Python机器学习期末总复习
目录
人工智能基本概念
KNN分类算法
K-NN源代码
K-means分类算法
K-means源代码
推荐算法概述
回归分析
神经网络基础模型
BP神经网络(Back Propagatioon)
人工智能基本概念
智能的定义
智能是人类智力和能力的总称,智能的核心是思维。
人工智能
是用人工的方法在机器(计算机)上实现的智能,或者说是人使得机器有了类似人的智能
机器学习
是专门研究计算机怎么模拟或实现人类的学习行为,以获得新的知识或技能,重新组织已有的知识结果使得不断改善自身的性能
深度学习
是一种试图使用包含复杂结构或由多重非线性变化构成的多个处理层对数据进行高层抽象的算法
监督学习---非监督学习---强化学习
1、监督学习(Supervised Learning)
监督学习(Supervised Learning)是使用已有的数据进行学习的机器学习方法。已有的数据是成双的——输入数据和对于的输出数据所组成的数据对。算法通过自动分析,找到输入和输出之间的关系,此后对于新的数据,算法也能够自动给出对应的输出结果。
监督学习算法在学习的过程中需要标签,相当于有老师教一样。
分类:如何把手写数字分为十类,根据头发的长短来区分男人,女人 。回归:未来牛肉的价格变化,预测中国人的平均寿命
2、非监督学习
非监督学习直接对没有标记的训练数据进行建模学习,与监督学习的最基本的区别就是建模的数据没有标签。非监督学习算法中,没有经验数据可供学习,算法运行时,只有输入的无标签的数据,需要从这些数据中自动提取出知识或者结论。
聚类就是比较经典的非监督学习,聚类是根据数据的相似性将数据分为多类的过程,通常使用的方法就是计算两个样本之间的距离,使用不同的计算方法计算样本之间的距离会关系到聚类结果的好坏。聚类:如何将学校里面的学生按不同特征将其分为四类
3、强化学习
强化学习属于试错学习,是智能体在与环境的交互过程中通过学习策略以达成回报最大化或实现特点目标。强化学习的核心是评价策略的优劣,从好的动作中学习优的策略,通过更好的策略使得系统输出向更好的方向发展。与监督学习相比,强化学习没有标签,系统只会给算法执行的动作一个评分反馈。即当前的状态决定执行什么动作,最后得到最大的回报。如: -贪心算法,k-摇臂d博机模型,阿尔法狗。
-贪心算法,k-摇臂d博机模型,阿尔法狗。
监督学习————分类学习
输入:一组有标签的训练数据,标签表明了这些数据的类别。
输出:分类模型根据这些训练数据,训练自己的模型参数,学习出一个适合这组数据的分类器,当有新数据(非训练数据)需要进行类别判断,就可以将这组新数据作为输入送给学好的分类器进行判断。
分类学习-评价标准
精确率:
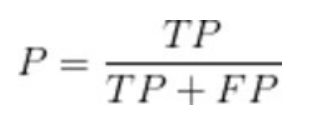
召回率:

准确率:

KNN分类算法
核心思想:KNN属于监督学习的一种,如果一个样本在特征空间中与K个实例最为相似(即特征空间中最相邻近),那么这k个实例大部分属于某一个类别,则该样本也属于这个类别。试用于:分类和回归方法
对于分类问题:对新的样本,根据其K个最近邻的训练样本的类别,通过多数表决等方式进行预测。即根据一组样本预测出它所属的类别。
对于回归问题:对新的样本,根据其k个最相邻的训练样本标签值的均值作为预测值。即根据一组样本预测出一个数量值。
K-近邻法(K-Nearest Neighbor)三要素:k值得选择,距离度量,决策规则
一般流程:
1、计算测试对象到训练集中已经打好标签的每个对象的距离
2、按照距离的远近排序
3、选取与当前测试对象最近的k个训练对象,作为该测试对象的邻居
4、统计这k个邻居的类别频次
5、k个邻居里频次最高的类别,即为测试对象的类别
方便了解下面KNN算法代码,我写的流程
# 第一步:在数据库里面引入数据,预先将样本数据设定不同的类别,我设为 0 类于1类
# 第二步:在数据库中引入待测数据并与已预先设定的个类别进行欧式计算
# 第三步:对计算得到的数据进行排序,然后取计算得到的最小的k个数据
# 第四步:用这个k个数据的计算结果(附带类型),计算出各个类型出现的频次
# 第五步:对频数并排序,最后打印出类别频数最多的类别
K-NN源代码
# 基本数据
x=[0,1,2,3,4,5,6,7,8] # 样本数据
y=[0,0,0,0,1,1,1,1,1] # 样本数据的类别
