基于联邦学习的MNIST手写数字识别-Pytorch实现
参考:基于联邦学习的MNIST手写数字识别-Pytorch实现 - 灰信网(软件开发博客聚合) (freesion.com)
一、MNIST数据集
大量参考:MNIST数据集_保持理智802的博客-CSDN博客_mnist数据集
1.加载数据
train_set = torchvision.datasets.MNIST(
root="./data",
train=True,
transform=transforms.ToTensor(),
download=False)- transform=transforms.ToTensor()作用为将形状为(H,W,C)的np.ndarray或img,转化为(C,H,W)的tensor,并将每一个数值归一化到 [0, 1]
train_data_loader = torch.utils.data.DataLoader(
dataset=train_set,
batch_size=64,
shuffle=True,
drop_last=True)- dataset:指定欲装载的MNIST数据集。
- batch_size:设置了每批次装载的数据图片为64个。
- shuffle:设置为True表示在装载数据时随机乱序,常用于进行多批次的模型训练。
- drop_last:设置为True表示当数据集size不能整除batch_size时,则删除最后一个batch_size,否则就不删除。
2.预览数据
images, labels = next(iter(train_data_loader))
img = torchvision.utils.make_grid(images, padding=0)
img = img.numpy().transpose(1, 2, 0)
plt.imshow(img)
plt.show()- iter():dataloader本质上是一个可迭代对象,可以使用iter()进行访问,采用iter(dataloader)返回的是一个迭代器,然后可以使用next()访问。
- next():返回迭代器的下一个项目。
- make_grid():组成图像的网络,其实就是将多张图片组合成一张图片。
- img.numpy().transpose(1,2,0):pytorch的网络输入格式为(通道数,高,宽),而numpy中的图像shape为(高,宽,通道数)
效果如下:

二、实现过程
1.加载数据
import torch
import torchvision
import torchvision.transforms as transforms
import torch.utils.data.dataloader as dataloader
from torch.utils.data import Subset
import torch.nn as nn
import torch.optim as optim
from torch.nn.parameter import Parameter导入库后,使用Subset函数对训练数据集进行划分,这里总共有ABC三个机构,每个机构的训练集数目为1000。然后将训练数据集放入Dataloader里。
这里我们把整个训练集作为一个batch_size,所以不需要打乱。
# 训练集
train_set = torchvision.datasets.MNIST(
root="./data",
train=True,
transform=transforms.ToTensor(),
download=False)
train_set_A = Subset(train_set, range(0, 1000))
train_set_B = Subset(train_set, range(1000, 2000))
train_set_C = Subset(train_set, range(2000, 3000))
train_loader_A = dataloader.DataLoader(dataset=train_set_A, batch_size=1000, shuffle=False)
train_loader_B = dataloader.DataLoader(dataset=train_set_B, batch_size=1000, shuffle=False)
train_loader_C = dataloader.DataLoader(dataset=train_set_C, batch_size=1000, shuffle=False)
# 测试集
test_set = torchvision.datasets.MNIST(
root="./data",
train=False,
transform=transforms.ToTensor(),
download=False)
transform=transforms.ToTensor(), download=False)
test_set = Subset(test_set, range(0, 2000))
test_loader = dataloader.DataLoader(dataset=test_set, shuffle=True)2.普通训练
首先定义神经网络的类型,这里用的是最简单的三层神经网络(也可以说是两层,不算输入层),输入层28×28,隐藏层12个神经元,输出层10个神经元。
class NeuralNet(nn.Module):
def __init__(self, input_num, hidden_num, output_num):
super(NeuralNet, self).__init__()
self.fc1 = nn.Linear(input_num, hidden_num) # 服从正态分布的权重w
self.fc2 = nn.Linear(hidden_num, output_num)
nn.init.normal_(self.fc1.weight)
nn.init.normal_(self.fc2.weight)
nn.init.constant_(self.fc1.bias, val=0) # 初始化bias为0
nn.init.constant_(self.fc2.bias, val=0)
self.relu = nn.ReLU() # Relu激励函数
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
y = self.fc2(x)
return y- class NeuralNet(nn.Module):自定义一个模型,通过继承nn.Module类来实现,在__init__构造函数中申明各个层的定义,在forward中实现层之间的连接关系,实际上就是前向传播的过程
- def __init__(self, input_num, hidden_num, output_num):继承init方法,参数中必须有self,需要三个参数
- super(NeuralNet, self).__init__():构造函数必须要有
- nn.Linear():线性层
- nn.init.normal_(self.fc1.weight):意思是,以正态分布的数据填充线性层的权重,默认平均值为0,标准差为1
- nn.init.constant_(self.fc1.bias, val=0):用0去填充self.fc1.bias,意思就是线形层的b
- forward(self, x):前馈函数,经历一次完整的计算
def train_and_test_1(train_loader, test_loader):
class NeuralNet(nn.Module):...
