联邦学习开山之作代码解读与收获
参考:联邦学习代码解读,超详细_一只揪°的博客-CSDN博客_联邦学习代码
参考文献:[1602.05629] Communication-Efficient Learning of Deep Networks from Decentralized Data (arxiv.org)
参考代码:GitHub - AshwinRJ/Federated-Learning-PyTorch: Implementation of Communication-Efficient Learning of Deep Networks from Decentralized Data
今天尝试阅读开山之作的代码。
目录
一、加载参数——options.py
二、数据IID和非IID采样——sampling.py
1.mnist_iid()
2.mnist_noniid()
3.mnist_noniid()
4.cifar_iid()、cifar_noniid()
三、本地模型参数更新——update.py
1.DatasetSplit(Dataset)
2.LocalUpdate(object)
3.test_inference(self,model)
四、应用集——utils.py
1.get_dataset(args)
2.average_weights(w)
3.exp_details(args)
五、模型设置——models.py
1.MLP多层感知机模型
2.CNN卷积神经网络
3.自创模型
六、主函数——federated_main.py
七、作图
八、个人总结
一、加载参数——options.py
import argparse
def args_parser():
parser = argparse.ArgumentParser()
# federated arguments (Notation for the arguments followed from paper)
parser.add_argument('--epochs', type=int, default=10,
help="number of rounds of training")
parser.add_argument('--num_users', type=int, default=100,
help="number of users: K")
parser.add_argument('--frac', type=float, default=0.1,
help='the fraction of clients: C')
parser.add_argument('--local_ep', type=int, default=10,
help="the number of local epochs: E")
parser.add_argument('--local_bs', type=int, default=10,
help="local batch size: B")
parser.add_argument('--lr', type=float, default=0.01,
help='learning rate')
parser.add_argument('--momentum', type=float, default=0.5,
help='SGD momentum (default: 0.5)')
# model arguments
parser.add_argument('--model', type=str, default='mlp', help='model name')
parser.add_argument('--kernel_num', type=int, default=9,
help='number of each kind of kernel')
parser.add_argument('--kernel_sizes', type=str, default='3,4,5',
help='comma-separated kernel size to \
use for convolution')
parser.add_argument('--num_channels', type=int, default=1, help="number \
of channels of imgs")
parser.add_argument('--norm', type=str, default='batch_norm',
help="batch_norm, layer_norm, or None")
parser.add_argument('--num_filters', type=int, default=32,
help="number of filters for conv nets -- 32 for \
mini-imagenet, 64 for omiglot.")
parser.add_argument('--max_pool', type=str, default='True',
help="Whether use max pooling rather than \
strided convolutions")
# other arguments
parser.add_argument('--dataset', type=str, default='mnist', help="name \
of dataset")
parser.add_argument('--num_classes', type=int, default=10, help="number \
of classes")
parser.add_argument('--gpu', default=None, help="To use cuda, set \
to a specific GPU ID. Default set to use CPU.")
parser.add_argument('--optimizer', type=str, default='sgd', help="type \
of optimizer")
parser.add_argument('--iid', type=int, default=1,
help='Default set to IID. Set to 0 for non-IID.')
