【数据分析】决策树预测用户流失
数据集说明
| 属性 | 描述 |
|---|---|
| customerID | 客户ID |
| gender | 客户性别 |
| SeniorCitizen | 客户是否是老年人(1, 0) |
| Partner | 客户是否有合作伙伴(是、否) |
| Dependents | 客户是否有家属(是、否) |
| tenure | 客户在公司停留的月数(入网时长) |
| PhoneService | 客户是否有电话服务(是、否) |
| MultipleLines | 客户是否有多条线路(是、否、没有电话服务) |
| InternetService | 客户的互联网服务提供商(DSL、光纤、否) |
| OnlineSecurity | 客户是否具有在线安全性(是、否、没有互联网服务) |
| OnlineBackup | 客户是否有在线备份(是、否、没有互联网服务) |
| DeviceProtection | 客户是否有设备保护(是、否、没有互联网服务) |
| TechSupport | 客户是否有技术支持(是、否、没有互联网服务) |
| StreamingTV | 客户是否有流媒体电视(是、否、没有互联网服务) |
| StreamingMovies | 客户是否有流媒体电影(是、否、没有互联网服务) |
| Contract | 客户的合同期限(每月、一年、两年) |
| PaperlessBilling | 客户是否有无纸化账单(是、否) |
| PaymentMethod | 客户的付款方式(电子支票、邮寄支票、银行转账(自动)、信用卡(自动)) |
| MonthlyCharges | 每月向客户收取的金额 |
| TotalCharges | 向客户收取的总金额 |
| Churn | 客户是否流失 |
问题:
已知用户的用户个人信息(gender、SeniorCitizen、Partner、Dependents)、
用户账户信息数据(tenure 、Contract 、PaperlessBilling、PaymentMethod、MonthlyCharges 、 TotalCharges)、
用户订阅服务数据(PhoneService、MultipleLines、InternetService 、OnlineSecurity、OnlineBackup、DeviceProtection、TechSupport、StreamingTV 、StreamingMovies)
来预测用户是否流失(Churn)
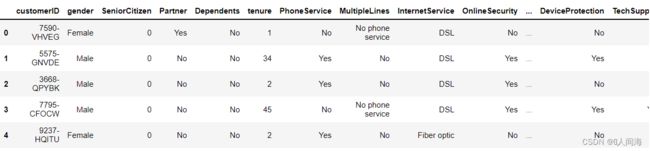
数据读取
df = pd.read_csv('Telco-Customer-Churn.csv')
df.head()
训练集 / 测试集划分
按理说,数据应该有两份,但是现在只有一份数据,我们可以通过按比例随机划分的方式来确定训练集(已知数据)
和测试集(假装它是未知数据)
test_ratio = 0.3
test_size = int(len(df)*test_ratio)
test_size
np.random.seed(920) #随机数种子,使用同一个种子得出的随机数序列是一样的
shuffle_index = np.random.permutation(len(df)) # 随机排列序列
shuffle_index
#测试集
test_index = shuffle_index[:test_size]
test_df = df.iloc[test_index]
test_df
#训练集
train_index = shuffle_index[test_size:]
train_df = df.iloc[train_index]
train_df
训练集–数据分析
为什么这里只用训练集呢,因为测试集的结果是未知的,需要去预测的,我们不能先把答案看了,再去做题
def churn_trans(x):
if x == 'Yes':
return 1
else:
return 0
train_df['churn_int'] = train_df['Churn'].apply(churn_trans)
train_df
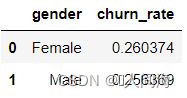
用户流失率的性别分布
这里我们关注的是用户流失率与用户性别之间的关系,所以要计算男性客户的流失率和女性客户的流失率
之前我们将用户流失情况转化为0和1,1代表流失,所以对churn_int这一项求平均数就表示流失率
gender_df = train_df.groupby('gender', as_index=False)['churn_int'].agg({'churn_rate':'mean'})
gender_df
x = ['男', '女']
