文本摘要的调研
文本摘要方式:
抽取式文本摘要(extractive),按照一定的权重,从原文中寻找跟中心思想最接近的一条或几条句子。
生成式文本摘要(abstractive),在计算机通读原文后,在理解整篇文章意思的基础上,按自己的话生成流畅的翻译。
抽取式文本摘要:Text rank排序算法,大体思想是先去除文章中的一些停用词(为节省存储空间和提高搜索效率,在处理之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words),之后对句子的相似度进行度量,计算每一句相对另一句的相似度得分,迭代传播,直到误差小于0.0001。再对上述得到的关键语句进行排序,便能得到想要的摘要。抽取式摘要主要考虑单词词频,并没有过多的语义信息,无法建立文本段落中的完整语义信息。
生成式文本摘要主要依靠深度神经网络结构实现,2014年GoogleBrain提出的Seq2Seq,开启了NLP中端到端网络的火热研究。
但就目前的形势而言,工业界应用广泛的还是抽取式文本摘要。抽取式文本摘要很多,主题不易偏离,适应性广,速度快。
最传统的抽取式文本摘要方法,是Lead3算法。最常用的是TextRank。
Bert With Summarization
结合了Textrank和Bert,属于抽取式文本摘要。
首先介绍一下模型的结构,原始的BERT的输出是针对Token而不是句子的,而且原始BERT的输入只有两个句子,并不适合文本摘要。
因此首先作者对BERT的结构做了一些更改,让他变得更适合文本摘要这个任务,作者的更改可以在下图体现到:
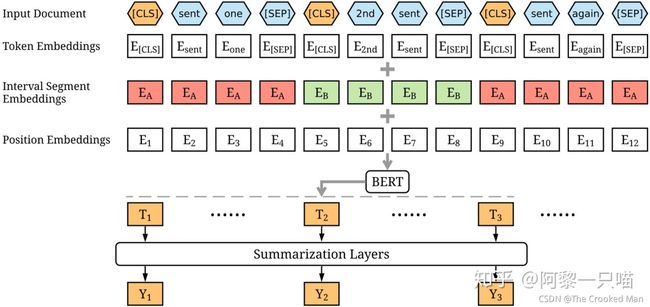
作者使用[CLS]和[SEP]区分每一个句子,在原始的BERT中[CLS]表示一整个句子或者句子对的内容,在这里作者修改了模型结构,使用[CLS]来区分每一个句子
作者对每一个句子增加了segment embedding,segment embedding由句子的奇偶顺序决定,例如对于句子[sen1, sen2, sen3, sen4, sen5]他们的segment embedding就是[EA, EB, EA, EB, EA]。
Summarizationlayer
得到了句子的向量之后,接下来要做的工作就是判断这句话是否要组成文本的摘要。这就是一个二分类的工作了,作者尝试了三种summarization layer,分别是
1、传统的全连接层
2、Inter-sentence Transformer
结构如下图所示,初始位置的句子向量为position embedding,之后每一个位置的输入都是由上一个位置的输入经过多头Attention层,layer norm和全连接层之后的输出结果。最后的输出依然是一个二分类。
3、RNN层
这里是在BERT之后接了LSTM层,LSTM是非常适合NLP任务的一种结构,当然最后输出也是一个二分类的结果。
实验结果
作者在CNN Daily和NYT两个公开数据集上进行了实验,实验效果如下图所示,其中
Lead是抽取文本的前三句话作为摘要
REFRESH是优化了ROUGE矩阵的抽取式文本摘要系统
NEUSUM是抽取式文本摘要的state-of-art的效果
PGN是Pointer Generator,生成式文本摘要
DCA是当前生成式文本摘要的state-of-art的效果

生成式文本摘要研究进展
生成式文本摘要需要通过转述、同义替换、句子缩写生成。
生成式神经网络模型的基本结构主要由编码器、解码器组成。
编码器负责将输入的原文本编码成一个向量C
解码器负责从这个向量C提取重要信息、加工剪辑、生成文本摘要。
Seq2Seq广泛应用于存在输入序列和输出序列的场景,比如机器翻译(一种语言序列到另一种语言序列),image captioning(图片像素序列到语言序列)、对话机器人(如问题到回答)
生成式缺点:原文本长度过长的话,效果就会不太好。由于“长距离依赖”问题,RNN到最后一个时间步输入单词的时候,已经丢失了相当一部分的信息。这时候编码生成的语义向量C同样也丢失了大量信息,就导致生成的摘要不够准确。因此Bahdanau引入attention[1]。eg:关注“知识”可以在翻译knowledge时更有针对性。
基本模型
Seq2Seq的Encoder&Decoder -> 用RNN/CNN/LSTM实现
编码器基于CNN,解码器基于RNN也可以。
最新进展
如何评价自动生成的摘要
ROUGE-n n个字幕组重叠

