浅尝YOLOv3论文
关于YOLO
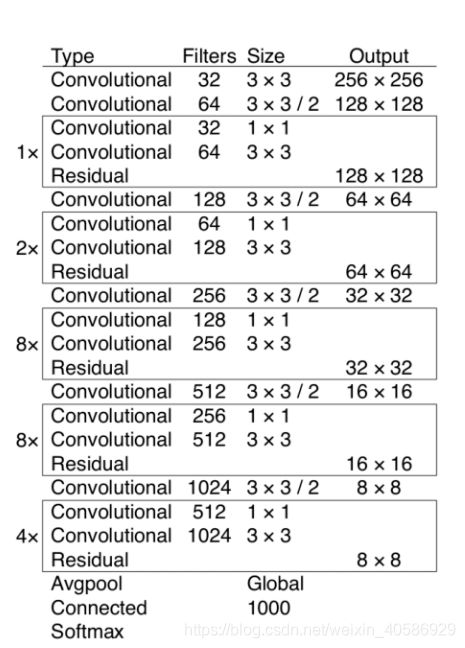
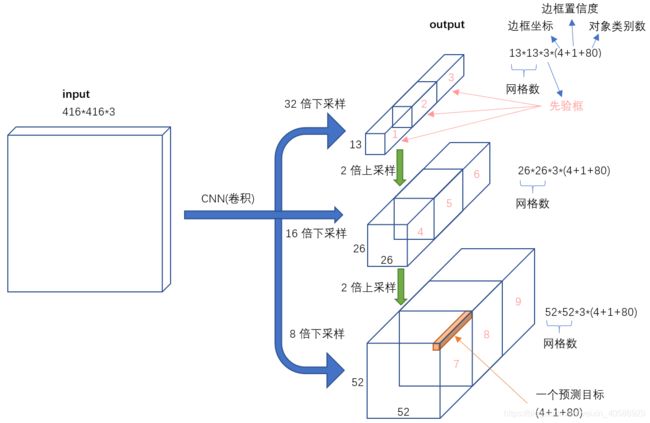
YOLO的意思是 you only look once,比起想RCNN,FAST RCNN这些two stage的方法,YOLO仅仅需要扫描一遍图像,而不需要另外再寻找ROI,感兴趣的区域。YOLOv3是2018年发明的算法,并且所发表的论文也较为简短。以下是YOLOv3的网络结构图:

上图三个蓝色方框内表示Yolov3的三个基本组件:
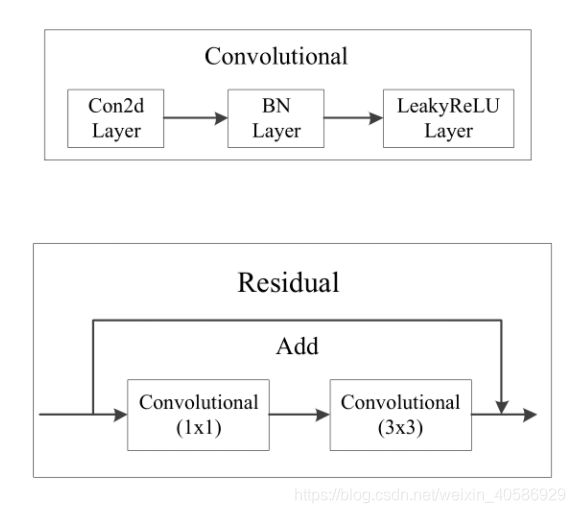
(1)CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。
(2)Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
(3)ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。
Darknet-53
在Darknetnet-53中,每个卷积层主要由多个1x1和3x3的卷积层组成,然后后面都会接上一个BN层以及LeakyReLU层,因为网络中有53个convolutional layers(2 + 12 + 1 + 22 + 1 + 82 + 1 + 82 + 1 + 4*2 + 1 = 53 ),所以叫做Darknet-53。注意的是,输入进YOLO的图像大小需要为32的整数倍。
YOLOv3中的损失函数
在YOLOv3中,损失函数主要分为三个部分:目标定位偏移量损失,目标置信度损失以及目标分类损失,
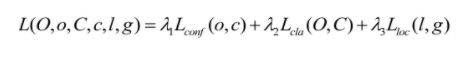
目标置信度损失
目标置信度即判断目标矩形框中是否存在目标,该损失是由二值交叉熵(Binary Cross Entropy)来预测目标框内是否存在目标。在网络中,使用逻辑回归预测每个边界框的存在目标的概率,如果当前预测的边界框比之前的更好地与ground truth对象重合,那它的分数就是1。如果当前的预测不是最好的,但它和ground truth对象重合到了一定阈值(这里使用的是0.5)以上,那么网络会忽视这个预测。并且,网络只为每个ground truth对象分配一个边界框。如果先前的边界框并未分配给相应对象,那它只是检测错了对象,而不会对坐标或分类预测造成影响。
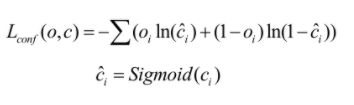
目标类别损失
目标类别损失依旧是采用二值交叉熵损失,其中Oij在[0,1]范围,表示预测目标边界框i中是否真实存在第j类目标,0表示不存在,1表示存在。Cij表示网络预测目标边界框i内存在第j类目标的Sigmoid概率(将预测值Cij通过sigmoid函数得到)。因为作者在使用softmax后发现对网络性能的提升角度来说,没有起到太大的作用,所以还是采用了单独的逻辑分类器。使用logistic的输出进行预测后,能够支持多标签对象(比如一个人有Woman 和 Person两个标签)。
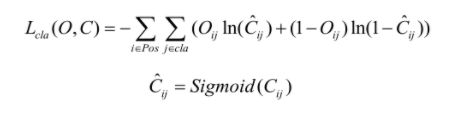
目标定位损失
目标定位损失是采用真实偏差值与预测偏差值差的平方和,其中 l ^ \small \hat{l} l^表示预测矩形框坐标偏移量(注意网络预测的是偏移量,不是直接预测坐标)。 g ^ \small \hat{g} g^表示与之匹配的GTbox与默认框之间的坐标偏移量, ( b x , b y , b w , b h ) \small (b^{x},b^{y},b^{w},b^{h}) (bx,by,bw,bh)为预测的目标矩形框参数 ( c x , c y , p w , p h ) \small (c^{x},c^{y},p^{w},p^{h}) (cx,cy,pw,ph)为默认矩形框参数, ( g x , g y , g w , g h ) \small (g^{x},g^{y},g^{w},g^{h}) (gx,gy,gw,gh)为与之匹配的真实目标矩形框参数,这些参数都是映射在预测特征图上的。
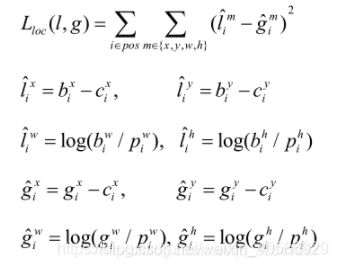
目标框的预测
在YOLOv3中,用于预测的三个特征层大小分别为52,26,13。随着输出的特征图的数量和尺度的变化,先验框的尺寸也需要相应的调整。YOLO2已经开始采用K-means聚类得到先验框的尺寸,YOLO3延续了这种方法,为每种下采样尺度设定3种先验框,总共聚类出9种尺寸的先验框。在COCO数据集这9个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。
在分配上,在最小的1313特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。中等的2626特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。较大的52*52特征图上(较小的感受野)应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。

在三个特征图中分别通过(4+1+c) x k个大小为1 x 1的卷积核进行卷积预测,k为预设边界框(bounding box prior)的个数(k默认取3),c为预测目标的类别数,其中4k个参数负责预测目标边界框的偏移量,k个参数负责预测目标边界框内包含目标的概率,ck个参数负责预测这k个预设边界框对应c个目标类别的概率。
图中虚线矩形框为预设边界框,实线矩形框为通过网络预测的偏移量计算得到的预测边界框。其中 ( c x , c y ) \small (c_{x},c_{y}) (cx,cy)为预设边界框在特征图上的中心坐标, ( p w , p y ) \small (p_{w},p_{y}) (pw,py)为预设边界框在特征图上的宽和高, ( t x , t y , t w , t h ) \small (t_{x}, t_{y},t_{w},t_{h}) (tx,ty,tw,th)分别为网络预测的边界框中心偏移量 ( t x , t y ) \small (t_{x},t_{y}) (tx,ty)以及宽高缩放比 ( t w , t y ) \small (t_{w},t_{y}) (tw,ty), ( b x , b y , b w , b h ) \small (b_{x},b_{y},b_{w},b_{h}) (bx,by,bw,bh)为最终预测的目标边界框.
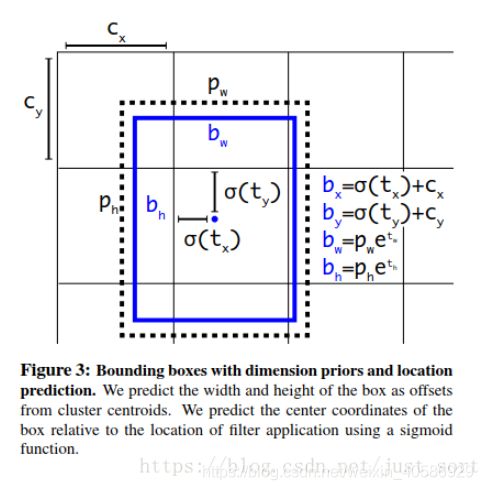
其中 σ ( x ) \small \sigma (x) σ(x)函数是sigmoid函数其目的是将预测偏移量缩放到0到1之间,这样能够将预设边界框的中心坐标固定在一个cell当中,缩放到这个范围内后能够加快网络收敛。
YOLOv3所做的其他尝试
作者在最后还提到了他们做了哪些尝试,但是发现并没有起到太大的作用:
- Anchor box坐标的偏移预测。作者尝试了常规的Anchor box预测方法,比如利用线性激活将坐标x、y的偏移程度预测为边界框宽度或高度的倍数。但我们发现这种做法降低了模型的稳定性,且效果不佳
- 用线性方法预测x,y,而不是使用逻辑方法。我们尝试使用线性激活来直接预测x,y的offset,而不是逻辑激活。这降低了mAP成绩。
- focal loss。作者还尝试使用focal loss,但它使mAP降低了2点。 对于focal loss函数试图解决的问题,但是YOLOv3从理论上来说已经很强大了,因为它具有单独的对象预测和条件类别预测。因此,对于大多数例子来说,在类别预测应该没有其他损失的存在。
- 双IOU阈值和真值分配。在训练期间,Faster RCNN用了两个IOU阈值,如果预测的边框与.7的ground truth重合,那它是个正面的结果;如果在[.3—.7]之间,则忽略;如果和.3的ground truth重合,那它就是个负面的结果。作者尝试了这种思路,但效果并不好。