y = [gender_df['churn_rate'][1], gender_df['churn_rate'][0]]
plt.figure(figsize=(8,8),dpi=80)
plt.style.use('ggplot')
plt.title("用户流失率-性别分布", size=24)
plt.xticks(size=16) # x轴字体大小调整
plt.yticks(size=16) # y轴字体大小调整
plt.bar(x, y, width=0.3, color='#6699CC')
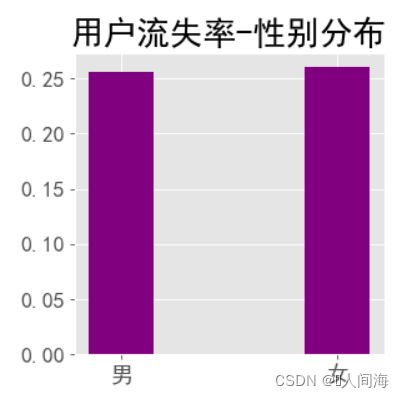
男女数量分布差不多,说明性别这个因素对用户流失没什么关系
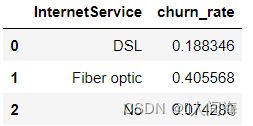
网络服务分布
internet_df = train_df.groupby('InternetService', as_index=False)['churn_int'].agg({'churn_rate':'mean'})
internet_df
x = ['DSL', 'Fiber optic', 'No']
y = [internet_df['churn_rate'][0], internet_df['churn_rate'][1], internet_df['churn_rate'][2]]
plt.figure(figsize=(20,8),dpi=80)
plt.style.use('ggplot')
plt.title("用户流失率-网络服务分布", size=24)
plt.xticks(size=16) # x轴字体大小调整
plt.yticks(size=16) # y轴字体大小调整
plt.bar(x, y, width=0.3, color='#6699CC')
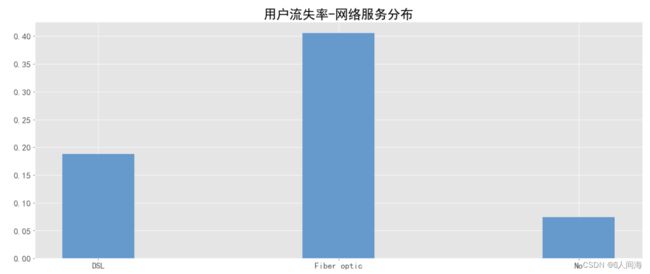
用户的不同互联网服务商对于用户流失的差别还是比较大的,说明这个因素对用户流失有一定影响
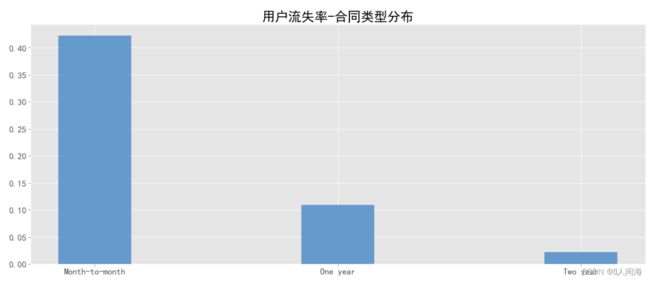
合同类型分布
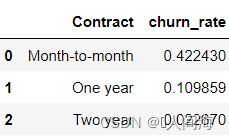
contract_df = train_df.groupby('Contract', as_index=False)['churn_int'].agg({'churn_rate':'mean'})
contract_df
x = ['Month-to-month', 'One year', 'Two year']
y = [contract_df['churn_rate'][0], contract_df['churn_rate'][1], contract_df['churn_rate'][2]]
plt.figure(figsize=(20,8),dpi=80)
plt.style.use('ggplot')
plt.title("用户流失率-合同类型分布", size=24)
plt.xticks(size=16) # x轴字体大小调整
plt.yticks(size=16) # y轴字体大小调整
plt.bar(x, y, width=0.3, color='#6699CC')
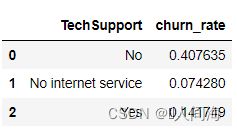
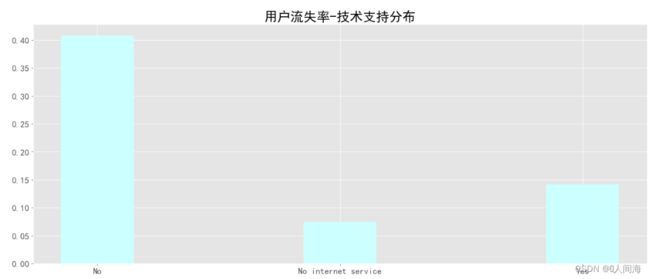
技术支持分布
contract_df = train_df.groupby('TechSupport', as_index=False)['churn_int'].agg({'churn_rate':'mean'})
contract_df
x = ['No', 'No internet service', 'Yes']
y = [contract_df['churn_rate'][0], contract_df['churn_rate'][1], contract_df['churn_rate'][2]]
plt.figure(figsize=(20,8),dpi=80)
plt.style.use('ggplot')
plt.title("用户流失率-技术支持分布", size=24)
plt.xticks(size=16) # x轴字体大小调整
plt.yticks(size=16) # y轴字体大小调整
plt.bar(x, y, width=0.3, color='#CCFFFF')
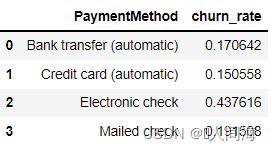
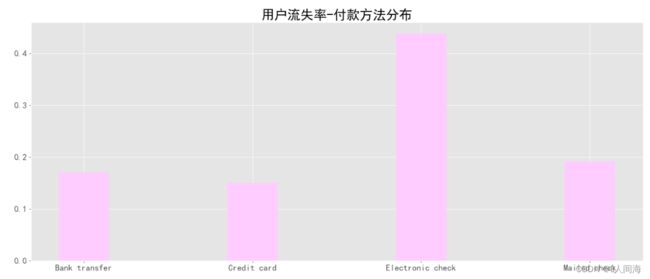
付款方法分布
contract_df = train_df.groupby('PaymentMethod', as_index=False)['churn_int'].agg({'churn_rate':'mean'})
