Linux基础
笔记生成于学习苏丙榅(“爱编程的大丙”)的《Linux 教程》过程。https://www.subingwen.cn/linux/
比较熟悉的知识点没有记录
Linux教程
第一章Linux基础
一、初识Linux操作系统
1.Linux 介绍
1.1Linux的诞生
1991 年,GNU 计划已经开发出了许多工具软件,最受期盼的 GNU C 编译器已经出现,GNU 的操作系统核心 HURD 一直处于实验阶段 (GNU 工程从 1984 年起就在做这件事),没有任何可用性,实质上也没能开发出完整的 GNU 操作系统。
也是这一年,Linux 诞生了,Linux 是 UNIX 操作系统的一个克隆系统, 但是Linux是开源的。 那时候它只是一个系统内核,没有与之配套的应用软件,这时候 Linux 和 GNU 一拍即合,就有了我们现在使用的操作系统,GNU 奠定了 Linux 用户基础和开发环境。
1、Linux 时间线
- 1991 年初,林纳斯・托瓦兹开始在一台 386sx 兼容微机上学习 minix 操作系统。
- 1991 年 4 月,林纳斯・托瓦兹开始酝酿并着手编制自己的操作系统。
- 1991 年 4 月 13 日在 comp.os.minix 上发布说自己已经成功地将 bash 移植到了 minix 上,而且已经爱不释手、不能离开这个 shell 软件了。
- 1991 年的 10 月 5 日,林纳斯・托瓦兹在 comp.os.minix 新闻组上发布消息,正式向外宣布 Linux 内核的诞生
- 1992 年 Linux 与其他 GNU 软件结合,完全自由的操作系统正式诞生。该操作系统往往被称为 “GNU/Linux”
- 1993 年,大约有 100 余名程序员参与了 Linux 内核代码编写 / 修改工作,其中核心组由 5 人组成,此时 Linux 0.99 的代码大约有十万行,用户大约有 10 万左右。
1994 年 3 月,Linux1.0 发布,代码量 17 万行,当时是按照完全自由免费的协议发布,随后正式采用 GPL 协议(GNU 通用公共授权书(GNU GPL, GNU General Public License))。
2、Linux的主要特性
-
Linux 是一个基于文件的操作系统
操作系统需要和硬件进行交互,对应 Linux 来说这些硬件都是文件,比如:操作系统会将 硬盘 , 鼠标 , 键盘 , 显示屏等抽象成一个设备文件来进行管理。
-
Linux 操作系统是一种自由软件,是免费的,并且公开源代码。
-
可以同时登陆多个用户,并且每个用户可以同时运行多个应用程序。
-
提供了友好的图形用户界面,操作简单, 易于快速上手。
-
支持多平台(这里指的是基于不同 CPU 架构的平台,比如国产 Linux 使用的龙芯等)。
1.2 一些名词
-
GNU:Gnu’s Not Unix. 可以理解成一种口号,最早由 Richard Stallman 呼吁并倡导的,号召软件自由。
-
GPL:General Public License. GNU 通用公共许可证,GPL 授予程序的接受方下述的权利,即 GPL 所倡导的 “自由”:
-
可以以任何目的运行所购买的程序;
-
在得到程序代码的前提下,可以以学习为目的,对源程序进行修改;
-
可以对复制件进行再发行;
-
对所购买的程序进行改进,并进行公开发布。
-
-
LGPL(GNU Lesser General Public License): LGPL 是 GPL 的一个为主要为类库使用设计的开源协议。
-
LGPL 允许商业软件通过类库引用 (link) 方式使用 LGPL 类库而不需要开源商业软件的代码。
-
采用 LGPL 协议的开源代码可以被商业软件作为类库引用并发布和销售。
-
-
BSD开源协议: BSD 开源协议是一个给于使用者很大自由的协议。基本上使用者可以” 为所欲为”,以 BSD 协议代码为基础做二次开发自己的产品时,需要满足三个条件:
-
如果再发布的产品中包含源代码,则在源代码中必须带有原来代码中的 BSD 协议。
-
不可以用开源代码的作者 / 机构名字和原来产品的名字做市场推广。
-
BSD 代码鼓励代码共享,但需要尊重代码作者的著作权。
-
-
FSF:自由软件基本会,给 GNU 提供资金支付的,毕竟没钱难成事啊。
-
自由软件:GNU 项目下的所有软件都基于 GPL 许可证(非 GNU 项目也可使用 GPL),都是自由软件。
-
开源软件:是美国 Open Source Initiative 协会定义,软件开放源代码。
-
POSIX:(Portable Operating System Interface for Computing Systems)是由 IEEE 和 ISO/IEC 开发的一套标准。POSIX 标准是对 UNIX 操作系统的经验和实践的总结,对操作系统调用的服务接口进行了标准化,保证所编制的应用程序在源代码一级可以在多种操作系统上进行移植。
1.3 Linux发行版
1、Linux操作系统发行版有两大类比较常见,一个是debian类系统,另一类是redhat。debian类的代表产品是ubuntu,它基于debian又进行了定制,用户界面更加友好。debian和ubuntu都是社区版,免费的。redhat操作系统是收费的,并不是用这个操作系统收费,而是红帽会给我们提供一系列的服务,如果要享受服务或者软件升级需要付费。CentOS使用redhat内核,完全免费的。


2、想要安装稳定版的 ubuntu, 应该如何选择版本呢?
官方每年会发布两个版本,每个版本的版本号由两部分组成: 主版本号 + 副版本号
- 主版本号为当年年份,长期支持版(一般支持3-5年)的年份为偶数,测试版年份为奇数
- 副版本号为月份,在 4 月份发布的为相对稳定版, 在 10 月份发布的为测试版
因此应当选择主版本号为偶数,副版本号为 04 的版本,进行安装使用。
3、因为Linux系统都遵循POSIX标准,所以我们编写的Linux程序可以在任意的发行版上运行。
4、Ubuntu系统不支持Oracle数据库,redhat类系统支持Oracle数据库。一般学习使用Ubuntu系统,公司项目使用CentOS进行软件开发。
1.4 Linux内核
1、Linux 系统从应用角度来看,分为内核空间和用户空间两个部分。
内核空间是 Linux 操作系统的主要部分,但是仅有内核的操作系统是不能完成用户任务的。丰富并且功能强大的应用程序包是一个操作系统成功的必要件。这个和武林秘籍一样,不仅得有招式还得有内功心法。
2、Linux 的内核主要由 5 个子系统组成:进程调度、内存管理、虚拟文件系统(主要处理I/O操作)、网络接口、进程间通信。
1、进程调度 SCHED
进程调度指的是系统对进程的多种状态之间转换的策略。Linux 下的进程调度有 3 种策略:SCHED_OTHER、SCHED_FIFO 和 SCHED_RR。SCHED_FIFO 和 SCHED_RR需要认为指定,如果不指定,则会按照SCHED_OTHER策略进行。
- SCHED_OTHER:分时调度策略(默认),是用于针对普通进程的时间片轮转调度策略。
- SCHED_FIFO:实时调度策略,是针对运行的实时性要求比较高、运行时间短的进程调度策略
- SCHED_RR:实时调度策略,是针对实时性要求比较高、运行时间比较长的进程调度策略。
2、内存管理 MMU
2、Linux目录MMU是CPU里的内存管理单元,每启动磁盘上的一个可执行程序,都会得到一个虚拟地址空间。MUU将虚拟内存地址和物理地址对应起来。
- 内存管理是多个进程间的内存共享策略。在 Linux 中,内存管理主要说的是虚拟内存。
- 虚拟内存可以让进程拥有比实际物理内存更大的内存,可以是实际内存的很多倍。
- 每个进程的虚拟内存有不同的地址空间,多个进程的虚拟内存不会冲突。
3、虚拟文件系统
虚拟文件系统将软件和硬件连接起来的中间缓冲层,通过这个缓冲层对磁盘进行管理,让数据有规律或按照某中格式存储或提取出来。
- 在 Linux 下支持多种文件系统,如 ext、ext2、minix、umsdos、msdos、vfat、ntfs、proc、smb、ncp、iso9660、sysv、hpfs、affs 等。
- 目前 Linux 下最常用的文件格式是 ext2 和 ext3。
4、网络接口
Linux 是在 Internet 飞速发展的时期成长起来的,所以 Linux 支持多种网络接口和协议。网络接口分为网络协议和驱动程序,网络协议是一种网络传输的通信标准,而网络驱动则是对硬件设备的驱动程序。Linux 支持的网络设备多种多样,几乎目前所有网络设备都有驱动程序。
5、进程间通信
Linux 操作系统支持多进程,进程之间需要进行数据的交流才能完成控制、协同工作等功能,Linux 的进程间通信是从 UNIX 系统继承过来的。Linux 下的进程间的通信方式主要有管道、信号(一般情况不建议使用)、消息队列、共享内存和套接字(分本地套接字和网络套接字)等方法。
2、Linux目录
与 Windows 下的文件组织结构不同,Linux 不使用磁盘分区符号来访问文件系统,而是将整个文件系统表示成树状的结构,Linux 系统每增加一个文件系统都会将其加入到这个树中。
操作系统文件结构的开始,只有一个单独的顶级目录结构,叫做根目录。所有一切都从“根”开始,用“/”代表,并且延伸到子目录。Linux 则通过 “挂接” 的方式把所有分区都放置在 “根” 下各个目录里。
2.1Linux目录结构
1、在 linux 中根目录的子目录结构相对是固定的 (名字固定), 不同的目录功能是也是固定的

-
bin: binary, 二进制文件目录,存储了可执行程序,今天要将的命令对应的可执行程序都在这个目录中
-
sbin: super binary, root 用户使用的一些二进制可执行程序
-
etc: 配置文件目录,系统的或者用户自己安装的应用程序的配置文件都存储在这个目录中
-
lib: library, 存储了一些动态库和静态库,给系统或者安装的软件使用
-
media: 挂载目录,挂载外部设备,比如:光驱,扫描仪
-
mnt: 临时挂载目录,比如我们可以将 U 盘临时挂载到这个目录下
-
proc: 内存使用的一个映射目录,给操作系统使用的
-
tmp: 临时目录,存放临时数据,重启电脑数据就被自动删除了
-
boot: 存储了开机相关的设置
-
home: 存储了普通用户的家目录,家目录名和用户名相同
-
root: root 用户的家目录
-
dev: device , 设备目录,Linux 中一切皆文件,所有的硬件会抽象成文件存储起来,比如:键盘, 鼠标
-
lost+found: 一般时候是空的,电脑异常关闭 / 崩溃时用来存储这些无家可归的文件,用于用户系统恢复
-
opt: 第三方软件的安装目录
-
var: 存储了系统使用的一些经常会发生变化的文件, 比如:日志文件
-
usr: unix system resource, 系统的资源目录
-
/usr/bin: 可执行的二进制应用程序
-
/usr/games: 游戏目录
-
/usr/include: 包含的标准头文件目录
-
/usr/local: 和 opt 目录作用相同,安装第三方软件
-
2.2 相对路径
相对路径:相对路径就是相对于当前文件的路径。在 Linux 中有两个表示路径的特殊符号:
-
./:代表目前所在的目录,也可以使用 . 表示。
-
…/:代表当前目录的上一层目录,也可以使用 … 表示。
优点:简洁,目录相对较短,书写方便
缺点:变更工作目录之后,使用相同的相对路径就找不到原来的文件了
2.3 绝对路径
绝对路径:从系统磁盘起始节点开始描述的路径。
优点:在操作系统的任意位置都可以通过绝对路径访问到对应的文件
缺点:字符串较长,书写起来比较麻烦,看起来也不够简洁
3、命令解析器
3.1命令提示行
命令whoami可以查看当前用户名
![]()
‘@’连接用户名和主机名:用户名@主机名。
‘:’后面是当前路径,‘~’表示用户的家目录,表示的绝对路径是:/home/用户名
'$'表示当前目录为普通用户,‘#’表示当前用户为root用户。
3.2 命令解析器工作原理
1、命令都是通过命令解析器解析完成并执行的,如果用户在终端输入是正确的内部指令,命令解析器就执行这个命令,如果不是正确的指令,则提示命令无法解析。
2、命令解析器是一个后台进程,名字叫做 bash 通常我们更习惯将其称之为 shell (即: sh)。在 Unix 操作系统诞生之后一个叫伯恩 (Bourne) 的人为其编写了命令解析器取名为 shell, Linux 操作系统诞生之后伯恩再次改写了 shell (sh), 将其称之为 bash (Bourne Again SHell), bash 就是 sh 的增强版本。
3、在 Linux 操作系统中默认使用的命令解析器是 bash, 当然也同样支持使用 sh。当用户打开一个终端窗口,并输入相关指令, 按回车键, 这时候命令解析器就开始工作了。
4、which命令可以查看当前指令的可执行程序位置
![]()
5、工作原理:
-
在 Linux 中有一个叫做 PATH 的环境变量,里边存储了一些系统目录 (windows也有, 叫 Path)
-
命令解析器需要依次搜索 PATH 中的各个目录,检查这些目录中是否有用户输入的指令
-
如果找到了,执行该目录下的可执行程序,用户输入的命令就被执行完毕了
-
如果没有找到,继续搜索其他目录,最后还是没有找到,会提示命令找不到,因此无法被执行
-
3.3 命令行快捷键
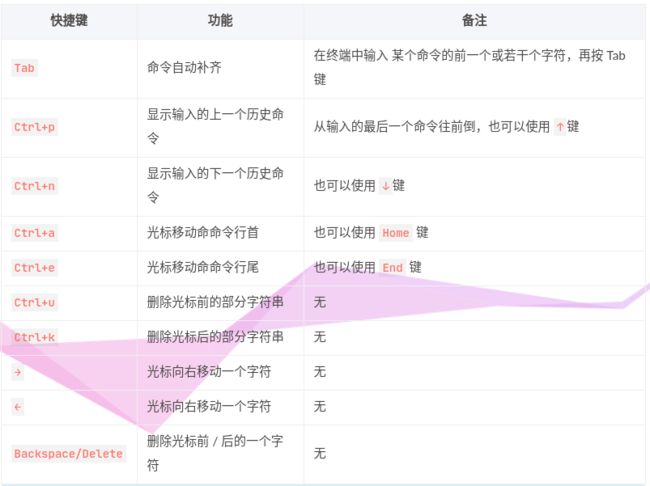
由于很多shell命令的开头字母是相同的, 在这种情况下, 按一次Tab是不会自动补齐的,我们可以连续按两次Tab键,在当前终端中就可以显示出所有匹配成功的shell命令。
如果使用cd指令,按一次Tab键就已经补齐了路径,那再按两次Tab键就能把那个路径下的所有文件显示出来
二、文件管理命令
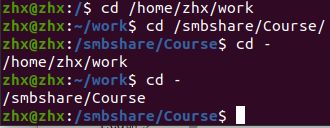
1.cd命令
cd:工作目录的切换
如果我们要频繁的在两个路径之间切换,也有相关的快捷操作,尤其是对于比较长的路径,可以说这简直是一个福利:
2.ls命令
ls 就是 list, 打印指定的文件信息
2.1 -l显示文件详细信息
给 ls 添加 -l 参数(就是 list 的意思)我们就可以看到文件的详细信息了,里边的信息量还是非常大的,其中包括: 文件类型 , 文件所有者对文件的操作权限 , 文件所属组用户对文件的操作权限 , 其他人对文件的操作权限 , 硬链接计数 , 文件所有者 , 文件所属组 , 文件大小(如果文件是目录,那仅代表目录所占磁盘空间大小,不包含目录内部文件大小) , 文件的修改日期 , 文件名。
(文件类型)(所有者权限)(所属组权限)(其他人权限) 硬链接计数 所有者 所属组 文件大小 文件修改日期 文件名字
在查看文件详细信息的时候,还有一种简单的写法,可以使用 ll 命令:
-
有些版本的 Linux 中 ll 等价于 ls -l;
-
有些版本的 Linux 中 ll 等价于 ls -laF;
2.1.1文件类型
在 Linux 操作系统中,一共有 7 中文件类型,这 7 中类型是根据文件属性进行划分的,而不是根据文件后缀划分的。
- -: 普通的文件,在 Linux 终端中没有执行权限的为白色,压缩包为红色,可执行程序为绿色字体
- d: 目录 (directory), 在 Linux 终端中为蓝色字体,如果目录的所有权限都是开放的,有绿色的背景色
- l: 软链接文件 (link), 相当于 windows 中的快捷方式,在 Linux 终端中为淡蓝色 (青色) 字体
- c: 字符设备 (char), 在 Linux 终端中为黄色字体
- b: 块设备 (block), 在 Linux 终端中为黄色字体
- p: 管道文件 (pipe), 在 Linux 终端中为棕黄色字体
- s: 本地套接字文件 (socket), 在 Linux 终端中为粉色字体
2.1.2用户类型
在 Linux 中有三大类用户: 文件所有者 , 文件所属组用户 , 其他人 , 我们可以对同一个文件给这三种人设置不同的操作权限,用于限制用户对文件的访问。
-
文件所有者
- Linux 中的所有的文件都有一个所有者,就是文件的主人
-
文件所属组
-
文件的主人属于哪个组,这个文件默认也就属于哪个组
-
用户组中可以有多个用户,这些组中的其他用户和所有者的权限可以是不一样的
-
-
其他人
-
这个用户既不是文件所有者也不是文件所属组中的用户,就称之为其他人
-
其他人对文件也可以拥有某些权限
-
2.1.3文件权限
Linux 中不同的用户可以对文件拥有不同的操作权限,权限一共有四种: 读权限 , 写权限 , 执行权限 , 无权限。
- 读权限:使用 r 表示,即: read
- 写权限:使用 w 表示,即: write
- 执行权限:使用 x 表示,即: excute
- 没有任何权限:使用 - 表示
2.1.4硬链接计数(文件别名数)
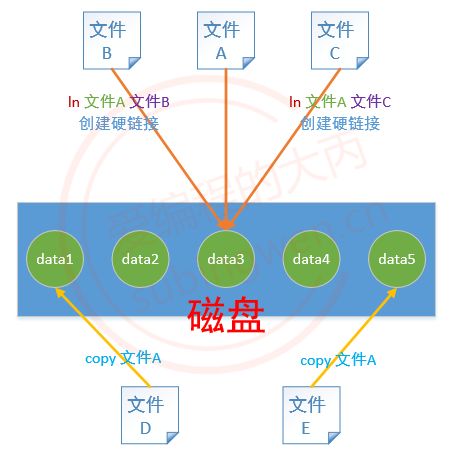
硬链接计数是一个整数,如果这个数为 N (N>=1),就说明在一个或者多个目录下一共有 N 个文件,但是这 N 个文件并不占用多块磁盘空间,他们使用的是同一块,如果通过其中一个文件修改了磁盘数据,那么其他文件中的内容也就变了。每当我们给给磁盘文件创建一个硬链接(使用 ln),磁盘上就会出现一个新的文件名,硬链接计数加 1,但是这新文件并不占用任何的磁盘空间,文件名还是映射到原来的磁盘地址上。
创建硬链接只是多了一个新的文件名, 拷贝文件不仅多了新的文件名在磁盘上数据也进行了拷贝
2.2.5 其他属性
- 文件大小 —> 单位是字节
- 如果文件是目录显示为 4096, 这是目录自身大小,不包括目录中的文件大小
- 文件日期:显示的是文件的修改日期,只要文件被更新,日期也会随之变化
- 文件名:文件自己的名字(没啥可解释的)
- 如果文件类型是软连接会这样显示: link -> /root/file/test, 后边的路径表示快捷方式链接的是哪个磁盘文件
2.2 -F显示目录后缀
在查看文件信息的时候,处理通过文件类型区分该文件是不是一个目录之外,还可以通过一个参数 -F 在目录名后边显示一个 /, 这样就可以直接区分出来了

