IDL学习:语法基础-指针、链表
本博客将介绍IDL语法基础中的指针、链表的创建及相关的用法。记录自己的学习+整理+理解 。
1. 指针
指针也就是内存地址,是用来存放内存地址的变量,指针可以理解为通讯地址,可以通过通讯地址查询具体的信息,而指针可以查询所指向的变量,这变量可以是任何类型的变量(包括指针)。通过修改指针变量,则所指向的变量不会发生改变(无法通过指针改变变量)。
1.1 创建指针
可以利用函数ptr_new()创建一个指针变量。
语法:
Result = PTR_NEW( [InitExpr] [, / ALLOCATE_HEAP][,/NO_COPY])
1.1.1 创建指针
利用函数ptr_new()函数创建指针;
>>A = 'Hulz' ; 变量A
>>Ptr_A = Ptr_new(A) ; 指针变量Prt_A,是变量A的指针
>>help,PTR_A
PTR_A POINTER =
指针数组可以利用PtrArr()函数创建(相当于一次性建立若干个空指针);PtrArr() 函数返回一个指针向量或数组。 数组的各个元素设置为空指针。
Result = PTRARR( D1, ... …, D8 [, /ALLOCATE_HEAP ] )
需注意,当 InitExpr 参数时,PTR_NEW 会分配额外的内存来制作副本。 如果设置了 NO_COPY 关键字,则值数据将从 InitExpr 变量中取出并直接附加到堆变量中。 此功能可用于非常有效地移动数据。 但是,它具有导致 InitExpr 变量未定义的副作用。例如:
>>A = 'Hulz'
>>B = Ptr_new(A,/No_copy)
>>B
>>A ; 此时A编程未定义的变量
% Attempt to call undefined procedure: 'A'.
% Execution halted at: $MAIN$
>>help,*A
% Pointer type required in this context: A.
% Execution halted at: $MAIN$ 1.1.2 创建空指针
Ptr_new()函数不带参数,则生成的是空指针。当不存在其他初始化值时,IDL 使用它来初始化指针变量。
>>Ptr_B = Ptr_new() ; 空指针Prt_B,不指向任何变量,也不是指向null空值
>>Ptr_B
>>help,Ptr_B
PTR_B POINTER =
>>!null
!NULL
>>Ptr_C = Ptr_new(!null) ; 与Ptr_B相比,可知空指针不是指向null的指针
>>Ptr_C
>>help,Ptr_C
PTR_C POINTER = 主要区别在于可以将有用的值写入指向未定义变量的指针,但对于空指针,这是不可能的。
>>A = PTR_NEW()
>>B = PTR_NEW(/ALLOCATE_HEAP)
>>*B ; 指向空指针A的指针B
!NULL
>>*A ; 空指针
% Unable to dereference NULL pointer: A.
% Execution halted at: $MAIN$ 另外,ptr_new(0) 不等于空指针,它表示一个指向已用整数值 0 初始化的堆变量的指针。
>>A =ptr_new(0)
>>help,A
A POINTER =
>>*A
0 1.2 指针验证
利用可以Ptr_valid()函数验证指正的有效性,有效则返回1,反之则为0;
>>A = 'Hulz'
>>p_A = Ptr_new(A)
>>help,Ptr_valid(p_A)
BYTE = 1
>>help,Ptr_valid(p_B)
BYTE = 0
>>p_B
% Attempt to call undefined procedure: 'P_B'.
% Execution halted at: $MAIN$ 1.3 访问指针
指针可以通过“*指针变量”的方式进行访问(提取数据),也可以将“*指针变量”看做变量。
>>A = 'Hlz' ; 变量A
>>p_a = Ptr_new(A) ; 指针
>>print,*p_a
Hlz
>>*p_a = 'Ok' ; 改变指针p_a的值
>>print,*p_a
Ok
>>print,A
Hlz
>> ; 改变变量A的值,但指针并未变化
>>A = 'Lizhen'
>>print,A
Lizhen
>>print,*p_a ; 指针p_a并未变化
Ok
>>另外,需要注意的是,指针无法改变变量的值。
1.4 指针释放
指针创建会占据一定的内存,因此需要及时清理无用的指针。IDL中可以用prt_free过程来释放(删除)指针。
>>A = 'Hlz' ; 变量A
>>p_a = Ptr_new(A) ; 指针
>>print,*p_a
Hlz
>>ptr_free,p_a
>>print,*p_a
% Invalid pointer: P_A.