contract_df
x = ['Bank transfer', 'Credit card', 'Electronic check', 'Mailed check']
y = [contract_df['churn_rate'][0], contract_df['churn_rate'][1], \
contract_df['churn_rate'][2], contract_df['churn_rate'][3]]
plt.figure(figsize=(20,8),dpi=80)
plt.style.use('ggplot')
plt.title("用户流失率-付款方法分布", size=24)
plt.xticks(size=16) # x轴字体大小调整
plt.yticks(size=16) # y轴字体大小调整
plt.bar(x, y, width=0.3, color='#FFCCFF')
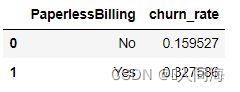
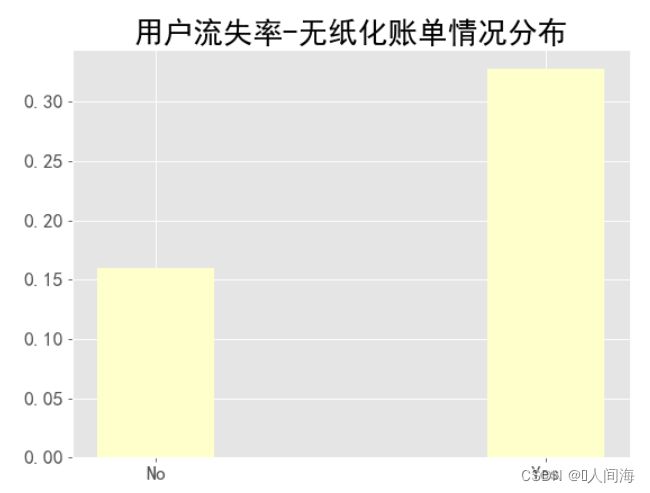
无纸化账单
contract_df = train_df.groupby('PaperlessBilling', as_index=False)['churn_int'].agg({'churn_rate':'mean'})
contract_df
x = ['No', 'Yes']
y = [contract_df['churn_rate'][0], contract_df['churn_rate'][1]]
plt.figure(figsize=(8,6),dpi=80)
plt.style.use('ggplot')
plt.title("用户流失率-无纸化账单情况分布", size=24)
plt.xticks(size=16) # x轴字体大小调整
plt.yticks(size=16) # y轴字体大小调整
plt.bar(x, y, width=0.3, color='#FFFFCC')
连续型特征处理–离散化
# 强制转换为数字,不可转换的变为NaN
# train_df['TotalCharges'] =train_df['TotalCharges'].astype(float)
train_df['TotalCharges'] = train_df['TotalCharges'].convert_objects(convert_numeric=True)
# 看看到底哪些数据不可转换
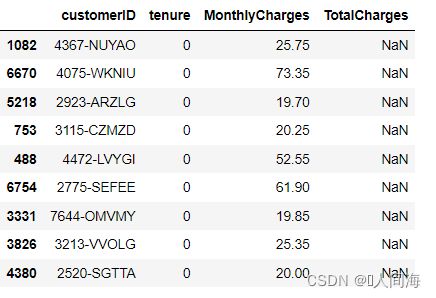
unconvert_df = train_df[pd.isnull(train_df['TotalCharges'])]
unconvert_df
#'TotalCharges'为空,从tenure来看说明是刚办理入户第一个月 总费用还未产生
# tenure是客户的入网时长,为0表示他们是新客户
unconvert_df[['customerID', 'tenure', 'MonthlyCharges', 'TotalCharges']]
# 根据业务经验,新用户就算是流失了也要把当月费用结清
# 所以处理方法为,将这些客户的入网时长改为1个月,费用使用月消费额填充
# 将总消费额填充为月消费额
train_df.loc[:,'TotalCharges'].replace(to_replace=np.nan, value=train_df.loc[:,'MonthlyCharges'], \
inplace=True)
# 将‘tenure’入网时长从0修改为1
train_df.loc[:,'tenure'].replace(to_replace=0, value=1, inplace=True)
train_df[train_df['tenure']==0][['tenure','MonthlyCharges','TotalCharges']]
![]()
连续特征进行分箱
#qcut按比例切分
pd.qcut(train_df['tenure'], 5).unique()
[(61.0, 72.0], (6.0, 20.0], (20.0, 40.0], (40.0, 61.0], (0.999, 6.0]]
Categories (5, interval[float64]): [(0.999, 6.0] < (6.0, 20.0] < (20.0, 40.0] < (40.0, 61.0] < (61.0, 72.0]]
def tenure_cate_func(x):
if x <= 6:
return 0
elif x <= 20:
return 1
elif x <= 40:
return 2
elif x <= 61:
return 3
else:
return 4
train_df['tenure_cate'] = train_df['tenure'].apply(tenure_cate_func)
train_df
pd.qcut(train_df['MonthlyCharges'], 5).unique()
[(94.4, 118.75], (25.0, 58.6], (58.6, 78.75], (78.75, 94.4], (18.249, 25.0]]
Categories (5, interval[float64]): [(18.249, 25.0] < (25.0, 58.6] < (58.6, 78.75] < (78.75, 94.4] < (94.4, 118.75]]
def month_cate_func(x):
if x <= 25:
return 0
elif x <= 58.6:
return 1
elif x <= 78.75:
return 2
elif x <= 94.4:
return 3
else:
return 4
pd.qcut(train_df['TotalCharges'], 5).unique()
[(4494.65, 8672.45], (269.65, 958.1], (2106.3, 4494.65], (958.1, 2106.3], (18.799, 269.65]]
Categories (5, interval[float64]): [(18.799, 269.65] < (269.65, 958.1] < (958.1, 2106.3] < (2106.3, 4494.65] < (4494.65, 8672.45]]
def total_cate_func(x):
if x <= 269.65:
return 0
elif x <= 958.1:
return 1
elif x <= 2106.3:
return 2
elif x <= 4494.65:
return 3
else:
return 4
train_df['month_cate'] = train_df['MonthlyCharges'].apply(month_cate_func)
train_df['total_cate'] = train_df['TotalCharges'].apply(total_cate_func)
train_df
对全数据集进行处理,并进行训练集测试集划分
# 对全数据集(训练集+测试集)进行数据处理
#训练集和测试集要做相同处理
df_2 = df.copy()
df_2['TotalCharges'] = df_2['TotalCharges'].convert_objects(convert_numeric=True)
df_2.loc[:,'TotalCharges'].replace(to_replace=np.nan, value=train_df.loc[:,'MonthlyCharges'], \
inplace=True)
df_2.loc[:,'tenure'].replace(to_replace=0, value=1, inplace=True)
df_2['tenure_cate'] = df_2['tenure'].apply(tenure_cate_func)
df_2['month_cate'] = df_2['MonthlyCharges'].apply(month_cate_func)
df_2['total_cate'] = df_2['TotalCharges'].apply(total_cate_func)
df_2
对类别型变量做数值处理
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
df_2['gender'] = le.fit_transform(df['gender'])
df_2['Partner'] = le.fit_transform(df['Partner'])
df_2['Dependents'] = le.fit_transform(df['Dependents'])
df_2['PhoneService'] = le.fit_transform(df['PhoneService'])
df_2['MultipleLines'] = le.fit_transform(df['MultipleLines'])
df_2['InternetService'] = le.fit_transform(df['InternetService'])
df_2['OnlineSecurity'] = le.fit_transform(df['OnlineSecurity'])
df_2['OnlineBackup'] = le.fit_transform(df['OnlineBackup'])