x0=3.1 # 待测数据
# 算出x0到其他所有值的距离,并将0,1表示的类别与之对应
data=[] #新创建的列表,用于放数据类型和计算得到的距离
for i in range(len(x)):
dis=(x[i]-x0)**2
data.append((y[i],dis)) # 元组有两个数据并入列表中 ,第一个数据为类型,第二个数据为距离
# 根据第二个值来排序
data_one=sorted(data, key=lambda x: x[1]) # 按元组第二个数据进行排序
# 只取距离最近的前三个来比较,选最优的类别
k = 5 # 超参数
data_two=data_one[:k] #只取计算得到的(经过sorted排序了)距离最小的前五位
c={} #新创立的字典,由下面代码可知,key为类别,values为类别出现的次数
for i in data_two: #data_two为列表,该列表包括元组,一个元组里面包含了两个数据
if i[0] in c.keys(): # i[0] 为元组的第零个元素,即类别,i不同则i[0]也不同
c[i[0]]=c[i[0]]+1 # c[i[0]]为字典对应的值,即类别出现的频次
else:
c[i[0]]=1
# 再根据上一步的结果,再进行排序(不排序则是按出现什么情况,进行将什么情况并入字典中,是无序排列的)
type_max=sorted(c.items(), key=lambda x:x[1]) # 返回列表,里面包含元组
print("如果 0,1,2,3 的类别是 0;\n4,5,6,7,8的类别是 1")
print("则x0的类别是:",type_max[-1][-2]) #即倒数第一个值的类别K-means分类算法
K-means算法,也称为K-平均或K-均值,是一种聚类算法。它将各个聚类子集内的所有数据样本的均值作为该聚类的代表点。主要思想:通过迭代过程把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优,从而使生成的每个聚类内更紧凑,类间独立。这一算法不适合处理离散型数据,对噪声数据比较敏感,但是对于连续型具有较好的聚类效果。
聚类算法:保证一个类的样本相似,不同类的样本之间尽量不同。
划分聚类方法对数据集进行聚类时包括三个要点:
1、选定某种距离作为数据样本之间的相似度量。上面讲到,K-means聚类算法不适合处理离散型属性,对连续型数据比较合适。因此在计算数据样本之间的距离时,可以根据实际需要选择欧式距离、曼哈顿距离或者--明考斯-距离中的一种来作为算法的相似性度量。
2、选择评价聚类性能的准则函数。K-means聚类算法使用误差平方和准则函数来评价聚类性能。给定数据集X,其中只包含描述属性,不包含类别属性。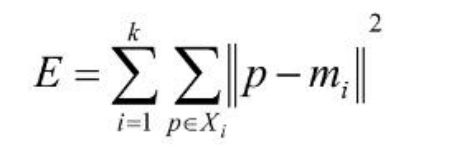
3、相似度的计算根据一个簇中对象的平均值来进行
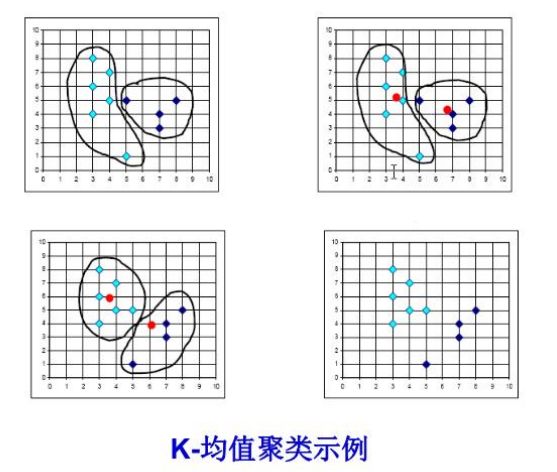
(1)随机选取k个对象作为初始聚类中心;
(2)将数据样本集合中的样本按照最小距离原则分配到最邻近聚类;
(3)根据聚类的结果,重新计算k个聚类的中心,并作为新的聚类中心;
(4)重复步骤2直到聚类中心不再变化;
K-means源代码
算法过程:
(1)随机选取k个对象作为初始聚类中心
(2)将数据样本集合中的样本按照最小距离原则分配到最邻近聚类
(3)根据聚类的结果,重新计算k个聚类的中心,并作为新的聚类中心;
(4)重复步骤2直到聚类中心不再变化
import matplotlib.pyplot as plt
import numpy as np
# 随机选取k个对象作为初始聚类中心
# 1、先列出一组二维数组
z = np.array([[2, 3], [2, 2], [3, 4], [8, 8], [8, 7], [9, 9], [1, 5], [2, 4], [7.9, 7], [8.9, 9], [2, 1], [7, 9]])
# 2,方便画图
x_scatter = [data[0] for data in z] # 取x
y_scatter = [data[1] for data in z] # 取y
# 3,分类 0类,1类
k = [0, 1]