% Execution halted at: $MAIN$ 2. 链表
链表是一个可以包含其它数据类型的复合数据类型,这点与结构体有些相似,同时链表中元素的是有顺序的,可以像数组一样进行索引、操作。列表具有以下属性:
- 列表中的元素是有序的,并且在一维中被索引。
- 列表可以随着元素的添加或删除而改变它们的大小、增长和缩小。
- 单个列表元素可以更改其值和数据类型而不会降低性能。
- List 实现为指针的单链表。
链表和数组相似,但也有不同,具体如下:
- IDL 数组只能包含相同数据类型的元素。 元素存储在连续的内存块中。 添加或删除元素始终是一项昂贵的操作,因为必须分配新内存并且必须复制现有数组的所有元素。 索引数组中的单个元素总是很快的,因为可以使用简单的数学来确定内存位置。
- IDL 列表可以包含任何数据类型的元素。 元素存储为指向数据的指针的单链表。 从列表的开头或结尾添加或删除元素很快,因为列表包含指向头部和尾部的特殊指针。 从列表中间添加或删除元素会比较慢,因为必须遍历链表。 但是,即使在这种情况下,它仍然可能比使用数组更快,因为不需要复制内存。 索引到列表中间会比数组慢。
也可以参考链表和数组的区别 - QY428 - 博客园。
总之,可以将数组中的每个元素都用不同的变量(包括指针)代替,这样就相当于链表了。
2.1 创建链表
链表使用list()函数创建的,其语法如下:
Result = LIST( [Value1, Value2, ... Valuen] [, /EXTRACT] [, LENGTH=value] [, /NO_COPY])
>>A = List('h',3,Indgen(2),{Pig,name:'Pelosi',weight:'200Kg'},ptr_new())
>>A
% Procedure LIST::_FORMATVALUE can't be restored while
active.
% Procedure LIST::_OVERLOADIMPLIEDPRINT can't be restored
while active.
[
"h",
3,
[0, 1],
{
"NAME": "Pelosi",
"WEIGHT": "200Kg"
},
""
]
>> 2.2 访问链表
链表的访问和数组一样,可以利用索引实现。
>>A[3]
{
"NAME": "Pelosi",
"WEIGHT": "200Kg"
}
>>help,A[3]
** Structure PIG, 2 tags, length=32, data length=32:
NAME STRING 'Pelosi'
WEIGHT STRING '200Kg'2.3 链表操作方法
2.3.1 Add-新增
链表新增元素的语法如下,
list.Add,Value [, Index] [, /EXTRACT] [, /NO_COPY]
>>A.Add,'Hulz'
>>A
[
"h",
3,
[0, 1],
"Hulz"
]
>>2.3.2 Count-统计
统计链表元素的语法如下
Result = list.Count( [Value] )
>>N_A = A.Count()
>>N_A
4此外,还可以利用N_elements()函数统计链表元素个数。
>>print,N_elements(A)
42.3.3 Filte-过滤
链表的过滤筛选可以筛选满足条件的元素,语法如下,
Result = list.Filter( Function, Args )
; 本代码来自官方教程
; 创建一个名为 List_test.pro 的新文件,它只保留素数:
; myfilterfunction()函数监测数据时候为素数;
FUNCTION Myfilterfunction, value
Return, value LE 3 || Min(value MOD [2:Fix(Sqrt(value))])
END
; 使用您的函数仅返回数组中的素数:
PRO List_test
var = List([2:50], /EXTRACT)
newvar = var.Filter('myfilterfunction') ; 获取的是链表中满足条件元素的索引
Print, newvar.Toarray() ; 转列表一IDL阵列,利用索引,获取元素
END2.3.4 IsEmpty-是否为空
该方法是测试是否表为空白,空白则返回1,反之则返回0。
