基于BERT模型的知识库问答(KBQA)系统
一、介绍
本项目的主要目标是构建一个公共的知识库问答系统,从用户所提出的问题,对知识库进行检索,返回一个确定的答案,或者没有答案。项目代码、数据在这个地址中:链接: https://pan.baidu.com/s/1HvdVIvYIrvDaRBDl5p1oUw 提取码: a917
本项目所使用的数据集是已经被预处理好的三元组 ,有两个文件 nlpcc-iccpol-2016.kbqa.training-data,nlpcc-iccpol-2016.kbqa.testing-data,文件内容样式:
二、数据处理
1. 切分数据
training-data样本数14609,testing-data样本数9870 。运行 1_split_data.py 重新切分一下数据,在路径".\bert-kbqa\input\data\NLPCC2016KBQA"得到 train.txt dev.txt test.txt三个文件。三个文件的样本数量分别是 14609,4935,4925。
2. 构造命名实体识别(NER)数据集
运行 2-construct_dataset_ner.py 得到命名实体识别数据集,在路径 "bert-kbqa\input\data\ner_data"得到。
txt文件是ner数据集,csv是后面数据库所需要的。
由于只需要识别实体,所以只标记处实体和非实体,供三个类别["O","B-LOC","I-LOC"],ner的数据:

3. 构建属性相似度的数据
一个问题(样本)自己的属性为正例,再随机从剩余的,非自身属性中选取5个作为负例。运行文件
3-construct_dataset_attribute.py得到。如图: 行末为1的是正例,行末为0是负例。
4. 构建数据库(Mysql)的数据
mysql的安装配置,这里就不展开了。假设各位mysql都已经存在。
运行文件 5-triple_clean.py 得到所需要数据,运行 6-load_dbdata.py 创建数据库,加载数据。
三、模型介绍
bert是基于transformer的decoder部分做的预训练模型,这里以项目为主 ,原理部分不展开
bert 论文:https://arxiv.org/abs/1810.04805
bert翻译的中文博客 :https://blog.csdn.net/qq_41664845/article/details/84787969#comments
bert的源代码(pytorch) :https://github.com/huggingface/transformers
CRF知乎专栏:https://zhuanlan.zhihu.com/p/44042528
模型基于bert,主要有两个模型
模型1:BertCrf 用 BertForTokenClassification + crf 模型 用于识别出问题中的实体,是查询数据库的基础。
运行文件 NER_main.py 训练
模型2: BertForSequenceClassification , 用于句子分类。把问题 和 属性拼接到一起,判断问题要问的是不是这个属性。
运行文件 SIM_main.py 训练
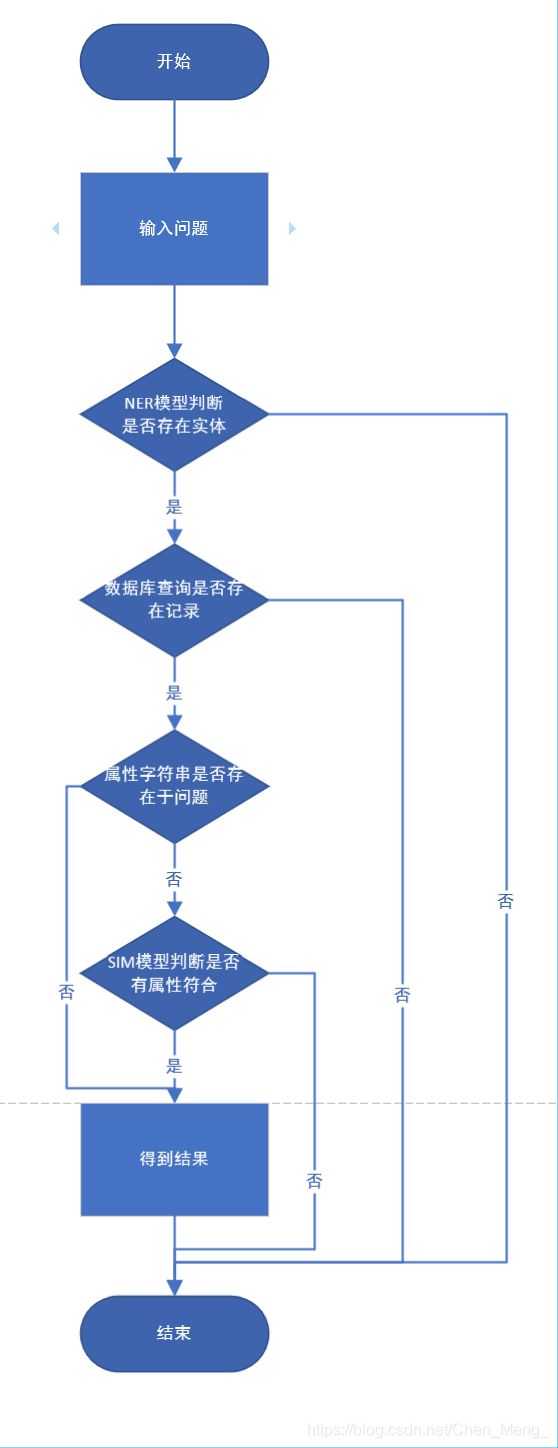
需要说明一下,当在数据库查询的属性在问题中已经出现,则此时认为该问题所对应的属性已经找到,不需要经过模型2来判断,以达到节约时间的目的。
例如:
问题:《机械设计基础》这本书的作者是谁?
在数据库查找的“作者”这个属性在问题中出现了,则直接返回对应的答案。
项目工作的流程:
四、最终结果
模型1 BertCrf 最佳模型,在测试集的表现:

模型二 BertForSequenceClassification 最佳模型,在训练集的表现

在测试集,找了一些问题,属性没有完全在问题中出现,问答对话的效果:
