One-Stage Visual Grounding之一种快速准确的单阶段视觉定位
One-Stage Visual Grounding之一种快速、准确的单阶段视觉定位方法
- 前言
- 两阶段框架存在的缺陷
- 单阶段视觉定位的优点
- 单阶段视觉定位的方法
-
- 视觉和文本特征编码
- 空间特征编码
- 融合
- 定位
- 一些细节
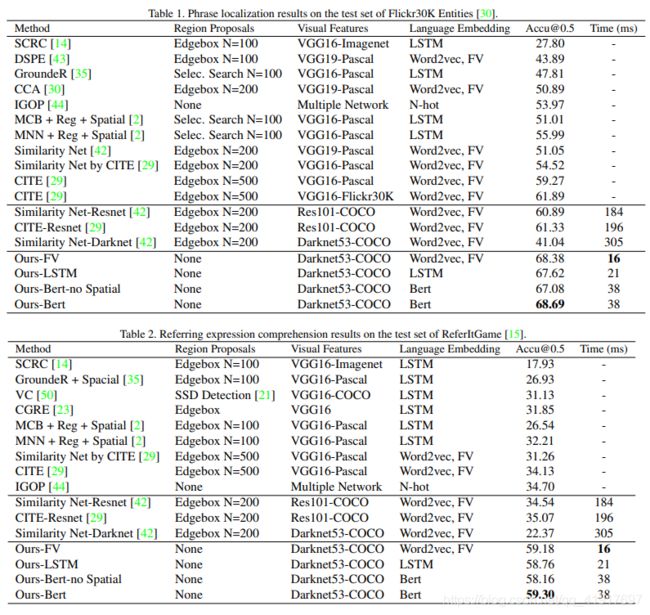
- 两阶段与单阶段方法性能对比
-
- 两阶段方法的错误对比分析
- 单阶段方法
- 结论
未经本人同意,禁止任何形式的转载!
《A Fast and Accurate One-Stage Approach to Visual Grounding》
论文地址发表于2019年ICCV。
前言
我们提出了一种简单、快速、准确的单阶段视觉定位方法,其目的是将关于图像的自然语言查询(短语或句子)对应到图像的正确区域。通过在这一层次上定义语言指示的视觉定位,我们故意抽象出短语定位、引用表达理解、自然语言对象检索、视觉问题分割等之间的微妙区别,其中每一个都可看作是一般性语言指示的视觉定位问题的一个变体。我们测试了单阶段的方法,无论是短语定位或引用表达理解。结果表明,该方法比最先进的两阶段方法快10倍,同时比它们更准确。
它的潜在应用包括但不限于机器人、人机交互和早期教育。此外,良好的视觉定位模型可以使视觉问答、图像字幕和图像检索等多种研究问题受益。
两阶段框架存在的缺陷
1)如果第一阶段的候选区域没有一个选中所需区域,那么无论第二阶段表现得多好,整个框架都会失败。我们发现,每幅图像的200个候选框只有68%能框中真相区域。如果200个候选框中的任何一个可以达到0.5或更高的与目标区域的交并比,则被认为是成功的。
2)大部分计算花费在候选区域上,如生成候选区,提取特征,融合查询嵌入,评分相似度等等。然而,在大多数测试用例中,只有一两个候选区建议是正确的。我们认为这个方案计算量很大,应该加以改进。
单阶段视觉定位的优点
这种单阶段方法有很多优点。首先,它可以快速的推断。仅从经过一次的输入图像中提取特征,然后直接预测输出区域的坐标。在没有经过任何代码优化的情况下,我们的实现比最先进的两阶段方法快10倍。此外,它也是准确的。与性能受候选区域限制的两阶段框架不同,它支持端到端优化。我们在短语定位和引用表达理解方面都取得了很好的结果。最后,相比于两阶段的方法,它可以更好地推广到不同的数据集,因为它不依赖于任何额外的工具或预先训练的模型。因此,我们主张单阶段的框架。
单阶段视觉定位的方法
简而言之,我们对视觉定位的单阶段方法是将文本查询的嵌入融合到YOLOv3中,并更改了一些配置,因为我们只需要返回一个区域进行查询,所以利用Softmax函数替换输出层的Sigmoid函数,最后用YOLO的损失训练网络。尽管简单,但这种单阶段方法却在准确性和速度方面都产生了优越的结果。
我们提出的vanilla单阶段模型如下,并在补充材料中对其进行了修改,以解释在两阶段方法中探索的一些方法。下图是该网络架构,主要由三个特征编码模块和三个融合模块组成。

视觉和文本特征编码
我们的模型是端到端的,以图像和文本查询作为输入,然后返回对文本查询所对应的图像区域。对于文本的处理,我们使用未压缩版本的Bert[4]将其嵌入到768维的实值向量中,然后是两个有512个神经元的全连接层。此外,我们还测试了其他的嵌入方法,以便与现有的工作进行比较。特别是最近的工作很多都使用Fisher向量的Word2vec方法,采用双向LSTM。