parser.add_argument('--unequal', type=int, default=0,
help='whether to use unequal data splits for \
non-i.i.d setting (use 0 for equal splits)')
parser.add_argument('--stopping_rounds', type=int, default=10,
help='rounds of early stopping')
parser.add_argument('--verbose', type=int, default=1, help='verbose')
parser.add_argument('--seed', type=int, default=1, help='random seed')
args = parser.parse_args()
return args这里使用argparse输入了三类参数,分别是联邦参数,模型参数,其他参数。其中联邦参数:
- epochs:训练轮数,10
- num_users:用户数量K,默认100
- frac:用户选取比例C,默认0.1
- local_ep:本地训练数量E,默认10
- local_bs:本地训练批量B,默认10
- lr:学习率,默认0.01
- momentum:SGD动量(为什么SGD有动量?),默认0.5
模型参数:
- model:模型名称,默认mlp,即全连接神经网络
- kernel_num:卷积核数量,默认9个
- kernel_sizes:卷积核大小,默认3,4,5
- num_channels:图像通道数,默认1
- norm:归一化方式,可以是BN和LN
- num_filters:过滤器数量,默认32
- max_pool:最大池化,默认为True
其他设置:
- dataset:选择什么数据集,默认mnist
- num_class:分类数量,默认10
- gpu:默认使用,可以填入具体cuda编号
- optimizer:优化器,默认是SGD算法
- iid:独立同分布,默认是1,即是独立同分布
- unequal:是否平均分配数据集,默认0,即是
- stopping_rounds:停止轮数,默认是10
- verbose:日志显示,0不输出,1输出带进度条的日志,2输出不带进度条的日志
- seed: 随机数种子,默认1
最后args_parser()函数会返回args,里面包含了控制台输入的参数。
二、数据IID和非IID采样——sampling.py
这个文件从mnist和cifar-10采集IID和非IID的数据。
1.mnist_iid()
def mnist_iid(dataset, num_users):
"""
Sample I.I.D. client data from MNIST dataset
:param dataset:
:param num_users:
:return: dict of image index
"""
num_items = int(len(dataset)/num_users)
dict_users, all_idxs = {}, [i for i in range(len(dataset))]
for i in range(num_users):
dict_users[i] = set(np.random.choice(all_idxs, num_items,
replace=False))
all_idxs = list(set(all_idxs) - dict_users[i])
return dict_users随机给100个用户选600个随机的样本。
2.mnist_noniid()
def mnist_noniid(dataset, num_users):
"""
Sample non-I.I.D client data from MNIST dataset
:param dataset:
:param num_users:
:return:
"""
# 60,000 training imgs --> 200 imgs/shard X 300 shards
num_shards, num_imgs = 200, 300
idx_shard = [i for i in range(num_shards)]
dict_users = {i: np.array([]) for i in range(num_users)}
idxs = np.arange(num_shards*num_imgs)
labels = dataset.train_labels.numpy()
# sort labels
idxs_labels = np.vstack((idxs, labels))
idxs_labels = idxs_labels[:, idxs_labels[1, :].argsort()]
idxs = idxs_labels[0, :]
# divide and assign 2 shards/client
for i in range(num_users):
rand_set = set(np.random.choice(idx_shard, 2, replace=False))
idx_shard = list(set(idx_shard) - rand_set)
for rand in rand_set:
dict_users[i] = np.concatenate(
(dict_users[i], idxs[rand*num_imgs:(rand+1)*num_imgs]), axis=0)
return dict_users- num_shards:把60000个训练集图片分为200份
- [i for i in range()]:可以生成一个递增list
- {i: np.array([]) for i in range(num_users)}:以大括号生成100个用户的字典
- np.vstack((idxs, labels)):把编号和标签堆叠起来,形成一个(2,60000)的数组
- idxs_labels = idxs_labels[:, idxs_labels[1, :].argsort()]:argsort函数的作用是,输出数组中的元素从小到大排序后的索引数组值
经过筛选之后,获得了由小到大的标签索引idxs。然后进行用户分片。
- np.random.choice():从切片序号中选出两个序号,replace参数表示不放回取样
- idxs[rand*num_imgs:(rand+1)*num_imgs]:取连续的300个排序后的索引号
- np.concatenate():从哪个维度拼哪个维度就会增加,这里从200个索引号中随机选取了两个随机数,把这两个随机数对应位置的数据给连起来了
最后函数返回了每个用户以及所对应的600个数据的字典。
3.mnist_noniid()
def mnist_noniid_unequal(dataset, num_users):
"""
Sample non-I.I.D client data from MNIST dataset s.t clients
have unequal amount of data
:param dataset:
:param num_users:
:returns a dict of clients with each clients assigned certain
number of training imgs
"""有点长,我分着说。把60000张数据分为1200份:
# 60,000 training imgs --> 50 imgs/shard X 1200 shards
num_shards, num_imgs = 1200, 50
idx_shard = [i for i in range(num_shards)]
dict_users = {i: np.array([]) for i in range(num_users)}
idxs = np.arange(num_shards*num_imgs)
labels = dataset.train_labels.numpy()获得排序后的索引号:
# sort labels
idxs_labels = np.vstack((idxs, labels))
idxs_labels = idxs_labels[:, idxs_labels[1, :].argsort()]
idxs = idxs_labels[0, :]设置每个用户所持有的数据份数范围:
# Minimum and maximum shards assigned per client:
min_shard = 1
max_shard = 30也就是说,每个用户至少拥有1×50=50张图片,至多拥有30*50=1500张图片。
接下来要把这1200份分给这些用户,并且保证每个用户至少被分到一个数据,且每个数据都要被分到。
# Divide the shards into random chunks for every client
# s.t the sum of these chunks = num_shards
random_shard_size = np.random.randint(min_shard, max_shard+1,
size=num_users)
random_shard_size = np.around(random_shard_size /
sum(random_shard_size) * num_shards)
random_shard_size = random_shard_size.astype(int)- np.random.randint:返回为一个前闭后开的区间的列表,长度为用户数量
- np.around:四舍六入,五归偶数
经过这一步,所有的份数都被等比地调整,使其总和接近于为1200。(因为有小数被四舍六入,所以不严格等于1200)所以接下来就要针对这不严格的部分进行调整和分配。
# Assign the shards randomly to each client
if sum(random_shard_size) > num_shards:
for i in range(num_users):
# First assign each client 1 shard to ensure every client has
# atleast one shard of data
rand_set = set(np.random.choice(idx_shard, 1, replace=False))
idx_shard = list(set(idx_shard) - rand_set)
for rand in rand_set:
dict_users[i] = np.concatenate(
(dict_users[i], idxs[rand*num_imgs:(rand+1)*num_imgs]),
axis=0)
random_shard_size = random_shard_size-1
# Next, randomly assign the remaining shards
for i in range(num_users):
if len(idx_shard) == 0:
continue
shard_size = random_shard_size[i]
if shard_size > len(idx_shard):
shard_size = len(idx_shard)
rand_set = set(np.random.choice(idx_shard, shard_size,
replace=False))
idx_shard = list(set(idx_shard) - rand_set)
for rand in rand_set:
dict_users[i] = np.concatenate(
(dict_users[i], idxs[rand*num_imgs:(rand+1)*num_imgs]),
axis=0)
else:
for i in range(num_users):
shard_size = random_shard_size[i]
rand_set = set(np.random.choice(idx_shard, shard_size,
replace=False))
idx_shard = list(set(idx_shard) - rand_set)
for rand in rand_set:
dict_users[i] = np.concatenate(
(dict_users[i], idxs[rand*num_imgs:(rand+1)*num_imgs]),
axis=0)
if len(idx_shard) > 0:
# Add the leftover shards to the client with minimum images:
shard_size = len(idx_shard)
# Add the remaining shard to the client with lowest data
k = min(dict_users, key=lambda x: len(dict_users.get(x)))
rand_set = set(np.random.choice(idx_shard, shard_size,
replace=False))
idx_shard = list(set(idx_shard) - rand_set)
for rand in rand_set:
dict_users[k] = np.concatenate(
(dict_users[k], idxs[rand*num_imgs:(rand+1)*num_imgs]),
axis=0)
return dict_users最后会获得随机分配的用户持有的非IID数据的索引字典.。
4.cifar_iid()、cifar_noniid()
没有区别,不写了
三、本地模型参数更新——update.py
1.DatasetSplit(Dataset)
先来看看Dataset类的官方解释:Dataset可以是任何东西,但它始终包含一个__len__函数(通过Python中的标准函数len调用)和一个用来索引到内容中的__getitem__函数。
class DatasetSplit(Dataset):
"""An abstract Dataset class wrapped around Pytorch Dataset class.
