数据库与数据仓库
数据库是一种逻辑概念,用来存放数据的仓库,通过数据库软件来实现。
数据仓库是数据库概念的升级。从逻辑上理解,数据库和数据仓库没有区别,从数据量来说,数据仓库要比数据库更庞大的多。数据仓库主要用于数据挖掘和数据分析,辅助做决策。
数据库 Database (Oracle, Mysql, PostgreSQL)主要用于事务处理,数据仓库 Datawarehouse (Amazon Redshift, Hive)主要用于数据分析。用途上的不同决定了这两种架构的特点不同。
各自特点
数据库(Database)的特点是:相对复杂的表格结构,存储结构相对紧致,少冗余数据。读和写都有优化。相对简单的read/write query,单次作用于相对的少量数据。
数据仓库(Datawarehouse)的特点是:相对简单的(Denormalized)表格结构,存储结构相对松散,多冗余数据。一般只是读优化。相对复杂的read query,单次作用于相对大量的数据(历史数据)。
用图书表格系统举例子。如果是数据库储存的话,表单的设计如下:
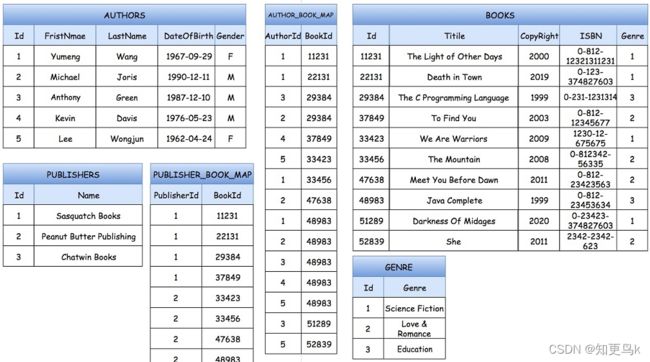 这里有六张表,分别记录了作者,图书,图书种类,发行商以及他们之间的关系。
这里有六张表,分别记录了作者,图书,图书种类,发行商以及他们之间的关系。
如果我们把以上数据用数据仓库来存储,表单设计需要对原始表单进行Denormalization(反规范化)。
实际是把这个数据库的五张表以Books.Title作为主键,用如下图的脚本使用**左连接(left join )**方式,拼表之后存到数据库仓库中.
-- Denormalization Script --
select
b.id,
b.title,
b.copyright,
b.isbn,
g.genre,
a.firstname as AuthorFirstName,
a.lastname as AuthorLastName,
a.dateofbirth,
a.gender,
p.name as PublisherName
from BOOKS b
left join GENRE g on b.genre = g.id
left join AUTHOR_BOOK_MAP abm on b.id = abm.bookid
left join AUTHORS a on a.id = abm.authorid
left join PUBLISHER_BOOK_MAP pbm on b.id = pbm.bookid
拼表之后,数据仓库中就只剩下一张表,如图所示:
 存储空间对比
存储空间对比
很明显,因为在denormalization的过程中,如果数据库主表
和次表不是一对一的关系,那么最终数据仓库主表或者次表一定会出现重复的数据。所以从存储空间角度讲,相比于数据库紧密的存储结构,数据仓库则存在大量冗余重复的数据。
读写优化对比
基本读(Read)操作对比下图所示的两种查询,一个是找一本书(PrimaryKey)的信息,另一个是找一位作者(Non-Key)所有的作品信息。由于数据库需要利用表之间的关联才能找到所有需要的数据,在效率上会相对低下。相比之下数据仓库把这些关联关系转化成重复数据记录到同一张表上了,查询效率相对就会较高。数据仓库相当于牺牲了空间换取了查询效率。

在数据库里面写这段query的时候,我们需要了解表单的结构与他们之间的关系——这对于做数据报告或者数据分析非常不友好,尤其是在表单结构很复杂的时候(比如表单使用了逻辑树的储存结构)。
这时候数据仓库简单明了的Denormalized表单结构就对于生成数据报告就非常有优势了。除此之外,由于数据报告和数据分析常常涉及到大规模的查询,这些查询很可能会占用很高的CPU资源,从而可能影响到数据库的常规读写操作——因为数据库常常是Single-Instance的(接下来会提到);这一点上数据仓库的Multi-instances.
大数据读(Read)操作对比
当数据量非常大的时候,特定条件下的数据仓库的读优化所带来的优势就开始碾压数据库了。大部分的数据库都是单事物(Single-instance)的,而数据仓库则是多事物Multi-instances的distributed system。
数据仓库在分配储存的节点的时候是根据主键PrimaryKey/PartitionKey来分配的,查询的时候不仅根据查询键的值来搜索对应节点位置,同时进行大量的并行查询。这使得在对大数据进行查询的时候有极大的优势。
但是,并不是所有的读操作,数据仓库一直都有优势。比如在如下两种情况时,数据仓库的读表现并不如数据库:
在对小量数据进行读取操作的时候,由于数据仓库要进行找Node的location之类的预运算,整体效率上反倒不如数据库。如果读取操作的目标不是主键
(PrimaryKey)或者分配键(PartitionKey),那么数据仓库的查询也需要进行全局扫描,效率上就不好说是否胜过数据库了。
这两点也是为什么现在即使有像Amazon Redshift这般强大的Datawarehouse应用,SQL Database仍然无法被取代的一部分主要原因。
写(Write)操作对比
大多数情况下,数据仓库不太会进行精确的写操作。因为冗余行数太多,有时候只是改一个很小的字段,也会修改大量的行数。而对于数据库来说,由于其紧凑的表格结构,写操作就可以非常精细有效了。比如,我需要修改某本书的版权,从2000改到2002,数据库里面只需要该一行,而数据仓库里面需要改5行。
数据仓库的写操作都是整段(表)刷新或者整段数据插入, 这也和它的用途——做数据分析有关系。由于数据仓库的整表刷新和分布式储存的特质,我们可以通过把PartitionKey设置成数据创建/更新的时间,然后记录一段时间内的历史数据。这对于数据分析以及利用数据进行决策都有重要意义。