# 3,先给出两个中心点
y_center = np.array([[10, 7], [9, 9]], dtype=np.float64)
y_center_new = np.copy(y_center)
# 将数据样本集合中的样本按照最小距离原则分配到最邻近聚类
# 4,用于判断是否退出
flag = True
# 5,用于后者分类
y_res = np.zeros(len(z))
# 6,用于判断是否退出
tmp = 0
while flag and tmp < 10:
tmp += 1
for i in range(len(z)): # z里面的点数
item = z[i] # z里面每一个数据都是一个列表
d1 = (item[0]-y_center[0][0])**2+(item[1]-y_center[0][1])**2 # 与第一个中心点的欧式距离
d2 = (item[0]-y_center[1][0])**2+(item[1]-y_center[1][1])**2 # 与第二个中心点的欧式距离
if d1 > d2:
y_res[i] = 0
else:
y_res[i] = 1 # 测距分类
y_res_like_0 = [[i, i] for i in y_res] # 二维列表,里面非0即1
temp_center = z*y_res_like_0 # 乘0得0,乘1不变 关键,到后面中心点不会动的原因是,y中分类已经分的固定了,每次计算用都是固定的几个数
y_center_new[0] = np.sum(temp_center, axis=0)/np.sum(y_res) # x坐标所有值求和,y坐标所有值求和,以及得到的y_res(1的求和)
y_res_like_1 = [[1-i, 1-i] for i in y_res] # 二维列表,里面非0即1
temp_center = z*y_res_like_1 # 乘0得0,乘1不变 关键,到后面中心点不会动的原因是,y中分类已经分的固定了,每次计算用都是固定的几个数
y_center_new[1] = np.sum(temp_center, axis=0)/(len(y_res)-np.sum(y_res)) # y_res的总数减去1的总数等于0的总数
# 根据聚类的结果,重新计算k个聚类的中心,并作为新的聚类中心;重复步骤2直到聚类中心不再变化
if(y_center != y_center_new).any(): # 判断前后两次中心点是否相同
y_center = y_center_new
else:
flag = False # 相同直接退出
# 画图
plt.scatter(x_scatter, y_scatter, c='blue', marker='.')
plt.scatter([y_center[0][0], y_center[1][0]], [y_center[0][1], y_center[1][1]], c="red", s=100, marker='*')
plt.title("K-means")
plt.show()
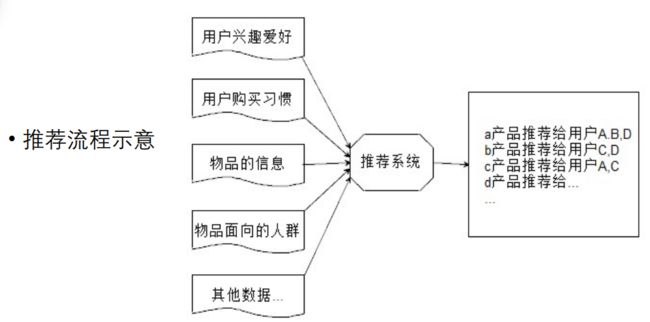
推荐算法概述
随着推荐系统的广泛应用,推荐算法也不断发展。目前来说,推荐算法可以初略分为几个大类:
1、协同过滤推荐算法
· 基于用户的协同过滤算法
· 基于物品的协同过滤算法
2、基于内容的推荐算法
3、基于图结构的推荐算法
4、混合推荐算法
基于用户的协同过滤算法
首先使用特定的方式找到与一个用户相似的用户集合,即他的朋友们,分析这些相似用户的喜好,将这些朋友们喜欢的东西推荐给该用户
算法基于如下假设:如果两个用户对一些项目的评分相似,则他们对其他项目的评分也具有相似性。





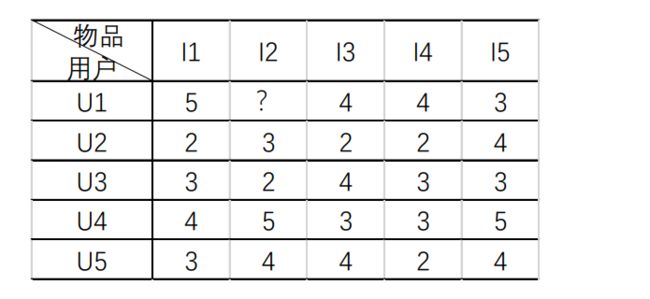
基于物品的的协同过滤算法,类似于上面,简单推导就可得知
回归分析
回归分析(Regression(n.回归,退化)Analysis)是确定两种或两种以上变量之间相互依赖的定量关系的一种统计分析方法,回归属于监视学习方法。
线性回归是一种通过属性的线性组合来进行预测的线性模型,其目的是找到一条直线或者一个平面或者一个更高维的超平面,使得预测值与真实值之间的误差最小化。
神经网络基础模型
人脑神经元模型
神经网络的输出怎么来的?