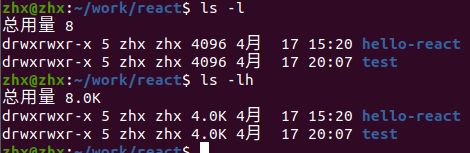
2.3 -h单位显示
在查看文件大小的时候,如果文件比较大对应的数组自然也就很大,我们还需要基于字节进行相关的换算,不能直观得到我们想要的结果,如果数学不好,我们可以使用一个参数 -h (human)(就是命令说人话)。
3.创建和删除目录
-
创建目录
-
创建单个目录 :
mkdir 新目录的名字 -
一次性创建多层目录:
mkdir parent/child/baby1/baby2 -p
-
-
删除目录
- rmdir: 只能删除空目录,有点 low,不好用
- rm: 可以删除文件也可以删除目录,如果删除的的是目录,需要加参数 -r, 意思是递归 (recursion)
rm 命令还有另外两个经常使用的参数:
- -i: 删除的时候给提示
- -f: 强制删除文件,没有提示直接删除并且不能恢复,慎用
如果同时写了i和f,那么谁写在后面谁生效。
4.cp命令
-
拷贝文件 => 文件不存在得到新文件, 文件存在就覆盖
-
拷贝目录 ==> 目录不存在得到新目录, 该目录被拷贝到存在的目录中
cp 目录A 目录B -r
5.mv命令
-
文件的移动 :
#其中A可以是文件也可以是目录, B必须是目录而且必须是存在的 $ mv A B -
文件改名
#其中A可以是文件也可以是目录,并且是存在的, B原来是不存在的 $ mv A B -
文件覆盖
# 其中A是文件(非目录)并且是存在的, B也是一个文件(非目录)并且也存在 # A文件中的内容覆盖B文件中的内容, A文件被删除, 只剩下B文件 $ mv A B
6.查看文件内容
6.1vim
6.2cat
该命令可以将文件内容显示到终端,由于终端是有缓存的,因此能显示的字节数也是受限制的。 如果文件太大数据就不能完全显示出来了,因此该命令适合查看比较小的文件内容。
$ cat 文件名
6.3more
该命令比 cat 要高级一点,我们可以以翻屏的方式查看文件中的内容,使用方式如下:
$ more 文件名
# 快捷键
- 回车: 显示下一行
- 空格: 向下滚动一屏
- b: 返回上一屏
- q: 退出more
6.4less
该命令和 more 命令差不多,我们可以以翻屏的方式查看文件中的内容,使用方式如下:
$ less 文件名
# 快捷键
- b: 向上翻页
- 空格: 向后翻页
- 回车: 显示下一行
- 上下键: 上下滚动
- q:退出
6.5head
使用该命令可以查看文件头部的若干行信息,使用方式如下:
# 默认显示文件的前10行
$ head 文件名
# 指定显示头部的前多少行
$ head -行数 文件名
6.6tail
使用该命令可以查看文件尾部的若干行信息,使用方式如下:
# 默认显示文件的后10行
$ tail 文件名
# 指定显示尾部的最后多少行
$ tail -行数 文件名
7.链接的创建
链接分两种类型: 软连接和硬链接。软连接相当于 windows 中的快捷方式,硬链接前边也已经介绍过了文件并不会进行拷贝,只是多出一个新的文件名并且硬链接计数会加 1。
-
软连接
# 语法: ln -s 源文件路径 软链接文件的名字(可以带路径) # 查看目录文件 [root@VM-8-14-centos ~/luffy]# ll total 8 drwxr-xr-x 3 root root 4096 Jan 25 17:27 get -rw-r--r-- 1 root root 37 Jan 25 17:26 onepiece.txt # 给 onepiece.txt 创建软连接, 放到子目录 get 中 [root@VM-8-14-centos ~/luffy]# ln -s /root/luffy/onepiece.txt get/link.lnk [root@VM-8-14-centos ~/luffy]# ll get total 4 lrwxrwxrwx 1 root root 24 Jan 25 17:27 link.lnk -> /root/luffy/onepiece.txt drwxr-xr-x 2 root root 4096 Jan 24 21:37 onepiece在创建软链接的时候, 命令中的 源文件路径建议使用绝对路径,这样才能保证创建出的软链接文件在任意目录中移动都可以访问到链接的那个源文件。
-
硬链接
# 语法: ln 源文件 硬链接文件的名字(可以带路径) # 创建硬链接文件, 放到子目录中 [root@VM-8-14-centos ~/luffy]# ln onepiece.txt get/link.txt # 查看链接文件和硬链接计数, 从 1 --> 2 [root@VM-8-14-centos ~/luffy]# ll get total 8 lrwxrwxrwx 1 root root 24 Jan 25 17:27 link.lnk -> /root/luffy/onepiece.txt -rw-r--r-- 2 root root 37 Jan 25 17:26 link.txt drwxr-xr-x 2 root root 4096 Jan 24 21:37 onepiece硬链接和软链接不同,它是通话文件名直接找对应的硬盘地址,而不是基于路径,因此 源文件使用相对路径即可,无需为其制定绝对路径。
目录是不允许创建硬链接的。
8.文件属性
文件属性相关的命令主要是修改用户对文件的操作权限,文件所有者,文件所属组的相关信息。
8.1 修改文件文件权限
文件权限是针对文件所有者 , 文件所属组用户 , 其他人这三类人而言的,对应的操作指令是 chmod。设置方式也有两种,分别为文字设定法和数字设定法。
文字设定法是通过一些关键字 r, w, x, - 来描述用户对文件的操作权限。
数字设定法是通过一些数字 0, 1, 2, 4, 5, 6, 7 来描述用户对文件的操作权限。
-
文字设定法
#chmod # 语法格式: chmod who [+|-|=] mod 文件名 - who: - u: user -> 文件所有者 - g: group -> 文件所属组用户 - o: other -> 其他 - a: all, 以上是三类人 u+g+o - 对权限的操作: +: 添加权限 -: 去除权限 =: 权限的覆盖 - mod: 权限 r: read, 读 w: write, 写 x: execute, 执行 -: 没有权限 # 将文件所有者权限设置为读和执行, 也就是权限覆盖 robin@OS:~/Linux$ chmod u=rx b.txt robin@OS:~/Linux$ ll b.txt -r-xrw-r-- 2 robin robin 2929 Apr 14 18:53 b.txt* # 给其他人添加写和执行权限 robin@OS:~/Linux$ chmod o+wx b.txt robin@OS:~/Linux$ ll b.txt -r-xrw-rwx 2 robin robin 2929 Apr 14 18:53 b.txt* # 给文件所属组用户去掉读和执行权限 robin@OS:~/Linux$ chmod g-rx b.txt robin@OS:~/Linux$ ll b.txt -r-x-w-rwx 2 robin robin 2929 Apr 14 18:53 b.txt* # 将文件所有者,文件所属组用户,其他人权限设置为读+写+执行 robin@OS:~/Linux$ chmod a=rwx b.txt robin@OS:~/Linux$ ll b.txt -rwxrwxrwx 2 robin robin 2929 Apr 14 18:53 b.txt* -
数字设定法
# 语法格式: chmod [+|-|=] mod 文件名 - 对权限的操作: +: 添加权限 -: 去除权限 =: 权限的覆盖, 等号可以不写 - mod: 权限描述, 所有权限都放开是 7 - 4: read, r - 2: write, w - 1: execute , x - 0: 没有权限 # 分解: chmod 0567 a.txt 0 5 6 7 八进制 文件所有者 文件所属组用户 其他人 r + x r + w r+w+x ######################### 举例 ######################### # 查看文件 c.txt 的权限 robin@OS:~/Linux$ ll c.txt -rwxrwxrwx 2 robin robin 2929 Apr 14 18:53 c.txt* # 文件所有者去掉执行权限, 所属组用户去掉写权限, 其他人去掉读+写权限 robin@OS:~/Linux$ chmod -123 c.txt robin@OS:~/Linux$ ll c.txt -rw-r-xr-- 2 robin robin 2929 Apr 14 18:53 c.txt* # 文件所有者添加执行权限, 所属组用户和其他人权限不变 robin@OS:~/Linux$ chmod +100 c.txt robin@OS:~/Linux$ ll c.txt -rwxr-xr-- 2 robin robin 2929 Apr 14 18:53 c.txt* # 将文件所有者,文件所属组用户,其他人权限设置为读+写, 没有执行权限 robin@OS:~/Linux$ chmod 666 c.txt robin@OS:~/Linux$ ll c.txt -rw-rw-rw- 2 robin robin 2929 Apr 14 18:53 c.txt
8.2 修改文件所有者
默认情况下,文件是通过哪个用户创建出来的,就属于哪个用户,这个用户属于哪个组,文件就属于哪个组。如果有特殊需求,可以修改文件所有者,对应的操作命令是 chown。因为修改文件所有者就跨用户操作,普通用户没有这个权限,需要借助管理员权限才能完成该操作。
普通用户借助管理员权限执行某些shell命令, 需要在命令前加关键字sudo, 但是普通用户默认是没有使用 sudo的资格的, 需要修改 /etc/sudoers 文件 。
8.2.1普通用户添加sudo权限
-
设置root用户密码
ubuntu 默认的 root 用户是没有固定密码的,它的密码是随机产生并且动态改变的,即每次开机都有一个新的 root 密码,如果想查看 root 密码,那么直接设置新的 root 密码即可。
sudo passwd root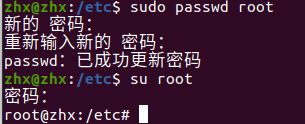
-
添加新用户
# 添加新用户 sanji [root@VM-8-14-centos ~]# adduser sanji # 给新用户 sanji 设置一个密码 [root@VM-8-14-centos ~]# passwd sanji Changing password for user sanji. New password: Retype new password: passwd: all authentication tokens updated successfully. # 切换到 sanji 用户 [root@VM-8-14-centos ~]# su - sanji # 让 sanji 用户执行一个只有管理员才有权限执行的操作, 因此需要在命令前加 sudo [sanji@VM-8-14-centos ~]$ sudo updatedb We trust you have received the usual lecture from the local System Administrator. It usually boils down to these three things: #1) Respect the privacy of others. #2) Think before you type. #3) With great power comes great responsibility. [sudo] password for sanji: sanji is not in the sudoers file. This incident will be reported.最后命令还是没能够执行,原因是没有权限,最后提示告诉我们 sanji is not in the sudoers file, 因此我们只需要将用户 sanji 添加到这个文件中就可以了,说干就干。
-
添加 sudo 权限
这个叫做 sudoers 的文件位于 /etc 目录下,我们先切换到 /etc 目录,然后查看一下这个文件的详细信息
$ cd /etc/ $ ll sudoers -r-------- 1 root root 4382 Jan 21 23:16 sudoers我们惊奇的发现这个文件的所有者 root 对它也只有读权限,默认是不能修改的,作为 root 以外的其他用户对它没有任何的操作权限。
解决方案:
-
先切换到 root 用户
-
在 root 用户下修改这个文件属性,给其添加写权限
-
修改文件内容,把普通用户 sanji 添加进去,保存退出
-
将文件权限修改为原来的 400 (r--------)
-
切换到用户 sanji, 这时候就可以使用 sudo 了,权限添加成功
# 1. 切换到root用户 $ su root Password: # 输入root用户的密码 # 2. 修改文件权限, 暴力一点没有关系, 反正还需要改回去, 直接 777 就行 $ chmod 777 sudoers # 3. 使用 vim 打开这个文件 $ vim sudoers # 4. 在文件中找到这一行, 在文件偏尾部的位置 root ALL=(ALL) ALL # 5. 照葫芦画瓢, 在下边新添加一行内容如下: root ALL=(ALL) ALL # 原来的内容 sanji ALL=(ALL) ALL # 新添加的行, 将用户名指定为 sanji 即可 # 6. 保存退出 (先按esc, 然后输入 :wq) # 7. 将文件改回原来的权限 $ chmod 400 sudoers恭喜,权限设置成功,你的普通的用户可以使用 sudo 执行只有管理员才能操作的命令啦。
-
8.2.2 修改文件所有者
# 语法1-只修改所有者:
$ sudo chown 新的所有者 文件名
# 语法2-同时修改所有者和所属组:
$ sudo chown 新的所有者:新的组名 文件名
# 查看文件所有者:b.txt 属于 robin 用户
robin@OS:~/Linux$ ll b.txt
-rw-rw-rw- 2 robin robin 2929 Apr 14 18:53 b.txt
# 将 b.txt 的所有者修改为 luffy
robin@OS:~/Linux$ sudo chown luffy b.txt
[sudo] password for robin:
robin@OS:~/Linux$ ll b.txt
-rw-rw-rw- 2 luffy robin 2929 Apr 14 18:53 b.txt
# 修改文件所有者和文件所属组
# 查看文件所有者和所属组
robin@OS:~/Linux$ ll b.txt
-rw-rw-rw- 2 luffy robin 2929 Apr 14 18:53 b.txt
# 同时修改文件所有者和文件所属组
robin@OS:~/Linux$ sudo chown robin:luffy b.txt
robin@OS:~/Linux$ ll b.txt
-rw-rw-rw- 2 robin luffy 2929 Apr 14 18:53 b.txt
8.3 修改文件所属组
普通用户没有修改文件所属组的权限,如果需要修改需要借助管理员权限才能完成,需要使用的命令是 chgrp。当然了这个属性的修改也可以使用 chown 命令来完成。
# 只修改文件所属的组, 普通用户没有这个权限, 借助管理员的权限
# 语法: sudo chgrp 新的组 文件名
# 查看文件所属组信息
robin@OS:~/Linux$ ll b.txt
-rw-rw-rw- 2 robin luffy 2929 Apr 14 18:53 b.txt
# 修改文件所属的组
robin@OS:~/Linux$ sudo chgrp robin b.txt
robin@OS:~/Linux$ ll b.txt
-rw-rw-rw- 2 robin robin 2929 Apr 14 18:53 b.txt
9.其他命令
9.1 tree命令 以树状结构查看目录
该命令有一个常用参数 -L, 即 (layer) 显示目录的层数。
# 语法格式
$ tree [-L n] # 查看当前目录的结构, n为显示的目录层数
$ tree 目录名 [-L n] # 查看指定目录的结构, n为显示的目录层数
# 只显示1层
[root@VM-8-14-centos ~]# tree -L 1
.
|-- ace
|-- file
|-- ipc.tar.gz
|-- link.lnk -> /root/luffy/onepiece.txt
`-- luffy
# 显示2层目录
[root@VM-8-14-centos ~]# tree -L 2
.
|-- ace
| `-- brother
|-- file
| |-- dir
| |-- haha.tar.gz
| |-- hello
| |-- link -> /root/file/test
| |-- pipe-2
| |-- subdir
| `-- test
|-- ipc.tar.gz
|-- link.lnk -> /root/luffy/onepiece.txt
`-- luffy
|-- get
`-- onepiece.txt
9.2 touch命令
使用 touch 命令可以创建一个新的空文件 , 如果指定的文件是已存在的,只会更新文件的修改日期,对内容没有任何影响。
9.3 which命令
which 命令可以查看要执行的命令所在的实际路径,命令解析器工作的时候也会搜索这个目录。需要注意的是该命令只能查看非内建的shell指令所在的实际路径, 有些命令是直接写到内核中的, 无法查看。
我们使用的大部分 shell 命令都是放在系统的 /bin 或者 /usr/bin 目录下:
9.4 重定向命令
关于重定向使用最多的是就是输出重定向 , 顾名思义就是修改输出的数据的位置,通过重定向操作我们可以非常方便的进行文件的复制,或者文件内容的追加。输出重定向使用的不是某个关键字而是符号 > 或者 >>。
-
‘>’:将文件内容写入到指定文件中,如果文件中已有数据,则会使用新数据覆盖原数据
-
‘>>’:将输出的内容追加到指定的文件尾部
# 输出的重定向举例: printf默认是要将数据打印到终端, 可以修改默认的输出位置 => 重定向到某个文件中
# 关键字 >
# 执行一个shell指令, 获得一个输出, 这个输出默认显示到终端, 如果要将其保存到文件中, 就可以使用重定向
# 如果当前目录下test.txt不存在, 会被创建, 如果存在, 内容被覆盖
$ date > test.txt
# 日期信息被写入到文件 test.txt中
robin@OS:~/Linux$ cat test.txt
Wed Apr 15 09:37:52 CST 2020
# 如果不希望文件被覆盖, 而是追加, 需要使用 >>
in@OS:~/Linux$ date >> test.txt
# 日期信息被追加到 test.txt中
robin@OS:~/Linux$ cat test.txt
Wed Apr 15 09:37:52 CST 2020
Wed Apr 15 09:38:44 CST 2020
# 继续追加信息
robin@OS:~/Linux$ date >> test.txt
robin@OS:~/Linux$ cat test.txt
Wed Apr 15 09:37:52 CST 2020
Wed Apr 15 09:38:44 CST 2020
Wed Apr 15 09:39:03 CST 2020
三、用户管理命令
1.切换用户
用户切换需要使用 su 或者 su -。使用 su 只切换用户,当前的工作目录不会变化,但是使用 su - 不仅会切换用户也会切换工作目录,工作目录切换为当前用户的家目录。
从用户 A 切换到用户 B, 如果还想再切换回用户 A,可以直接使用 exit。
Centos可以直接登陆root用户,Ubuntu不能用root用户登陆,只能先登陆普通用户,再从终端切换到root用户
# 只切换用户, 工作目录不变
$ su 用户名
# 举例:
robin@OS:~/Linux$ su luffy
Password: # 需要输入luffy用户的密码
luffy@OS:/home/robin/Linux$ # 工作目录不变
# 切换用户和工作目录, 会自动跳转到当前用户的家目录中
$ su - 用户名
# 举例:
robin@OS:~/Linux$ su - luffy
Password: # 需要输入luffy用户的密码
luffy@OS:~$ pwd
/home/luffy # 工作目录变成了luffy的家目录
# 回到原来的用户
$ exit
2.添加删除用户
作为一个普通用户是没有给系统添加新用户这个权限的,如果想要添加新用户可以先切换到 root 用户,或者基于普通用户为其添加管理员权限来完成新用户的添加。添加新用户需要使用 adduser/useradd 命令来完成。建议使用adduser,在Ubuntu和Centos上都是一样操作。
普通用户没有添加 / 删除用户的权限,需要授权,查看8.2.1普通用户添加sudo权限。
2.1 添加新用户
# 添加用户
# sudo -> 使用管理员权限执行这个命令
$ sudo adduser 用户名
# centos
$ sudo useradd 用户名
# ubuntu
$ sudo useradd -m -s /bin/bash 用户名
#-m表示如果用户的home目录是不存在的就会自动创建home目录
#-s指定用户使用的命令解析器
#-t设置密码,不建议使用,因为会暴露密码
# 在使用 adduser 添加新用户的时候,有的Linux版本执行完命令就结束了,有的版本会提示设置密码等用户信息
robin@OS:~/Linux$ sudo adduser lisi
Adding user `lisi' ...
Adding new group `lisi' (1004) ...
Adding new user `lisi' (1004) with group `lisi' ...
Creating home directory `/home/lisi' ...
Copying files from `/etc/skel' ...
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
Changing the user information for lisi
Enter the new value, or press ENTER for the default
Full Name []:
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n] y
当新用户添加完毕之后,我们可以切换到新添加的用户下,用来检测是否真的添加成功了,另外我们也可以使用其他方式来检验,首先在 /home 目录中会出现一个和用户名同名的目录,这就是新创建的用户的家目录,另外我们还可以查看 /etc/passwd 文件,里边记录着新添加的用户的更加详细的信息:
zhx@zhx:/etc$ cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
//文件格式:
用户名:加密之后的密码:用户ID:所属组ID:用户名:用户家目录:用户默认使用命令解析器
2.2 删除用户
删除用户并不是将 /home 下的用户家目录删除就完事儿了,我们需要使用 userdle 命令才能删除用户在系统中的用户 ID 和所属组 ID 等相关信息,但是需要注意的是在某些Linux版本中用户虽然被删除了, 但是它的家目录却没有被删除,需要我们手动将其删除。
# 删除用户, 添加参数 -r 就可以一并删除用户的家目录了
$ sudo userdel 用户名 -r
# 删除用户 lisi
$ sudo userdel lisi -r
# 使用deluser不能添加参数-r, 家目录不能被删除, 需要使用 rm 命令删除用户的家目录, 比如:
$ sudo rm /home/用户名 -r
由于 Linux 的版本很多,删除用户对应的操作指令不是唯一的,经测试在 CentOS 版本只支持 userdel命令 , 在 Ubuntu中既支持 userdel 也支持 deluser命令。
3.添加删除用户组
默认情况下,只要创建新用户就会得到一个同名的用户组,并且这个用户属于这个组。一般情况下不需要创建新的用户组,如果有需求可以使用 groupadd 添加用户组,使用 groupdel 删除用户组。
由于普通用户没有添加删除用户组权限,因此需要在管理员(root)用户下操作,或者在普通用户下借助管理员权限完成该操作。
# 基于普通用户创建新的用户组
$ sudo groupadd 组名
# 基于普通用户删除已经存在的用户组
$ sudo groupdel 组名
如果验证用户组是否添加成功了,可以查看 /etc/group 文件,里边有用户组相关的信息:
zhx@zhx:/etc$ cat /etc/group
root:x:0:
daemon:x:1:
bin:x:2:
sys:x:3:
adm:x:4:syslog,zhx
tty:x:5:syslog
#文件格式:
用户名:加密之后的密码:用户组ID
在 Ubuntu 中添加删除用户组可以使用 addgroup/groupadd 和 delgroup/groupdel
在 CentOS 中添加和删除用户只能使用 groupadd 和 groupdel
我们只需要通过 which 命令名 查看,就能知道该 Linux 版本是不是支持使用该命令了。
4.修改密码
Linux 中设置用户密码和修改用户密码的方式是一样的,修改用户密码又分几种情况: 修改当前用户密码 , 普通用户A修改其他普通用户密码 , 普通用户A修改root用户密码 , root用户修改普通用户密码。修改密码需要使用 passwd 命令。当创建了一个普通用户却没有提示指定密码,或者忘记了用户密码都可以通过该命令来实现自己重置密码的需求。
- 当前用户修改自己的密码,默认是有权限操作的
- 当前普通用户修改其他用户密码,默认没有权限,需要借助管理员权限才能完成操作
- 当前普通用户修改 root 用户密码,默认没有权限,需要借助管理员权限才能完成操作
- root 用户修改其他普通用户密码,默认有权限,可以直接修改
# passwd
# 修改当前用户
$ passwd
# 修改非当前用户密码
$ sudo passwd 用户名
# 修改root
$ sudo passwd root
四、压缩命令
基于 Linux 的常用压缩包操作,格式包含:tar.gz, .tgz, .tar.bz2, .zip, .rar, .tar.xz。
1.tar
在 Linux 操作系统中默认自带两个原始的压缩工具分别是 gzip 和 bzip2, 但是它们都有先天的缺陷,不能打包压缩文件, 每个文件都会生成一个单独的压缩包, 并且压缩之后不会保留原文件。
Linux 中自带一个打包工具,叫做 tar, 默认情况下该工具是不能进行压缩操作的,在这种情况下 tar 和 gzip, bzip2 就联姻了,各自发挥各自的优势,Linux 下最强大的打包压缩工具至此诞生。
我们在使用 tar 进行压缩和解压缩的时候,只需要指定相对用的参数,在其内部就会调用对应的压缩工具 gzip 或者 bzip2 完成指定的操作。
使用tar如果发生覆盖,不会给任何提示,会直接覆盖
1.1 压缩 (.tar.gz .tar.bz2 .tgz)
如果使用 tar 完成文件压缩,涉及的参数如下,在使用过程中参数没有先后顺序:
- c: 创建压缩文件
- z: 使用 gzip 的方式进行文件压缩
- j: 使用 bzip2 的方式进行文件压缩
- v: 压缩过程中显示压缩信息,可以省略不写
- f: 指定压缩包的名字
一般认为 .tgz 文件就等同于 .tar.gz 文件,因此它们的压缩方式是相同的。
# 语法:
$ tar 参数 生成的压缩包的名字 要压缩的文件(文件或者目录)
# 备注: 关于生成的压缩包的名字, 建议使用标准后缀, 方便识别:
- 压缩使用 gzip 方式, 标准后缀格式为: .tar.gz
- 压缩使用 bzip2 方式, 标准后缀格式为: .tar.bz2
举例:使用 gzip 的方式进行文件压缩
# 查看目录内容
[root@VM-8-14-centos ~/luffy]# ls
get onepiece.txt robin.txt
# 压缩目录中所有文件, 如果要压缩某几个文件, 直接指定文件名即可
[root@VM-8-14-centos ~/luffy]# tar zcvf all.tar.gz *
get/ # ....... 压缩信息
get/link.lnk # ....... 压缩信息
get/onepiece/ # ....... 压缩信息
get/onepiece/haha.txt
get/link.txt
onepiece.txt
robin.txt
# 查看目录文件, 多了一个压缩文件 all.tar.gz
[root@VM-8-14-centos ~/luffy]# ls
all.tar.gz get onepiece.txt robin.txt
举例:使用 bzip2 的方式进行文件压缩
# 查看目录内容
[root@VM-8-14-centos ~/luffy]# ls
all.tar.gz get onepiece.txt robin.txt
# 压缩目录中除 all.tar.gz 的文件和目录
[root@VM-8-14-centos ~/luffy]# tar jcvf part.tar.bz2 get onepiece.txt robin.txt
get/ # ....... 压缩信息
get/link.lnk # ....... 压缩信息
get/onepiece/ # ....... 压缩信息
get/onepiece/haha.txt
get/link.txt
onepiece.txt
robin.txt
# 查看目录信息, 多了一个压缩文件 part.tar.bz2
[root@VM-8-14-centos ~/luffy]# ls
all.tar.gz get onepiece.txt part.tar.bz2 robin.txt
1.2 解压缩 (.tar.gz .tar.bz2 .tgz)
如果使用 tar 进行文件的解压缩,涉及的参数如下,在使用过程中参数没有先后顺序:
- x: 释放压缩文件内容
- z: 使用 gzip 的方式进行文件压缩,压缩包后缀为.tar.gz
- j: 使用 bzip2 的方式进行文件压缩,压缩包后缀为.tar.bz2
- v: 解压缩过程中显示解压缩信息
- f: 指定压缩包的名字
使用以上参数是将压缩包解压到当前目录,如果需要解压到指定目录,需要指定参数 -C。 一般认为 .tgz 文件就等同于 .tar.gz 文件,解压缩方式是相同的。解压的语法格式如下:
# 语法1: 解压到当前目录中
$ tar 参数 压缩包名
# 语法2: 解压到指定目录中
$ tar 参数 压缩包名 -C 解压目录
举例:使用 gzip 的方式进行文件解压缩
# 查看目录文件信息
[root@VM-8-14-centos ~/luffy]# ls
all.tar.gz get onepiece.txt part.tar.bz2 robin.txt temp
# 将 all.tar.gz 压缩包解压缩到 temp 目录中
[root@VM-8-14-centos ~/luffy]# tar zxvf all.tar.gz -C temp
get/ # 解压缩文件信息
get/link.lnk # 解压缩文件信息
get/onepiece/ # 解压缩文件信息
get/onepiece/haha.txt # 解压缩文件信息
get/link.txt
onepiece.txt
robin.txt
# 查看temp目录内容, 都是从压缩包中释放出来的
[root@VM-8-14-centos ~/luffy]# ls temp/
get onepiece.txt robin.txt
举例:使用 bzip2 的方式进行文件解压缩
# 删除 temp 目录中的所有文件
[root@VM-8-14-centos ~/luffy]# rm temp/* -rf
# 查看 luffy 目录中的文件信息
[root@VM-8-14-centos ~/luffy]# ls
all.tar.gz get onepiece.txt part.tar.bz2 robin.txt temp
# 将 part.tar.bz2 中的文件加压缩到 temp 目录中
[root@VM-8-14-centos ~/luffy]# tar jxvf part.tar.bz2 -C temp
get/ # 解压缩文件信息
get/link.lnk # 解压缩文件信息
get/onepiece/ # 解压缩文件信息
get/onepiece/haha.txt # 解压缩文件信息
get/link.txt
onepiece.txt
robin.txt
# 查看 temp 目录中的文件信息
[root@VM-8-14-centos ~/luffy]# ls temp/