"""
def __init__(self, dataset, idxs):
self.dataset = dataset
self.idxs = [int(i) for i in idxs]
def __len__(self):
return len(self.idxs)
def __getitem__(self, item):
image, label = self.dataset[self.idxs[item]]
return torch.tensor(image), torch.tensor(label)这部分代码重写了Dataset类:
- 重写了__len__(self)方法,返回数据列表长度,即数据集的样本数量
- 重写了__getitem__(self,item)方法,获取image和label的张量
2.LocalUpdate(object)
这是本地更新模型的代码,有点多我分着说:
class LocalUpdate(object):...首先是构造函数,首先定义了参数和日志,然后从train_val_test()函数获取了数据加载器,随后指定了运算设备。
比较重要的是这里的损失函数是NLL损失函数,它跟交叉熵相似,唯一的区别在于NLL的log里面对结果进行了一次Softmax。
def __init__(self, args, dataset, idxs, logger):
self.args = args
self.logger = logger
self.trainloader, self.validloader, self.testloader = self.train_val_test(
dataset, list(idxs))
self.device = 'cuda' if args.gpu else 'cpu'
# Default criterion set to NLL loss function
self.criterion = nn.NLLLoss().to(self.device)接下来是train_val_test()函数,它用来分割数据集。输入数据集和索引,按照8:1:1来划分。注意到在指定batchsize的时候,除了训练集是从args参数里指定的,val和test都是取了总数的十分之一。
def train_val_test(self, dataset, idxs):
"""
Returns train, validation and test dataloaders for a given dataset
and user indexes.
"""
# split indexes for train, validation, and test (80, 10, 10)
idxs_train = idxs[:int(0.8*len(idxs))]
idxs_val = idxs[int(0.8*len(idxs)):int(0.9*len(idxs))]
idxs_test = idxs[int(0.9*len(idxs)):]
trainloader = DataLoader(DatasetSplit(dataset, idxs_train),
batch_size=self.args.local_bs, shuffle=True)
validloader = DataLoader(DatasetSplit(dataset, idxs_val),
batch_size=int(len(idxs_val)/10), shuffle=False)
testloader = DataLoader(DatasetSplit(dataset, idxs_test),
batch_size=int(len(idxs_test)/10), shuffle=False)
return trainloader, validloader, testloader接下来是本地权重更新函数,输入模型和全局更新的回合数,输出更新后的权重和损失平均值。首先选择了优化器,然后开始训练循环。
def update_weights(self, model, global_round):
# Set mode to train model
model.train()
epoch_loss = []
# Set optimizer for the local updates
if self.args.optimizer == 'sgd':
optimizer = torch.optim.SGD(model.parameters(), lr=self.args.lr,
momentum=0.5)
elif self.args.optimizer == 'adam':
optimizer = torch.optim.Adam(model.parameters(), lr=self.args.lr,
weight_decay=1e-4)
for iter in range(self.args.local_ep):
batch_loss = []
for batch_idx, (images, labels) in enumerate(self.trainloader):
images, labels = images.to(self.device), labels.to(self.device)
model.zero_grad()
log_probs = model(images)
loss = self.criterion(log_probs, labels)
loss.backward()
optimizer.step()
if self.args.verbose and (batch_idx % 10 == 0):
print('| Global Round : {} | Local Epoch : {} | [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
global_round, iter, batch_idx * len(images),
len(self.trainloader.dataset),
100. * batch_idx / len(self.trainloader), loss.item()))
self.logger.add_scalar('loss', loss.item())
batch_loss.append(loss.item())
epoch_loss.append(sum(batch_loss)/len(batch_loss))
return model.state_dict(), sum(epoch_loss) / len(epoch_loss)- self.logger.add_scalar('loss', loss.item()):这个函数是用来保存程序中的数据,然后利用tensorboard工具来进行可视化的
- 每经过一次本地轮次,统计当前的loss,用于最后的平均损失统计
- model.state_dict():是Pytorch中用于查看网络参数的方法,可以用torch.save()保存成pth文件
接下来是评估函数:inference(self,model)。输入为模型,计算准确值、loss值,这里的代码很有参考意义:
def inference(self, model):
""" Returns the inference accuracy and loss.
