PAI-Diffusion模型来了!阿里云机器学习团队带您徜徉中文艺术海洋
作者:汪诚愚、段忠杰、朱祥茹、黄俊
导读
近年来,随着海量多模态数据在互联网的爆炸性增长和训练深度学习大模型的算力大幅提升,AI生成内容(AI Generated Content,AIGC)的应用呈现出爆发性增长趋势。其中,文图生成(Text-to-image Generation)任务是最流行的AIGC任务之一,旨在生成与给定文本对应的图像。典型的文图模型例如OpenAI开发的DALL-E和DALL-E2、Google提出的Parti和Imagen、基于扩散模型的Stable Diffusion和Stable Diffusion2.0等。
然而,上述模型一般不能用于处理中文的文图生成需求,而且上述模型的参数量庞大,很难被开源社区的广大用户直接使用。在先前文图生成模型(看这里)工作积累之上,阿里云机器学习(PAI)团队进一步开源了PAI-Diffusion系列模型,包括一系列通用场景和特定场景的文图生成模型,例如古诗配图、二次元动漫、魔幻现实等。这些模型的Pipeline除了包括标准的Latent Diffusion Model,还集成了PAI团队先前提出了中文CLIP跨模态对齐模型(看这里),及图像超分模型,使得模型可以生成符合中文文本描述的、各种场景下的高清大图。
本⽂简要介绍PAI-Diffusion模型及其体验方式。
Diffusion技术概述
我们的模型是基于一个基于隐式扩散模型(Latent Diffusion Model, LDM)的文图生成模型。接下来,我们简要地介绍LDM的原理以及技术改进。
Latent Diffusion Model原理
扩散模型有两个过程,分别为扩散过程和逆扩散过程。如下图,扩散过程为从左到右的过程 ( D a t a → N o i s e ) ( Data→Noise ) (Data→Noise),表示对图片逐步增加噪声。逆扩散过程为从右到左的过程 ( N o i s e → D a t a ) ( Noise→Data) (Noise→Data),表示从高斯噪声中逐步去噪,复原出原图。

扩散模型中的噪声是在像素空间进行的计算的,维度与图像一致,由此导致加噪和去噪过程的时间和内存消耗会非常大。Latent Diffusion Model利用自动编码器(Auto Encoder)将图像数据从高维像素空间表示 ( x ) ( x ) (x)转换到低维潜空间表示 ( z ) ( z ) (z),之后在低维空间进行去噪生成,大大降低时间和内存消耗。
文本引导的Diffusion模型主要包含两部分:文本编码器(Text Encoder)和U-Net;其中U-Net用于模拟噪声的分布,文本编码器把输入文本转换成U-Net可以理解的空间编码,引导噪声的采样以生成符合文本描述的图片。文本作为条件 τ θ τθ τθ输入,和时间步长 t t t 一起,以简单连接或者交叉注意力的方式,指导 z z z的去噪。推理时,由Auto Encoder将 T T T 时刻生成的表示 z z z 转换为像素空间的表示 x x x ,即可得到像素级别的图片。

StableDiffusion
StableDiffusion是在LAION-5B数据集子集上训练的一个LDM,可以在消费级GPU运行,生成 512 × 512 512×512 512×512的图像仅需要几秒。目前StableDiffusion公布了v1和v2两个版本。StableDiffusion1.0主要支持文本引导的图像生成(text-to-img)、草图引导的图像生成(sketch-to-img)。最近发布的StableDiffusion2.0改进了文本编码器,并且默认生成的图像分辨率也提升至 768 × 768 768×768 768×768,可支持 2048 × 2048 2048×2048 2048×2048 或更高。此外,StableDiffusion2.0增加了新的特性,支持深度图引导的图像生成(depth-to-img)和文本引导的图像编辑(text guided inpainting)。
PAI-Diffusion模型详解
由于现有Diffusion模型主要使用英文数据进行训练,如果直接使用机器翻译将英文数据翻译成中文进行模型训练,因为中英文在文化和表达上具有很大的差异性,产出的模型通常无法建模中文特有的现象。此外,通用的StableDiffusion模型由于数据源的限制,很难用于生成特定领域、特定场景下的高清图片。PAI-Diffusion系列模型由阿里云机器学习(PAI)团队发布并开源,除了可以用于通用文图生成场景,还具有一系列特定场景的定制化中文Diffusion模型,包括古诗配图、二次元动漫、魔幻现实等。在下文中,我们首先介绍PAI-Diffusion的模型Pipeline架构,包括中文CLIP模型、Diffusion模型、图像超分模型等。
模型Pipeline架构

