知识图谱x推荐《A Survey on Knowledge Graph-Based Recommender Systems》
2020 IEEE Transactions on Knowledge and Data Engineering(TKDE)
pdf下载
摘要
该文对在推荐系统中引入知识图作为辅助信息的相关工作做出了总结,并将其分为三类,即embedding-based方法、connection-based方法和propagation-based方法。同时,根据这些方法的特点,对每一类进行了细分。此外,该文还通过研究如何利用知识图谱进行准确和可解释的推荐,对所提出的算法进行了研究。最后,总结了一些相关数据集并提出了该领域的几个潜在研究方向。
前言
- 推荐系统存在的问题
推荐算法是推荐系统的核心元素,可分为基于协同过滤(CF)的推荐系统、基于内容的推荐系统和混合推荐系统。基于CF的推荐根据交互数据中users或items的相似性来建立user偏好模型,而基于内容的推荐则利用item的内容特征。基于CF的推荐系统不需要在基于内容的推荐系统中进行特征提取,但存在数据稀疏和冷启动问题。所以,人们提出了混合推荐系统来统一交互层的相似度和内容层的相似度。 - 推荐系统引入知识图谱的好处
(1). 通过将users和user侧信息集成到KG中,更准确地捕捉到users和items之间的关系以及user的偏好。
(2). 基于KG的推荐系统的好处是推荐结果的可解释性。 - 该文的贡献
(1). 将现有基于知识图谱的推荐系统相关工作分为三类:

(2). 总结了相关工作如何利用KG进行解释性推荐以及其常用的技术。
(3). 按照不同的应用场景对现有工作进行分类并收集这些中评估的数据集。
背景
该部分主要介绍了基于KG的推荐系统的基本知识以及相关工作,涉及相关知识及概念请读者自行了解。
- Recommender Systems
- Heterogeneous Information Network (HIN)
- Knowledge Graph (KG)
- Item Knowledge Graph
- User-Item Knowledge Graph
- Meta-path
- Meta-graph
- Knowledge Graph Embedding (KGE)
- H-hop Neighbor
- Entity Triplet Set
后续相关符号及其描述见下图。

基于KG的推荐系统方法总结
下图为一些相关论文利用KG进行推荐的方法。

| 缩写 | 含义 | 缩写 | 含义 |
|---|---|---|---|
| Emb. | embedding-based 方法 | RU. | user的细化 |
| Conn. | connection-based 方法 | RI. | item的细化 |
| Prop. | propagation-based 方法 | RUI. | user和item的细化 |
| TSL. | two-stage learning 方法 | * | 推荐模型是可解释的 |
| JL. | joint learning 方法 | KG Embed. | KGE方法 |
| MTL. | multi-task learning 方法 | IKG | item KG |
| MSB. | 基于 meta-structure的方法 | UIKG | user-item KG |
| PEB. | 基于path-embedding的方法 | — | 该模型没有采用KGE方法,或者该模型没有解决此类问题 |
1. Embedding-based 方法
此类研究包含两个基本模块,一个是graph embedding 模块,用于学习KG中实体和关系的表示;另一个是recommendation 模块,用于估计user u i u_{i} ui 对具有学习特征的item v j v_{j} vj 的偏好。