我们使用具有特征金字塔结构[18]的Darknet-53[33]网络提取输入图像的视觉特征,输入图像的大小调整为256x256。三个空间分辨率:88D1、1616D2和3232 D3。换句话说,特征映射分别是原始图像大小的1/32、1/16和1/8。在三个分辨率下分别有D1=1024、D2=512和D3=256个特征通道。我们添加了一个具有批处理归一化和RELU的1*1卷积层,将它们映射到同一维D=512。
空间特征编码
我们发现语言指示通常使用空间信息来引用对象,例如“左边的人”和“右下角的草”。然而,Darknet-53的特征主要是捕捉视觉的外观,缺乏位置信息。因此,我们显式地为三个空间分辨率的每个位置编码一些空间特征。具体来说,如图2所示,我们每个分辨率的空间生成一个大小为W’×H’×Dspatial的坐标图,其中W’和H’是视觉特征映射的空间大小,即 8x8、16x16或32x32,Dspatial=8表示我们编码八个空间特征。 如果我们将特征映射放置在坐标系中,使其左上角和右下角分别位于(0,0)和(1,1),则任何位置(i,j),i∈{0,1,···,W’-1}和j∈{0,1,···,H’-1},计算如下:

它代表网格处于(i,j)时的网格左上角、中心和右下角的坐标,以及W’和H’的倒数。
融合
我们使用相同的操作将视觉、文本和空间特征融合在三个空间分辨率上。特别是,我们首先将查询嵌入广播到每个空间位置(i,j),然后将其与视觉和空间特征连接起来,产生512+512+8=1032维的特征向量。视觉、文本和空间特征在连接之前也分别的归一化。我们添加了一个1x1卷积层,以便更好地在每个位置独立地融合它们。我们还测试了3x3卷积核,希望融合的时候能够融入邻域的信息,但与1x1卷积核的结果大致相同。在此融合步骤之后,三个分辨率空间的每个位置都有一个512维的特征向量,即分别大小为8x8x512、16x16x512和32x32x512的三个特征向量。
定位
定位模块以融合后的特征作为输入,并生成一个框预测,将语言查询定位到图像区域。我们通过YOLOv3的输出层来设计这个模块,我们重新校准它的锚定框,并将其sigmoid函数更改为softmax函数。
三个空间分辨率中有8x8+16x16+32x32=1344个位置,每个位置都与512维特征向量相关联。YOLOv3每个位置中心都围绕着三种锚框。为了更好地适应我们的数据集,我们通过Kmeans在训练集中以(1-loU)作为距离聚类得到,定制了锚框的宽度和高度。
共有(每个位置3个锚框x1344个位置)=4032个锚框。YOLOv3预测的是从每个锚框中,通过回归得到四个量来移动锚盒的中心,宽度和高度,以及第五个量通过一个sigmoid函数输出来表示这个移位的盒子的置信度。我们保持回归分支的原样。由于只需要一个区域作为查询定位的输出,根据当前定位问题,我们将所有4032个锚框的sigmoid函数替换为softmax函数。因此,我们用这个softmax和一个one-hot向量之间的交叉熵替换置信分数上的损失函数——与真实目标区域的交并比最高的锚框被标记为1,其他所有都被标记为0。
一些细节