"""
model.eval()
loss, total, correct = 0.0, 0.0, 0.0
for batch_idx, (images, labels) in enumerate(self.testloader):
images, labels = images.to(self.device), labels.to(self.device)
# Inference
outputs = model(images)
batch_loss = self.criterion(outputs, labels)
loss += batch_loss.item()
# Prediction
_, pred_labels = torch.max(outputs, 1)
pred_labels = pred_labels.view(-1)
correct += torch.sum(torch.eq(pred_labels, labels)).item()
total += len(labels)
accuracy = correct/total
return accuracy, loss- model.eval():开启模型的评估模式
- torch.max():第二个参数指维度,即返回第1维度(即行),这里返回了虽大数值的索引
- pred_labels.view(-1):本意是根据另外一个数来自动调整维度,但是这里只有一个维度,因此就会将X里面的所有维度数据转化成一维的,并且按先后顺序排列。
- torch.eq():对两个张量Tensor进行逐元素的比较,若相同位置的两个元素相同,则返回True;若不同,返回False。
这里的函数通取测试集图像和标签,模型出结果后计算loss然后累加,
3.test_inference(self,model)
与LocalUpdate中的inference函数完全一致,只不过这里的输入参数除了args和model,还要指定test_dataset:
def test_inference(args, model, test_dataset):
""" Returns the test accuracy and loss.
"""
model.eval()
loss, total, correct = 0.0, 0.0, 0.0
device = 'cuda' if args.gpu else 'cpu'
criterion = nn.NLLLoss().to(device)
testloader = DataLoader(test_dataset, batch_size=128,
shuffle=False)
for batch_idx, (images, labels) in enumerate(testloader):
images, labels = images.to(device), labels.to(device)
# Inference
outputs = model(images)
batch_loss = criterion(outputs, labels)
loss += batch_loss.item()
# Prediction
_, pred_labels = torch.max(outputs, 1)
pred_labels = pred_labels.view(-1)
correct += torch.sum(torch.eq(pred_labels, labels)).item()
total += len(labels)
accuracy = correct/total
return accuracy, loss四、应用集——utils.py
这里面封装了一些工具函数:get_dataset(),average_weights(),exp_details()
1.get_dataset(args)
get_dataset(args)根据命令台参数获取相应的数据集和用户数据字典。就是个if else,有点简单就不说了。
2.average_weights(w)
返回权重的平均值,即执行联邦平均算法:
def average_weights(w):
"""
Returns the average of the weights.
