神经网络优化中的Weight Averaging

©PaperWeekly 原创 · 作者|张子逊
研究方向|神经网络剪枝、NAS
在神经网络优化的研究中,有研究改进优化器本身的(例如学习率衰减策略、一系列 Adam 改进等等),也有不少是改进 normalization 之类的技术(例如 Weight Decay、BN、GN 等等)来提高优化器的性能和稳定性。除此之外,还有一个比较常见的技术就是 Weight Averaging,也就是字面意思对网络的权重进行平均,这也是一个不错的提高优化器性能/稳定性的方式。

Stochastic Weight Averaging (SWA)
在神经网络的优化中,有一个比较公认的问题就是 train loss 和 test loss 优化曲面不一致。导致这个问题可能的原因有很多,(以下是个人推测)可能是 train 和 test 数据本身存在分布不一致的问题、也可能是因为训练的时候在 train loss 中加入了一系列正则化等等。由于这个不一致的问题,就会导致优化出来的网络 generalization performance 可能会不好。
本文提出了一个比较简单直接的方式来解决这个问题,在优化的末期取 k 个优化轨迹上的 checkpoints,平均他们的权重,得到最终的网络权重,这样就会使得最终的权重位于 flat 曲面更中心的位置。这个方法也被集成到了 PyTorch 1.6 之后的版本中。

本文的实验分析部分也给出了详细的分析和结果来验证这样的一种方法是有效的。首先是分析的部分,本文通过可视化绘制了通过 SWA 和 SGD 在 loss landscape 上的收敛位置,以及 SGD 优化得到的权重对应的 loss 和 error 相比 SWA 得到的权重的距离,如下图所示。
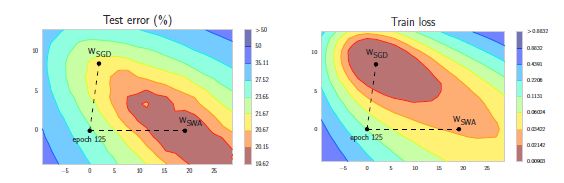

从图上可以看到几个有趣的现象:首先,train loss 和 test loss 的 landscape 之间确实存在偏移;其次,SGD 更倾向于收敛到 flat 区域的边缘。比较直观的一种猜想就是,利用这样的性质,SWA 可以通过平均 flat 区域边缘的一些 checkpoints,来使得最终的收敛位置更靠近中心的位置。在实际实验中,也显示了类似的结果,经过 SWA 平均之后,网络的测试准确率都有不同程度的提升。

Stochastic Weight Averaging in Parallel
这篇文章是对上面的 SWA 在并行优化中的一个应用。在并行优化神经网络的过程中,batch size 的增加可以使 SGD 的梯度计算更精确,因此可以使用更大的 lr 进行优化,同时也可以缩短优化的次数。但是这样往往也会使得优化出来的 generalization performance 更差,因此就需要引入一些额外的技术来避免这个问题。
本文则是讲优化过程分成三个阶段。在前期利用 large batch size 的优势让网络的 loss 快速收敛到一个相对不错的平坦区。在第二阶段每一个节点独立的用 mini batch 来更新模型。最后利用 SWA 来对这些模型进行平均,改善 large batch 带来的 generalization 问题。

本文在实验分析中,同样发现了类似 SWA 的现象就是 train loss 的曲面与 test loss 的曲面不一致。本文利用可视化方法绘制了一张 CIFAR-10 上的 loss landscape 如下图所示。

从图上可见,train loss 的 flat 区域要比 test loss 大得多;同时 SGD 更倾向于停在 flat 区域的边缘。而经过 SWA 之后,平均之后的模型有更大的概率落在相对中心的位置上。

Lookahead Optimizer
前面提到的 SWA 在优化上,并没有改变原本优化器更新的梯度,只在结束之后选取一部分 checkpoints 进行 weight averaging 得到最终的权重。而这篇文章则是在更新过程中,利用指数移动平均的方式来计算梯度更新权重。
本文提出了一种权重的更新策略,每一个 step 的优化中维护两组权重,第一组称为 fast weight,就是常规优化器更新得到的权重,第二组称为 slow weight,是利用 fast weight 得到的权重。之所以称为 fast/slow,是由于二者的更新频率不同,先用 fast 更新 k 步,然后根据得到的 fast weight 更新 slow weight 1 步作为这一个优化 step 的结果,依次循环进行。

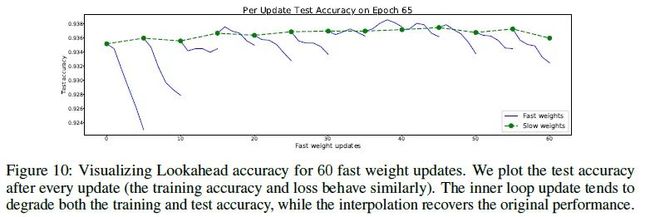
在实验中,本文也通过大量的实验,验证了 Lookahead 优化器在前期比 SGD 优化的更快。此外,在实验分析中,本文也发现了一个有趣的现象,就是每一轮从 slow weight 开始 fast weight(SGD/Adam 更新)反而让 loss 上升了,而经过 slow weight 移动平均之后 loss 又恢复了下降。

Filter Grafting
这篇论文虽然在出发点上与前文并不相同,但是实际的方法也可以看作是一种 weight average,因此也总结在这里了。
神经网络经常会出现冗余的问题,一般的方法都是剪枝的方式来消除冗余部分,而也有一些其他的方法则是重新利用冗余部分来提高网络的性能/泛化性,例如 Dense sparse dense training、RePr 等等。本文也是同样的出发点,希望通过引入外部信息来改善冗余问题。
本文提出了一种利用权重的熵来评估网络中 filter 所包含的信息量,在优化中,同时优化两个相同的网络,采用不同的超参来进行优化,在优化过程中对 filter 进行加权平均实现对信息量的补足。


在加权平均时,为了简洁,不采用针对特定位置的 filter 进行加权,而是根据一层的熵大小来对整个一层的参数进行平均,加权所用的 alpha 则是根据两个网络这一层熵的大小自适应决定的。更进一步,则是可以将 2 个网络相互加权,拓展成多个网络循环加权,如下图所示。

在实验中,本文除了对这种 grafting 策略进行了性能测试,也对其他的一些细节进行了分析:(1) 不同的信息来源对提升的影响(网络自身、噪声、不同网络);(2) 不同的信息量评估方式的影响(L1 norm、熵)。最终得出文中提出的多个网络基于熵的杂交策略是最优的。同时也对杂交训练得到的网络的冗余量(权重 L1 norm 统计)和网络最终熵之和进行了分析。

参考文献
[1] Izmailov P, Podoprikhin D, Garipov T, et al. Averaging weights leads to wider optima and better generalization[J]. arXiv preprint arXiv:1803.05407, 2018.
[2] Gupta V, Serrano S A, DeCoste D. Stochastic Weight Averaging in Parallel: Large-Batch Training that Generalizes Well[J]. arXiv preprint arXiv:2001.02312, 2020.
[3] Zhang M, Lucas J, Ba J, et al. Lookahead optimizer: k steps forward, 1 step back[J]. Advances in Neural Information Processing Systems, 2019, 32: 9597-9608.
[4] Meng F, Cheng H, Li K, et al. Filter grafting for deep neural networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 6599-6607.
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