get onepiece.txt robin.txt
2. zip
zip 格式的压缩包在 Linux 中也是很常见的,在某些版本中需要安装才能使用
- Ubuntu
$ sudo apt install zip # 压缩
$ sudo apt install unzip # 解压缩
- CentOS
# 因为 centos 可以使用 root 用户登录, 基于 root 用户安装软件, 不需要加 sudo
$ sudo yum install zip # 压缩
$ sudo yum install unzip # 解压缩
2.1 压缩 (.zip)
使用 zip 压缩目录需要注意一点,必须要添加参数 -r, 这样才能将子目录中的文件一并压缩,如果要压缩的文件中没有目录,该参数就可以不写了。
另外使用 zip 压缩文件,会自动生成文件后缀.zip, 因此就不需要额外指定了。
# 语法: 后自动添加压缩包后缀 .zip, 如果要压缩目录, 需要添加参数 r
$ zip [-r] 压缩包名 要压缩的文件
# 查看目录文件信息
[root@VM-8-14-centos ~/luffy]# ls
get onepiece.txt robin.txt temp
# 压缩目录 get 和文件 onepiece.txt robin.txt 得到压缩包 all.zip(不需要指定后缀, 自动添加)
[root@VM-8-14-centos ~/luffy]# zip all onepiece.txt robin.txt get/ -r
adding: onepiece.txt (stored 0%)
adding: robin.txt (stored 0%)
adding: get/ (stored 0%)
adding: get/link.lnk (stored 0%) # 子目录中的文件也被压缩进去了
adding: get/onepiece/ (stored 0%) # 子目录中的文件也被压缩进去了
adding: get/onepiece/haha.txt (stored 0%) # 子目录中的文件也被压缩进去了
adding: get/link.txt (stored 0%) # 子目录中的文件也被压缩进去了
# 查看目录文件信息, 多了一个压缩包文件 all.zip
[root@VM-8-14-centos ~/luffy]# ls
all.zip get onepiece.txt robin.txt temp
2.2 解压缩 (.zip)
对应 zip 格式的文件解压缩,必须要使用 unzip 命令,和压缩的时候使用的命令是不一样的。如果压缩包中的文件要解压到指定目录需要指定参数 -d, 默认是解压缩到当前目录中。
# 语法1: 解压到当前目录中
$ unzip 压缩包名
# 语法: 解压到指定目录, 需要添加参数 -d
$ unzip 压缩包名 -d 解压目录
# 查看目录文件信息
[root@VM-8-14-centos ~/luffy]# ls
all.zip get onepiece.txt robin.txt temp
# 删除 temp 目录中的所有文件
[root@VM-8-14-centos ~/luffy]# rm temp/* -rf
# 将 all.zip 解压缩到 temp 目录中
[root@VM-8-14-centos ~/luffy]# unzip all.zip -d temp/
Archive: all.zip
extracting: temp/onepiece.txt # 释放压缩的子目录中的文件
extracting: temp/robin.txt # 释放压缩的子目录中的文件
creating: temp/get/
extracting: temp/get/link.lnk
creating: temp/get/onepiece/
extracting: temp/get/onepiece/haha.txt # 释放压缩的子目录中的文件
extracting: temp/get/link.txt
# 查看 temp 目录中的文件信息
[root@VM-8-14-centos ~/luffy]# ls temp/
get onepiece.txt robin.txt
3. rar
rar 这种压缩格式在 Linux 中并不常用,这是 Windows 常用的压缩格式,如果想要在 Linux 压缩和解压这种格式的文件需要额外安装对应的工具,不同版本的 Linux 安装方式也是不同的。
- Ubuntu
# 执行在线下载命令即可
$ sudo apt install rar
- CentOS
# 需要下载安装包, 官方地址: https://www.rarlab.com/download.htm
# 从下载页面找到 Linux 版本的下载链接并复制链接地址, 使用 wget 下载到本地
$ wget https://www.rarlab.com/rar/rarlinux-x64-6.0.0.tar.gz
# 将下载得到的 rarlinux-x64-6.0.0.tar.gz 压缩包解压缩, 得到解压目录 rar
$ tar zxvf rarlinux-x64-6.0.0.tar.gz
# 将得到的解压目录移动到 /opt 目录中 (因为/opt软件安装目录, 移动是为了方便管理, 不移动也没事儿)
# 该操作需要管理员权限, 我是使用 root 用户操作的
$ mv ./rar /opt
# 给 /opt/rar 目录中的可执行程序添加软连接, 方便命令解析器可以找到该压缩命令
$ ln -s /opt/rar/rar /usr/local/bin/rar
$ ln -s /opt/rar/unrar /usr/local/bin/unrar
该方法在任何版本的 Linux 系统中都适用
3.1 压缩 (.rar)
使用 rar 压缩过程中的注意事项和 zip 是一样的,如果压缩的是目录, 需要指定参 -r, 如果只压缩文件就不需要添加了。压缩过程中需要使用参数 a (archive), 压缩归档的意思。
rar 工具在生成压缩包的时候也会自动添加后缀,名字为.rar, 因此我们只需要指定压缩包的名字。
# 文件压缩, 需要使用参数 a, 压缩包名会自动添加后缀 .rar
# 如果压缩了目录, 需要加参数 -r
# 语法:
$ rar a 压缩包名 要压缩的文件 [-r]
# 举例
# 查看目录文件信息
[root@VM-8-14-centos ~/luffy]# ls
get onepiece.txt robin.txt temp
# 压缩文件 onepiece.txt, robin.txt 和目录 get/ 到要是文件 all.rar 中
[root@VM-8-14-centos ~/luffy]# rar a all onepiece.txt get/ robin.txt -r
RAR 6.00 Copyright (c) 1993-2020 Alexander Roshal 1 Dec 2020
Trial version Type 'rar -?' for help
Evaluation copy. Please register.
Creating archive all.rar
Adding onepiece.txt OK
Adding get/link.lnk OK # 子目录中的文件也被压缩了
Adding get/onepiece/haha.txt OK # 子目录中的文件也被压缩了
Adding get/link.txt OK # 子目录中的文件也被压缩了
Adding robin.txt OK
Adding get/onepiece OK
Done
[root@VM-8-14-centos ~/luffy]# ls
all.rar get onepiece.txt robin.txt temp
3.2 解压缩 (.rar)
解压缩.rar 格式的文件的时候,可以使用 rar 也可以使用 unrar, 操作方式是一样的,需要添加参数 x, 默认是将压缩包内容释放到当前目录中,如果要释放到指定目录直接指定解压目录名即可,不需要使用任何参数。
# 解压缩: 需要参数 x
# 语法: 解压缩到当前目录中
$ rar/unrar x 压缩包名字
# 语法: 解压缩到指定目录中
rar/unrar x 压缩包名字 解压目录
# 查看目录文件信息
[root@VM-8-14-centos ~/luffy]# ls
all.rar get onepiece.txt robin.txt temp
# 删除 temp 目录中的所有文件
[root@VM-8-14-centos ~/luffy]# rm temp/* -rf
# 将 all.rar 中的文件解压缩到 temp 目录中
[root@VM-8-14-centos ~/luffy]# rar x all.rar temp/
RAR 6.00 Copyright (c) 1993-2020 Alexander Roshal 1 Dec 2020
Trial version Type 'rar -?' for help
Extracting from all.rar
Extracting temp/onepiece.txt OK
Creating temp/get OK
Extracting temp/get/link.lnk OK # 子目录文件也被释放出来了
Extracting temp/get/link.lnk OK # 子目录文件也被释放出来了
Extracting temp/get/link.lnk OK # 子目录文件也被释放出来了
Creating temp/get/onepiece OK
Extracting temp/get/link.lnk OK # 子目录文件也被释放出来了
Extracting temp/get/link.lnk OK # 子目录文件也被释放出来了
Extracting temp/get/onepiece/haha.txt OK
Extracting temp/get/link.txt OK
Extracting temp/robin.txt OK
All OK
# 查看 temp 目录中文件信息
[root@VM-8-14-centos ~/luffy]# ls temp/
get onepiece.txt robin.txt
4. xz
.xz 格式的文件压缩和解压缩都相对比较麻烦,通过一个命令是完不成对应的操作的,需要通过两步操作才行。并且操作过程中需要使用 tar 工具进行打包,压缩使用的则是 xz 工具。
4.1 压缩(.tar.xz)
创建文件的步骤如下,首先 将需要压缩的文件打包 tar cvf xxx.tar files, 然后再对打包文件进行压缩 xz -z xxx.tar, 这样我们就可以得到一个打包之后的压缩文件了。
使用 xz 工具压缩文件的时候需要添加参数 -z
# 语法:
# 第一步
$ tar cvf xxx.tar 要压缩的文件
# 第二步, 最终得到一个xxx.tar.xz 格式的压缩文件
$ xz -z xxx.tar
# 查看目录文件信息
[root@VM-8-14-centos ~/luffy]# ls
get onepiece.txt robin.txt temp
# 将文件 onepiece.txt, robin.txt 和目录 get 打包到 all.tar 中
[root@VM-8-14-centos ~/luffy]# tar cvf all.tar onepiece.txt robin.txt get/
onepiece.txt
robin.txt
get/
get/link.lnk
get/onepiece/
get/onepiece/haha.txt
get/link.txt
# 查看目录文件信息, 多了一个打包文件 all.tar
[root@VM-8-14-centos ~/luffy]# ls
all.tar get onepiece.txt robin.txt temp
# 使用 xz 工具压缩打包文件 all.tar
[root@VM-8-14-centos ~/luffy]# xz -z all.tar
# 最终得到了压缩之后的打包文件 all.tar.xz
[root@VM-8-14-centos ~/luffy]# ls
all.tar.xz get onepiece.txt robin.txt temp
4.2 解压缩 (.tar.xz)
解压缩的步骤和压缩的步骤相反,需要先解压缩,然后将文件包中的文件释放出来。
使用 xz 工具解压需要使用参数 -d。
# 语法:
# 第一步: 压缩包解压缩, 得到 xxx.tar
$ xz -d xxx.tar.xz
# 第二步: 将 xxx.tar 中的文件释放到当前目录
$ tar xvf xxx.tar
# 查看目录中文件信息, 有一个 all.tar.xz
[root@VM-8-14-centos ~/luffy]# ls
all.tar.xz get onepiece.txt robin.txt temp
# 将 all.tar.xz 解压缩, 得到 all.tar
[root@VM-8-14-centos ~/luffy]# xz -d all.tar.xz
# 查看目录文件, 得到了 all.tar
[root@VM-8-14-centos ~/luffy]# ls
all.tar get onepiece.txt robin.txt temp
# 释放 all.tar 到当前目录
[root@VM-8-14-centos ~/luffy]# tar xvf all.tar
onepiece.txt
robin.txt
get/
get/link.lnk
get/onepiece/
get/onepiece/haha.txt
get/link.txt
五、查找命令
Linux 为我们提供了很多的用于文件搜索的命令,如果需求比较简单可以使用 locate,which,whereis 来完成搜索,如果需求复杂可以使用 find, grep 进行搜索。其中 which 在前边已经介绍过了, 使用方法和功能就直接略过了,whereis 局限性太大,不常用这里也就不介绍了。
1. find
find 是 Linux 中一个搜索功能非常强大的工具,它的主要功能是根据文件的属性,查找对应的磁盘文件,比如说我们常用的一些属性 文件名 , 文件类型 , 文件大小 , 文件的目录深度 等,下面基于这些常用数据来讲解一些具体的使用方法。
如果想用通过属性对文件进行搜索, 只需要指定出属性对应的参数就可以了, 下面将依次进行介绍。
find搜索默认是递归的
1.1 文件名 (-name)
根据文件名进行搜索有两种方式: 精确查询和模糊查询。关于模糊查询必须要使用对应的通配符,最常用的有两个, 分别为 * 和 ?。其中 * 可以匹配零个或者多个字符, ?用于匹配单个字符。
如果我们进行模糊查询,建议(非必须)将带有通配符的文件名写到引号中(单引号或者双引号都可以),这样可以避免搜索命令执行失败(如果不加引号,某些情况下会这样)。
如果需要根据文件名进行搜索,需要使用参数 -name。
# 语法格式: 根据文件名搜索
$ find 搜索的路径 -name 要搜索的文件名
# 模式搜索
# 搜索 root 家目录下文件后缀为 txt 的文件
[root@VM-8-14-centos ~]# find /root -name "*.txt"
/root/luffy/get/onepiece/haha.txt
/root/luffy/get/onepiece/onepiece.txt
/root/luffy/get/onepiece.txt
/root/luffy/get/link.txt
/root/luffy/robin.txt
/root/luffy/onepiece.txt
/root/ace/brother/finally/die.txt
/root/onepiece.txt
##################################################
# 精确搜索
# 搜索 root 家目录下文件名为 onepiece.txt 的文件
[root@VM-8-14-centos ~]# find /root -name "onepiece.txt"
/root/luffy/get/onepiece/onepiece.txt
/root/luffy/get/onepiece.txt
/root/luffy/onepiece.txt
/root/onepiece.txt
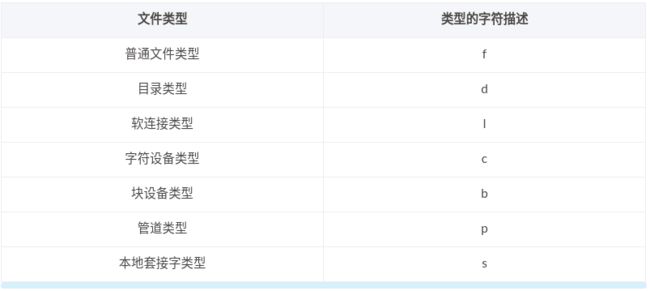
1.2 文件类型 (-type)
在前边文章中已经介绍过 Linux 中有 7 中文件类型 , 如果有去求我们可以通过 find 对指定类型的文件进行搜索,该属性对应的参数为 -type。其中每种类型都有对应的关键字,如下表:
# 语法格式:
$ find 搜索的路径 -type 文件类型
# 搜索 root 用户家目录下, 软连接类型的文件
[root@VM-8-14-centos ~]# find /root -type l
/root/link.lnk
/root/luffy/get/link.lnk
/root/file/link
1.3 文件大小 (-size)
如果需要根据文件大小进行搜索,需要使用参数 -size。关于文件大小的单位有很多,可以根据实际需求选择,常用的分别有 k(小写), M(大写), G(大写)。
在进行文件大小判断的时候,需要指定相应的范围,涉及的符号有两个分别为:加号 (+) 和 减号 (-),下面具体说明其使用方法:
# 语法格式:
$ find 搜索的路径 -size [+|-]文件大小
- 文件大小需要加单位:
- k (小写)
- M (大写)
- G (大写)
关于文件大小的区间划分非常重要,请仔细阅读,并思考,可以自己画个图,这里以 4k 来举例:
-
-size 4k 表示的区间为 (4-1k,4k], 表示一个区间,大于 3k, 小于等于 4k
-
-size -4k: [0k, 4-1k], 表示一个区间,大于等于 0 并且 小于等于 3k
-
-size +4k: (4k, 正无穷), 表示搜索大于 4k 的文件
# 搜索当前目录下 大于1M的所有文件 (file>3M)
$ find ./ -size +3M
# 搜索当前目录下 大于等于0M并且小于等于2M的文件 (0M <= file <=2M)
$ find ./ -size -3M
# 搜索当前目录下 大于2M并且小于等于3M的文件 (2M < file <=3M)
$ find ./ -size 3M
# 搜索当前目录下 大于1M 并且 小于等于 3M 的文件
$ find ./ -size +1M -size -4M
1.4 目录层级
因为 Linux 的目录是树状结构,所有目录可能有很多层,在搜索某些属性的时候可以指定只搜索某几层目录,相关的参数有两个,分别为: -maxdepth 和 -mindepth。
这两个参数不能单独使用, 必须和其他属性一起使用,且这两个参数要在其他属性之前,也就是搜索某几层目录中满足条件的文件。
- -maxdepth: 最多搜索到第多少层目录,
- -mindepth: 至少从第多少层开始搜索
# 查找文件, 从根目录开始, 最多搜索5层, 这个文件叫做 *.txt (1 <= 层数 <= 5)
$ sudo find / -maxdepth 5 -name "*.txt"
# 查找文件, 从根目录开始, 至少从第5层开始搜索, 这个文件叫做 *.txt (层数>=5层)
$ sudo find / -mindepth 5 -name "*.txt"
1.5 同时执行多个操作
在搜索文件的时候如果想在一个 find 执行多个操作,通过使用管道 (|) 的方式是行不通的,比如下面的操作:
# 比如: 通过find搜索最多两层目录中后缀为 .txt 的文件, 然后再查看这些满足条件的文件的详细信息
# 在find操作中直接通过管道操作多个指令, 最终输出的结果是有问题, 因此不能直接这样使用
$ find ./ -maxdepth 2 -name "*.txt" | ls -l
total 612
drwxr-xr-x 2 root root 4096 Jan 26 18:11 a
-rw-r--r-- 1 root root 269 Jan 26 17:44 a.c
drwxr-xr-x 3 root root 4096 Jan 26 18:39 ace
drwxr-xr-x 4 root root 4096 Jan 25 15:21 file
lrwxrwxrwx 1 root root 24 Jan 25 17:27 link.lnk -> /root/luffy/onepiece.txt
drwxr-xr-x 4 root root 4096 Jan 26 18:39 luffy
-r--r--r-- 1 root root 37 Jan 26 16:50 onepiece.txt
-rw-r--r-- 1 root root 598314 Dec 2 02:07 rarlinux-x64-6.0.0.tar.gz
如果想要实现上面的需求,需要在 find 中使用 exec, ok, xargs, 这样就可以在 find 命令执行完毕之后,再执行其他的子命令了。
1.5.1 exec
-exec 是 find 的参数,可以在exec参数后添加其他需要被执行的shell命令。
find 添加了 exec 参数之后,命令的尾部需要加一个后缀 {} ;, 注意 {} 和 \ 之间需要有一个空格。
在参数 -exec 后添加的 shell 命令处理的是 find 搜索之后的结果,find 的结果会作为 新添加的 shell 命令 的输入,最后在终端上输出最终的处理结果。
# 语法:
$ find 路径 参数 参数值 -exec shell命令2 {} \;
# 搜索最多两层目录, 文件名后缀为 .txt的文件
$ find ./ -maxdepth 2 -name "*.txt"
./luffy/robin.txt
./luffy/onepiece.txt
./onepiece.txt
# 搜索到满足条件的文件之后, 再继续查看文件的详细属性信息
$ find ./ -maxdepth 2 -name "*.txt" -exec ls -l {} \;
-rw-r--r-- 1 root root 0 Jan 25 17:54 ./luffy/robin.txt
-r--r--r-- 2 root root 37 Jan 25 17:54 ./luffy/onepiece.txt
-r--r--r-- 1 root root 37 Jan 26 16:50 ./onepiece.txt
1.5.2 ok
-ok 和 -exec 都是 find 命令的参数,使用方式类似,但是这个参数是交互式的,在处理 find 的结果的时候,会向用户发起询问,比如在删除搜索结果的时候,为了保险起见,就需要询问机制了。
语法格式如下:
# 语法: 其实就是将 -exec 替换为 -ok, 其他都不变
$ find 路径 参数 参数值 -ok shell命令2 {} \;
# 搜索到了2个满足条件的文件
$ find ./ -maxdepth 1 -name "*.txt"
./aaaaa.txt
./english.txt
# 查找并显示文件详细信息
$ find ./ -maxdepth 1 -name "*.txt" -ok ls -l {} \;
< ls ... ./aaaaa.txt > ? y # 同意显示文件详细信息
-rw-rw-r-- 1 robin robin 10 Apr 17 11:34 ./aaaaa.txt
< ls ... ./english.txt > ? n # 不同意显示文件详细信息, 会跳过显示该条信息
# 什么时候需要交互呢? ---> 删除文件的时候
$ find ./ -maxdepth 1 -name "*.txt" -ok rm -rf {} \;
< rm ... ./aaaaa.txt > ? y # 同意删除
< rm ... ./english.txt > ? n # 不同意删除
# 删除一个文件之后再次进行相同的搜索
$ find ./ -maxdepth 1 -name "*.txt"
./english.txt # 只剩下了一个.txt 文件
1.5.3 xargs
在使用 find 的 -exec 参数的时候,需要在指定的子命令尾部添加几个特殊字符 {} ;,一不小心就容易写错,有一种看起来更加直观、书写更加简便的方式,我们可以使用 xargs 替换掉 -exec 参数,而且在处理数据的时候 xargs更高效。有了 xargs 的加持我们就可以在 find 命令中直接使用管道完成前后命令的数据传递,使用方法如下:
# 在find 中 使用 xargs 关键字我们就可以使用管道了, 否则使用管道也不会起作用
# 将 find 搜索的结果通过管道传递给后边的shell命令继续处理
$ find 路径 参数 参数值 | xargs shell命令2
# 查找文件
$ find ./ -maxdepth 1 -name "*.cpp"
./occi.cpp
./main.cpp
./test.cpp
# 查找文件, 并且显示文件的详细信息
robin@OS:~$ find ./ -maxdepth 1 -name "*.cpp" | xargs ls -l
-rw-r--r-- 1 robin robin 2223 Mar 2 2020 ./main.cpp
-rw-r--r-- 1 robin robin 1406 Mar 2 2020 ./occi.cpp
-rw-r--r-- 1 robin robin 2015 Mar 1 2020 ./test.cpp
# xargs的效率比使用 -exec 效率高
-exec: 将find查询的结果逐条传递给后边的shell命令
-xargs: 将find查询的结果一次性传递给后边的shell命令
2. grep
和 find 不同 grep 命令用于查找文件里符合条件的字符串。grep 命令中有几个常用参数,下面介绍一下:
- -r: 如果需要搜索目录中的文件内容,需要进行递归操作,必须指定该参数
- -i: 对应要搜索的关键字,忽略字符大小写的差别
- -n: 在显示符合样式的那一行之前,标示出该行的列数编号
# 语法格式:
$ grep "搜索的内容" 搜索的路径/文件 参数
对应要搜索的文件内容,建议放到引号中,因为关键字中可能有特殊字符,或者有空格,从而导致解析错误。
关于引号, 单双都可以,可根据自己的需求选择。
# 搜索指定文件中是否有字符串 include
[root@VM-8-14-centos ~]# grep "include" a.c
#include
#include
#include
# 不区分大小写进行搜索
[root@VM-8-14-centos ~]# grep "INCLUDE" a.c
[root@VM-8-14-centos ~]# grep "INCLUDE" a.c -i
#include
#include
#include
# 搜索指定目录中哪些文件中包含字符串 include 并且显示关键字所在的行号
[root@VM-8-14-centos ~]# grep "include" ./ -rn
./a.c:1:#include
./a.c:2:#include
./a.c:3:#include
./luffy/get/e.c:1:#include
./luffy/get/e.c:2:#include
./luffy/get/e.c:3:#include
./luffy/c.c:1:#include
./luffy/c.c:2:#include
./luffy/c.c:3:#include
./ace/b.c:1:#include
./ace/b.c:2:#include
./ace/b.c:3:#include
./.bash_history:1449:grep "include" ./
./.bash_history:1451:grep "include" ./ -r
./.bash_history:1465:grep "include" a.c
3. locate
我们可以将 locate 看作是一个简化版的 find, 使用这个命令我们可以根据文件名搜索本地的磁盘文件 , 但是 locate的效率比find要高很多。原因在于它不搜索具体目录,而是搜索一个本地的数据库文件,这个数据库中含有本地所有文件信息。Linux 系统自动创建这个数据库,并且每天自动更新一次,所以使用 locate 命令查不到最新变动过的文件。为了避免这种情况,可以在使用locate之前,先使用updatedb命令,手动更新数据库。
# 使用管理员权限更新本地数据库文件, root用户这样做
$ updatedb
# 非root用户需要加 sudo
$ sudo updatedb
locate 有一些常用参数,使用之前先来介绍一下:
-
搜索所有目录下以某个关键字开头的文件
$ locate test # 搜索所有目录下以 test 开头的文件 -
搜索指定目录下以某个关键字开头的文件,指定的目录必须要使用绝对路径
$ locate /home/robin/test # 指定搜索目录为 /home/robin/, 文件以 test 开头 -
搜索文件的时候,忽略文件名的大小写,使用参数 -i
$ locate TEST -i # 文件名以小写的test为前缀的文件也能被搜索到 -
列出前 N 个匹配到的文件名称或路径名称,使用参数 -n
$ locate test -n 5 # 搜索文件前缀为 test 的文件, 并且只显示5条信息 -
基于正则表达式进行文件名匹配,查找符合条件的文件,使用参数 -r
# 使用该参数, 需要有正则表达式基础 $ locate -r "\.cpp$" # 搜索以 .cpp 结尾的文件正则表达式小科普:
- 在正则表达式中 . 可以匹配任意一个 非 \n 的单字符
- 上边的命令中使用转译字符 \ 对特殊字符. 转译,就得到了普通的字符.
- 在正则表达式中 $ 放到字符尾部,表示字符串必须以这个字符结尾,上边的命令中修饰的是字符 p
- 正则表达式中的 字符 c 和后边的字符 p 需要进行字节匹配,没有特殊含义
- 通过上面的解释就能明白 .cpp$ 说的就是以 .cpp 结尾的字符串
六、Vim的使用
Vim 是 Linux 操作系统中一款功能强大的文本编辑器,支持安装各种插件。但是 vim 和 windows 中的文件编辑器所不同的是它没有 UI 界面,所有的操作都是通过键盘快捷键操作完成的,因此要想熟练使用 vim 在 Linux 中进行文本编辑是有成本的,需要花费一定的时间去练习。
如果我们拿到了一个纯净版的 Linux, 里边是没有 vim 的,但是有一个类似的文本编辑器叫做 Vi。vi 编辑器的功能不是很强,可以这样理解 vim 就是 vi 的增强版。
首先介绍一下如何在线安装 vim,软件安装需要管理员权限:
1. vim 的安装
-
Ubuntu
- $ sudo apt install vim # 如果是root用户就不用加 sudo 了 -
CentOS
$ sudo yum install vim # 如果是root用户就不用加 sudo 了
vim 安装完毕之后,可以先查看一下版本 (在线安装不能保证安装的软件是最新版本)
$ vim --version
另外 vim 还提供了使用文档,直接在终端执行下面的命令就可以打开了
$ vimtutor
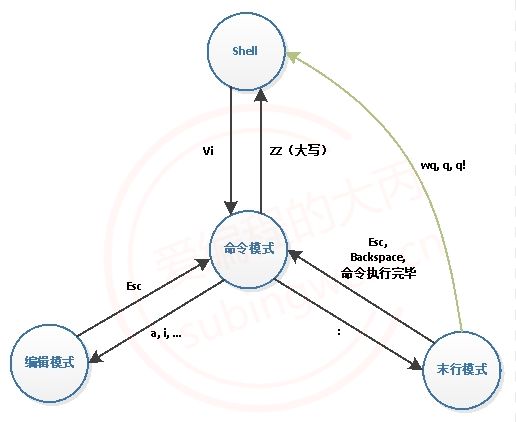
2. vim 的模式
在 vim 中一共有三种模式,分别是 命令模式 , 末行模式 , 编辑模式,当我们打开 vim 之后默认进入的是命令模式。
- 命令模式:在该模式下我们可以进行查看文件内容 , 修改文件 , 关键的搜索等操作。
- 编辑模式:在该模式下主要对文件内容进行修改和内容添加。
- 末行模式:在该模式下可以进行 执行Linux命令 , 保存文件 , 进行行的跳转 , 窗口分屏等操作。
介绍的以上三种模式之间是可以相互切换的:
- 命令模式 -> 编辑模式 -> 命令模式
- 命令模式 -> 末行模式 -> 命令模式
- 编辑模式和末行模式之间是不能相互直接切换的
3. 命令模式下的操作
通过 vim 打开一个文件,如果文件不存在,在退出的时候进行了保存,文件就会被创建出来
# 打开一个文件
$ vim 文件名
3.1 保存退出
直接在键盘上操作,通过键盘按两个连续的大写的 Z (此处是大写的Z, 需要先按住 Shift 再操作哦)
# 先按住 shift 键, 然后连续按两次 z
ZZ
3.2 代码格式化
在编码过程中,为了便于阅读和代码维护,代码都需要按照样式对其,如果代码格式凌乱,可以在命令模式下快速进行代码的格式化,让其看起来更加美观,这个操作需要在键盘上连续输入多个字符。
# 假设写的c/c+代码没有对齐, 通过该命令可以对齐代码
# 一定要注意最后一个字符是 大写的 G, 因此需要先按 shift
gg=G
3.3 光标移动
在 vim 中可以使用键盘上的方向键 (↑, ↓, ←, →) 来移动光标,这种操作相对比较麻烦, 有一种更加简便的操作方式, 就是使用键盘上的 h, j, k, l。
# 标准的移动光标的方法: 使用 h, j, k, l
光标上移
↑
|
光标左移 <-- h j k l --> 光标右移
|
↓
光标下移
除此之外我们还可以使用一些快捷键实现光标的快速跳转,常用的有:

3.4 删除命令
在 vim 中是没有删除操作的,其实所谓的删除就是剪切,被删除的数据都可被粘贴到文档的任意位置,即便如此我们还是习惯性的将剪切操作称之为删除,常用的删除操作如下表所示:

3.5 撤销和反撤销
撤销和反撤销对应 windows 中的 ctrl+z 和 ctrl+y, 但是在 vim 中使用这两个快捷键是不行的。

3.6 复制和粘贴
前边已经介绍了,在 vim 中做删除操作就相当于剪切,剪切或者复制之后的数据都可以用来做粘贴操作,在 vim 中对应的快捷键如下:

3.7 可视模式
在编辑文件的过程中,有时候需要删除或者需要复制的数据不整行的,而是一行中的某一部分,这时候可以使用可视模式进行文本的选择,之后再通过相关的快捷键对所选中的数据块进行复制或者删除操作。
有三种方式可以切换到可视模式:
- v: 进入的字符可视化模式(Characterwise visual mode),文本选择是以字符为单位的。
- V :进入的行可视化模式(Linewise visual mode),文本选择是以行为单位的。
- ctrl-v: 进入的块可视化模式(Blockwise visual mode),可以选择一个矩形内的文本。
进入到可视模式之后,就可以进行文本块的选择和复制以及删除了