我们使用在COCO数据集上为目标检测的预训练模型Darknet53作为视觉编码器。为了嵌入语言查询,我们测试了一个使用bi-LSTM框架的Bert,以及Fisher向量编码。通过K均值聚类生成锚框。 ReferitGame的锚框是(18x22)、(48x28)、(29x52)、(91x48)、(50x91)、(203x57)、(96x127)、(234x100)、(202x175)以及Flickr30K Entities上的锚框是(17x16)、 (33x35)、 (84x43)、 (50x74)、 (76x126) 、 (125x81)、(128x161)、(227x104)、(216x180)。
训练细节。当我们调整输入图像的大小时,保持原始图像的比例。我们将其长边调整为 256,然后用图像像素的平均值在短边方向进行填充,使最终图像大小为 256x256。我们一开始使用较弱的数据增强[33],即在颜色空间(饱和度和强度)、水平翻转和随机仿射变换。我们用RMSProp[40]优化来训练模型,从10E-4的学习率开始并遵循幂为1的多项式调整策略。由于Darknet已经被预先训练,我们在Darknet模型部分的主要学习率乘以0.1。在我们所有的实验中,批次大小为32。当我们在一个有8 个 P100的GPU 工作站上使用更大的批处理大小时,我们观察到大约有1%的提升,但是我们选择小批量大小(32)的结果,这样其他人就可以很容易地在一个有双 GPU的机器上复现我们的结构。
详情请参阅论文。
两阶段与单阶段方法性能对比

两阶段网络的错误(上一行)可以通过我们的单阶段方法来纠正(下一行)。蓝色方框是预测区域,黄色方框是真实目标区域。
可见单阶段方法可以克服很多两阶段的难题。
两阶段方法的错误对比分析
两阶段方法的常见故障有三种:涉及多个对象的查询(a,b),对一个物体相对位置的物体的查询(c, d)和具有挑战性的区域(e, f)。
具有挑战性的区域:第一,第一阶段的候选框选取可能不能提供良好的覆盖范围,特别是小对象。第二,小区域的视觉特征判别性不够,无法在第二阶段学习到较好的排序。第三,图像描绘复杂的场景或许多重复的物体。
单阶段方法

在我们的单阶段方法中具有挑战性的样本的成功案例(上一行)和常见的失败案例(下一行)。蓝色/黄色框是预测框/真实目标区域。左边的四列来自ReferitGame数据集,其他的来自Flickr30K Entities数据集 。
单阶段失败案例分析:
上图显示了我们方法的成功和失败案例。第一行展示典型的成功案例。上图(a)中的“蓝色油漆自行车”在同一类的多个对象中查询图像。上图(b)提供了一个关于微小对象的正确预测的样例,©和(d) 展示了我们的方法能够在查询中加入位置信息。在(e)中的查询包含一个分散注意力的名词“羊”。我们在(f)中的模型成功地预测了包含两个对象的区域。上图(g)-(l)是我们模型的一些失败案例。我们发现我们的模型对类别属性不敏感,例如(g)和(k)中的“蓝色”。它在(h)和(i)上失败只是因为这些都是非常困难的测试(例如,为了做出正确的预测,必须识别图像中的“colonial”一词)。最后,(j)和(l)给出了两个不明确的查询,我们的模型恰好预测了与用户注释的框不同的框。
结论
我们提出了一种简单而有效的单阶段视觉定位方法。我们将语言查询和空间特征合并到YOLOv3对象检测器中,并构建了可端到端训练的视觉定位模型。它比最先进的两级方法快10倍左右,达到了很好的定位精度。此外,我们的分析表明,现有的候选框区域选取方法通常不够好,限制了两阶段方法的性能,并认为需要向单阶段框架转变。在未来的工作中,我们计划研究所提出的单阶段框架在视觉定位问题中的可扩展性。