Learning color and locality cues for moving object detection and segmentation方法解析
Learning color and locality cues for moving object detection and segmentation方法解析
标签(空格分隔): detection segmentation MRF Machine-learning
作者:贾金让
本人博客链接:http://blog.csdn.net/jiajinrang93
1.概述
文章名称:Learning color and locality cues for moving object detection and segmentation
文章来源:2009CVPR
文章作者:Feng Liu and Michael Gleicher
文章原文:在本文最后有论文原文
简要介绍:这篇文章来自2009年的CVPR会议论文,其提出了一种从单眼视频中自动检测和分割移动物体的算法。算法相比于之前存在的其他算法的优势在于,在目标的移动是部分位置移动并且是部分帧存在移动的情况下,算法仍然可以检测并分割出整个物体,同时具有良好的鲁棒性。
基本原理:算法首先通过像素位移提取关键帧,并在关键帧中根据像素位移使用MRF网络寻找“子移动物体”(moving sub-objects),之后在子移动物体的基础上采用GMM学习得到一个物体颜色模型和局部线索,最后将颜色模型和局部线索组合到MRF网络中,提取出整个移动物体。
下面具体叙述和分析该算法的理论。
2. 从检测移动物体开始
给定一段视频,如何检测并分割出其中的移动物体,是我们所要研究的问题的本质。
当今存在的大多数方法,都是在视频中含有丰富的物体移动信息和相机移动信息的情况下提出的。然而,在物体或相机只有微小或部分移动的条件下,进行运动目标检测和分割仍旧是一个很重要的研究方向。大多数方法在小移动情况下并不适用。
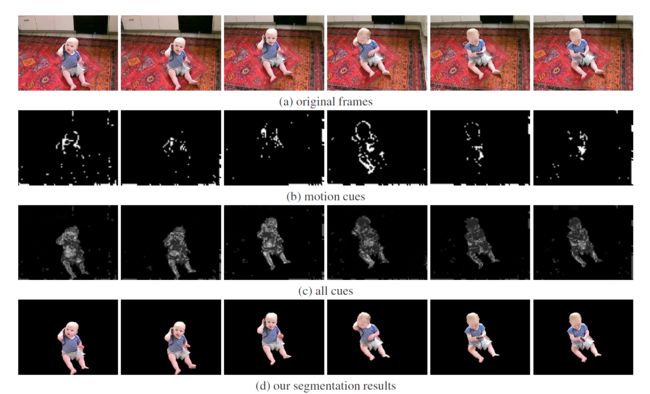
比如,大多数方法都是用位移量(motion)来判断物体的移动,它们假设如果有一块区域和背景的位移量不同,那么它就可能属于移动物体的一部分,这就是基于位移的方法。基于位移的方法通常把检测到的移动像素作为种子,然后将和它有相同位移的像素连接起来作为构成移动物体。然而这种方法在物体的移动是稀疏的或是不完整的时候,没有鲁棒性,表现很差,比如下面这个例子,如图。
一个小孩子坐在地上,每次移动只移动身体的一部分,如果使用前面说的基于位移的方法,得到的结果如图(b)、(c)所示,只能检测到身体的一部分,而如果使用本文提出的方法,则可以得到如图(d)、(e)的结果。
本文提出了一种算法,通过在视频中搜集稀疏和不完整的移动信息来学习移动物体的模型。
下面给出本文算法的主要步骤:
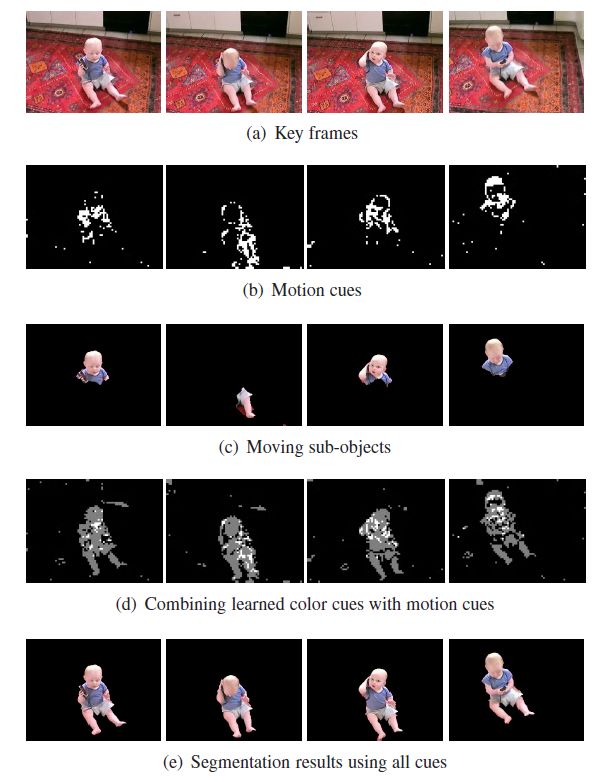
a.提取关键帧:我们首先通过移动线索检测关键帧,关键帧包含物体的移动线索(motion cues),可以可靠地表达移动物体的一些部分。
b.估计移动子物体:从这些关键帧中,我们使用MRF模型在移动线索的基础上估计出移动子物体。
c.学习颜色模型:接着我们从这些移动子物体中学习到一个移动目标的颜色模型(以GMM模型分类)。
d.学习局部线索:为了避免对和移动子物体有相同颜色的背景像素错误检测,我们把移动子物体的坐标信息当成局部线索传递给非关键帧。