3.7.1 字符可视模式
控制光标方向用来选择文件中的不规则数据块,可以对选中的文本信息进行复制和删除
# 进入到字符可视模式,直接在键盘上按 v 即可:
v
通过 v 切换到字符可视模式之后, 在窗口的最下方会看到 – VISUAL-- 字样
3.7.2 行可视模式
向下移动光标可以选择一整行,向上移动光标可以取消整行选择
# 进入行可视模式, 键盘上按 shift+v
V
通过 V 切换到行可视模式之后, 在窗口的最下方会看到 – VISUAL LINE – 字样。
3.7.3 块可视化模式
通过向上,下移动光标控制矩形文本块的高度,通过向左,右移动光标控制矩形文本块的宽度。
# 进入块可视模式, 选择一个矩形文本块
ctrl+v
通过 ctrl+v 切换到块可视模式之后, 在窗口的最下方会看到 – VISUAL BLOCK – 字样。
3.7.4 代码注释
代码块注释可以使用块可视模式,具体操作步骤如下:
-
通过 ctrl+v 进入块可视模式
-
移动光标上移(k)或者下移(j),选中多个代码行的开头,如下图所示
-
选择完毕后,按大写的的 I 键,此时下方会提示进入 “insert” 模式,输入你要插入的注释符,例如: //
-
最后按 ESC 键,你就会发现选中的多行代码已经被注释了
删除多行注释的方法,同样 Ctrl+v 进入列选择模式,移动光标把要删除的注释符选中,按下 d,注释就被删除了。
3.8 替换
命令模式下的替换功能并不强,常用于某个单字符的替换。

3.9 查找
在 vim 的命令模式下一共有三种查找方式,首先需要在键盘上输入对应的字符,然后按回车键 vim 会进行关键字匹配,之后就可以通过 n 或者 N 进行关键字之间的切换了。
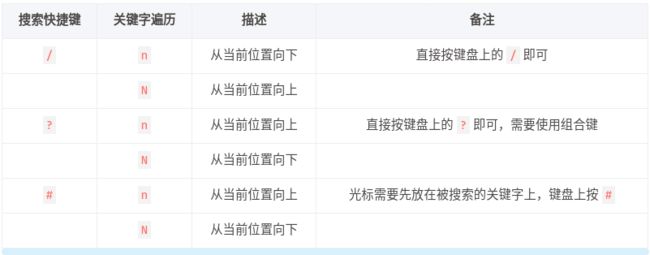
关于 ? 和 # 都需要使用组合键,这点要注意一下。
下面总结一下这三种搜索方式:
- 使用 / 或者 ? 搜索效果一样,只是遍历关键字的时候的顺序是相反的
- 使用 # 必须先从被搜索的文件中找到要搜索的关键字,好处就是搜索的内容不需要通过键盘输入
- 以上两种搜索方式各有优劣,请根据实际情况选择使用。
3.10 查看 man 文档
man 文档,是 Linux 中默认自带的帮助文档,作为程序猿可以通过这个文档来查询 shell 命令或者标准 API 函数或者系统自带的配置文件格式的说明等信息。
man 文档一共有 9 个章节, 具体如下:
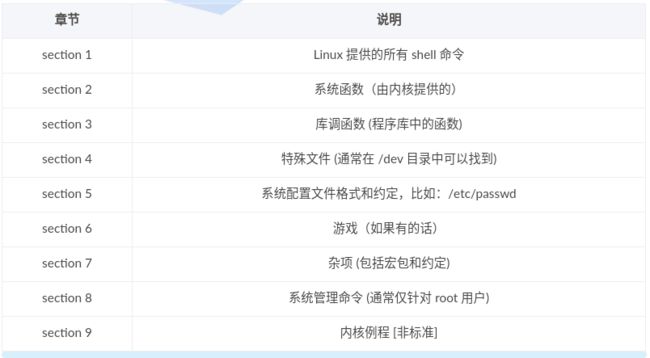
# 打开 man 文档首页
$ man man
# 退出 man 文档,直接按键盘上的 q 即可
q
那么,我们如何通过 man 文档查询相关的 shell 命令或者函数等信息呢?
# 下边举几个例子:
# 查询第一章的shell命令
$ man 1 cp
# 查询第二章的系统函数 (如: read, write, open 等)
$ man 2 read
# 查询第三章的标准的库函数 (如: fread, fwrite, fopen 等)
$ man 3 fread
# 查询第五章的特殊的配置文件说明, 比如: /etc/passwd 或者 /etc/group
$ man 5 passwd
查询的时候章节号是可以省略的,只是查到的结果不精确。如果不写章节号,从第一章开始搜索查询的关键字,如果查询到了,直接就结束了。也就是说如果查询的是函数,但是这个函数和某个命令的名字是相同的,查询到第一章搜索就结束了。
如果当前是在 vim 的命令模式下,我们可以直接跳转到 man 文档:
- 找到要查看的函数,然后将光标放到该函数上
- 在键盘上依次输入:章节号 (可选) + K(shift+k)(大写的k),就会自动调整到 man 文档中了
3.11 切换到编辑模式
如果要编辑文件,需要从命令模式切换到文件编辑模式,切换模式的快捷键有很多,不同的快捷键对应的效果有所不同,效果如下表所示:

文件编辑完成之后,从编辑模式回到命令模式只需要按键盘上的 Esc 即可。
4. 末行模式下的操作
4.1 命令模式到末行模式
从命令模式切换到末行模式只需要在键盘上输入一个 :,同时这个符号也会出现在窗口的最下端,这时候我们就可以在最后一行输入我们执行的命令了。
# 命令模式切换到末行模式
在命令模式下键盘输入一个 冒号 -> :
# 从末行模式 -> 命令模式
1. 按两次esc
2. 在末行模式下执行一个完整指令, 执行完毕, 自动回到命令模式
4.2 保存退出
使用 vim 对文件编辑完成之后,需要保存或者退出 vim 一般都是在末行模式下完成的,不管是进行那种操作都有对应的操作命令,如下表:

4.3 替换
末行模式下的替换比命令模式下的替换功能要强大的多,在末行模式下可以指定将什么样的内容替换为什么样的内容,并且可以指定替换某一行或者某几行或者是全文替换。
替换对应的命令是 s 并且可以给其指定参数,默认情况下只替换相关行的第一个满足条件的关键字, 如果需要整行替换需要加参数 /g。

4.4 分屏
分屏就是将当前屏幕中的窗口以水平或者垂直的方式拆分成多个,在不同的子窗口中可以显示同一个文件或者不同文件中的内容,下边介绍一下相关的分屏命令:

除了在命令模式下分屏,我们也可以在使用 vim 打开文件的时候直接分屏,下边是需要用到的参数:
- -o: 水平分屏
- -O: 垂直分屏
# 在vim打开文件的时候指定打开多个文件和分屏方式
# 水平分屏
$ vim -o 文件1, 文件2, 文件3 ...
# 垂直分屏
$ vim -O 文件1, 文件2, 文件3 ...
4.5 行跳转
在 vim 中不仅可以在命令模式下进行行的跳转,也可以在末行模式下进行行跳转,末行模式下指定哪一行光标就可以跳转到哪一行。
:行号 # 输入完行号之后敲回车
4.6 执行 shell 命令
在使用 vim 编辑文件的过程中,还可以在末行模式下执行需要的 shell 命令,在执行 shell 命令之前需要在前边加上一个叹号 !。
# 语法:
:!shell命令
# 举例
:!ls # 回车即可
5. vim 配置文件
vim 是一个文本编辑器工具,这个工具也是有配置文件的,文件的名字叫做 vimrc,在里边可以设置样式,功能 , 快捷键等属性 。对应的配置文件分为两种 用户级别和系统级别。
- 用户级别的配置文件(~/.vimrc)只对当前用户有效
- 系统级别的配置文件(/ect/vim/vimrc)对所有 Linux 用户都有效
- 如果两个配置文件都设置了,用户级别的配置文件起作用(用户级别优先级高)
6.vim 插件快速安装
Linux 的文本编辑器 vim 功能不仅强大,还支持安装各种插件,但是插件的安装一直是让小伙伴们头疼的问题。下面为大家介绍一个快速安装插件的方法,这是 github 上的一个开源项目,基于脚本一键安装。
vimplus 项目的 github 地址: https://github.com/chxuan/vimplus
七、GCC
GCC 是 Linux 下的编译工具集,是 GNU Compiler Collection 的缩写,包含 gcc、g++ 等编译器。这个工具集不仅包含编译器,还包含其他工具集,例如 ar、nm 等。
GCC 工具集不仅能编译 C/C++ 语言,其他例如 Objective-C、Pascal、Fortran、Java、Ada 等语言均能进行编译。GCC 在可以根据不同的硬件平台进行编译,即能进行交叉编译,在 A 平台上编译 B 平台的程序,支持常见的 X86、ARM、PowerPC、mips 等,以及 Linux、Windows 等软件平台。
1. 安装 GCC
有些纯净版的 Linux 默认没有 gcc 编译器,需要自己安装,在线安装步骤如下:
# 安装软件必须要有管理员权限
# ubuntu
$ sudo apt update # 更新本地的软件下载列表, 得到最新的下载地址
$ sudo apt install gcc g++ # 通过下载列表中提供的地址下载安装包, 并安装
# centos
$ sudo yum update # 更新本地的软件下载列表, 得到最新的下载地址
$ sudo yum install gcc g++ # 通过下载列表中提供的地址下载安装包, 并安装
# 查看 gcc 版本
$ gcc -v
$ gcc --version
# 查看 g++ 版本
$ g++ -v
$ g++ --version
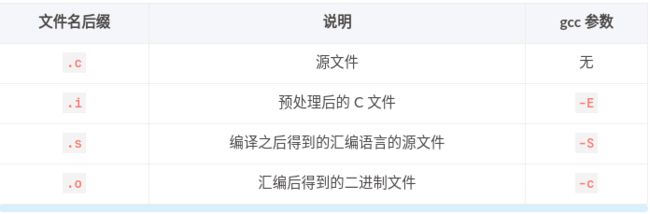
2. gcc 工作流程
GCC 编译器对程序的编译下图所示,分为 4 个阶段:预处理(预编译)、编译和优化、汇编和链接。GCC 的编译器可以将这 4 个步骤合并成一个。 先介绍一个每个步骤都分别做了写什么事儿:
-
预处理:在这个阶段主要做了三件事: 展开头文件 、宏替换 、去掉注释行
- 这个阶段需要 GCC 调用预处理器来完成,最终得到的还是源文件,文本格式
-
编译:这个阶段需要 GCC 调用编译器对文件进行编译,最终得到一个汇编文件
-
汇编:这个阶段需要 GCC 调用汇编器对文件进行汇编,最终得到一个二进制文件
-
链接:这个阶段需要 GCC 调用链接器对程序需要调用的库进行链接,最终得到一个可执行的二进制文件
在 Linux 下使用 GCC 编译器编译单个文件十分简单,直接使用 gcc 命令后面加上要编译的 C 语言的源文件,GCC 会自动生成文件名为 a.out 的可执行文件(也可以通过参数 -o 指定生成的文件名),也就是通过一个简单的命令上边提到的 4 个步骤就全部执行完毕了。但是如果想要单步执行也是没问题的, 下边基于这段示例程序给大家演示一下。
第一步:对源文件进行预处理,需要使用的 gcc 参数为 -E
# 1. 预处理, -o 指定生成的文件名
$ gcc -E test.c -o test.i
第二步:编译预处理之后的文件,需要使用的 gcc 参数为 -S
# 2. 编译, 得到汇编文件
$ gcc -S test.i -o test.s
第三步:对得到的汇编文件进行汇编,需要使用的 gcc 参数为 -c
# 3. 汇编
$ gcc -c test.s -o test.o
第四步:将得到的二进制文件和标准库进制链接,得到可执行的二进制文件,不需要任何参数
# 4. 链接
$ gcc test.o -o test
最后再次强调,在使用 gcc 编译程序的时候可以通过参数控制内部自动执行几个步骤:
# 参数 -c 是进行文件的汇编, 汇编之前的两步会自动执行
$ gcc test.c -c -o app.o
# 该命令是直接进行链接生成可执行程序, 链接之前的三步会自动执行
$ gcc test.c -o app
3.gcc 常用参数
下面的表格中列出了常用的一些 gcc 参数,这些参数在 gcc命令中没有位置要求,只需要编译程序的时候将需要的参数指定出来即可。