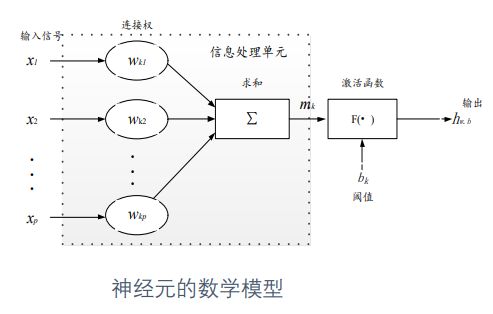
人脑神经元模型有以下三个基本要素
(1)连接加权
(2)求和单元
(3)激活函数
神经网络具有以下特点:是一个信息处理器,里面有多个神经处理单元,可以多输入,多输出;不同的输入对神经处理单元的作用权重不同,可能增强也可能削弱;神经元具有整合的特性;神经元的处理具有方向性。
神经网络需要遵循以下原则:
(1)同一层的神经元之间没有连接
(2)上一层的输出是下一层的输入
(3)每个连接都有一个权值
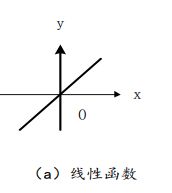
激活函数 :常用的激活函数主要有,线性函数,非线性函数,概率型函数
神经元和感受器本质上是一样的,只不过我们说感知器的时候,它的激活函数是阶跃函数;而当我们说神经元时,激活函数往往选择为sigmoid函数等函数
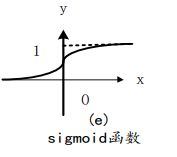
Sigmoid函数:
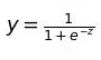
S型函数(如Sigmoid函数)让函数的输出有一定的局限范围,有最大值和最小值。
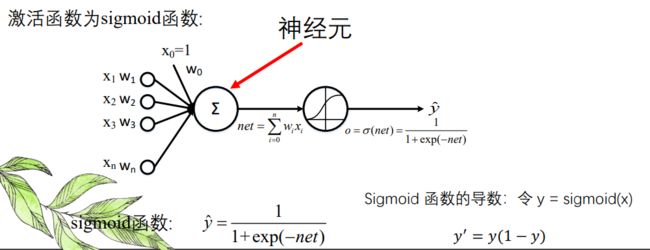
神经元的数学模型示意图:
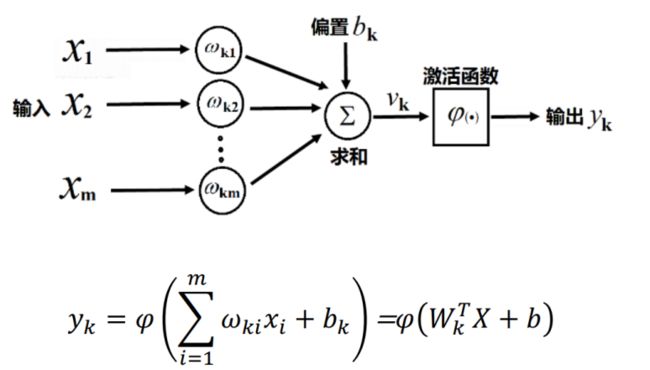
整体思路:
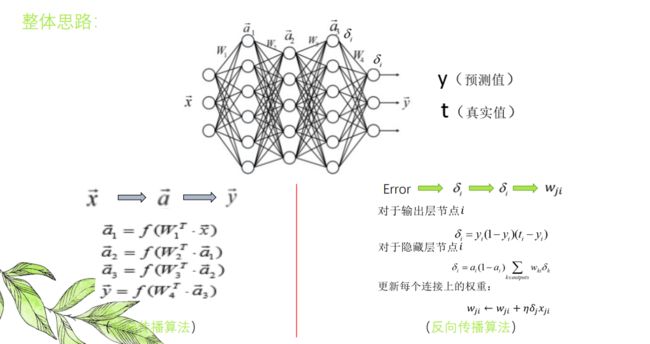
前向传播算法:

BP神经网络(Back Propagatioon)
反向传播(back propagation)算法也称BP神经网络,是一种带有反馈的神经网络反向学习方法。
BP神经网络学习过程:
1、神经网络初始化。包括为各个连接权重赋予初始值,设定内部函数,设定误差函数、给定预期精度,以及设置最大迭代次数等。
2、将数据输入神经网络,计算输出结果
3、求输出结果与预期值的差,作出误差
4、将误差回传到与输出层相邻的隐藏层,调整各个连接权值w,然后依次传回,直到第一个隐藏层
5、使用新的权值作为神经网络的参数,重复步骤2~4,使误差逐步减小,达到预期精度。
反向传播算法:

文章部分概念来自《Python机器学习-清华大学-刘艳,韩龙哲,李沫沫》,感谢