PAI-Diffusion模型Pipeline如上所示,分为四部分:
- Text Encoder:把中文文本输入转化成 Embedding 向量,我们采用EasyNLP中文CLIP跨模态对齐模型(看这里)的Text Transformer作为Text Encoder;
- Latent Diffusion Model:在 Latent 空间中根据文本输入处理随机生成的噪声;
- Auto Encoder:将 Latent 空间中的张量还原为图片;
- Super Resolution Model:提升图片分辨率,这里我们使用ESRGAN作为图像超分模型。
我们在使用Wukong数据集中的两千万中文图文数据对 Latent Diffusion Model部分进行了约 20 天的预训练,随后在多个下游数据集中进行了微调。
多场景艺术画鉴赏
下面我们展示几个不同场景下PAI-Diffusion模型的艺术画生成效果。
通用场景

古诗配图

二次元动漫

艺术画

魔幻现实
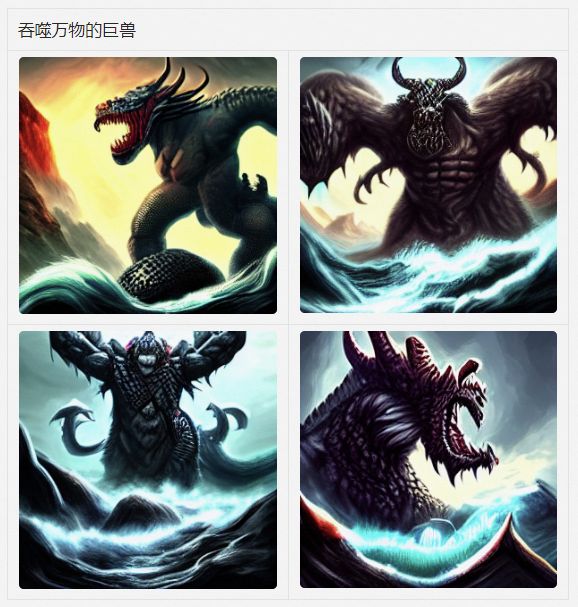
真实业务场景示例
除了艺术画生成,PAI-Diffusion模型也能广泛地应用在各个真实业务场景中,以下我们给出在电商和美食场景下的文图生成效果。
电商商品

世界美食

轻松体验PAI-Diffusion模型
PAI-Diffusion模型可以通过多个途径进行体验。我们在阿里云机器学习AI能力中心上展示了更多不同场景下模型生成的高清大图。阿里云机器学习产品PAI-DSW(Data Science Workshop)提供了交互式的开发体验,方便用户通过调用Python API访问这些模型。此外,为了方便开源社区用户的体验,我们也在HuggingFace Space上展示了多个PAI-Diffusion模型的应用。
阿里云机器学习AI能力中心
阿里云机器学习AI能力中心提供了场景多样的AI实操案例,包括图像智能、自然语言处理、视频智能、多模态等各个领域的案例。我们也上架了PAI-Diffusion模型文图生成的功能,提供了更多不同场景下模型生成的高清大图。用户可以在这里体验AI能力中心的文图生成功能,示例参见下图。
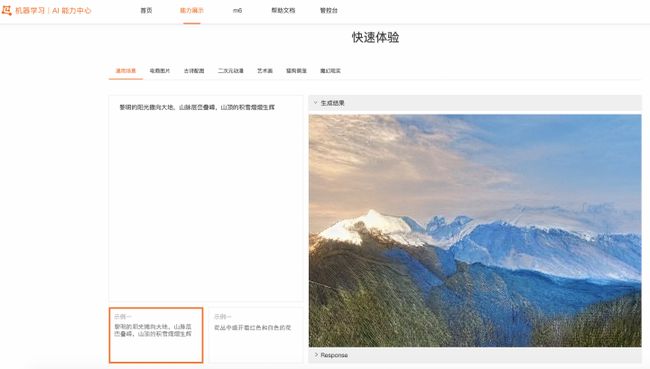
阿里云机器学习PAI-DSW
PAI-DSW(Data Science Workshop)是阿里云机器学习平台PAI开发的云上IDE,面向不同水平的开发者,提供了交互式的编程环境(文档)。在DSW Gallery中,提供了各种Notebook示例,方便用户轻松上手DSW,搭建各种机器学习应用。我们也在DSW Gallery中上架了使用PAI-Diffusion模型进行中文文图生成的Sample Notebook,欢迎大家体验!