3.1 指定生成的文件名 (-o)
该参数用于指定原文件通过 gcc 处理之后生成的新文件的名字,有两种写法,原文件可以写在参数 -o 前边后缀写在后边。
# 参数 -o的用法 , 原材料 test.c 最终生成的文件名为 app
# test.c 写在 -o 之前
$ gcc test.c -o app
# test.c 写在 -o 之后
$ gcc -o app test.c
3.2 搜索头文件 (-I)
如果在程序中包含了一些头文件,但是包含的一些头文件在程序预处理的时候因为找不到无法被展开,导致程序编译失败,这时候我们可以在 gcc 命令中添加 -I 参数重新指定要引用的头文件路径,保证编译顺利完成。
# -I, 指定头文件目录
$ tree
.
├── add.c
├── div.c
├── include
│ └── head.h
├── main.c
├── mult.c
└── sub.c
# 编译当前目录中的所有源文件,得到可执行程序
$ gcc *.c -o calc
main.c:2:18: fatal error: head.h: No such file or directory
compilation terminated.
sub.c:2:18: fatal error: head.h: No such file or directory
compilation terminated.
通过编译得到的错误信息可以知道,源文件中包含的头文件无法被找到。通过提供的目录结构可以得知头文件 head.h 在 include 目录中,因此可以在编译的时候重新指定头文件位置,具体操作如下:
# 可以在编译的时候重新指定头文件位置 -I 头文件目录
$ gcc *.c -o calc -I ./include
3.3 指定一个宏 (-D)
在程序中我们可以使用宏定义一个常量,也可以通过宏控制某段代码是否能够被执行。
如果不想在程序中定义这个宏, 但是又想让它存在,通过 gcc 的参数 -D 就可以实现了,编译器会认为参数后边指定的宏在程序中是存在的。
# 在编译命令中定义这个 DEBUG 宏,
$ gcc test.c -o app -D DEBUG
# 执行生成的程序, 可以看到程序第9行的输出
$ ./app
我是一个程序猿, 我不会爬树...
hello, GCC!!!
hello, GCC!!!
hello, GCC!!!
-D 参数的应用场景:
在发布程序的时候,一般都会要求将程序中所有的 log 输出去掉,如果不去掉会影响程序的执行效率,很显然删除这些打印 log 的源代码是一件很麻烦的事情,解决方案是这样的:
- 将所有的打印 log 的代码都写到一个宏判定中,可以模仿上边的例子
- 在编译程序的时候指定 -D 就会有 log 输出
- 在编译程序的时候不指定 -D, log 就不会输出
4. 多文件编译
GCC 可以自动编译链接多个文件,不管是目标文件还是源文件,都可以使用同一个命令编译到一个可执行文件中。
我们可以通过一个 gcc 命令将多个源文件编译并生成可执行程序,也可以分多步完成这个操作。
-
直接链接生成可执行程序
# 直接生成可执行程序 test $ gcc -o test string.c main.c # 运行可执行程序 $ ./test -
先将源文件编成目标文件,然后进行链接得到可执行程序
# 汇编生成二进制目标文件, 指定了 -c 参数之后, 源文件会自动生成 string.o 和 main.o $ gcc –c string.c main.c # 链接目标文件, 生成可执行程序 test $ gcc –o test string.o main.o # 运行可执行程序 $ ./test
5. gcc 与 g++
关于对 gcc 和 g++ 很多人的理解都是比较片面的或者是对二者的理解有一些误区,下边从三个方面介绍一下二者的区别:
-
在代码编译阶段(第二个阶段):
- 后缀为 .c 的,gcc 把它当作是 C 程序,而 g++ 当作是 C++ 程序
- 后缀为.cpp 的,两者都会认为是 C++ 程序,C++ 的语法规则更加严谨一些
- g++ 会调用 gcc,对于 C++ 代码,两者是等价的,也就是说 gcc 和 g++ 都可以编译 C/C++ 代码
-
在链接阶段(最后一个阶段):
- gcc 和 g++ 都可以自动链接到标准 C 库
- g++ 可以自动链接到标准 C++ 库,gcc 如果要链接到标准 C++ 库需要加参数 -lstdc++
-
关于 __cplusplus 宏的定义
- g++ 会自动定义cplusplus 宏,但是这个不影响它去编译 C 程序
- gcc 需要根据文件后缀判断是否需要定义 __cplusplus 宏 (规则参考第一条)
综上所述:
- 不管是 gcc 还是 g++ 都可以编译 C 程序,编译程序的规则和参数都相同
- g++ 可以直接编译 C++ 程序, gcc 编译 C++ 程序需要添加额外参数 -lstdc++
- 不管是 gcc 还是 g++ 都可以定义 __cplusplus 宏
# 编译 c 程序
$ gcc test.c -o test # 使用gcc
$ g++ test.c -o test # 使用g++
# 编译 c++ 程序
$ g++ test.cpp -o test # 使用g++
$ gcc test.cpp -lstdc++ -o test # 使用gcc
八、Linux 静态库和动态库
不管是 Linux 还是 Windows 中的库文件其本质和工作模式都是相同的,只不过在不同的平台上库对应的文件格式和文件后缀不同。程序中调用的库有两种 静态库和动态库,不管是哪种库文件本质是还是源文件,只不过是二进制格式只有计算机能够识别,作为一个普通人就无能为力了。
在项目中使用库一般有两个目的,一个是为了使程序更加简洁不需要在项目中维护太多的源文件,另一方面是为了源代码保密,毕竟不是所有人都想把自己编写的程序开源出来。
当我们拿到了库文件(动态库、静态库)之后要想使用还必须有这些库中提供的 API 函数的声明,也就是头文件,把这些都添加到项目中,就可以快乐的写代码了。
1. 静态库
在 Linux 中静态库由程序 ar 生成,现在静态库已经不像之前那么普遍了,这主要是由于程序都在使用动态库。关于静态库的命名规则如下:
- 在 Linux 中静态库以 lib 作为前缀,以.a 作为后缀,中间是库的名字自己指定即可,即: libxxx.a
- 在 Windows 中静态库一般以 lib 作为前缀,以 lib 作为后缀,中间是库的名字需要自己指定,即: libxxx.lib
1.1 生成静态链接库
生成静态库,需要先对源文件进行汇编操作 (使用参数 -c) 得到二进制格式的目标文件 (.o 格式), 然后在通过 ar 工具将目标文件打包就可以得到静态库文件了 (libxxx.a)。
使用 ar 工具创建静态库的时候需要三个参数:
- 参数c:创建一个库,不管库是否存在,都将创建。
- 参数s:创建目标文件索引,这在创建较大的库时能加快时间。
- 参数r:在库中插入模块 (替换)。默认新的成员添加在库的结尾处,如果模块名已经在库中存在,则替换同名的模块。
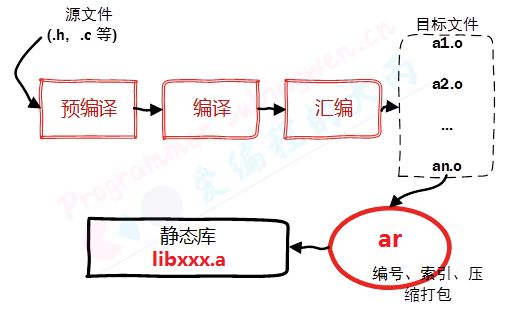
生成静态链接库的具体步骤如下:
-
需要将源文件进行汇编,得到 .o 文件,需要使用参数 -c
# 执行如下操作, 默认生成二进制的 .o 文件 # -c 参数位置没有要求 $ gcc 源文件(*.c) -c -
将得到的 .o 进行打包,得到静态库
$ ar rcs 静态库的名字(libxxx.a) 原材料(*.o) -
发布静态库
# 发布静态库 1. 提供头文件 **.h 2. 提供制作出来的静态库 libxxx.a
1.2 静态库制作举例
1.2.1 生成静态库
第一步:将源文件 add.c, div.c, mult.c, sub.c 进行汇编,得到二进制目标文件 add.o, div.o, mult.o, sub.o
# 1. 生成.o
$ gcc add.c div.c mult.c sub.c -c
sub.c:2:18: fatal error: head.h: No such file or directory
compilation terminated.
# 提示头文件找不到, 添加参数 -I 重新头文件路径即可
$ gcc add.c div.c mult.c sub.c -c -I ./include/
# 查看目标文件是否已经生成
$ tree
.
├── add.c
├── add.o # 目标文件
├── div.c
├── div.o # 目标文件
├── include
│ └── head.h
├── main.c
├── mult.c
├── mult.o # 目标文件
├── sub.c
└── sub.o # 目标文件
第二步:将生成的目标文件通过 ar 工具打包生成静态库
# 2. 将生成的目标文件 .o 打包成静态库
$ ar rcs libcalc.a a.o b.o c.o # a.o b.o c.o在同一个目录中可以写成 *.o
# 查看目录中的文件
$ tree
.
├── add.c
├── add.o
├── div.c
├── div.o
├── include
│ └── `head.h ===> 和静态库一并发布
├── `libcalc.a ===> 生成的静态库
├── main.c
├── mult.c
├── mult.o
├── sub.c
└── sub.o
第三步:将生成的的静态库 libcalc.a 和库对应的头文件 head.h 一并发布给使用者就可以了。
# 3. 发布静态库
1. head.h => 函数声明
2. libcalc.a => 函数定义(二进制格式)
1.3 静态库的使用
当我们得到了一个可用的静态库之后,需要将其放到一个目录中,然后根据得到的头文件编写测试代码,对静态库中的函数进行调用。
# 1. 首先拿到了发布的静态库
`head.h` 和 `libcalc.a`
# 2. 将静态库, 头文件, 测试程序放到一个目录中准备进行测试
.
├── head.h # 函数声明
├── libcalc.a # 函数定义(二进制格式)
└── main.c # 函数测试
编译测试程序,得到可执行文件。
# 3. 编译测试程序 main.c
$ gcc main.c -o app
/tmp/ccR7Fk49.o: In function `main':
main.c:(.text+0x38): undefined reference to `add'
main.c:(.text+0x58): undefined reference to `subtract'
main.c:(.text+0x78): undefined reference to `multiply'
main.c:(.text+0x98): undefined reference to `divide'
collect2: error: ld returned 1 exit status
上述错误分析:
编译的源文件中包含了头文件 head.h, 这个头文件中声明的函数对应的定义(也就是函数体实现)在静态库中,程序在编译的时候没有找到函数实现,因此提示 undefined reference to xxxx。
解决方案:在编译的时将静态库的路径和名字都指定出来
- -L: 指定库所在的目录 (相对或者绝对路径)
- -l: 指定库的名字,需要掐头 (lib) 去尾 (.a) 剩下的才是需要的静态库的名字
# 4. 编译的时候指定库信息
-L: 指定库所在的目录(相对或者绝对路径)
-l: 指定库的名字, 掐头(lib)去尾(.a) ==> calc
# -L -l, 参数和参数值之间可以有空格, 也可以没有 -L./ -lcalc
$ gcc main.c -o app -L ./ -l calc
# 查看目录信息, 发现可执行程序已经生成了
$ tree
.
├── app # 生成的可执行程序
├── head.h
├── libcalc.a
└── main.c
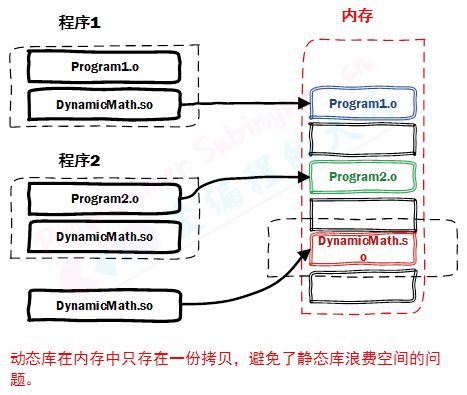
2. 动态库
动态链接库是程序运行时加载的库,当动态链接库正确部署之后,运行的多个程序可以使用同一个加载到内存中的动态库,因此在 Linux 中动态链接库也可称之为共享库。
动态链接库是目标文件的集合,目标文件在动态链接库中的组织方式是按照特殊方式形成的。库中函数和变量的地址使用的是相对地址(静态库中使用的是绝对地址),其真实地址是在应用程序加载动态库时形成的。
动态库有执行权限,静态库没有执行权限。
关于动态库的命名规则如下:
- 在 Linux 中动态库以 lib 作为前缀,以.so 作为后缀,中间是库的名字自己指定即可,即: libxxx.so
- 在 Windows 中动态库一般以 lib 作为前缀,以 dll 作为后缀,中间是库的名字需要自己指定,即: libxxx.dll。使用的编译软件不同可能生成不同后缀的动态库,比如用vs会生成.dll和.lib两种后缀。
2.1 生成动态链接库
生成动态链接库是直接使用 gcc 命令并且需要添加 -fPIC(-fpic) 以及 -shared 参数。
- -fPIC 或 -fpic 参数的作用是使得 gcc 生成的代码是与位置无关的,也就是使用相对位置。
- -shared参数的作用是告诉编译器生成一个动态链接库。
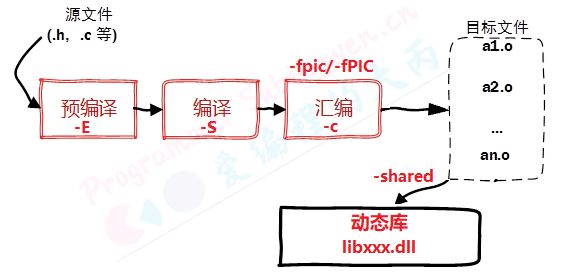
生成动态链接库的具体步骤如下:
-
将源文件进行汇编操作,需要使用参数 -c, 还需要添加额外参数 -fpic /-fPIC
# 得到若干个 .o文件 $ gcc 源文件(*.c) -c -fpic -
将得到的.o 文件打包成动态库,还是使用 gcc, 使用参数 -shared 指定生成动态库 (位置没有要求)
$ gcc -shared 与位置无关的目标文件(*.o) -o 动态库(libxxx.so) -
发布动态库和头文件
# 发布 1. 提供头文件: xxx.h 2. 提供动态库: libxxx.so
2.2 动态库制作举例
第一步:使用 gcc 将源文件进行汇编 (参数-c), 生成与位置无关的目标文件,需要使用参数 -fpic或者-fPIC
# 1. 将.c汇编得到.o, 需要额外的参数 -fpic/-fPIC
$ gcc add.c div.c mult.c sub.c -c -fpic -I ./include/
# 查看目录文件信息, 检查是否生成了目标文件
$ tree
.
├── add.c
├── add.o # 生成的目标文件
├── div.c
├── div.o # 生成的目标文件
├── include
│ └── head.h
├── main.c
├── mult.c
├── mult.o # 生成的目标文件
├── sub.c
└── sub.o # 生成的目标文件
第二步:使用 gcc 将得到的目标文件打包生成动态库,需要使用参数 -shared
# 2. 将得到 .o 打包成动态库, 使用gcc , 参数 -shared
$ gcc -shared add.o div.o mult.o sub.o -o libcalc.so
# 检查目录中是否生成了动态库
$ tree
.
├── add.c
├── add.o
├── div.c
├── div.o
├── include
│ └── `head.h ===> 和动态库一起发布
├── `libcalc.so ===> 生成的动态库
├── main.c
├── mult.c
├── mult.o
├── sub.c
└── sub.o
第三步:发布生成的动态库和相关的头文件
# 3. 发布库文件和头文件
1. head.h
2. libcalc.so
2.3 动态库的使用
当我们得到了一个可用的动态库之后,需要将其放到一个目录中,然后根据得到的头文件编写测试代码,对动态库中的函数进行调用。
# 1. 拿到发布的动态库
`head.h libcalc.so
# 2. 基于头文件编写测试程序, 测试动态库中提供的接口是否可用
`main.c`
# 示例目录:
.
├── head.h ==> 函数声明
├── libcalc.so ==> 函数定义
└── main.c ==> 函数测试
编译测试程序
# 3. 编译测试程序
$ gcc main.c -o app
/tmp/ccwlUpVy.o: In function `main':
main.c:(.text+0x38): undefined reference to `add'
main.c:(.text+0x58): undefined reference to `subtract'
main.c:(.text+0x78): undefined reference to `multiply'
main.c:(.text+0x98): undefined reference to `divide'
collect2: error: ld returned 1 exit status
错误原因:
和使用静态库一样,在编译的时候需要指定库相关的信息: 库的路径 -L 和 库的名字 -l
添加库信息相关参数,重新编译测试代码:
# 在编译的时候指定动态库相关的信息: 库的路径 -L, 库的名字 -l
$ gcc main.c -o app -L./ -lcalc
# 查看是否生成了可执行程序
$ tree
.
├── app # 生成的可执行程序
├── head.h
├── libcalc.so
└── main.c
# 执行生成的可执行程序, 错误提示 ==> 可执行程序执行的时候找不到动态库
$ ./app
./app: error while loading shared libraries: libcalc.so: cannot open shared object file: No such file or directory
关于整个操作过程的报告:
gcc 通过指定的动态库信息生成了可执行程序,但是可执行程序运行却提示无法加载到动态库。
2.4 解决动态库无法加载问题
2.4.1 库的工作原理
-
静态库如何被加载
在程序编译的最后一个阶段也就是链接阶段,提供的静态库会被打包到可执行程序中。当可执行程序被执行,静态库中的代码也会一并被加载到内存中,因此不会出现静态库找不到无法被加载的问题。
-
动态库如何被加载
- 在程序编译的最后一个阶段也就是链接阶段:
- 在 gcc 命令中虽然指定了库路径 (使用参数 -L ), 但是这个路径并没有记录到可执行程序中,只是检查了这个路径下的库文件是否存在。
- 同样对应的动态库文件也没有被打包到可执行程序中,只是在可执行程序中记录了库的名字。
- 可执行程序被执行起来之后:
- 程序执行的时候会先检测需要的动态库是否可以被加载,加载不到就会提示上边的错误信息
- 当动态库中的函数在程序中被调用了, 这个时候动态库才加载到内存,如果不被调用就不加载
- 动态库的检测和内存加载操作都是由动态连接器来完成的
- 在程序编译的最后一个阶段也就是链接阶段:
2.4.2 动态链接器
动态链接器是一个独立于应用程序的进程,属于操作系统,当用户的程序需要加载动态库的时候动态连接器就开始工作了,很显然动态连接器根本就不知道用户通过 gcc 编译程序的时候通过参数 -L 指定的路径。
那么动态链接器是如何搜索某一个动态库的呢,在它内部有一个默认的搜索顺序,按照优先级从高到低的顺序分别是:
-
可执行文件内部的 DT_RPATH 段
-
系统的环境变量 LD_LIBRARY_PATH
-
系统动态库的缓存文件 /etc/ld.so.cache,这是一个二进制文件,无法修改,如果要修改,找到它对应的文本文件/etc/ld.so.config,这个文件会同步到/etc/ld.so.cache
-
存储动态库 / 静态库的系统目录 /lib/, /usr/lib 等
按照以上四个顺序,依次搜索,找到之后结束遍历,最终还是没找到,动态连接器就会提示动态库找不到的错误信息。
2.4.3 解决方案
可执行程序生成之后,根据动态链接器的搜索路径,我们可以提供三种解决方案,我们只需要将动态库的路径放到对应的环境变量或者系统配置文件中,同样也可以将动态库拷贝到系统库目录(或者是将动态库的软链接文件放到这些系统库目录中)。
-
方案 1: 将库路径添加到环境变量 LD_LIBRARY_PATH 中
-
找到相关的配置文件
- 用户级别: ~/.bashrc —> 设置对当前用户有效
- 系统级别: /etc/profile —> 设置对所有用户有效
-
使用 vim 打开配置文件,在文件最后添加这样一句话
# 自己把路径写进去就行了 export LIBRARY_PATH=$LIBRARY_PATH:动态库的绝对路径 -
让修改的配置文件生效
-
修改了用户级别的配置文件,关闭当前终端,打开一个新的终端配置就生效了
-
修改了系统级别的配置文件,注销或关闭系统,再开机配置就生效了
-
不想执行上边的操作,可以执行一个命令让配置重新被加载
# 修改的是哪一个就执行对应的那个命令 # source 可以简写为一个 . , 作用是让文件内容被重新加载 $ source ~/.bashrc (. ~/.bashrc) $ source /etc/profile (. /etc/profile)
-
-
-
方案 2: 更新 /etc/ld.so.cache 文件
-
找到动态库所在的绝对路径(不包括库的名字)比如:/home/robin/Library/
-
使用 vim 修改 /etc/ld.so.conf 这个文件,将上边的路径添加到文件中 (独自占一行)
# 1. 打开文件 $ sudo vim /etc/ld.so.conf # 2. 添加动态库路径, 并保存退出 -
更新 /etc/ld.so.conf 中的数据到 /etc/ld.so.cache 中
# 必须使用管理员权限执行这个命令 $ sudo ldconfig
-
-
方案 3: 拷贝动态库文件到系统库目录 /lib/ 或者 /usr/lib 中 (或者将库的软链接文件放进去)
# 库拷贝,如果动态库更新了,需要重新拷贝 sudo cp /xxx/xxx/libxxx.so /usr/lib # 创建软连接 sudo ln -s /xxx/xxx/libxxx.so /usr/lib/libxxx.so
2.4.4 验证
在启动可执行程序之前,或者在设置了动态库路径之后,我们可以通过一个命令检测程序能不能够通过动态链接器加载到对应的动态库,这个命令叫做 ldd
# 语法:
$ ldd 可执行程序名
# 举例:
$ ldd app
linux-vdso.so.1 => (0x00007ffe8fbd6000)
libcalc.so => /home/robin/Linux/3Day/calc/test/libcalc.so (0x00007f5d85dd4000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f5d85a0a000)
/lib64/ld-linux-x86-64.so.2 (0x00007f5d85fd6000) ==> 动态链接器, 操作系统提供
3. 优缺点
3.1 静态库
-
优点:
-
静态库被打包到应用程序中加载速度快
-
发布程序无需提供静态库,移植方便
-
-
缺点:
- 相同的库文件数据可能在内存中被加载多份,消耗系统资源,浪费内存
- 库文件更新需要重新编译项目文件,生成新的可执行程序,浪费时间。