ROUGE-L 使用了最长公共子序列
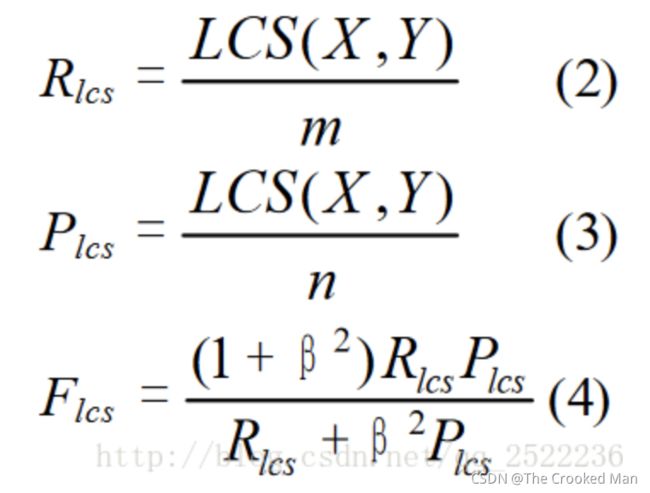
ROUGE-W
ROUGE-S
ROUGE-SU
生成式文本摘要实例
https://blog.csdn.net/valleria/article/details/104505818
数据集
来自NLPCC2017
一共约50K条数据, 分为摘要(summarization)和原文(text)两部分.
使用正则匹配清洗数据集,得到段落的主体部分。
部分数据的清洗效果, 上面是原文, 下面是清洗后的数据:


评估方法
本项目使用的评估方法是ROUGE-N和ROUGE-L
ROUGE-N的最大值是1. 即"参考摘要"里的所有字都在"模型自动生成的摘要"里出现过.
词表构建
直接进行分词,将每个词映射成对应的input_id
即padding,补全用
unknown,未知词/不在词表里的词
开始符
结束符
Baseline模型使用了sequence to sequence结构+attention机制.
encoder部分用了双向LSTM结构(即BiLSTM), decoder里面用了单向LSTM.
由于单向结构只考虑了上下文中的"上文"信息, 并没有考虑后面的内容. 双向结构同时拥有从后往前的信息, 即考虑了"下文"的信息.
Baseline结果
![]()
![]()
基线模型分数:
Rouge-1分数: 0.298
Rouge-2分数: 0.137
Rouge-L分数: 0.633
摘要部分质量并不是很好, 并且有相当多的重复词语。
科研现状调研
模型评价方式
摘要的主流评价方向:标准值和bert score、QA、CLOZE

一开始我们做摘要的评测时,让这个模型根据原始的document进行摘要作为评测,如果给摘要里加入一些error,想看一下评价指标会有什么样的变化,来证明它对评价指标是敏感的。
R-3和 bert score是最符合直观感受的,但有一些评价指标不降反升,因此推断它们是有问题的。
Pointer-Generator(PG、指针网络)
什么是指针网络
首先,指针网络中的指针和c语言中的指针没有关系。
关于指针网络的任务类型,在某些任务中,输入严格依赖于输入,或者说输出只能从输入中选择。如果使用传统的seq2seq模型,则忽略了输入只能从输出中选择这个先验信息。
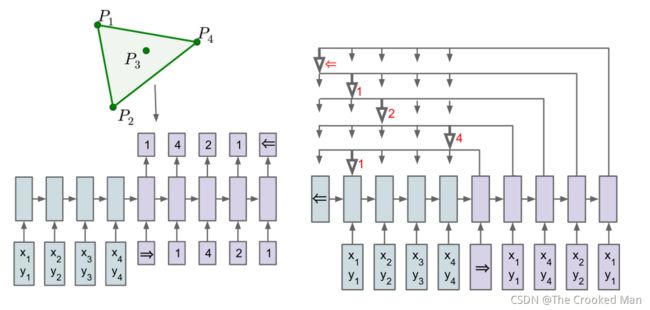
Pointer Network 和 Seq2Seq 的区别如下图所示,图中展示了凸包问题。Seq2Seq 的 Decoder 会预测每一个位置的输出 (但是输出目标的数量是固定的),而 Pointer Network 的 Decoder 直接根据 Attention 得到输入序列中每一个位置的概率,取概率最大的输入位置作为当前输出。
左边是seq2seq,右边是指针网络。
https://www.cnblogs.com/zingp/p/11571593.html#_label0
Seq2seq attention model

encoder:
(1)embedding
(2)将embedding的结果输入到lstm中
(3)对lstm的每一个输出进行加权求和(每一个encoder存在一个归一化的系数,该系数由上一步的decoder生成)
指针生成器模型,在基础上加入了一个生成概率,该概率决定从词汇表生成单词的概率,而不是从源文本复制单词的概率。
抽取式摘要从源文档中抽取关键句和关键词组成摘要,摘要全部来源于原文。生成式摘要根据原文,允许生成新的词语、原文本中没有的短语来组成摘要。
仅仅使用seq2seq可以实现生成式摘要,但存在两个问题:
(1)可能不准确的再现问题,无法处理词汇不足(oov)问题
(2)倾向于重复自己
指针生成网络从两个地方进行改进
(1)该网络通过指向(pointer)从源文本中复制单词,有助于准确地复制信息,同时保留通过生成器生成新单词的能力。
(2)使用coverage机制来跟踪已总结的内容,防止重复。
coverage mechanism可以解决过翻译、漏翻译的内容。如:不准确的摘要细节生成(UNK为未登陆词,无法解决OOV问题),绿色的字体标明了模型生成了重复文本。