"""
w_avg = copy.deepcopy(w[0])
for key in w_avg.keys():
for i in range(1, len(w)):
w_avg[key] += w[i][key]
w_avg[key] = torch.div(w_avg[key], len(w))
return w_avg- w:这个w是经过多轮本地训练后统计的权重list,在参数默认的情况下,是一个长度为10的列表,而每个元素都是一个字典,每个字典都包含了模型参数的名称(比如layer_input.weight或者layer_hidden.bias),以及其权重具体的值。
- copy.deepcopy():深度复制,被复制的对象不会随着复制的对象的改变而改变。这里复制了第一个用户的权重字典。
随后,对于每一类参数进行循环,累加每个用户模型里对应参数的值,最后取平均获得平均后的模型。
3.exp_details(args)
可视化命令台参数args:
def exp_details(args):
print('\nExperimental details:')
print(f' Model : {args.model}')
print(f' Optimizer : {args.optimizer}')
print(f' Learning : {args.lr}')
print(f' Global Rounds : {args.epochs}\n')
print(' Federated parameters:')
if args.iid:
print(' IID')
else:
print(' Non-IID')
print(f' Fraction of users : {args.frac}')
print(f' Local Batch size : {args.local_bs}')
print(f' Local Epochs : {args.local_ep}\n')
return五、模型设置——models.py
这个文件设置了一些比较常见的网络模型
1.MLP多层感知机模型
class MLP(nn.Module):
def __init__(self, dim_in, dim_hidden, dim_out):
super(MLP, self).__init__()
self.layer_input = nn.Linear(dim_in, dim_hidden)
self.relu = nn.ReLU()
self.dropout = nn.Dropout()
self.layer_hidden = nn.Linear(dim_hidden, dim_out)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = x.view(-1, x.shape[1]*x.shape[-2]*x.shape[-1])
x = self.layer_input(x)
x = self.dropout(x)
x = self.relu(x)
x = self.layer_hidden(x)
return self.softmax(x)- nn.Dropout():你懂得,不懂就搜
2.CNN卷积神经网络
太多了不予展示。
3.自创模型
这里原代码是modelC,其构造函数下,super第一个参数是AllConvNet,在编译器中会报错。但是这里并非打错,而是让用户自定义。
六、主函数——federated_main.py
(这里我贴的代码是我更改了注释的)
首先是库的引用:
import os
import copy
import time
import pickle
import numpy as np
from tqdm import tqdm
import torch
from tensorboardX import SummaryWriter
from options import args_parser
from update import LocalUpdate, test_inference
from models import MLP, CNNMnist, CNNFashion_Mnist, CNNCifar
from utils import get_dataset, average_weights, exp_details随后直接开始主函数:
if __name__ == '__main__':
start_time = time.time()
# 定义路径
path_project = os.path.abspath('..') # 上级目录的绝对路径
logger = SummaryWriter('../logs') # python可视化工具
args = args_parser() # 输入命令行参数
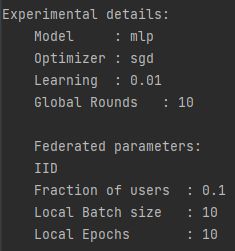
exp_details(args) # 显示命令行参数情况由于是调试状态运行,所以没有更改参数,参数情况如下所示:
接下来加载数据集和用户数据字典:
# 判断GPU是否可用:
if args.gpu:
torch.cuda.set_device(args.gpu)
device = 'cuda' if args.gpu else 'cpu'