3.2 动态库
-
优点:
- 可实现不同进程间的资源共享
- 动态库升级简单,只需要替换库文件,无需重新编译应用程序
- 程序猿可以控制何时加载动态库,不调用库函数动态库不会被加载
-
缺点:
- 加载速度比静态库慢,以现在计算机的性能可以忽略
- 发布程序需要提供依赖的动态库
九、Makefile
make 是一个命令工具,是一个解释 makefile 中指令的命令工具,一般来说,大多数的 IDE 都有这个命令,比如:Visual C++ 的 nmake,QtCreator 的 qmake 等。
make 工具在构造项目的时候需要加载一个叫做 makefile 的文件,makefile 关系到了整个工程的编译规则。一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile 定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为 makefile 就像一个 Shell 脚本一样,其中也可以执行操作系统的命令。
makefile 带来的好处就是 ——“自动化编译”,一旦写好,只需要一个 make 命令,整个工程完全自动编译,极大的提高了软件开发的效率。
makefile 文件有两种命名方式 makefile 和 Makefile,构建项目的时候在哪个目录下执行构建命令 make 这个目录下的 makefile 文件就会别加载,因此在一个项目中可以有多个 makefile 文件,分别位于不同的项目目录中。
1. 规则
Makefile 的框架是由规则构成的。make 命令执行时先在 Makefile 文件中查找各种规则,对各种规则进行解析后运行规则。规则的基本格式为:
# 每条规则的语法格式:
target1,target2...: depend1, depend2, ...
command
......
......
每条规则由三个部分组成分别是目标(target), 依赖(depend) 和命令(command)。
-
命令(command): 当前这条规则的动作,一般情况下这个动作就是一个 shell 命令
- 例如:通过某个命令编译文件、生成库文件、进入目录等。
- 动作可以是多个,每个命令前必须有一个Tab缩进并且独占占一行。
-
依赖(depend): 规则所必需的依赖条件,在规则的命令中可以使用这些依赖。
- 例如:生成可执行文件的目标文件(*.o)可以作为依赖使用
- 如果规则的命令中不需要任何依赖,那么规则的依赖可以为空
- 当前规则中的依赖可以是其他规则中的某个目标,这样就形成了规则之间的嵌套
- 依赖可以根据要执行的命令的实际需求,指定很多个
-
目标(target): 规则中的目标,这个目标和规则中的命令是对应的
- 通过执行规则中的命令,可以生成一个和目标同名的文件
- 规则中可以有多个命令,因此可以通过这多条命令来生成多个目标,所以目标也可以有很多个
- 通过执行规则中的命令,可以只执行一个动作,不生成任何文件,这样的目标被称为伪目标
举例
# 举例: 有源文件 a.c b.c c.c head.h, 需要生成可执行程序 app
################# 例1 #################
app:a.c b.c c.c
gcc a.c b.c c.c -o app
################# 例2 #################
# 有多个目标, 多个依赖, 多个命令
app,app1:a.c b.c c.c d.c
gcc a.c b.c -o app
gcc c.c d.c -o app1
################# 例3 #################
# 规则之间的嵌套
app:a.o b.o c.o
gcc a.o b.o c.o -o app
# a.o 是第一条规则中的依赖
a.o:a.c
gcc -c a.c
# b.o 是第一条规则中的依赖
b.o:b.c
gcc -c b.c
# c.o 是第一条规则中的依赖
c.o:c.c
gcc -c c.c
2. 工作原理
2.1 规则的执行
在调用 make 命令编译程序的时候,make 会首先找到 Makefile 文件中的第 1 个规则,分析并执行相关的动作。但是需要注意的是,好多时候要执行的动作(命令)中使用的依赖是不存在的,如果使用的依赖不存在,这个动作也就不会被执行。
对应的解决方案是先将需要的依赖生成出来,我们就可以在 makefile 中添加新的规则,将不存在的依赖作为这个新的规则中的目标,当这条新的规则对应的命令执行完毕,对应的目标就被生成了,同时另一条规则中需要的依赖也就存在了。
这样,makefile 中的某一条规则在需要的时候,就会被其他的规则调用,直到 makefile 中的第一条规则中的所有的依赖全部被生成,第一条规则中的命令就可以基于这些依赖生成对应的目标,make 的任务也就完成了。
# makefile
# 规则之间的嵌套
# 规则1
app:a.o b.o c.o
gcc a.o b.o c.o -o app
# 规则2
a.o:a.c
gcc -c a.c
# 规则3
b.o:b.c
gcc -c b.c
# 规则4
c.o:c.c
gcc -c c.c
在这个例子中,如果执行 make 命令就会根据这个 makefile 中的 4 条规则编译这三个源文件。在解析第一条规则的时候发现里边的三个依赖都是不存在的,因此规则对应的命令也就不能被执行。
当依赖不存在的时候,make 就是查找其他的规则,看哪一条规则是用来生成需要的这个依赖的,找到之后就会执行这条规则中的命令。因此规则 2, 规则 3, 规则 4 里的命令会相继被执行,当规则 1 中依赖全部被生成之后对应的命令也就被执行了,因此规则 1 的目标被生成,make 工作结束。
知识点拓展:
如果想要执行 makefile 中非第一条规则对应的命令,那么就不能直接 make, 需要将那条规则的目标也写到 make 的后边,比如只需要执行规则 3 中的命令,就需要: make b.o。
2.2 文件的时间戳
make 命令执行的时候会根据文件的时间戳判定是否执行 makefile 文件中相关规则中的命令。
- 目标是通过依赖生成的,因此正常情况下:目标时间戳 > 所有依赖的时间戳 , 如果执行 make 命令的时候检测到规则中的目标和依赖满足这个条件,那么规则中的命令就不会被执行。
- 当依赖文件被更新了,文件时间戳也会随之被更新,这时候 目标时间戳 < 某些依赖的时间戳 , 在这种情况下目标文件会通过规则中的命令被重新生成。
- 如果规则中的目标对应的文件根本就不存在, 那么规则中的命令肯定会被执行。
# makefile
# 规则之间的嵌套
# 规则1
app:a.o b.o c.o
gcc a.o b.o c.o -o app
# 规则2
a.o:a.c
gcc -c a.c
# 规则3
b.o:b.c
gcc -c b.c
# 规则4
c.o:c.c
gcc -c c.c
根据上文的描述,先执行 make 命令,基于这个 makefile 编译这几个源文件生成对应的目标文件。然后再修改例子中的 a.c, 再次通过 make 编译这几个源文件,那么这个时候先执行规则 2 更新目标文件 a.o, 然后再执行规则 1 更新目标文件 app,其余的规则是不会被执行的。
2.3 自动推导
make 是一个功能强大的构建工具,虽然 make 需要根据 makefile 中指定的规则来完成源文件的编译。作为小白的我们编写 makefile 的时候难免写的不是那么严谨从而漏写一些构建规则,但是我们会发现程序还是会被编译成功。这是因为 make 有自动推导的能力,不会完全依赖 makefile。
比如:使用命令 make 编译扩展名为.c 的 C 语言文件的时候,源文件的编译规则不用明确给出。这是因为 make 进行编译的时候会使用一个默认的编译规则,按照默认规则完成对.c 文件的编译,生成对应的.o 文件。它使用命令 cc -c 来编译.c 源文件。在 Makefile 中只要给出需要构建的目标文件名(一个.o 文件),make 会自动为这个.o 文件寻找合适的依赖文件(对应的.c 文件),并且使用默认的命令来构建这个目标文件。
目录中 makefile 文件内容如下
# 这是一个完整的 makefile 文件
calc:add.o div.o main.o mult.o sub.o
gcc add.o div.o main.o mult.o sub.o -o calc
通过 make 构建项目:
$ make
cc -c -o add.o add.c
cc -c -o div.o div.c
cc -c -o main.o main.c
cc -c -o mult.o mult.c
cc -c -o sub.o sub.c
gcc add.o div.o main.o mult.o sub.o -o calc
我们可以发现上边的 makefile 文件中只有一条规则,依赖中所有的 .o 文件在本地项目目录中是不存在的,并且也没有其他的规则用来生成这些依赖文件,这时候 make 会使用内部默认的构造规则先将这些依赖文件生成出来,然后在执行规则中的命令,最后生成目标文件 calc。
3. 变量
使用 Makefile 进行规则定义的时候,为了写起来更加灵活,我们可以在里边使用变量。makefile 中的变量分为三种:自定义变量,预定义变量和自动变量。
3.1 自定义变量
用 Makefile 进行规则定义的时候,用户可以定义自己的变量,称为用户自定义变量。makefile 中的变量是没有类型的,直接创建变量然后给其赋值就可以了。
# 错误, 只创建了变量名, 没有赋值
变量名
# 正确, 创建一个变量名并且给其赋值
变量名=变量值
在给 makefile 中的变量赋值之后,如何在需要的时候将变量值取出来呢?
# 如果将变量的值取出?
$(变量的名字)
# 举例 add.o div.o main.o mult.o sub.o
# 定义变量并赋值
obj=add.o div.o main.o mult.o sub.o
# 取变量的值
$(obj)
自定义变量使用举例:
# 这是一个规则,普通写法
calc:add.o div.o main.o mult.o sub.o
gcc add.o div.o main.o mult.o sub.o -o calc
# 这是一个规则,里边使用了自定义变量
obj=add.o div.o main.o mult.o sub.o
target=calc
$(target):$(obj)
gcc $(obj) -o $(target)
3.2 预定义变量
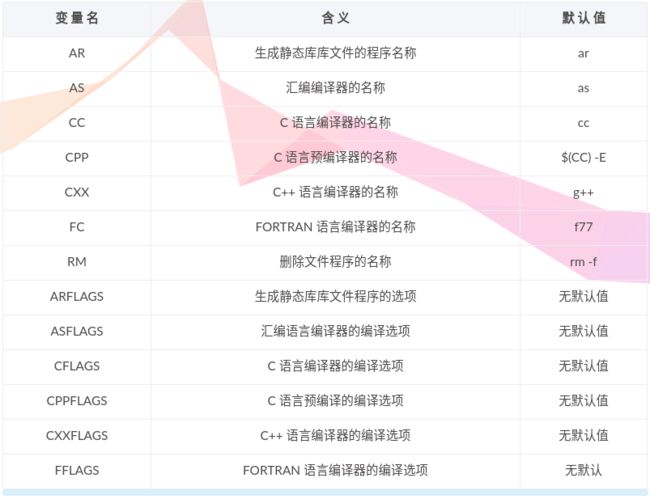
在 Makefile 中有一些已经定义的变量,用户可以直接使用这些变量,不用进行定义。在进行编译的时候,某些条件下 Makefile 会使用这些预定义变量的值进行编译。这些预定义变量的名字一般都是大写的,经常采用的预定义变量如下表所示:
# 这是一个规则,普通写法
calc:add.o div.o main.o mult.o sub.o
gcc add.o div.o main.o mult.o sub.o -o calc
# 这是一个规则,里边使用了自定义变量和预定义变量
obj=add.o div.o main.o mult.o sub.o
target=calc
CFLAGS=-O3 # 代码优化
$(target):$(obj)
$(CC) $(obj) -o $(target) $(CFLAGS)
3.3 自动变量
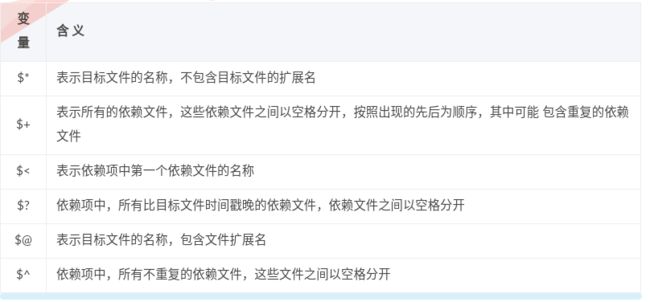
Makefile 中的变量除了用户自定义变量和预定义变量外,还有一类自动变量。Makefile 中的规则语句中经常会出现目标文件和依赖文件,自动变量用来代表这些规则中的目标文件和依赖文件,并且它们只能在规则的命令中使用。
下表中是一些常见的自动变量。
# 这是一个规则,普通写法
calc:add.o div.o main.o mult.o sub.o
gcc add.o div.o main.o mult.o sub.o -o calc
# 这是一个规则,里边使用了自定义变量
# 使用自动变量, 替换相关的内容
calc:add.o div.o main.o mult.o sub.o
gcc $^ -o $@ # 自动变量只能在规则的命令中使用
4. 模式匹配
在介绍概念之前,先读一下下面的这个 makefile 文件:
calc:add.o div.o main.o mult.o sub.o
gcc add.o div.o main.o mult.o sub.o -o calc
# 语法格式重复的规则, 将 .c -> .o, 使用的命令都是一样的 gcc *.c -c
add.o:add.c
gcc add.c -c
div.o:div.c
gcc div.c -c
main.o:main.c
gcc main.c -c
sub.o:sub.c
gcc sub.c -c
mult.o:mult.c
gcc mult.c -c
在阅读过程中能够发现从第二个规则开始到第六个规则做的是相同的事情,但是由于文件名不同不得不在文件中写出多个规则,这就让 makefile 文件看起来非常的冗余,我们可以将这一系列的相同操作整理成一个模板,所有类似的操作都通过模板去匹配 makefile 会因此而精简不少,只是可读性会有所下降。
这个规则模板可以写成下边的样子,这种操作就称之为模式匹配。
# 模式匹配 -> 通过一个公式, 代表若干个满足条件的规则
# 依赖有一个, 后缀为.c, 生成的目标是一个 .o 的文件, % 是一个通配符, 匹配的是文件名
%.o:%.c
gcc $< -c

