不会会有明显的性能影响。然而,尽管索引列提高查询性能,它同时也会在添加新记录时带来一些负面的性能影响。同样地,当添加多条数据并且站点时加载方式时,执行效率将明显降低。
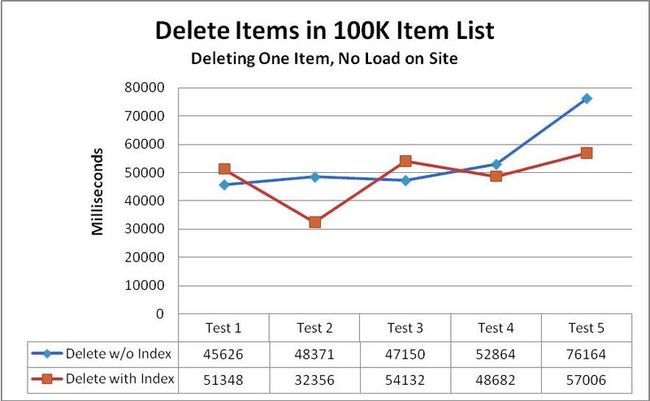
Performance for deleting items degrades significantly when a list becomes very large. Deleting a single item from a very large list takes much more time than deleting an item from a smaller list. In the test case, a single item was deleted from a site that was not under load. As the data shows, whether there was an indexed column or not, performance when changing list items degrades as the size of the list grows. It’s more likely that a batch process would need to be built to delete items during off-peak periods. If that is not an option, the performance of delete functionality alone could conceivably force you to abandon plans to use very large lists in Office SharePoint Server 2007.
当列表变得非常大时,删除项目时的性能降低得很多。从大列表删除一个简单的项目比从一个小列表中删除花费的时间多得多。在测试中,以非加载方式中站点中删除一条简单项。正如数据表面的那样,无论列是否索引,随着列表容量的增长,改变列表项时的性能也在降低。很可能需要创建一个批处理任务在非高峰期间来删除项目。如果不这样做,删除的性能会迫使你放弃在MOSS2007使用大列表的计划。
Data locking
Another important consideration when using large lists is the concept of the locks that Microsoft SQL Server" places on data tables that contain list information. Virtually all data for all Office SharePoint Server 2007 lists is contained within a single table in SQL Server. This table contains data for all the lists in all the site collections whose data is stored in that content database. When you attempt to update data on a list item, whether that is adding, editing or deleting a list item, SQL Server will attempt to lock other items (rows to SQL Server) for that particular list.
另外一个重要的需要考虑的是,当使用大列表时,MS SQL Server中包含列表信息的数据表的锁的概念。事实上,所有MOSS2007列表的数据都被放置在SQL Server的一个表中。这个表存储在内容数据库中,包含了站点集中的所有列表数据。当你视图更新一个列表项的数据时,无论是添加、编辑还是删除一个列表项,SQL Server都将视图锁定指定列表的其它项(SQL Server数据库中的行)。
However, there is a limit to the number of individual rows that SQL Server will try to lock down. If you try to select approximately 5,000 items or more simultaneously for reading or update, SQL Server will typically lock the entire table for the duration of that change. In this event, all other reads and writes for all lists in all site collections are queued until the previous transaction is complete and the lock is released. If your query retrieves data across multiple folders within the list, the locking behavior occurs whether or not list items are recursively nested so that there are not more than 2,000 items in an individual container. To ensure that you don’t encounter this locking behavior, make sure the number of items you retrieve in a single request is well below this threshold. For example, you can control the number of records returned by setting the RowLimit on the SPQuery class.
然而,SQL Server中,尝试锁定独立的行是有限制的。假如你尝试选择接近5000条项目或者同时读或更新,SQL Server将会在变化期间锁定整个表。这就意味着,其它所有站点集中所有的列表的读写操作都将等候直到先前的事务完成并且锁被释放。如果你的查询时从列表中的多个文件夹中检索数据,无论列表项是否递归嵌套,锁行为都会发生,所以在一个独立的容器中不要超过2000条数据。为了确保是否遇到了锁行为,请弄清你的请求在一个简单列表中的检索的项的数量在极限以内。比如,你可以通过在SPQuery中设置RowLimit控制返回的记录数。
Crawl times
" Another consideration with very large lists is crawl time and crawl time-outs. As a list gets larger, the chances of the indexer timing out when crawling the contents of that list increases. This is an issue that should be carefully monitored and tested in a lab environment before rolling out any large list in production. If the indexer is timing out when crawling large lists, you can increase the time-out value with the following steps:
在大列表中还有要考虑的是爬网时间和爬网超时。当列表便得越来越大,爬行列表内容的索引器超时的机会也增加了。这有一个结论,在生产环境中使用大列表之前应该仔细地监视并且在试验环境中测试。如果索引器在爬行大列表时超时,你可以通过下列步骤设置增加超时时间的值。
1. In Central Administration, on the Application Management tab, in the Search section, click Manage search service. (在管理中心的应用程序管理标签的搜索节中点击管理搜索服务)
2. On the Manage Search Service page, in the Farm-Level Search Settings section, click Farm-level search settings. (在管理搜索服务页上的服务器场级搜索设置节上点击服务器场级搜索设置)
3. In the Timeout Settings section, in the Connection time and Request acknowledgement time boxes, enter the desired number of seconds. (在超时设置节中的连接时间和请求确认时间框,输入想要的秒数)
Related content
For more detailed information about the factors involved in performance and capacity planning for Office SharePoint Server 2007 lists, see following resource:
更多关于MOSS2007解决列表性能以及容量规划的细节信息,可以参看下面的资源:
Plan for software boundaries (Office SharePoint Server) (http://go.microsoft.com/fwlink/?LinkID=95115&clcid=0x409). This article provides a starting point for planning the performance and capacity of your system, including performance and capacity testing results and guidelines for acceptable performance.