logistic回归 如何_Logistic回归分析之二元Logistic回归
在研究X对于Y的影响时,如果Y为定量数据,那么使用多元线性回归分析(SPSSAU通用方法里面的线性回归);如果Y为定类数据,那么使用Logistic回归分析。
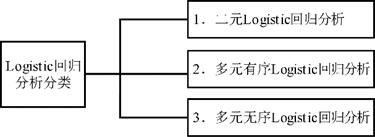
结合实际情况,可以将Logistic回归分析分为3类,分别是二元Logistic回归分析、多元有序Logistic回归分析和多元无序Logistic回归分析,如下图。
Logistic回归分析用于研究X对Y的影响,并且对X的数据类型没有要求,X可以为定类数据,也可以为定量数据,但要求Y必须为定类数据,并且根据Y的选项数,使用相应的数据分析方法。
本次内容将针对二元logistic(logit)回归进行说明,后续两篇文章将分别讲解有序logistic(logit)和多分类logistic(logit)回归。
1、二元logistic分析思路说明
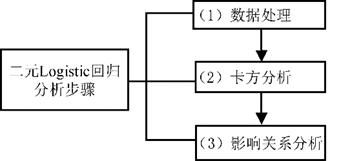
在进行二元Logistic回归分析时,通常会涉及3个步骤,分别是数据处理、卡方分析和影响关系研究,如下图。
1.1 第一步为数据处理
例如,在研究相关因素对样本将来是否愿意购买理财产品的影响情况时,性别,专业等均为影响因素,而且明显的,性别和专业属于定类数据,因此需要进行虚拟哑变量设置,可使用【数据处理->生成变量】完成。
除此之外,二元logistic回归要求因变量只能为2项,而且数字一定是0和1,数字1表示YES,愿意,购买,患病等,数字0表示no,不愿意,不购买,不患病等。如果不是这样,那么就需要针对因变量Y进行数据编码,使用【数据处理->数据编码】即可完成。
1.2 第二步为卡方分析或方差分析
此步不是必需的步骤,通过此步可以试探性了解每个影响因素X与Y之间的影响关系情况,研究影响关系前,首先需要自变量X与Y之间有着差异关系,才可能进一步有着影响关系,也或者说差异关系是一种基础性关系,影响关系是更进一步的深层次关系。所以在进行二元logistic回归分析前,可先对X做差异分析,筛选出与Y有着差异性的X。
如果X是定类数据,那么就使用卡方分析去分析差异;如果说X是定量数据,那么可使用方差分析去研究X和Y的差异性。
分析完成X与Y的差异关系之后,筛选出有差异的X,然后再放入模型中,进行二元logistic回归;这样做的目的有两个,一是简化模型,越简单的模型越容易拟合且效果越好;二是做到心里有数,提前了解到数据之间的大致关系情况。
1.3 第三步为影响关系分析,即二元Logistic回归分析
在上一步确认了可能的影响因素之后,此步骤直接对题进行二元Logistic回归分析。二元Logistic回归分析时,首先需要看某个题是否呈现出显著性(如果P值小于0.05,则说明呈现出0.05水平的显著性;如果P值小于0.01,则说明呈现出0.01水平的显著性),如果呈现出显著性,那么说明该题对Y有影响关系。具体是正向影响还是负向影响需要结合对应的回归系数值进行说明,如果回归系数值大于0,则说明是正向影响;反之则说明是负向影响。
除此之外,二元Logistic回归分析会涉及一个术语——对数比(SPSSAU中称其为OR值)。对数比是一个倍数概念指标,该值等于回归系数的指数次方,也称exp(b)值。例如,研究相关因素对样本‘是否购买理财产品’的影响,性别因素呈现出显著性,并且性别以女性为对照项,其对数比(OR值)为1.34,这说明男性样本购买理财产品的可能性是女性样本的1.34倍。
二元Logistic回归分析模型的拟合情况或模型效果的判断会涉及3个指标,分别是Hosmer和Lemeshow检验、R2值和模型预测准确率表格。Hosmer和Lemeshow检验用于检验事实数据情况与模型拟合结果是否保持一致,如果在进行Hosmer和Lemeshow检验时P值大于0.05,那么说明事实数据情况与模型拟合结果保持一致,即说明模型拟合情况良好。
R2用于表示模型拟合程度,此值与多元线性回归分析的R2值意义基本一致,此值的取值范围为0~1,值越大意味着相关因素对Y的解释力度越高。SPSSAU提供3个R方值指标,分别是McFadden R 方、Cox & Snell R 方和Nagelkerke R 方。
除此之外,SPSSAU还会输出模型预测准确率表格,用于分析模型的预测水平情况。比如有多大比例将本身为愿意购买理财产品的样本误判断为不愿意购买理财产品的样本。
2、如何使用SPSSAU进行二元logistic操作
在进行二元logistic回归分析时,共分为三个步骤,第1步是数据处理。第二步是进行卡方或者方差分析试控X对于Y的差异,找出有差异关系的X,用于进一步的二元logistic回归分析。
2.1 数据处理
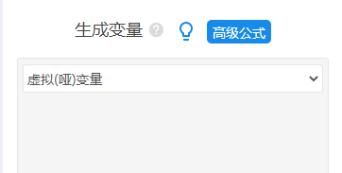
如果X是定类数据,比如性别或专业。那么就需要首先对它们做虚拟哑变量处理,使用SPSSAU【数据处理】--【生成变量】。操作如下图:
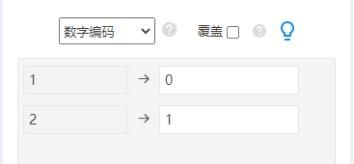
因变量Y只能包括数字0和1,如果因变量的原始数据不是这样,那么就需要数据编码,设置成0和1,使用SPSSAU数据处理->数据编码功能,操作如下图:
2.2 卡方分析或方差分析
本例子中想研究性别,专业,年龄,月生活费共4项对于‘是否愿意理财’的影响。性别,专业这两项为定类数据,所以可使用卡方分析它们分别与‘是否愿意理财’的差异关系。而年龄和月生活费可看成定量数据,可使用方差分析(或非参数检验)分析它们分别与‘是否愿意理财’的差异关系情况。
由于例子里面仅4个X,本身就较少,因此模型本身并不复杂,因此直接忽略此步骤即可,直接进行二元logistic回归分析。
2.3 二元logistic回归分析
SPSSAU进行二元logistic回归分两步,分别是在进阶方法里面找到二元logit,第二是拖拽分析项到右我们就是右侧框后开始分析,如下所示:
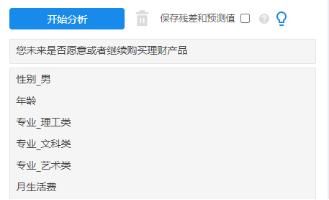
性别和专业均为定类数据,所以进行了虚拟哑变量设置。
而且性别分为男和女,以女作为参照项,因此框中仅放入‘男’即可;
专业分为理工类,文科类,艺术类和,体育类;以体育类作为参照项,因此框中会少放体育类,放入另外3项即理工类,文科类和艺术类即可。
虚拟哑变量在进行影响关系研究时,一定需要有1个参照项,至于具体是哪一项,由研究者自行决定即可,无固定要求,一般是第1个或者最后1个,或者研究者希望设置作为参考项的。
完成后,SPSSAU会得到一系列的表格和智能分析,包括模型基本汇总表格,模型似然比检验表格,模型参数拟合表格,模型预测准确率表格,Hosmer-Lemeshow拟合度检验等。如下:
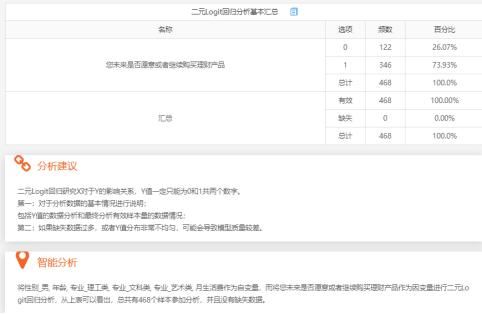
二元logit回归分析基本汇总
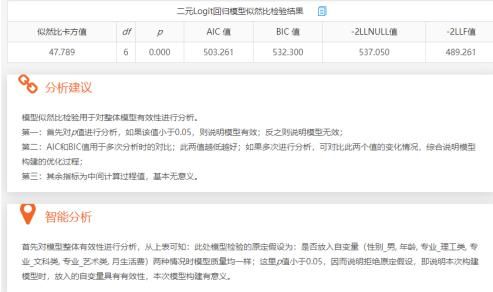
二元logit回归模型似然比检验结果
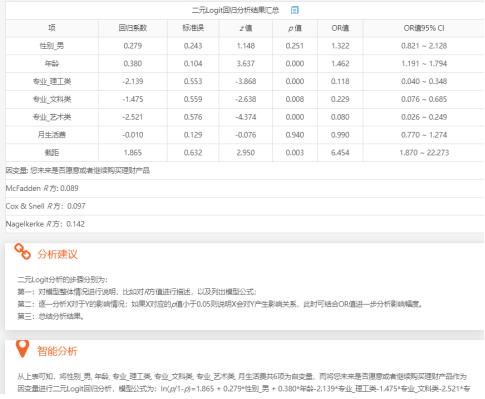
二元logit回归结果分析
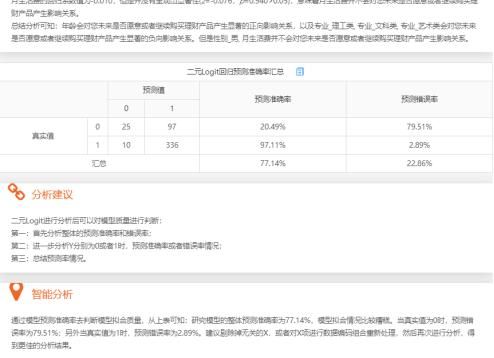
二元logit回归预测准确率表格
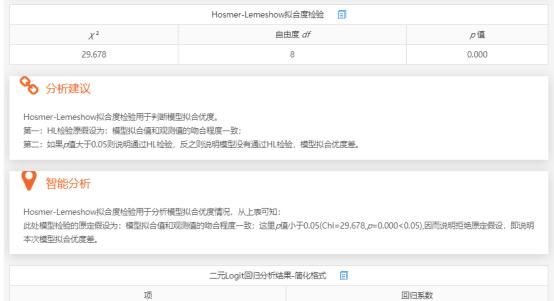
Hosmer-Lemeshow拟合度检验
3、二元logistic相关问题
在使用SPSSSAU进行二元logistic回归时,可能会出现一些问题,比如提示奇异矩阵,质量异常,Y值只能为0或1等,接下来一一说明。
第1点:出现奇异矩阵或质量异常
如果做二元logistic提示奇异矩阵,通常有两个原因,一是虚拟哑变量设置后,本应该少放1项作为参考项但是并没有,而是把所有的哑变量项都放入框中,这会导致绝对的共线性问题即会出现奇异矩阵矩阵。二是X之间有着太强的共线性(可使用通用方法的线性回归查看下VIF值),此时也可能导致模型无法拟合等。先找出原因,然后把有问题的项移出模型中即可。
同时,如果自变量X的分布极其不均匀,SPSSAU建议可先对类别进行组合,可使用数据处理里面的数据编码完成。
第2点:Y值只能为0或1
二元logistic回归研究X对Y的影响,Y为两个类别,比如是否愿意,是否喜欢,是否患病等,数字一定有且仅为2个,分别是0和1。如果不是这样就会出现此类提示,可使用SPSSAU频数分析进行检查,并且使用数据处理->数据编码功能进行处理成0和1。
第3点:OR值的意义
OR值=exp(b)值,即回归系数的指数次方,该值在医学研究里面使用较多,实际意义是X增加1个单位时,Y的增加幅度。如果仅仅是研究影响关系,该值意义较小。
第4点: wald值或z值
z 值=回归系数/标准误,该值为中间过程值无意义,只需要看p 值即可。有的软件会提供wald值(但不提供z 值,该值也无实际意义),wald值= z 值的平方。
第5点: McFadden R 方、Cox & Snell R 方和Nagelkerke R 方相关问题?
Logit回归时会提供此3个R 方值(分别是McFadden R 方、Cox & Snell R 方和Nagelkerke R 方),此3个R 方均为伪R 方值,其值越大越好,但其无法非常有效的表达模型的拟合程度,意义相对交小,而且多数情况此3个指标值均会特别小,研究人员不用过分关注于此3个指标值。一般报告其中任意一个R方值指标即可。