Result = list.IsEmpty( )
>>A= List('Hulizhen',2,Indgen(2,3),Ptr_new(0)) ; 非空的list
>>Result = A.Isempty()
>>help,Result
RESULT BYTE = 0
>>B = List() ; 空白的list
>>Result_B = B.Isempty()
>>help,Result_B
RESULT_B BYTE = 12.3.5 Map
通过每个列表的价值通过用户定义的函数或 Lambda 函数。用法如下:
Result = list.Map( Function, Args )
Function表示用户需要输入的函数,Args 表示需要输入Function的参数,可以理解为:
a.Map(F, b) 返回的一个列表,包含:
[F(a[0]、b[0]),F(a[1]、b[1]),F(a[2]、b[2])]
; 来自官方教程
; 创建一个名为listmap_test.PRO 的新文件,该文件返回三次 POLYNOMIAL:
; mymapfunction()函数根据输入的未知数X以及参数a、b、c获取方程的解
FUNCTION Mymapfunction, x, a, b, c
Return, (x - a)^3.0 + (x - b)^2 + (x - c)
END
PRO Listmap_test
; 使用您的功能将列表映射到新值:
var = List([-2: 2], /EXTRACT)
; 每个 var 值分别传入,及Mymapfunction()函数中的X
newvar = var.Map('mymapfunction', 1, 2, 0) ;计算mymapfunction()函数
print,'输入的列表,X的值'
Print, var.Toarray() ;根据索引(不输入则默认所有元素),获取元素
print,'方程的解'
Print,newvar.Toarray() ;根据索引(不输入则默认所有元素),获取元素
END
2.3.6 Move
该链表方法转移的一个元素从一个索引列表中的一个新的索引。 顺序的其他要素的列表中保持不变,虽然他们指数可能会被转移,基于位置的移动单元。 用法如下:
list.Move, Source, Destination
; 来自官方教程
>>list = LIST(0, 1, 2, 3, 4)
>>list.Move, 1,4 ; 将第一个移到第4个元素后面(从0开始数)
>>PRINT, list
0
2
3
4
12.3.7 NestedMap
通过每个列表的值随着八个其他的参数通过用户定义的函数或 Lambda 函数。 每一列表的值是合并与每一个元素从其他参数使用一套循环。 这种动作也称"名单的理解"或"笛卡尔的产品"。 你也可以提供一个可选的过滤功能,以去除不想要的结果。语法如下:
Result = list.NestedMap( Function, Args , FILTER=string)
list::NestedMap与list::Map的差异如下:
a.Map(F, b) 返回的一个列表,包含:
[F(a[0]、b[0]),F(a[1]、b[1]),F(a[2]、b[2])]
a.Nestedmap(F, b) 返回的一个列表,包含:
[F(a[0]、b[0]),F(a[1]、b[0]),F(a[2]、b[0]),
F(a[0]、b[1]),F(a[1]、b[1]),F(a[2]、b[1]),
F(a[0]、b[2]),F(a[1]、b[2]),F(a[2]、b[2])]
>>l1 = LIST('a', 'b', 'c')
>>l2 = LIST('d', 'e', 'f')
>>l3 = l1.NestedMap(Lambda(x,y:x+y), l2)
>>help, l3
L3 LIST
>>print, l3.ToArray()
ad bd cd ae be ce af bf cf 2.3.8 Reduce
通过每个数据值的累积,从左到右通过用户定义的函数或Lambda函数和返回的一个单一的标的结果。
Result = list.Reduce( Function, Args, /CUMULATIVE, VALUE=value)
2.3.9 Remove
删除链表中的元素,具体语法如下:
- list.Remove [, /ALL]