# 加载数据集,用户本地数据字典
train_dataset, test_dataset, user_groups = get_dataset(args)这里会返回60000的训练集,10000的测试集,以及长度为100的用户字典,用户字典是100个用户到各自600个IID训练数据的映射。
然后开始建立模型,这里模型选择的是多层感知机:
# 建立模型
if args.model == 'cnn':
# 卷积神经网络
if args.dataset == 'mnist':
global_model = CNNMnist(args=args)
elif args.dataset == 'fmnist':
global_model = CNNFashion_Mnist(args=args)
elif args.dataset == 'cifar':
global_model = CNNCifar(args=args)
elif args.model == 'mlp':
# 多层感知机
img_size = train_dataset[0][0].shape
len_in = 1
for x in img_size:
len_in *= x
global_model = MLP(dim_in=len_in, dim_hidden=64,
dim_out=args.num_classes)
else:
exit('Error: unrecognized model')接下来就是设置模型进行第一轮训练,并复制权重:
# 设置模型进行训练,并传输给计算设备
global_model.to(device)
global_model.train()
print(global_model)
# 复制权重
global_weights = global_model.state_dict()模型如下所示:
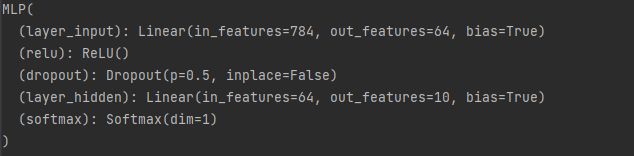
这是一个输入层784个,隐藏层64个,输出层10个的多层感知机,且设置了0.5的Dropout。
然后就开始正式训练:
# 训练
train_loss, train_accuracy = [], []
val_acc_list, net_list = [], []
cv_loss, cv_acc = [], []
print_every = 2
val_loss_pre, counter = 0, 0
for epoch in tqdm(range(args.epochs)):
local_weights, local_losses = [], []
print(f'\n | Global Training Round : {epoch + 1} |\n')
global_model.train()
m = max(int(args.frac * args.num_users), 1) # 随机选比例为frac的用户
idxs_users = np.random.choice(range(args.num_users), m, replace=False)
for idx in idxs_users:
local_model = LocalUpdate(args=args, dataset=train_dataset,
idxs=user_groups[idx], logger=logger)
w, loss = local_model.update_weights(
model=copy.deepcopy(global_model), global_round=epoch)
local_weights.append(copy.deepcopy(w))
local_losses.append(copy.deepcopy(loss))
# 联邦平均,更新全局权重
global_weights = average_weights(local_weights)
# 将更新后的全局权重载入模型
global_model.load_state_dict(global_weights)
loss_avg = sum(local_losses) / len(local_losses)
train_loss.append(loss_avg)
# 每轮训练,都要计算所有用户的平均训练精度
list_acc, list_loss = [], []
global_model.eval()
for c in range(args.num_users):
local_model = LocalUpdate(args=args, dataset=train_dataset,
idxs=user_groups[idx], logger=logger)
acc, loss = local_model.inference(model=global_model)
list_acc.append(acc)
list_loss.append(loss)
train_accuracy.append(sum(list_acc) / len(list_acc))
# 每i轮打印全局Loss
if (epoch + 1) % print_every == 0:
print(f' \nAvg Training Stats after {epoch + 1} global rounds:')