(1) Two-stage learning
Two-stage learning 训练步骤:
- 用KGE算法学习实体和关系的表示
- 将经过预训练的图相关embeddings与其他user特征和item特征一起输入推荐模块中进行预测
相关方法介绍:
- DKN 首先挖掘新闻之间的知识层次关系,结合Kim-CNN所学句子的文本embedding 和通过TransD在新闻内容中实体的知识级embedding 对新闻建模,通过使用注意力机制聚合历史点击新闻embedding,最后通过MLP计算user对候选新闻的喜好。
- KSR 该方法用于序列推荐,利用GRU网络捕获用户的顺序偏好,利用KV-MV模块知识库信息对用户的属性级偏好进行建模,将 u i t u_{i}^{t} uit和 v j v_{j} vj转换为同一维度后,可以通过内积来估计用户对项目的偏好。
- KTGAN 提出了一个基于GAN的推荐模型。首先,通过在电影KG上引入Metapath2Vec模型,并在电影的属性上使用带有Word2Vec模型的tag embedding来学习电影 v j v_{j} vj的knowledge embedding;然后学习生成器G和鉴别器D来改进users和items的初始表示,通过G的得分函数对电影进行排名,为目标user生成推荐。
- BEM 分别使用TransE模型和GraphSAGE模型从item-attribute level knowledge和behavior graph学习初始embedding;设计了贝叶斯生成模型互相细化这两种表示,并在每个图种保留项目结构信息;在behavior graph中找到最接近的items来生成推荐。
Two-stage learning 优缺点:
- Two-stage learning易于实现,KG embedding通常被视为后续推荐模块的额外特征。
- KG embedding可以在没有交互数据的情况下学习,因此,大规模交互数据集不会增加计算复杂性。
- KG通常是稳定的,一旦学习到embedding,就不需要频繁地更新它们。
- KGE模型优化的实体embedding更适合于图内应用,如KG补全。
- 由于KGE模块和推荐模块是松散耦合的,所学习的embeddings可能不适合推荐任务
(2) Joint Learning
以端到端的训练方式联合学习图embedding模块和推荐模块,推荐模块可以引导图embedding模块中的特征学习过程。
相关方法介绍:
- CKE 使用TransR对item属性级特征进行编码,通过自动编码器提取文本特征和视觉特征,将这三个特征学习模块和推荐模块一起构成目标函数。
- SHINE 利用自动编码器模型分别从user之间的情感网络、user关系的社交网络和user属性级知识的文件网络学习用户特征。
- CFKG 采用TransE对图进行编码,并通过hinge loss来学习实体和关系的embedding。推荐模块根据user和item的欧氏距离对候选item进行排名,其中欧式距离是通过“buy”关系得到的。
Joint Learning 优缺点:
Joint Learning方法可以使用KG结构来规范推荐过程。但是,需要微调不同目标函数的组合。
(3) Multi-task Learning
因为user-item二分图中的item及其再KG中的关联实体可能共享相似的结构,所以,items和实体之间的low-level feature转移有助于促进推荐系统的效果提升。
相关方法介绍:
- MKR 由推荐模块和KGE模块组成,他们通过cross&compress单元连接共享知识。
- KTUP 采用TransH学习实体和关系的embedding,和推荐模块共同训练
Multi-task Learning 优缺点:
有助于防止推荐系统过度拟合,提高模型的泛化能力。但是,它也需要将不同的任务集成在一个框架下。
小结

2. Connection-based方法
利用user-item KG挖掘图中的实体之间的关系
- 基于Meta-structure的方法。利用meta-path和meta-graph计算实体之间的相似度,预测users的兴趣
- 基于path-embedding的方法。将user-item pairs和item-item pairs之间的连接模式编码成向量,整合到推荐框架中。
面临挑战:
- 如何为不用的任务设计适当的meta-paths
- 如何为实体之间的连接模式建模
(1). 基于Meta-structure的方法
基于元路径具有高度相似性的实体在隐空间应该很接近,所以利用不同meta-path路径中实体的连接相似性来图正则化约束user和item的表示。
三种实体相似性:
User-User相似性
Item-Item相似性
User-Item相似性
相关方法介绍:
- Hete-MF 只提取了item-item相似性
- Hete-CF 提取了user-user、item-item、user-item相似性
- HeteRec 利用实体相似性来预测user对unrated items的兴趣,局限性是每个路径的学习权重对于所有user都是相同的。
- HeteRec-p 引入聚类算法对user过去的行为进行分类,然后生成个性化的推荐。
- SemRec 通过相似users评分的加权综合来预测unrated items的偏好
- FMG 通过meta-graph来捕捉异构图中实体之间的关系
基于Meta-structure方法的优缺点:
这种方法的推荐结果是可解释的;但是,选择meta-path或meta-graph需要一定的领域知识,meta-structures可能因不同数据集而存在差异。
(2). 基于Path-embedding的方法
通过学习连接user-item KG中的user-item pairs或item-item KG种的item pairs的路径的显式embedding,来直接对user-item或item-item关系建模。
相关方法介绍:
- MCRec 用CNN学习每个路径实例的embedding,对计算过的meta-path embedding进行加权平均,得到user和item之间的交互embedding;另外user embedding和item embedding通过交互embedding进行更新。但仍需手动定义meta-path的类型和数量。
- RKGE 自动挖掘user和item之间的路径关系
- KPRN 采用实体embedding和关系embedding两种方法构造路径序列
- RuleRec 将外部items中的相关item的连接模式转换为规则特征
- PGPR 使用强化学习自动的搜索user-item pairs之间的合理路径
基于Path-embedding的方法的优缺点:
大多数模型可以自动挖掘连接模式,无需预先定义meta-structures。但是如果路径数过大会影响模型的性能。
小结

3. Propagation-based方法
通过聚集KG中multi-hop邻居的embedding来细化实体表示,利用user和潜在item丰富表示来预测user偏好。
面临挑战:
- 如何给不同的邻居分配适当的权重
- 如何在不同的关系边上传播消息
- 如何提高模型的可扩展性
(1). user表示的细化
基于user的交互历史来改进user表示,在item KG中逐层向外传播user的偏好,即沿着KG种的路径来传播用户历史兴趣偏好。学习user表示的过程为:

相关方法介绍:
- RippleNet 通过训练关系矩阵来为图中的邻域赋值,偏好矩阵难以训练
- AKUPM 采用TransR对实体进行建模,应用自注意力机制为聚合过程中的实体分配权重,可以更好的捕捉user兴趣
user表示的细化的优缺点:
KG中边的权重是明确的,可以选择连接候选item和交互item的显著路径,并作为推荐结果的解释。但只细化了user的表示
(2). item表示的细化
通过item KG中item的multi-hop邻居来学习候选item的高阶表示,在内向传播过程中,采用了图注意力机制,不同邻居的权重是用户特定和关系特定的。传播过程为:

相关方法介绍:
- KGCN 每个邻居的权重是user特定的。容易出现过拟合,因为user-item交互是整个框架的唯一监督信号
- KGCN-LS 再KGCN模型上增加了label smoothness正则化
user表示的细化的优缺点:
只细化了item的表示
(3). user和item表示的细化
user embedding和item embedding可以在传播过程中用它们相应的邻居来细化
相关方法介绍:
- KGAT 通过embedding传播直接模拟user和item之间的高阶关系。
- KNI 利用增强的user邻域表示和item邻域表示来进行偏好估计
- IntentGC 将原来的user-item KG转换成两个user-user和item-item多关系图。
以上方法可能会引入不相关的邻居 - AKGE 通过在这个user-item pair的子图中传播信息来学习user和候选item的增强表示
user和item表示的细化的优缺点:
图中的关系越多,会带来不相关的实体,可能会在聚合过程中误导用户的偏好。
小结
基于传播的方法随着图形的变大,模型很难收敛,需要更快的图卷积运算;在每一层随机采样的方法会导致信息的缺失。
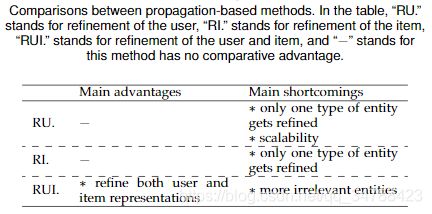
总结
| 优点 | 缺点 | |
|---|---|---|
| embedding-based | 编码容易 适用大多数场景 |
不能充分挖掘KG中的信息 不适合解释推荐 |
| connection-based | 可解释的推荐 | 定义元路径或元图比较繁琐 不同场景元路径不同 大规模数据下计算复杂度高 数据稀疏性问题容易导致路径质量、数量差 |
| propagation-based | 可解释的推荐 更充分的挖掘KG中的信息 |
聚合和更新部分需要仔细设计 大规模数据下计算复杂度高 |
常用技巧:
- Attention mechanism on relation embedding
- Defining meta-path/meta-graph
- Attention mechanism on path embedding
- Reinforcement learning in User-Item KG
- Extracting edge weight
基于Trans系列的KGE方法:
- TransE 简单有效,但不适用于处理多对多的关系
- TransH 可处理多对多的关系
- TransR 实体具有不同方面, 而不同的关系侧重于不同的方面
- TransD 映射关系应该由实体和关系共同决定
数据集
在实际应用中,通常从大数据集中选取一个子集,过滤掉记录较少的user和item,以获得更高质量的数据。
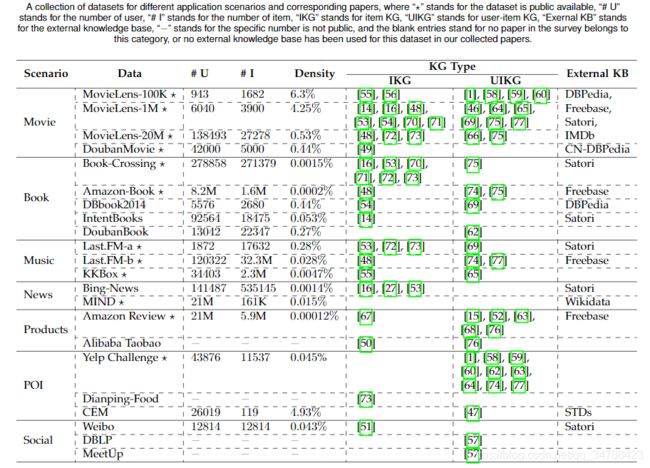
未来研究方向
- 动态推荐 利用动态图网络捕获user动态偏好
- 多任务学习 联合训练KG补全模块和推荐模块
- 跨域推荐 通过迁移学习技术以及在图中加入不同类型的user和item侧信息来提高跨域推荐的性能
- 知识增强的语言表示 将外部知识集成到语言表示模型中,使知识表示和文本表示相互细化。
注意: 该论文提及的相关方法将在后续文章中详细介绍,感兴趣的读者可以持续关注。