df_2['DeviceProtection'] = le.fit_transform(df['DeviceProtection'])
df_2['TechSupport'] = le.fit_transform(df['TechSupport'])
df_2['StreamingTV'] = le.fit_transform(df['StreamingTV'])
df_2['StreamingMovies'] = le.fit_transform(df['StreamingMovies'])
df_2['Contract'] = le.fit_transform(df['Contract'])
df_2['PaperlessBilling'] = le.fit_transform(df['PaperlessBilling'])
df_2['PaymentMethod'] = le.fit_transform(df['PaymentMethod'])
df_2['Churn'] = le.fit_transform(df['Churn'])
df_2
划分训练集和测试集
train_df = df_2.iloc[train_index]
test_df = df_2.iloc[test_index]
# y表示训练集数据的“结果”
y_train = train_df['Churn']
y_train
# X表示训练集数据的特征
# 去掉特征中的无用列,例如customerID
X_train = train_df.drop(['customerID', 'Churn', 'tenure', 'MonthlyCharges', 'TotalCharges'], axis=1)
X_train
y_test = test_df['Churn']
X_test = test_df.drop(['customerID', 'Churn', 'tenure', 'MonthlyCharges', 'TotalCharges'], axis=1)
使用Sklearn中的决策树模型包,完成算法模型预测
from sklearn import tree
# DecisionTreeClassifier是决策树分类器,这里我们初步学习,先完全使用默认值
# 有兴趣的同学可以查一下DecisionTreeClassifier中的参数,并尝试调节参数,看看模型会有何不同
clf = tree.DecisionTreeClassifier()
# 模型拟合训练集数据
clf = clf.fit(X_train, y_train)
pred = clf.predict(X_test)
# 结果展示
print("true:{}\npred:{}".format(y_test[:20].values, pred[:20]))
true:[0 0 0 1 1 1 0 0 0 0 0 0 1 0 0 0 1 0 0 0]
pred:[0 0 0 0 1 0 1 0 0 0 0 0 1 1 0 0 1 0 1 0]
# 准确率,精准率,召回率
from sklearn.metrics import accuracy_score, precision_score, recall_score
print("准确率:{}".format(accuracy_score(y_test.values, pred)))
print("精准率:{}".format(precision_score(y_test.values, pred)))
print("召回率:{}".format(recall_score(y_test.values, pred)))
准确率:0.7130681818181818
精准率:0.49012567324955114
召回率:0.4588235294117647
# DecisionTreeClassifier中内容为超参数
clf_2 = tree.DecisionTreeClassifier(criterion='entropy', \
max_depth=5, min_samples_split=4, class_weight="balanced")
clf_2 = clf_2.fit(X_train, y_train)
pred_2 = clf_2.predict(X_test)
print("准确率:{}".format(accuracy_score(y_test.values, pred_2)))
print("精准率:{}".format(precision_score(y_test.values, pred_2)))
print("召回率:{}".format(recall_score(y_test.values, pred_2)))
准确率:0.7419507575757576
精准率:0.5285388127853882
召回率:0.7781512605042017
经过调参,各个参数有提高