epoches = 20 # 迭代20轮
lr = 0.01 # 学习率,即步长
input_num = 784
hidden_num = 12
output_num = 10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = NeuralNet(input_num, hidden_num, output_num)
model.to(device)
loss_func = nn.CrossEntropyLoss() # 损失函数的类型:交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=lr) # Adam优化,也可以用SGD随机梯度下降法
# optimizer = optim.SGD(model.parameters(), lr=lr)
for epoch in range(epoches):
flag = 0
for images, labels in train_loader:
images = images.reshape(-1, 28 * 28).to(device)
labels = labels.to(device)
output = model(images)
loss = loss_func(output, labels)
optimizer.zero_grad()
loss.backward() # 误差反向传播,计算参数更新值
optimizer.step() # 将参数更新值施加到net的parameters上
# 以下两步可以看每轮损失函数具体的变化情况
# if (flag + 1) % 10 == 0:
# print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch + 1, epoches, loss.item()))
flag += 1
params = list(model.named_parameters()) # 获取模型参数
# 测试,评估准确率
correct = 0
total = 0
for images, labels in test_loader:
images = images.reshape(-1, 28 * 28).to(device)
labels = labels.to(device)
output = model(images)
values, predicte = torch.max(output, 1) # 0是每列的最大值,1是每行的最大值
total += labels.size(0)
# predicte == labels 返回每张图片的布尔类型
correct += (predicte == labels).sum().item()
print("The accuracy of total {} images: {}%".format(total, 100 * correct / total))
return params- epoches:迭代次数
- lr:学习率,即步长
- input_num,hidden_num,output_num:神经网络各层的单元个数
- torch.device():将张量部署在指定的运算设备上进行计算,这里是GPU
- model.to(device):当我们指定了设备之后,就需要将模型加载到相应设备中
- loss_func:这里我们指定了交叉熵损失函数,若要计算loss,则传入output和labels。要查看loss需要调用loss.item()
- optimizer:指定了Adam优化
- for循环迭代优化:记住四金刚,算损失函数→梯度清零→反向传播→更新
以上是更新一个简单的神经网络的过程,接下来是测试:
- params = list(model.named_parameters()):获取模型参数,这个模型参数是以多项list的形式展示的
- for循环计算模型准确率:每一批次算出来output都softmax一下(这里的操作是用max函数返回predicte),然后把相同的标签比较值(1对0错)都加起来。
最后,这整个函数会返回此时模型的参数params,用来进行联邦聚合。
3.联邦后训练
首先是定义神经网络:
class NeuralNet(nn.Module):
def __init__(self, input_num, hidden_num, output_num, com_para_fc1, com_para_fc2):
super(NeuralNet, self).__init__()
self.fc1 = nn.Linear(input_num, hidden_num)
self.fc2 = nn.Linear(hidden_num, output_num)
self.fc1.weight = Parameter(com_para_fc1)
self.fc2.weight = Parameter(com_para_fc2)
nn.init.constant_(self.fc1.bias, val=0)
nn.init.constant_(self.fc2.bias, val=0)
self.relu = nn.ReLU()
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
y = self.fc2(x)
return y可以与之前的网络对比一下,区别在于:
- 两个线性层权重,由输入参数初始化
def train_and_test_2(train_loader, test_loader, com_para_fc1, com_para_fc2):
class NeuralNet(nn.Module):...