e.提取移动物体:最后我们通过将学习到的颜色和局部线索与MRF网络中的移动线索相结合,提取出移动物体。
3.移动线索(motion cues)
我们认为,视频中的移动物体其实可以当做一些像素聚合区域,如果存在某个像素聚合区域的整体位移和图像背景位置的差别较大,那就说明这个像素聚合区域是移动物体或是移动物体的一部分。这是符合实际情况的。因此,如果一个像素/区域和背景有明显的移动区别,那它很可能属于一个移动物体。
移动线索(motion cues)由像素位移和背景位移的差值来定义。
我们通过有力的移动线索来提取关键帧。
之后再从这些关键帧中,依据移动线索使用MRF来估计移动子物体。
那么首先要计算出移动线索,我们先假设场景中背景是固定不同的。在这个假设的基础上,移动线索就可以由局部位移和全局整体位移的差值来计算。计算全局位移的方法有很多,由于全局位移在连续帧中变化很微小,所以我们要先计算单应(homography),单应就是两张图片之间的投影关系,我们使用SIFT特征来计算单应,因为SIFT特征在视频质量较差情况下仍然具有很好的鲁棒性。也就是说,我们从每一帧图像中提取SIFT特征,并且建立相邻帧之间的特征关系,并通过RANSAC算法计算单应。
有了单应之后,就可以计算移动线索了,通过下面的公式计算移动线索。
其中 mc(x,y) 是 (x,y) 点的移动线索, mo(x,y) 是该点的光流, mg(x,y) 是全局位移量。由于直接计算光流会由于噪声等原因引入误差,因此我们使用光流来增加鲁棒性。
4.提取关键帧(Key frame extraction)
什么是关键帧,我们定义的关键帧为:从该帧中的移动线索可以可靠地得到一个移动物体或移动物体的一部分,那么这一帧就是关键帧。
因此,我们给出两个依据移动线索提取关键帧的标准:
第一个标准对图像中被看做有效移动像素的个数,只有数量大于 minArea 才能算做关键帧。
第二个标准的左边通过计算位置的方差来衡量潜在目标像素的空间分布。通过这种方法,第二个标准要求一个关键帧有紧凑的移动线索。也即要求有效的移动像素在空间位置上聚集在一起。
5.从关键帧中提取移动子物体(Segment moving sub-objects from key frames)
只使用移动线索来确定移动物体是有局限的:
第一:不是移动物体的所有像素都有明显的移动线索。就如前面的孩子的例子,其移动线索就是稀疏的。
第二:移动物体的移动并非贯穿整个视频,甚至当物体移动时,只有它的一部分有明显的移动。
在这部分,我们目的在于提取出移动物体的在当前帧的几个移动部分,以此解决第二个问题。我们称这些部分为:移动子物体。
而第一个问题可以通过考虑相邻像素标签的相互作用来解决:
1.相邻像素有可能有相同的标签;
2.有相同颜色的相邻元素有更大可能有相同的标签。
所以我们使用MRF网络来描述这种像素之间的相似性:
其中 li 是像素 i 的标签,li=−1 表示属于移动物体, li=1 表示属于背景物体, M 是图像中的像素个数,Ni 是像素i的8个邻域像素。 d(i,j) 衡量两个像素之间的颜色差。
因此对于关键帧来说,移动线索对于预测物体的移动部分是可靠的,所以,给定标签的一张图片 I 的似然概率可以表示为:
其中 fi 是像素 i 的特征,mci 是像素 i 点的移动线索,δm 是参数。
有了上面两个公式,即得到了MRF先验概率和似然模型,那么对于一张关键帧图像来说,运动物体分割就可以通过找到使下面的表达式最大的标签值来实现:
上面的表达式的求解很容易,有很多算法可以解决这个优化问题,本文采用的是graph cut algorithm,原因是此算法针对二元MRF可以快速找到全局最优点