为什么要用PG?
sequence-to-sequence为生成式摘要提供了一种可行的新方法。然而,这些模型有两个缺点:它们容易复制事实上的细节不准确,他们倾向于重复自己。而指针生成网络从两方面做了改进。第一,使用指针生成器网络可以通过指向从源文本中复制单词,这有助于准确复制信息,同时保留generater的生成能力。第二,使用coverage跟踪摘要的内容,不断更新注意力,从而阻止文本不断重复。
传统的Attention
传统的 Attention 会根据 Attention 值融合 Encoder 的每一个时刻的输出,然后和 Decoder 当前时刻的输出混在一起再预测输出。如下面的公式所示,e表示 Encoder 的输出,d 表示 Decoder 的输出,W 和 v 都是可以学习的参数。

Pointer Network的Attention
Pointer Network 计算 Attention 值之后不会把 Encoder 的输出融合,而是将 Attention 作为输入序列 P中每一个位置输出的概率。

seq2seq中的注意力机制,和Attention有所不同。
Attention模型中,当我们翻译当前词语时,我们会寻找源语句中相对应的几个词语,并结合之前的已经翻译的部分作出相应的翻译,如下图所示,当我们翻译“knowledge”时,只需将注意力放在源句中“知识”的部分,当翻译“power”时,只需将注意力集中在"力量“。这样,当我们decoder预测目标翻译的时候就可以看到encoder的所有信息,而不仅局限于原来模型中定长的隐藏向量,并且不会丧失长程的信息。
抽取式文本摘要
主题建模
主题模型(topic model)是以非监督学习的方式对文集的隐含语义结构(latent semantic structure)进行聚类(clustering)的统计模型
主题模型是对文字隐含主题进行建模的方法。它克服了传统信息检索中文档相似度计算方法的缺点,并且能够在海量互联网数据中自动寻找出文字间的语义主题。
在这里,我们先定义一下主题究竟是什么。主题就是一个概念、一个方面。它表现为一系列相关的词语。比如一个文章如果涉及到“百度”这个主题,那么“中文搜索”、“李彦宏”等词语就会以较高的频率出现,而如果涉及到“IBM”这个主题,那么“笔记本”等就会出现的很频繁。如果用数学来描述一下的话,主题就是词汇表上词语的条件概率分布 。与主题关系越密切的词语,它的条件概率越大,反之则越小。

通俗来说,一个主题就好像一个“桶”,它装了若干出现概率较高的词语。这些词语和这个主题有很强的相关性,或者说,正是这些词语共同定义了这个主题。对于一段话来说,有些词语可以出自这个“桶”,有些可能来自那个“桶”,一段文本往往是若干个主题的杂合体。我们举个简单的例子,见下图

主题模型的工作原理
首先,我们用生成模型的视角来看文档和主题这两件事。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到的。那么,如果我们要生成一篇文档,它里面的每个词语出现的概率为:

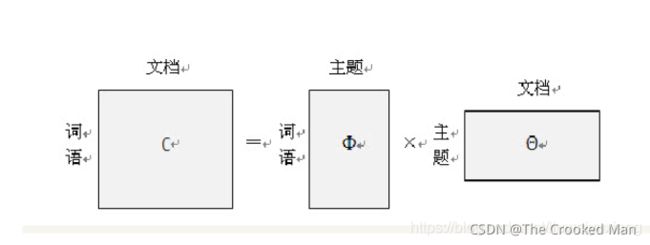
左边的矩阵表示每篇文章中每次词语出现的概率;中间的Φ矩阵表示的是每个主题中每个词语出现的概率 。
右边的矩阵表示的是每篇文档中各个主题出现的概率 ,可以理解为一段话中每个主题所占的比例。
假如我们有很多的文档,比如大量的网页,我们先对所有文档进行分词,得到一个词汇列表。这样每篇文档就可以表示为一个词语的集合。对于每个词语,我们可以用它在文档中出现的次数除以文档中词语的数目作为它在文档中出现的概率 。这样,对任意一篇文档,左边的矩阵是已知的,右边的两个矩阵未知。而主题模型就是用大量已知的“词语-文档”矩阵 ,通过一系列的训练,推理出右边的“词语-主题”矩阵Φ 和“主题文档”矩阵Θ 。