5.函数
makefile 中有很多函数并且所有的函数都是有返回值的。makefile 中函数的格式和 C/C++ 中函数也不同,其写法是这样的: $(函数名 参数1, 参数2, 参数3, …),主要目的是让我们能够快速方便的得到函数的返回值。
这里为大家介绍两个 makefile 中使用频率比较高的函数:wildcard 和 patsubst。
5.1 wildcard
这个函数的主要作用是获取指定目录下指定类型的文件名,其返回值是以空格分割的、指定目录下的所有符合条件的文件名列表。函数原型如下:
# 该函数的参数只有一个, 但是这个参数可以分成若干个部分, 通过空格间隔
$(wildcard PATTERN...)
参数: 指定某个目录, 搜索这个路径下指定类型的文件,比如: *.c
- 参数功能:
- PATTERN 指的是某个或多个目录下的对应的某种类型的文件,比如当前目录下的.c 文件可以写成 *.c
- 可以指定多个目录,每个路径之间使用空格间隔
- 返回值:
- 得到的若干个文件的文件列表, 文件名之间使用空格间隔
- 示例:$(wildcard .c ./sub/.c)
- 返回值格式: a.c b.c c.c d.c e.c f.c ./sub/aa.c ./sub/bb.c
# 使用举例: 分别搜索三个不同目录下的 .c 格式的源文件
src = $(wildcard /home/robin/a/*.c /home/robin/b/*.c *.c) # *.c == ./*.c
# 返回值: 得到一个大的字符串, 里边有若干个满足条件的文件名, 文件名之间使用空格间隔
/home/robin/a/a.c /home/robin/a/b.c /home/robin/b/c.c /home/robin/b/d.c e.c f.c
5.2 patsubst
这个函数的功能是按照指定的模式替换指定的文件名的后缀,函数原型如下:
# 有三个参数, 参数之间使用 逗号间隔
$(patsubst ,,)
- 参数功能:
- pattern: 这是一个模式字符串,需要指定出要被替换的文件名中的后缀是什么
- 文件名和路径不需要关心,因此使用 % 表示即可 [通配符是 %]
- 在通配符后边指定出要被替换的后缀,比如: %.c, 意味着 .c 的后缀要被替换掉
- replacement: 这是一个模式字符串,指定参数 pattern 中的后缀最终要被替换为什么
- 还是使用 % 来表示参数 pattern 中文件的路径和名字
- 在通配符 % 后边指定出新的后缀名,比如: %.o 这表示原来的后缀被替换为 .o
- text: 该参数中存储这要被替换的原始数据
- 返回值:
- 函数返回被替换过后的字符串。
- pattern: 这是一个模式字符串,需要指定出要被替换的文件名中的后缀是什么
函数使用举例:
src = a.cpp b.cpp c.cpp e.cpp
# 把变量 src 中的所有文件名的后缀从 .cpp 替换为 .o
obj = $(patsubst %.cpp, %.o, $(src))
# obj 的值为: a.o b.o c.o e.o
6. makefile 的编写
下面基于一个简单的项目,为大家演示一下编写一个 makefile 从不标准到标准的进化过程。
# 项目目录结构
.
├── add.c
├── div.c
├── head.h
├── main.c
├── mult.c
└── sub.c
# 需要编写makefile对该项目进行自动化编译
6.1 版本 1
calc:add.c div.c main.c mult.c sub.c
gcc add.c div.c main.c mult.c sub.c -o calc
这个版本的优点:书写简单
这版本的缺点:只要依赖中的某一个源文件被修改,所有的源文件都需要被重新编译,太耗时、效率低
改进方式:提高效率,修改哪一个源文件,哪个源文件被重新编译,不修改就不重新编译
6.2 版本 2
# 默认所有的依赖都不存在, 需要使用其他规则生成这些依赖
# 因为 add.o 被更新, 需要使用最新的依赖, 生成最新的目标
calc:add.o div.o main.o mult.o sub.o
gcc add.o div.o main.o mult.o sub.o -o calc
# 如果修改了add.c, add.o 被重新生成
add.o:add.c
gcc add.c -c
div.o:div.c
gcc div.c -c
main.o:main.c
gcc main.c -c
sub.o:sub.c
gcc sub.c -c
mult.o:mult.c
gcc mult.c -c
这个版本的优点:相较于版本 1 效率提升了
这个版本的缺点:规则比较冗余,需要精简
改进方式:在 makefile 中使用变量 和 模式匹配
6.3 版本 3
# 添加自定义变量 -> makefile中注释前 使用 #
obj=add.o div.o main.o mult.o sub.o
target=calc
$(target):$(obj)
gcc $(obj) -o $(target)
%.o:%.c
gcc $< -c
这个版本的优点:文件精简不少,变得简洁了
这个版本的缺点:变量 obj 的值需要手动的写出来,如果需要编译的项目文件很多,都用手写出来不现实
改进方式:在 makefile 中使用函数
6.4 版本 4
# 添加自定义变量 -> makefile中注释前 使用 #
# 使用函数搜索当前目录下的源文件 .c
src=$(wildcard *.c)
# 将源文件的后缀替换为 .o
# % 匹配的内容是不能被替换的, 需要替换的是第一个参数中的后缀, 替换为第二个参数中指定的后缀
# obj=$(patsubst %.cpp, %.o, $(src)) 将src中的关键字 .cpp 替换为 .o
obj=$(patsubst %.c, %.o, $(src))
target=calc
$(target):$(obj)
gcc $(obj) -o $(target)
%.o:%.c
gcc $< -c
这个版本的优点:解决了自动加载项目文件的问题,解放了双手
这个版本的缺点:没有文件删除的功能,不能删除项目编译过程中生成的目标文件(*.o)和可执行程序
改进方式:在 makefile 文件中添加新的规则用于删除生成的目标文件(*.o)和可执行程序
6.5 版本 5
# 添加自定义变量 -> makefile中注释前 使用 #
# 使用函数搜索当前目录下的源文件 .c
src=$(wildcard *.c)
# 将源文件的后缀替换为 .o
obj=$(patsubst %.c, %.o, $(src))
target=calc
# obj 的值 xxx.o xxx.o xxx.o xx.o
$(target):$(obj)
gcc $(obj) -o $(target)
%.o:%.c
gcc $< -c
# 添加规则, 删除生成文件 *.o 可执行程序
# 这个规则比较特殊, clean根本不会生成, 这是一个伪目标
clean:
rm $(obj) $(target)
这个版本的优点:添加了新的规则(16 行)用于文件的删除,直接 make clean 就可以执行规则中的删除命令了
这个版本的缺点:在下面有具体的问题演示和分析
改进方式:在 makefile 文件中声明 clean 是一个伪目标,让 make 放弃对它的时间戳检测。
正常情况下这个版本的 makefile 是可以正常工作的,但是我们如果在这个项目目录中添加一个叫做 clean 的文件(和规则中的目标名称相同),再进行 make clean 发现这个规则就不能正常工作了。
# 在项目目录中添加一个叫 clean的文件, 然后在 make clean 这个规则中的命令就不工作了
$ ls
add.c calc div.c head.h main.o mult.c sub.c
add.o div.o main.c makefile mult.o sub.o clean ---> 新添加的
# 使用 makefile 中的规则删除生成的目标文件和可执行程序
$ make clean
make: 'clean' is up to date.
# 查看目录, 发现相关文件并没有被删除, make clean 失败了
$ ls
add.c calc div.c head.h main.o mult.c sub.c
add.o clean div.o main.c makefile mult.o sub.o
这个问题的关键点在于 clean 是一个伪目标,不对应任何实体文件,在前边讲关于文件时间戳更新问题的时候说过,如果目标不存在规则的命令肯定被执行, 如果目标文件存在了就需要比较规则中目标文件和依赖文件的时间戳,满足条件才执行规则的命令,否则不执行。
解决这个问题需要在 makefile 中声明 clean 是一个伪目标,这样 make 就不会对文件的时间戳进行检测,规则中的命令也就每次都会被执行了。
在 makefile 中声明一个伪目标需要使用 .PHONY 关键字,声明方式为: .PHONY:伪文件名称
6.6 最终版
# 添加自定义变量 -> makefile中注释前 使用 #
# 使用函数搜索当前目录下的源文件 .c
src=$(wildcard *.c)
# 将源文件的后缀替换为 .o
obj=$(patsubst %.c, %.o, $(src))
target=calc
$(target):$(obj)
gcc $(obj) -o $(target)
%.o:%.c
gcc $< -c
# 添加规则, 删除生成文件 *.o 可执行程序
# 声明clean为伪文件
.PHONY:clean
clean:
# shell命令前的 - 表示强制这个指令执行, 如果执行失败也不会终止。默认情况下如果第一条命令失败以后,不会继续往下执行了。
-rm $(obj) $(target)
echo "hello, 我是测试字符串"
7. 练习题
# 目录结构
.
├── include
│ └── head.h ==> 头文件, 声明了加减乘除四个函数
├── main.c ==> 测试程序, 调用了head.h中的函数
└── src
├── add.c ==> 加法运算
├── div.c ==> 除法运算
├── mult.c ==> 乘法运算
└── sub.c ==> 减法运算
根据上边的项目目录结构编写的 makefile 文件如下:
# 最终的目标名 app
target = app
# 搜索当前项目目录下的源文件
src=$(wildcard *.c ./src/*.c)
# 将文件的后缀替换掉 .c -> .o
obj=$(patsubst %.c, %.o, $(src))
# 头文件目录
include=./include
# 第一条规则
# 依赖中都是 xx.o yy.o zz.o
# gcc命令执行的是链接操作
$(target):$(obj)
gcc $^ -o $@
# 模式匹配规则
# 执行汇编操作, 前两步: 预处理, 编译是自动完成
%.o:%.c
gcc $< -c -I $(include) -o $@
# 添加一个清除文件的规则
.PHONY:clean
clean:
-rm $(obj) $(target) -f
十、GDB调试
gdb 是由 GNU 软件系统社区提供的调试器,同 gcc 配套组成了一套完整的开发环境,可移植性很好,支持非常多的体系结构并被移植到各种系统中(包括各种类 Unix 系统与 Windows 系统里的 MinGW 和 Cygwin )。此外,除了 C 语言之外,gcc/gdb 还支持包括 C++、Objective-C、Ada 和 Pascal 等各种语言后端的编译和调试。 gcc/gdb 是 Linux 和许多类 Unix 系统中的标准开发环境,Linux 内核也是专门针对 gcc 进行编码的。
gdb 的吉祥物是专门捕杀 bug 的射手鱼,官方有这样一段描述:
For a fish, the archer fish is known to shoot down bugs from low hanging plants by spitting water at them.
作为一种鱼,射手鱼以喷水射下低垂的植物上的虫子而闻名。
GDB 是一套字符界面的程序集,可以使用命令 gdb 加载要调试的程序。 下面为大家介绍一些常用的 GDB 调试命令。
1.调试准备
项目程序如果是为了进行调试而编译时, 必须要打开调试选项 (-g)。另外还有一些可选项,比如:在尽量不影响程序行为的情况下关掉编译器的优化选项 (-O0),-Wall 选项打开所有 warning,也可以发现许多问题,避免一些不必要的 bug。
-g 选项的作用是在可执行文件中加入源代码的信息,比如可执行文件中第几条机器指令对应源代码的第几行,但并不是把整个源文件嵌入到可执行文件中,所以在调试时必须保证 gdb 能找到源文件。
习惯上如果是 c程序就使用 gcc 编译,如果是 c++ 程序就使用 g++ 编译,编译命令中添加上边提到的参数即可。
假设有一个文件 args.c, 要对其进行gdb调试,编译的时候必须要添加参数 -g,加入了源代码信息的可执行文件比不加之前要大一些。
# -g 将调试信息写入到可执行程序中
$ gcc -g args.c -o app
# 编译不添加 -g 参数
$ gcc args.c -o app1
# 查看生成的两个可执行程序的大小
$ ll
-rwxrwxr-x 1 robin robin 9816 Apr 19 09:25 app* # 可以用于gdb调试
-rwxrwxr-x 1 robin robin 8608 Apr 19 09:25 app1* # 不能用于gdb调试
2.启动和退出 gdb
2.1 启动 gdb
gdb 是一个用于应用程序调试的进程,需要先将其打开,一定要注意 gdb进程启动之后, 需要的被调试的应用程序是没有执行的。打开 Linux 终端,切换到要调试的可执行程序所在路径,执行如下命令就可以启动 gdb 了。
# 在终端中执行如下命令
# gdb程序启动了, 但是可执行程序并没有执行
$ gdb 可执行程序的名字
# 使用举例:
$ gdb app
(gdb) # gdb等待输入调试的相关命令
2.2 命令行传参
有些程序在启动的时候需要传递命令行参数,如果要调试这类程序,这些命令行参数必须要在应用程序启动之前通过调试程序的 gdb 进程传递进去。下面是一段带命令行参数的程序:
// args.c
#include
#include
#include
#include
#define NUM 10
// argc, argv 是命令行参数
// 启动应用程序的时候
int main(int argc, char* argv[])
{
printf("参数个数: %d\n", argc);
for(int i=0; i 第一步:编译出带条信息的可执行程序
第一步:编译出带条信息的可执行程序
$ gcc args.c -o app -g
第二步:启动 gdb 进程,指定需要 gdb 调试的应用程序名称
$ gdb app
(gdb)
第三步:在启动应用程序 app 之前设置命令行参数。gdb 中设置参数的命令叫做 set args …,查看设置的命令行参数命令是 show args。 语法格式如下:
# 设置的时机: 启动gdb之后, 在应用程序启动之前
(gdb) set args 参数1 参数2 .... ...
# 查看设置的命令行参数
(gdb) show args
使用举例:
# 非gdb调试命令行传参
# argc 参数总个数,argv[0] == ./app, argv[1] == "11" argv[2] == "22" ... argv[5] == "55"
$ ./app 11 22 33 44 55 # 这是数据传递给main函数
# 使用 gdb 调试
$ gdb app
GNU gdb (Ubuntu 7.11.1-0ubuntu1~16.5) 7.11.1
Copyright (C) 2016 Free Software Foundation, Inc.
# 通过gdb给应用程序设置命令行参数
(gdb) set args 11 22 33 44 55
# 查看设置的命令行参数
(gdb) show args
Argument list to give program being debugged when it is started is "11 22 33 44 55".
2.3 gdb 中启动程序
在 gdb 中启动要调试的应用程序有两种方式,一种是使用 run 命令,另一种是使用 start 命令启动。在整个 gdb 调试过程中,启动应用程序的命令只能使用一次。
- run: 可以缩写为 r, 如果程序中设置了断点会停在第一个断点的位置,如果没有设置断点,程序就执行完了
- start: 启动程序,最终会阻塞在 main 函数的第一行,等待输入后续其它 gdb 指令
# 两种方式
# 方式1: run == r
(gdb) run
# 方式2: start
(gdb) start
如果想让程序 start 之后继续运行,或者在断点处继续运行,可以使用 continue 命令,可以简写为 c
# continue == c
(gdb) continue
2.4 退出 gdb
退出 gdb 调试,就是终止 gdb 进程,需要使用 quit 命令,可以缩写为 q
# quit == q
(gdb) quit
3.查看代码
因为 gdb 调试没有 IDE 那样的完善的可视化窗口界面,给调试的程序打断点又是调试之前必须做的一项工作。因此 gdb 提供了查看代码的命令,这样就可以轻松定位要调试的代码行的位置了。
查看代码的命令叫做 list 可以缩写为 l, 通过这个命令我们可以查看项目中任意一个文件中的内容,并且还可以通过文件行号,函数名等方式查看。
3.1 当前文件
一个项目中一般是有很多源文件的,默认情况下通过 list 查看到代码信息位于程序入口函数 main 对应的的那个文件中。因此如果不进行文件切换 main 函数所在的文件就是当前文件,如果进行了文件切换,切换到哪个文件哪个文件就是当前文件。查看文件内容的方式如下:
# 使用 list 和使用 l 都可以
# 从第一行开始显示
(gdb) list
# 列值这行号对应的上下文代码, 默认情况下只显示10行内容
(gdb) list 行号
# 显示这个函数的上下文内容, 默认显示10行
(gdb) list 函数名
通过 list 去查看文件代码,默认只显示 10 行,如果还想继续查看后边的内容,可以继续执行 list 命令,也可以直接回车(再次执行上一次执行的那个 gdb 命令)。
3.2 切换文件
在查看文件内容的时候,很多情况下需要进行文件切换,我们只需要在 list 命令后边将要查看的文件名指定出来就可以了,切换命令执行完毕之后,这个文件就变成了当前文件。文件切换方式如下:
# 切换到指定的文件,并列出这行号对应的上下文代码, 默认情况下只显示10行内容
(gdb) l 文件名:行号
# 切换到指定的文件,并显示这个函数的上下文内容, 默认显示10行
(gdb) l 文件名:函数名
3.3 设置显示的行数
默认通过 list 只能一次查看 10 行代码,如果想显示更多,可以通过 set listsize 设置,同样如果想查看当前显示的行数可以通过 show listsize 查看,这里的 listsize 可以简写为 list。具体语法格式如下:
# 以下两个命令中的 listsize 都可以写成 list
(gdb) set listsize 行数
# 查看当前list一次显示的行数
(gdb) show listsize
4.断点操作
想要通过 gdb 调试某一行或者得到某个变量在运行状态下的实际值,就需要在在这一行设置断点,程序指定到断点的位置就会阻塞,我们就可以通过 gdb 的调试命令得到我们想要的信息了。
设置断点的命令叫做 break 可以缩写为 b。
4.1 设置断点
断点的设置有两种方式一种是常规断点,程序只要运行到这个位置就会被阻塞,还有一种叫条件断点,只有指定的条件被满足了程序才会在断点处阻塞。
调试程序的断点可以设置到某个具体的行,也可以设置到某个函数上,具体的设置方式如下:
- 设置普通断点到当前文件
# 在当前文件的某一行上设置断点
# break == b
(gdb) b 行号
(gdb) b 函数名 # 停止在函数的第一行
- 设置普通断点到某个非当前文件上
# 在非当前文件的某一行上设置断点
(gdb) b 文件名:行号
(gdb) b 文件名:函数名 # 停止在函数的第一行
- 设置条件断点
# 必须要满足某个条件, 程序才会停在这个断点的位置上
# 通常情况下, 在循环中条件断点用的比较多
(gdb) b 行数 if 变量名==某个值
4.2 查看断点
断点设置完毕之后,可以通过 info break 命令查看设置的断点信息,其中 info 可以缩写为 i
# info == i
# 查看设置的断点信息
(gdb) i b #info break
# 举例
(gdb) i b
Num Type Disp Enb Address What
1 breakpoint keep y 0x0000000000400cb5 in main() at test.cpp:12
2 breakpoint keep y 0x0000000000400cbd in main() at test.cpp:13
3 breakpoint keep y 0x0000000000400cec in main() at test.cpp:18
4 breakpoint keep y 0x00000000004009a5 in insertionSort(int*, int)
at insert.cpp:8
5 breakpoint keep y 0x0000000000400cdd in main() at test.cpp:16
6 breakpoint keep y 0x00000000004009e5 in insertionSort(int*, int)
at insert.cpp:16
在显示的断点信息中有一些属性需要在其他操作中被使用,下面介绍一下:
- Num: 断点的编号,删除断点或者设置断点状态的时候都需要使用
- Enb: 当前断点的状态,y 表示断点可用,n 表示断点不可用
- What: 描述断点被设置在了哪个文件的哪一行或者哪个函数上
4.3 删除断点
如果确定设置的某个断点不再被使用了,可用将其删除,删除命令是 delete 断点编号 , 这个 delete 可以简写为 del 也可以再简写为 d。
删除断点的方式有两种: 删除(一个或者多个)指定断点或者删除一个连续的断点区间,具体操作如下:
# delete == del == d
# 需要 info b 查看断点的信息, 第一列就是编号
(gdb) d 断点的编号1 [断点编号2 ...]
# 举例:
(gdb) d 1 # 删除第1个断点
(gdb) d 2 4 6 # 删除第2,4,6个断点
# 删除一个范围, 断点编号 num1 - numN 是一个连续区间
(gdb) d num1-numN
# 举例, 删除第1到第5个断点
(gdb) d 1-5
4.4 设置断点状态
如果某个断点只是临时不需要了,我们可以将其设置为不可用状态,设置命令为 disable 断点编号,当需要的时候再将其设置回可用状态,设置命令为 enable 断点编号。
- 设置断点无效
# 让断点失效之后, gdb调试过程中程序是不会停在这个位置的
# disable == dis
# 设置某一个或者某几个断点无效
(gdb) dis 断点1的编号 [断点2的编号 ...]
# 设置某个区间断点无效
(gdb) dis 断点1编号-断点n编号
演示设置断点为无效状态:enable == ena
设置某一个或者某几个断点有效
(gdb) ena 断点1的编号 [断点2的编号 …]
设置某个区间断点有效
(gdb) ena 断点1编号-断点n编号
# 查看断点信息
(gdb) i b
Num Type Disp Enb Address What
2 breakpoint keep y 0x0000000000400cce in main() at test.cpp:14
4 breakpoint keep y 0x0000000000400cdd in main() at test.cpp:16
5 breakpoint keep y 0x0000000000400d46 in main() at test.cpp:23
6 breakpoint keep y 0x0000000000400d4e in main() at test.cpp:25
7 breakpoint keep y 0x0000000000400d6e in main() at test.cpp:28
8 breakpoint keep y 0x0000000000400d7d in main() at test.cpp:30
# 设置第2, 第4 个断点无效
(gdb) dis 2 4
# 查看断点信息
(gdb) i b
Num Type Disp Enb Address What
2 breakpoint keep n 0x0000000000400cce in main() at test.cpp:14
4 breakpoint keep n 0x0000000000400cdd in main() at test.cpp:16
5 breakpoint keep y 0x0000000000400d46 in main() at test.cpp:23
6 breakpoint keep y 0x0000000000400d4e in main() at test.cpp:25
7 breakpoint keep y 0x0000000000400d6e in main() at test.cpp:28
8 breakpoint keep y 0x0000000000400d7d in main() at test.cpp:30
# 设置 第5,6,7,8个 断点无效
(gdb) dis 5-8
# 查看断点信息
(gdb) i b
Num Type Disp Enb Address What
2 breakpoint keep n 0x0000000000400cce in main() at test.cpp:14
4 breakpoint keep n 0x0000000000400cdd in main() at test.cpp:16
5 breakpoint keep n 0x0000000000400d46 in main() at test.cpp:23
6 breakpoint keep n 0x0000000000400d4e in main() at test.cpp:25
7 breakpoint keep n 0x0000000000400d6e in main() at test.cpp:28
8 breakpoint keep n 0x0000000000400d7d in main() at test.cpp:30
- 让无效的断点生效
# enable == ena
# 设置某一个或者某几个断点有效
(gdb) ena 断点1的编号 [断点2的编号 ...]
# 设置某个区间断点有效
(gdb) ena 断点1编号-断点n编号
演示设置断点为有效状态:
# 查看断点信息
(gdb) i b
Num Type Disp Enb Address What
2 breakpoint keep n 0x0000000000400cce in main() at test.cpp:14
4 breakpoint keep n 0x0000000000400cdd in main() at test.cpp:16
5 breakpoint keep n 0x0000000000400d46 in main() at test.cpp:23
6 breakpoint keep n 0x0000000000400d4e in main() at test.cpp:25
7 breakpoint keep n 0x0000000000400d6e in main() at test.cpp:28
8 breakpoint keep n 0x0000000000400d7d in main() at test.cpp:30
# 设置第2, 第4个断点有效
(gdb) ena 2 4
# 查看断点信息
(gdb) i b
Num Type Disp Enb Address What
2 breakpoint keep y 0x0000000000400cce in main() at test.cpp:14
4 breakpoint keep y 0x0000000000400cdd in main() at test.cpp:16
5 breakpoint keep n 0x0000000000400d46 in main() at test.cpp:23
6 breakpoint keep n 0x0000000000400d4e in main() at test.cpp:25
7 breakpoint keep n 0x0000000000400d6e in main() at test.cpp:28
8 breakpoint keep n 0x0000000000400d7d in main() at test.cpp:30
# 设置第5,6,7个断点有效
(gdb) ena 5-7
# 查看断点信息
(gdb) i b
Num Type Disp Enb Address What
2 breakpoint keep y 0x0000000000400cce in main() at test.cpp:14
4 breakpoint keep y 0x0000000000400cdd in main() at test.cpp:16
5 breakpoint keep y 0x0000000000400d46 in main() at test.cpp:23
6 breakpoint keep y 0x0000000000400d4e in main() at test.cpp:25
7 breakpoint keep y 0x0000000000400d6e in main() at test.cpp:28
8 breakpoint keep n 0x0000000000400d7d in main() at test.cpp:30
5.调试命令
5.1 继续运行 gdb
如果调试的程序被断点阻塞了又想让程序继续执行,这时候就可以使用 continue 命令。程序会继续运行,直到遇到下一个有效的断点。continue 可以缩写为 c。
# continue == c
(gdb) continue
5.2 手动打印信息
当程序被某个断点阻塞之后,可以通过一些命令打印变量的名字或者变量的类型,并且还可以跟踪打印某个变量的值。
5.2.1 打印变量值
在 gdb 调试的时候如果需要打印变量的值, 使用的命令是 print, 可缩写为 p。如果打印的变量是整数还可以指定输出的整数的格式,格式化输出的整数对应的字符表如下:
格式化字符 (/fmt) 说明
/x 以十六进制的形式打印出整数。
/d 以有符号、十进制的形式打印出整数。
/u 以无符号、十进制的形式打印出整数。
/o 以八进制的形式打印出整数。
/t 以二进制的形式打印出整数。
/f 以浮点数的形式打印变量或表达式的值。
/c 以字符形式打印变量或表达式的值。
print 命令的语法格式如下:
# print == p
(gdb) p 变量名
# 如果变量是一个整形, 默认对应的值是以10进制格式输出, 其他格式请参考上表
(gdb) p/fmt 变量名
举例:
# 举例
(gdb) p i # 10进制
$5 = 3
(gdb) p/x i # 16进制
$6 = 0x3
(gdb) p/o i # 8进制
$7 = 03
5.2.2 打印变量类型
如果在调试过程中需要查看某个变量的类型,可以使用命令 ptype, 语法格式如下:
# 语法格式
(gdb) ptype 变量名
举例:
# 打印变量类型
(gdb) ptype i
type = int
(gdb) ptype array[i]
type = int
(gdb) ptype array
type = int [12]
5.3 自动打印信息
5.3.1 设置变量名自动显示
和 print 命令一样,display 命令也用于调试阶段查看某个变量或表达式的值,它们的区别是,使用 display 命令查看变量或表达式的值,每当程序暂停执行(例如单步执行)时,GDB 调试器都会自动帮我们打印出来,而 print 命令则不会。因此,当我们想频繁查看某个变量或表达式的值从而观察它的变化情况时,使用 display 命令可以一劳永逸。display 命令没有缩写形式,常用的语法格式如下 2 种:
# 在变量的有效取值范围内, 自动打印变量的值(设置一次, 以后就会自动显示)
(gdb) display 变量名
# 以指定的整形格式打印变量的值, 关于 fmt 的取值, 请参考 print 命令
(gdb) display/fmt 变量名
5.3.2 查看自动显示列表
对于使用 display 命令查看的目标变量或表达式,都会被记录在一张列表(称为自动显示列表)中。通过执行 info dispaly 命令,可以打印出这张表:
# info == i
(gdb) info display
Auto-display expressions now in effect:
Num Enb Expression
1: y i
2: y array[i]
3: y /x array[i]
在展示出的信息中,每个列的含义如下:
- Num : 变量或表达式的编号,GDB 调试器为每个变量或表达式都分配有唯一的编号
- Enb : 表示当前变量(表达式)是处于激活状态还是禁用状态,如果处于激活状态(用 y 表示),则每次程序停止执行,该变量的值都会被打印出来;反之,如果处于禁用状态(用 n 表示),则该变量(表达式)的值不会被打印。
- Expression :被自动打印值的变量或表达式的名字。
5.3.3 取消自动显示
对于不需要再打印值的变量或表达式,可以将其删除或者禁用。
删除自动显示列表中的变量或表达式
# 命令中的 num 是通过 info display 得到的编号, 编号可以是一个或者多个
(gdb) undisplay num [num1 ...]
# num1 - numN 表示一个范围
(gdb) undisplay num1-numN
(gdb) delete display num [num1 ...]
(gdb) delete display num1-numN
举例说明:
# 查看显示列表
(gdb) info display
Auto-display expressions now in effect:
Num Enb Expression
1: y i
2: y array[i]
3: y /x array[i]
# 删除变量显示, 需要使用 info display 得到的变量/表达式编号
(gdb) undisplay 1 2
# 查看显示列表, 只剩下一个了
(gdb) i display
Auto-display expressions now in effect:
Num Enb Expression
3: y /x array[i]
如果不想删除自动显示的变量,也可以禁用自动显示列表中处于激活状态下的变量或表达式
# 命令中的 num 是通过 info display 得到的编号, 编号可以是一个或者多个
(gdb) disable display num [num1 ...]
# num1 - numN 表示一个范围
(gdb) disable display num1-numN
当需要启用自动显示列表中被禁用的变量或表达式时,可以使用下边的命令
# 命令中的 num 是通过 info display 得到的编号, 编号可以是一个或者多个
(gdb) enable display num [num1 ...]
# num1 - numN 表示一个范围
(gdb) enable display num1-numN
5.3 单步调试
当程序阻塞到某个断点上之后,可以通过以下命令对程序进行单步调试:
5.3.1 step
step 命令可以缩写为 s, 命令被执行一次代码被向下执行一行,如果这一行是一个函数调用,那么程序会进入到函数体内部。
# 从当前代码行位置, 一次调试当前行下的每一行代码
# step == s
# 如果这一行是函数调用, 执行这个命令, 就可以进入到函数体的内部
(gdb) step
5.3.2 finish
如果通过 s 单步调试进入到函数内部,想要跳出这个函数体, 可以执行 finish 命令。如果想要跳出函数体必须要保证函数体内不能有有效断点,否则无法跳出。
# 如果通过 s 单步调试进入到函数内部, 想要跳出这个函数体
(gdb) finish
5.3.3 next
next 命令和 step 命令功能是相似的,只是在使用 next 调试程序的时候不会进入到函数体内部,next 可以缩写为 n
# next == n
# 如果这一行是函数调用, 执行这个命令, 不会进入到函数体的内部
(gdb) next
5.3.4 until
通过 until 命令可以直接跳出某个循环体,这样就能提高调试效率了。如果想直接从循环体中跳出,必须要满足以下的条件,否则命令不会生效:
- 要跳出的循环体内部不能有有效的断点
- 必须要在循环体的开始 / 结束行执行该命令
(gdb) until
5.4 设置变量值
在调试程序的时候,我们需要在某个变量等于某个特殊值的时候查看程序的运行状态,但是通过程序运行让变量等于这个值又非常困难,这种情况下就可以在 gdb 中直接对这个变量进行值的设置,或者是在单步调试的时候通过设置循环因子的值直接跳出某个循环,值设置的命令格式为: set var 变量名=值
# 可以在循环中使用, 直接设置循环因子的值
# 假设某个变量的值在程序中==90的概率是5%, 这时候可以直接通过命令将这个变量值设置为90
(gdb) set var 变量名=值