- list.Remove, Indices
- Value = list.Remove( [, /ALL] )
- Value = list.Remove( Indices )
>>list1 = list('Hu',18,{university,name:'xmu',Where:'Xiamen'},Ptr_new(0))
>>PRINT, list1
Hu
18
{ "NAME": "xmu", "WHERE": "Xiamen"}
>>list1.Remove, [2]
>>PRINT, list1
Hu
18
>>Value = list1.Remove(2) ; 移除的元素。此时链表中的元素也没了
>>Value
>>list1
[
"Hu",
18
] 2.3.10 Reverse
顺序反转,效果与数组一样,语法如下:
list.Reverse
>>list1 = list('Hu',18,{university,name:'xmu',Where:'Xiamen'},Ptr_new(0))
>>list1.Reverse
>>print,list1
{ "NAME": "xmu", "WHERE": "Xiamen"}
18
Hu 2.3.11 Sort
排序,所有列表元素进行排序并返回一个新列表。 语法如下:
result = list.Sort( COMPARE_FUNCTION=string, COUNT=integer, INDICES=variable, /OVERWRITE, /REVERSE )
>>list1 = List(9,-5,5,2,4)
>>result = list1.Sort( )
>>PRINT, result
-5
2
4
5
9更复杂的链表排序:
; 新建一个list_Sort_test.Pro文件
FUNCTION struct_compare, v1, v2
; 根据名称字段返回 -1、0 或 1
Return, (v1.NAME).Compare(v2.NAME)
END
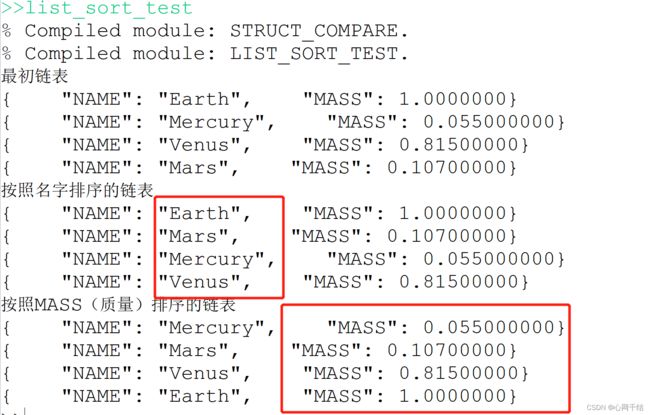
PRO list_Sort_test
void = {PLANET, NAME: "", MASS: 0.0}
p = List({PLANET, "Earth", 1}, {PLANET, "Mercury", 0.055}, $
{PLANET, "Venus", 0.815}, {PLANET, "Mars", 0.107})
result1 = p.Sort(COMPARE_FUNCTION='struct_compare')
print,'最初链表'
Print, p
Print, '按照名字排序的链表'
Print, result1
result2 = p.Sort(COMPARE_FUNCTION=Lambda(a,B:(a.MASS).Compare(b.MASS)))
Print, '按照MASS(质量)排序的链表'
Print, result2
END注:程序来自官方教程,结果如下
2.3.12 Swap
链表元素位置互换
list.Swap, Index1, Index2
>>list1 = LIST(0, 1, 2, 3, 4)
>>list1
[
0,
1,
2,
3,
4
]
>>list1.Swap, 1, 4
>>list1
[
0,
4,
2,
3,
1
]2.3.13 ToArray
将链表转化为数组,语法如下:
Result = list.ToArray( DIMENSION=value, MISSING=value, /NO_COPY, /PROMOTE_TYPE, /TRANSPOSE, TYPE=value )
2.3.14 Where
判断那些等于某个值的列表元素返回一个索引数组。
Result = list.Where( Value [, COMPLEMENT=variable] [, COUNT=variable] [, NCOMPLEMENT=variable] )
2.2.15 链表合并
可以利用加号进行合并,和字符串一样,形如:
链表1+连表[+l链表……]
此外,链表也能进行正则(EQ,NE,GE,GT,LE,LT)判断,
2.4 删除链表
可以利用Obj_destroy过程来销毁,语法如下:
Obj_destroy,list
不足之处,敬请斧正!
路漫漫其修远兮,吾将上下而求索