print(f'Training Loss : {np.mean(np.array(train_loss))}')
print('Train Accuracy: {:.2f}% \n'.format(100 * train_accuracy[-1]))- 老实说除了train_loss,train_accuracy和print_every之外我都不知道其他的是干嘛的
- tqdm是一个功能强大的进度条,支持在for循环中展示运行时间和进度
- global_model.train():将模型设置为训练模式
- idxs_users:随机选取用户的索引列表,这里来说,用户选取比例为0.1,用户总数100,那么就会随机抽取100×0.1=10个用户参与训练
- 执行本地更新:对于选取的用户执行本地更新,数据集索引由user_groups[idx]获得,并记录更新后的本地参数和损失值
- 联邦平均:把模型参数字典传入更新函数,返回平均后的模型参数字典,再载入到全局模型中
每轮结束都统计所有100个用户的训练精度,每 轮都打印全局损失值。
轮都打印全局损失值。

(注意,你跑模型不停滚动的什么Global Round,Local Epoch,那都是update.py里面的调用LocalUpdate类里的update_weights方法形成的,如果不想他这么频繁的滚动,到这个函数底下注释掉即可)
全局训练后,模型在测试集的表现:
# 训练后,测试模型在测试集的表现
test_acc, test_loss = test_inference(args, global_model, test_dataset)
print(f' \n Results after {args.epochs} global rounds of training:')
print("|---- Avg Train Accuracy: {:.2f}%".format(100 * train_accuracy[-1]))
print("|---- Test Accuracy: {:.2f}%".format(100 * test_acc))结果:
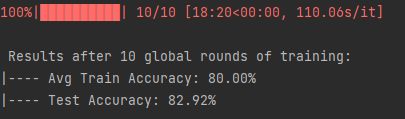
最后就是保存目标训练损失和训练精度了,最后输出时间。
# 保存目标训练损失和训练精度
file_name = '../save/objects/{}_{}_{}_C[{}]_iid[{}]_E[{}]_B[{}].pkl'. \
format(args.dataset, args.model, args.epochs, args.frac, args.iid,
args.local_ep, args.local_bs)
with open(file_name, 'wb') as f:
pickle.dump([train_loss, train_accuracy], f)
print('\n Total Run Time: {0:0.4f}'.format(time.time() - start_time))- pkl文件:pickle.dump(数据,f)为写入,pickle.load(文件名)为读出,这里保存了Loss和Accuracy
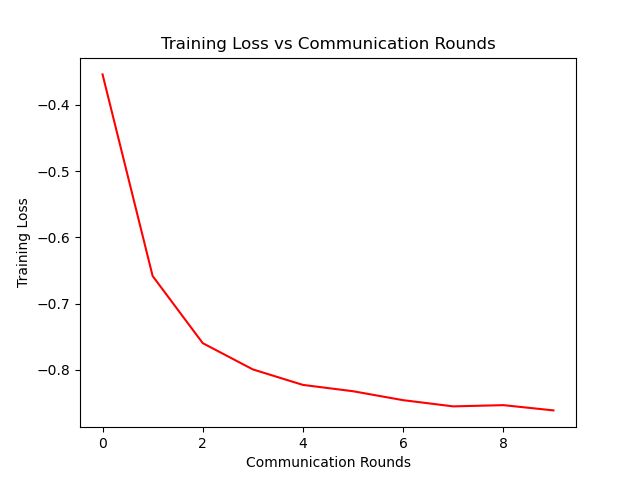
七、作图
在代码的最后,作者用注释写出的作图代码:
# 画图
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use('Agg')
# 绘制损失曲线
plt.figure()
plt.title('训练损失 vs 通信回合数')
plt.plot(range(len(train_loss)), train_loss, color='r')
plt.ylabel('训练损失')
plt.xlabel('通信回合数')
plt.savefig('../save/fed_{}_{}_{}_C[{}]_iid[{}]_E[{}]_B[{}]_loss.png'.
format(args.dataset, args.model, args.epochs, args.frac,
args.iid, args.local_ep, args.local_bs))
# 平均准度曲线
plt.figure()
plt.title('平均准度 vs 通信回合数')
plt.plot(range(len(train_accuracy)), train_accuracy, color='k')
plt.ylabel('平均准度')
plt.xlabel('通信回合数')
plt.savefig('../save/fed_{}_{}_{}_C[{}]_iid[{}]_E[{}]_B[{}]_acc.png'.
format(args.dataset, args.model, args.epochs, args.frac,
args.iid, args.local_ep, args.local_bs))做图如下:
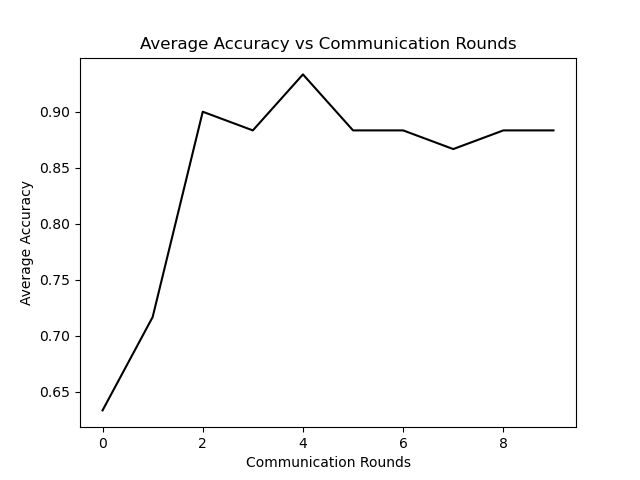
八、个人总结
这次细读代码让我收获良多,包括代码的组织,一些库的应用以及最重要的联邦学习的机理,作者用简单易懂的代码写出了一篇如此有意义的文章,是在敬佩。不但提高了我的码力,也让我正式跨进fl的大门。