epoches = 20
lr = 0.01
input_num = 784
hidden_num = 12
output_num = 10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = NeuralNet(input_num, hidden_num, output_num, com_para_fc1, com_para_fc2)
model.to(device)
loss_func = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
# optimizer = optim.SGD(model.parameters(), lr=lr)
for epoch in range(epoches):
flag = 0
for images, labels in train_loader:
# (images, labels) = data
images = images.reshape(-1, 28 * 28).to(device)
labels = labels.to(device)
output = model(images)
loss = loss_func(output, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# if (flag + 1) % 10 == 0:
# print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch + 1, epoches, loss.item()))
flag += 1
params = list(model.named_parameters()) # get the index by debuging
correct = 0
total = 0
for images, labels in test_loader:
images = images.reshape(-1, 28 * 28).to(device)
labels = labels.to(device)
output = model(images)
values, predicte = torch.max(output, 1)
total += labels.size(0)
correct += (predicte == labels).sum().item()
print("The accuracy of total {} images: {}%".format(total, 100 * correct / total))
return params除了网络之外,其余与普通训练一样。
4.联邦平均
这里只对w做平均:
def combine_params(para_A, para_B, para_C, para_D, para_E):
fc1_wA = para_A[0][1].data
fc1_wB = para_A[0][1].data
fc1_wC = para_A[0][1].data
fc2_wA = para_A[2][1].data
fc2_wB = para_A[2][1].data
fc2_wC = para_A[2][1].data
com_para_fc1 = (fc1_wA + fc1_wB + fc1_wC) / 3
com_para_fc2 = (fc2_wA + fc2_wB + fc2_wC) / 3
return com_para_fc1, com_para_fc2- para_A[0][1]和para_A[2][1]:上文提到,我们提取的网络参数是一个list,这个list由tuple元组组成的,每个元组是权重的名称(str)和权重数据(Parameter),包含第一个线性层的w和b,第二个线性层的w和b。
- para_A[0][1].data:为了能够直接运算,要从Parameter类型中调用data方法转化为tensor数据。
可以看出,这里的平均,仅仅是把三个模型中两个线性层的w部分进行了平均。最后返回的是平均之后的两个线性层系数。
5.主函数
if __name__ == '__main__':
print('\033[31m'+'Start training model ABC at 1st time...'+'\033[0m')
para_A = train_and_test_1(train_loader_A, test_loader)
para_B = train_and_test_1(train_loader_B, test_loader)
para_C = train_and_test_1(train_loader_C, test_loader)
for i in range(6):
print('\033[31m'+'The {} round to be federated!!!'.format(i + 1)+'\033[0m')
com_para_fc1, com_para_fc2 = combine_params(para_A, para_B, para_C)
para_A = train_and_test_2(train_loader_A, test_loader, com_para_fc1, com_para_fc2)
para_B = train_and_test_2(train_loader_B, test_loader, com_para_fc1, com_para_fc2)
para_C = train_and_test_2(train_loader_C, test_loader, com_para_fc1, com_para_fc2)- 在print里,加上'\033[31m'代表以后的字符改为红色
这里首先模拟了初始时刻,每个机器训练了自己的模型,然后在循环中,所有的模型被聚合,然后收到聚合后的模型,继续用本地数据进行训练。
三、训练结果

(第一轮训练,未经联邦优化)
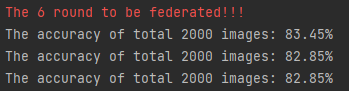
(第六轮训练,联邦优化)