HuggingFace Space
为了方便开源社区用户的体验,我们在HuggingFace Space上展示了多个PAI-Diffusion模型的文图生成应用。以世界美食为例(https://huggingface.co/spaces/alibaba-pai/pai-diffusion-food-large-zh),用户只需要输入或者选择菜品名称作为输入,就可以得到模型生成的高清大图,示例参见下图。


未来展望
在这一期的工作中,我们公开了一系列PAI-Diffusion模型,支持各种场景下的中文文图生成功能。在未来,我们计划在EasyNLP框架(https://github.com/alibaba/EasyNLP)中集成这些模型的Checkpoint,并且提供简洁高效的训练接口,方便开源社区用户在资源有限情况下进行少量领域相关的微调,进行各种艺术创作,敬请期待。我们也将致力于PAI-Diffusion模型的优化策略,包括模型推理速度优化、生成图片质量提升和支持更为复杂的图像编辑功能。此外,阿里云机器学习PAI团队也在持续推进中文多模态模型的自研工作,欢迎用户持续关注我们,也欢迎加入我们的开源社区,共建中文NLP和多模态算法库!
Github地址:https://github.com/alibaba/EasyNLP
Reference
- Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. EMNLP 2022
- Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer. High-Resolution Image Synthesis with Latent Diffusion Models. CVPR 2022
- Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. ICML 2021
- Jiaxi Gu, Xiaojun Meng, Guansong Lu, Lu Hou, Minzhe Niu, Xiaodan Liang, Lewei Yao, Runhui Huang, Wei Zhang, Xin Jiang, Chunjing Xu, Hang Xu. Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework. arXiv
- Ling Yang, Zhilong Zhang, Yang Song, Shenda Hong, Runsheng Xu, Yue Zhao, Yingxia Shao, Wentao Zhang, Bin Cui, Ming-Hsuan Yang. Diffusion models: A comprehensive survey of methods and applications. arXiv
EasyNLP阿里灵杰回顾
- 阿里灵杰:阿里云机器学习PAI开源中文NLP算法框架EasyNLP,助力NLP大模型落地
- 阿里灵杰:预训练知识度量比赛夺冠!阿里云PAI发布知识预训练工具
- 阿里灵杰:EasyNLP带你玩转CLIP图文检索
- 阿里灵杰:EasyNLP中文文图生成模型带你秒变艺术家
- 阿里灵杰:EasyNLP集成K-BERT算法,借助知识图谱实现更优Finetune
- 阿里灵杰:中文稀疏GPT大模型落地 — 通往低成本&高性能多任务通用自然语言理解的关键里程碑
- 阿里灵杰:EasyNLP玩转文本摘要(新闻标题)生成
- 阿里灵杰:跨模态学习能力再升级,EasyNLP电商文图检索效果刷新SOTA
- 阿里灵杰:EasyNLP带你实现中英文机器阅读理解
- 阿里灵杰:EasyNLP发布融合语言学和事实知识的中文预训练模型CKBERT
- 阿里灵杰:当大火的文图生成模型遇见知识图谱,AI画像趋近于真实世界