至此,已经可以提取出视频的移动子物体并做出分割,即达到图1的(c)的效果,然而我们想要得到的是整个运动物体,因此还需要进行颜色模型的学习和局部线索的获取,从而获得整个运动物体。
6.学习颜色模型(Learning color cues)
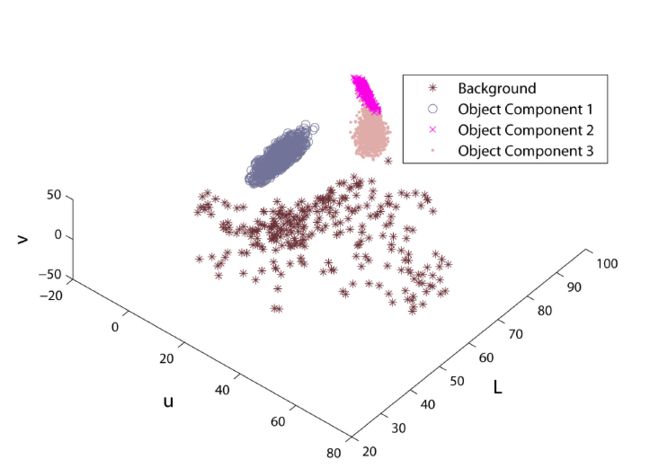
在本部分,我们首先假设从所有关键帧中提取出的移动子物体可以构成视频中对运动物体的完整采样,这就意味着运动物体的任何一个部分都会在关键帧中出现过至少一次。
基于上面这个假设,运动物体的颜色分布就可以被一个**高斯混合模型(Gaussian
Mixture Model,GMM)**来描述。
一个高斯混合模型可以被参数化地表示为 gi(pi,μi,Σi) , i=1,...,n 其中 n 是高斯分量的个数,Σi,μi和 pi 分别是颜色均值向量,协方差矩阵和 gi 的先验概率分布。
文章使用由关键帧得到的移动子物体来训练一个高斯混合模型 Gf 。学习是通过EM算法完成的。
一个像素在颜色c上对移动物体的亲和力 Gf 可以表示为:
因此,基于上式的似然模型可以表示为:
其中 δc 是参数。
不可避免地,由于检测到的移动子物体会包含有一些背景像素,因此运动物体模型 Gf 会含有一些错误的高斯成分。这些错误的成分在检查成分和背景像素之间的亲和度时会被检查出来,如果一个成分 g 和背景像素太过相近,它应该被排除在外,从Gf 中剔除。
我们通过计算一个成分 g 和移动子物体边缘的背景像素的距离来衡量其和背景像素的相似度。如果一个移动子物体周围很多像素都和g 很接近,那么 g 就有很大可能是个错误的成分。根据这个思路,我们都过下面的式子计算亲和相似度:
其中 F 是所有移动子物体的集合,B 是所有这些子物体边缘的集合。 1expr 是一个指示函数,当 expr 为真时等于1,否则等于0。分母是所有属于成分 g 的B 中的像素的总和。 Ni 是 pi 的8邻域。 g(pi) 是 pj 和 g 的相似程度。
学习得到的GMM模型可以表示如下图:
7.学习局部线索(Learning locality cues)
当背景颜色和运动物体颜色相近时,只有颜色模型是不够的。我们要用关键帧中的移动子物体的位置来提供局部线索来结局颜色上的近似。
由于运动物体的形状是任意的,我们使用一个基于真实数据的非参数模型来计算一个像素和运动物体的空间相似性:
affitx(xi) 是关键帧 t 中的像素i 和移动子物体 F 的空间相似度,xi 是像素 i 的位置。
和之前的颜色线索类似,基于上面相似度的似然模型可以表示成:
8.运动物体分割(Moving object segmentation)
得到了颜色模型和局部线索之后,我们就可以扩展我们的MRF模型了,将颜色模型和局部线索加入到公式6中去来得到整个运动物体的模型。接下来要将MRF模型从关键帧扩展到整个视频,不过因为移动线索是稀疏的和不完整的,同时局部线索只在关键帧中有效,因此颜色模型会占主导地位,这会导致在背景中有和运动物体颜色相近的像素块的时候出现检测错误。为了解决这个问题,我们要把局部线索从关键帧扩展到其他帧去。我们使用下面的方法扩展局部线索同时进行运动物体的分割。
第一步是重新估计关键帧中的移动物体,我们通过将颜色模型和局部线索加入到公式6中来扩展了MRF模型:
第二步是将局部线索扩展到所有帧中去,具体方法如下图算法1,同时分割物体。
最后我们使用公式15重新估计运动物体,即完成所有步骤。

文章中提供了实验结果示意图,如下图所示: