数据分析业务场景 | CTR预估
一.概况
定义
是推荐中最核心的算法之一
对每次广告的点击情况做出预测,预测用户是点击还是不点击
就是预测点击与否的而分类算法,成功的关键之一就是样本的准确性
对于正样本,一般可发挥的空间不是很大,最多就是卡一个停留时长,将属于误点击的正样本剔除
对于负样本,CTR预估是非常讲究真实负样本的,即一定是给用户真实曝光过而被用户忽略的item,才能作为负样本
作用
CTR是为广告排序用的,而排序是竞价广告的核心,连接了点击和曝光
广告平台关心自己的流量价值,即自己的流量曝光卖的贵还是便宜,一般用ECPM(earning cost per mille)这个指标来衡量,即每1000次曝光带来收入
广告主一般按点击进行扣费,即广告主通常关心结果,出价原则就看一个点击需要花多少钱
广告平台需要把点击出价转化成ECPM进行扣费和排序
CTR架起了从点击到曝光的一座桥梁,为排序提供基础
推荐系统也需要CTR预估来排序
意义
有针对性地对个体单独预估,通过某个模型用交叉特征看每一个个体的点击率,从而下一个拥有该特征的人群来访问的时候,就能相对更加准确地预估了
过程
决定广告点击率的因素有三类
广告主侧:比如广告创意,广告文案,广告的表现形式,广告主行业
用户侧:比如人群属性(年龄,性别,地域,兴趣,活跃度等)
广告平台侧:比如不同的广告位,投放时间,竞价策略,流量分配机制,频次控制策略等
这些决定因素在CTR预估中被称为特征,CTR预估的第一步就是特征工程,即把这些特征找到并数据化,列出不同的特征可能对CTR产生的影响
确定了特征之后就需要对这些特征进行处理,即把特征数据化,比如把所有的特征变成0和1的二值化,把连续的特征离散化,把特征的值平滑化,把多个特征向量化
特征完成后就开始建立模型:尝试新模型,训练不同的模型参数
特征
1.统计相关特征
①用户统计特征
用户在各属性ID上,历史点击行为的target mean(平滑)
用户在属性ID上的信息熵,共现次数,比例偏好等统计特征
②商品统计特征
各属性ID,历史点击行为的target mean(平滑)
各属性ID,曝光次数统计
2.序列相关特征:Embedding特征
由word2vec生成的用户,广告等ID的embedding(取平均)
穿越特征(强)
基本构造方法就是计算距离下一次行为的时间差
这么做的原因很好理解,假如一个人点击了某个广告,那么必然会停留一段时间,那么距离下一次的行为就会久一点,差值也较大。相反,连续两次行为的时间间隔应该很小,距离上次行为的时间差也是有效的,根据APP推荐规则,在点击广告后下次推荐的也是相关广告,从而再次点击的可能性较大,可以单特征或组合,行为可以间隔1次,也可以2次,3次等
data.groupby(col)['data'].shift(-gap)
data['ts_{}_{}_diff_next'.format('_'.join(col),gap)] - data['data']
data.groupby(col)['data'].shift(+gap)
data['date'] - data['ts_{}_{}_diff_last'.format('_'.join(col),gap)]如何使用源域用户行为数据?
根据日期(day,hour),统计用户行为次数(count),用户对应类别的属性数(nunique)
根据日期(day,hour),构建用户交互类别的属性,作为多值特征处理
针对多值特征,可以结合CountVectorizer和TfidfVectorizer进行处理,如果维度较多,可以再结合pca,svd,nmf等方法进行降维处理
模型
逻辑回归:使用最广泛的模型,一般结合onehot encoding之后的特征使用
GBDT:一般配合连续值特征使用
FM:输入的每个特征除了学到一个对应的权重外,还能得到一组权重存在于vector中,当需要把特征a和特征b进行组合时,就把a的vector和b的vector做内积
FFM:是FM的增强版,也能做特征组合,而且对于每个特征,可以得到好几个vector
DeepFM:可以从原始特征中学习低阶和高阶特征交互,不需要做大量专业的特征工作
DNN:一般使用连续值特征,否则离线训练时间难以承受
传统CTR模型演化关系图
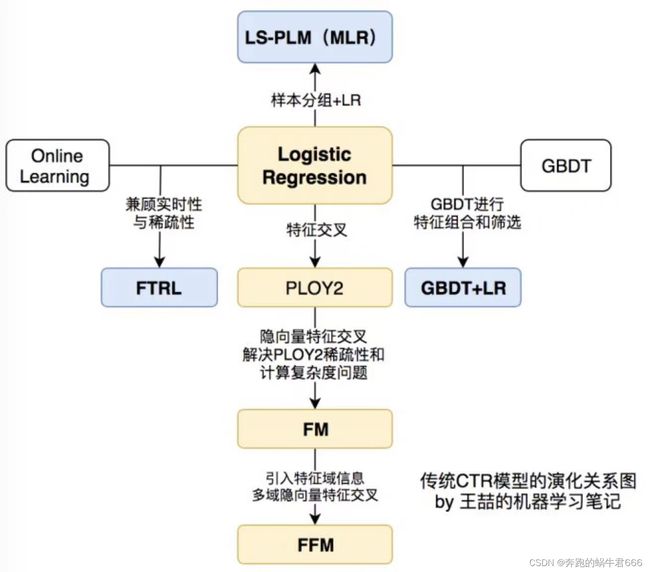
深度学习CTR模型演化关系图
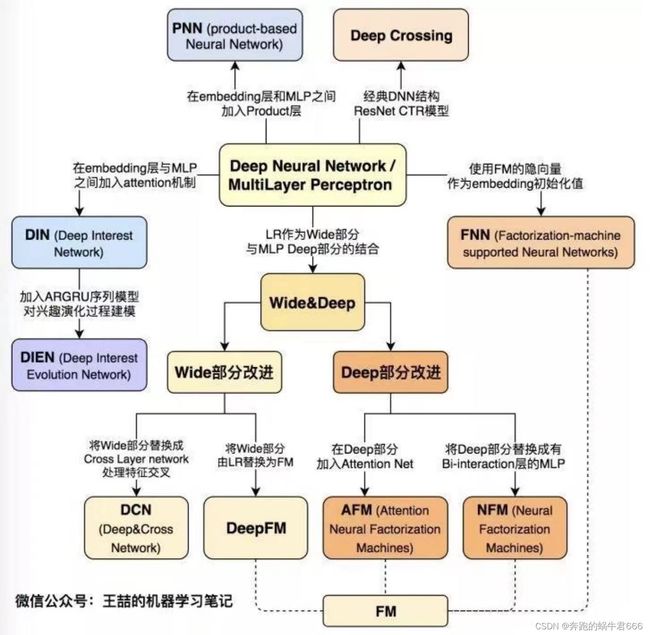
二.案例
1.背景
广告点击率预估是在线广告交易的核心环节之一,公司想确定CTR以确定将它们的钱花在数字广告上是否值得。如何有效利用积累的海量广告数据和用户数据去预测用户的广告点击率,是大数据应用在精准营销中的关键问题,也是所有智能营销平台必须具备的核心技术
通过人工智能技术构建预测模型预估用户的广告点击概率,即给定广告点击相关的广告,媒体,用户,上下文内容等信息的条件下预测广告点击概率
由于是CTR预估问题,所以可以简单抽象为样本分布不均衡的二分类问题,需要预测的内容为用户是否会点击该商品
2.数据预处理
对于CTR问题而言,广告是否被点击的主导因素是用户,其次是广告信息
数据探索一般先从活动特征,商品历史特征,时间序列特征入手
活动特征是外部导致(一般来源于业务本身)
商品历史特征(统计比例,权重设置)
时间序列特征(可以做的处理比较多)
缺失值处理:用-1填充,模型能够识别缺失值与非缺失值的不同
df = df.fillna(-1)时间提取
#时间特征:可以构造时间差,平均用时,总用时特征,不同分类组合的平均用时,总用时特征
df['day'] = df['time'].apply(lambda x: int(time.strftime("%d",time.localtime(x)))
df['hour'] = df['time'].apply(lambda x: int(time.strftime("%H",time.localtime(x)))布尔型数据转换
list(filter(lambda s: s=='bool',[df[i].dtype for i in df.columns]))
bool_feature = list(filter(lambda s: s!=0,[i if df[i].dtype == 'bool' else 0 for i in df.columns]))
#转换bool
for i in bool_feature:
df[i] = df[i].astype(int)advert_industry_inner特征提取
df['advert_industry_inner_1'] = df['advert_industry_inner'].apply(lambda x: x.split('-')[0])将广告相关特征放到一个列表
ad_cate_feature = ['adid','advert_id','orderid','advert_industry_inner_1','advert_industry_inner','advert_name','compaign_id','creative_id','creative_type','creative_tp_dnf','creative_ha_deeplink','creative_is_jump','creative_is_download']
df['creative_is_js'].value_counts()将媒体相关特征放到一个列表
media_cate_feature = ['app_cate_id','f_channel','app_id','inner_slot_id']
df['app_paid'].value_counts()上下文特征(用户信息)
content_cate_feature = ['city','carrier','province','nnt','devtype','osv','os','make']
df['os_name'].value_counts()
df['os'].value_counts()列表合并
origin_cate_list = ad_cate_feature + media_cate_feature + content_cate_feature将分类特征labelencode
for i in origin_cate_list:
df[i] = df[i].map(dict(zip(df[i].unique(),range(0,df[i].nunique()))))
df['os_name'].map(dict(zip(df['os_name'].unique(),range(0,df['os_name'].nunique())))).value_counts()
pd.DataFrame(df['os_name'].value_counts()).reset_index()3.特征工程
遍历所有特征做个新的统计特征
#函数参数
features = ['day','hour','creative_id']
data = df.copy()
is_feature = True
n = df[features].nunique()
#改变特证名
new_feature = 'count'
nunique = []
for i in features:
nunique.append(data[i].nunique())
new_feature += '_' + i.replace('add','')
#不符合以下条件就是无效的交叉特征,不作处理
#条件:features列表里不止1个元素,并且features列的独立元素特别少的情况
if len(features) > 1 and len(data[feature].drop_duplicates()) <= np.max(nunique):
print(new_feature,'is_unvalid cross feature:')
temp = data.groupby(features).size().reset_index().rename(columns={0:new_feature})
data = data.merge(temp,'left',on=features)
data.groupby(features2).size().reset_index().rename(columns={0:new_features})
count_feature_list = []
if is_feature:
count_feature_list.append(new_feature)
if 'day_' in new_feature:
data.loc[data.day==3,new_feature] = data[data.day==3][new_feature]*4
df['day'].value_counts()遍历两个交叉元素做个比例特征
ratio_feature_list = []
for i in media_cate_feature:
for j in content_cate_feature + ad_cate_feature:
new_feature = 'inf_' + i + '_' + j
df = feature_count(df,[i,j])
if df[i].nunique() > 5 and df[j].nunique() > 5:
df['ratio_' + j + '_of_' + i] = df['count_' + i + '_' + j] / df['count_' + i]
df['ratio_' + i + '_of_' + j] = df['count_' + i + '_' + j] / df['count_' + j]
ratio_feature_list.append('ratio_' + j + '_of_' + i)
ratio_feature_list.append('ratio_' + i + '_of_' + j)
print(i,'&',j)特征列表组合,新增统计特征和比例特征字段
cate_feature = origin_cate_list
num_feature = ['creative_width','creative_height','hour'] + count_feature_list + ratio_feature_list
feature = cate_feature + num_feature低频过滤:把只有一个元素的特征变成-1,然后再+1,变成0,只有一个元素的特征做onehotencode会造成维度爆炸
for feature in cate_feature:
#它这里不是一个DataFrame了,所以没有columns()属性,它是一个table
if 'count_' + feature in df.keys():
df.loc[df['count_' + feature] < 2,feature] = -1
df[feature] = df[feature] + 1构建训练集和测试集
label = list(click) + [-1]*(len(df) - len(click))
df['label'] = label
#测试集数据
predict = df[df.label == -1]
predict_result = predict[['instance_id']]
predict_result['predict_score'] = 0
predict_x = predict.drop('label',axis=1)
#建立训练集,里面全是正例样本,drop=True一定要写,意思是返回一个DataFrame
train_x = df[df.label != -1].reset_index(drop=True)
#pop()的功能就是删除并返回所删除的内容,将之传给训练集
train_y = train_x.pop('label').values
train_x.shape
predict_x.shape建立稀疏矩阵:压缩矩阵对象的内存空间和加速多数机器学习程序
base_train_csr = sparse.csr_matrix((len(train_x),0))
base_predict_csr = sparse.csr_matrix((len(predict_x),0))分类变量onehot encode
将多个特征对应的编码向量链接在一起构成特征向量
作用:分类编码变量,用来解决类别型数据的离散值问题;将每一个类可能取值的特征变换为二进制特征向量,每一类特征向量只有一个地方是1,其余位置都是0
#这个sparse.hstack非常有必要,代表粗细粒度
#使用hstack时要从粗粒度往细粒度加,否则细粒度的特征就会被压缩,信息损失很多,更省内存
enc = OneHotEncoder()
for feature in cate_feature:
enc.fit(df[feature].values.reshape(-1,1))
base_train_csr = sparse.hstack((base_train_csr,enc.transform(train_x[feature].values.reshape(-1,1))),'csr','bool')
base_predict_csr = sparse.hstack((base_predict_csr,enc.transforms(predict_x[feature].values.reshape(-1,1)))
base_train_csr.shape
base_predict_csr.shapeuser_tags特征
#建立一个文本提取器
cv = CountVectorizer(min_df=20)
#对于特征user_tags,对其进行文本特征提取并且跟之前的矩阵进行水平方向上的合并
#adtype(str)非常有必要,因为它可能原来是obj类型,反正这样不会错
for feature in ['user_tags']:
df[feature] = df[feature].astype(str)
cv.fit(df[feature])
base_train_csr = sparse.hstack((base_train_csr,cv.transform(train_[feature].astype(str))),'csr','bool')
base_predict_csr = sparse.hstack((base_predict_csr,cv.transform(predict_x[feature].astype(str))),'csr','bool')
#忽略少于20个文档中出现的术语
cv = CountVectorizer(min_df=20)
base_train_csr.shape
base_predict_csr.shape4.特征选择
方差选择法
from sklearn.feature_selection import SelectKBest,SelectPercentile
from sklearn.feature_selection import chi2
from sklearn.feature_selection import VarianceThreshold
sel_var = VarianceThreshold(threshold=0.001)
sel_var.fit(base_train_csr)
base_train_csr = sel_var.transform(base_train_csr)
base_predict_csr = sel_var.transform(base_predict_csr)稀疏矩阵从布尔转换为float
#训练集,预测集压缩稀疏矩阵:将数字特征列表num_feature跟之前的矩阵进行水平方向上的合并
train_csr = sparse.hstack((sparse.csr_matrix(train_x[num_feature]),base_train_csr),'csr').astype('float32')
predict_csr = sparse.hstack((sparse.csr_matrix(predict_x[num_feature]),base_predict_csr),'csr').astype('float32')
sys.getsizeof(train_csr)5.构建模型及交叉验证
StratifiedKFold:分层采样,训练集和测试集中各类别样本的比例与原始数据相同(分类问题)
KFold:分层采样,将数据分成训练集和测试集,不考虑训练集和测试集中各类别数据是否相同(回归问题)
#建立一个lgb_model,LGBM分类器
lgb_model = lgb.LGBMClassifier(
boosting_type='gbdt',num_leaves=61,reg_alpha=3,reg_lambda=1,
max_depth=-1,n_etimators=5000,objective='binary',
subsample=0.8,colsample_bytree=0.8,subsample_freq=1,
learning_rate=0.035,random_state=2022,n_jobs=10
)
#建立一个分层k折采样器,为5折
skf = StratifiedKFold(n_split=5,random_state=2022,shuffle=True)6.模型训练与评估
这类问题评估函数常用logloss和AUC
logloss:更关注和观察数据的吻合程度,用于评估模型输出概率与训练数据概率的一致程度,logloss越小,模型预估的ctr越准
AUC:更关注rank order,主要预估模型对于整体样本的排序能力
如果是按照概率期望来进行收费投放的话就用logloss,如果定投一定量就用AUC,主要和业务相关
best_score = []
for index,(train_index,test_index) in enumerate(skf.split(train_csr,train_y)):
lgb_model.fit(train_csr[train_index],train_y[train_index],eval_set=[(train_csr[train_index],train_y[train_index],(train_csr[test_index],train_y[test_index])],early_stopping_rounds=200,verbose=10)
best_score.append(lgb_model.best_score_['valid_1']['binary_logloss'])
print(best_score)
#如果在训练期间启用了早期停止,可以通过best_iteration方式从最佳迭代中获得预测
test_pred = lgb_model.predict_proba(predict_csr,num_iteration=lgb_model.best_iteration_)[:,1]
predict_result['predicted_score'] = predict_result['predicted_score'] + best_pred
predict_result['predicted_score'] = predict_result['predicted_score']/5
mean = predict_result['predicted_score'].mean()
print('mean',mean)