ASCII码对照表(Unicode 字符集列表)
ASCII相关文章汇总如下:
- ASCII码对照表(255个ascii字符汇总)
- ASCII码对照表(Unicode 字符集列表)
- ASCII码对照表(emoji表情符号)
- ASCII码对照表(Python代码实现打印)
- ASCII码对照表(C++17 实现ANSI、UTF8、Unicode编码互转)
文章目录
- 1、ASCII码
- 2、摩尔斯电码
- 3、语言字符集
-
- 3.1 地图分布
- 3.2 汉字
- 3.3 拉丁语
- 3.4 希腊语
- 3.5 阿拉伯语
- 3.6 西里尔文
- 3.7 蒙古文
- 3.8 日语
- 3.9 韩语
- 4、其他字符集
-
- 4.1 易经卦符
- 4.2 太玄经符号
- 4.3 音乐符号
- 4.4 象棋符号
- 4.5 炼金术符号
- 4.6 多米诺骨牌
- 4.7 麻将牌
- 4.8 扑克牌
- 4.9 盲文
- 结语
《中秋篇》
戈戈:看什么?
狄狄:看见了一个机器人。
戈戈:望什么?
狄狄:望见了一个睡在工位上的人。
戈戈:想什么?
狄狄:想起了一个难得随遇而安的人。

诗云:
天上星,
亮晶晶,
攀高峰,
登月宫。
湖边草,
盈盈绿,
杨柳枝,
多喜乐。

1、ASCII码
ASCII ( / ˈ æs k iː / ( listen ) ASS -kee ),是American Standard Code for Information Interchange的缩写,是一种用于电子通信的字符编码标准。ASCII 代码代表计算机、电信设备和其他设备中的文本。大多数现代字符编码方案都基于 ASCII,尽管它们支持许多附加字符。
ASCII最初基于英文字母表,将 128 个指定字符编码为 7 位整数。95 个编码字符是可打印的:包括数字0到9、小写字母a到z、大写字母A到Z和标点符号。此外,原始的 ASCII 规范包括 33 个源自电传打字机的非打印控制代码;其中大部分现在已经过时了,尽管有一些仍然常用,例如回车、换行和制表符代码。
例如,小写i将在 ASCII 编码中表示为二进制1101001 =十六进制69(i是第九个字母)=十进制105。

- ASCII chart from a pre-1972 printer manual

- ASCII (1963). Control pictures of equivalent controls are shown where they exist, or a grey dot otherwise.

- Control code chart
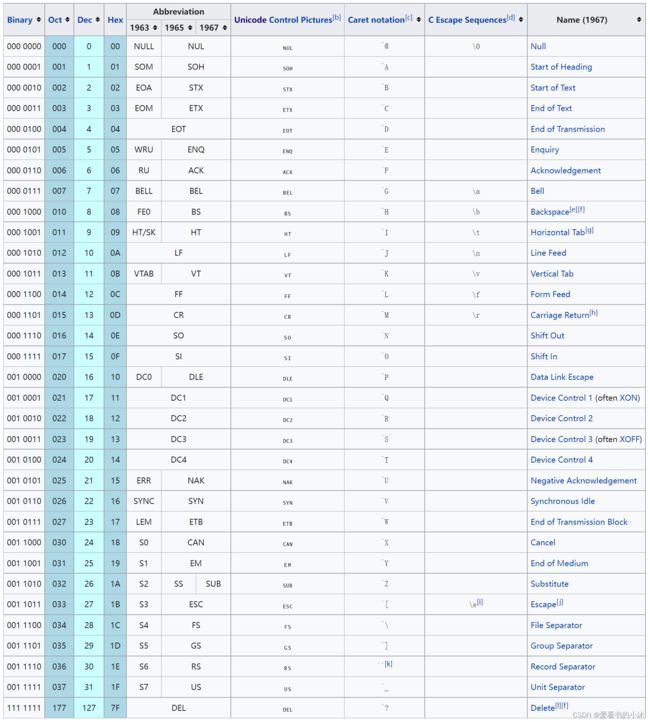
- Printable characters

- Character set

2、摩尔斯电码
摩尔斯电码(Morse’s code)是电信中使用的一种方法,用于将文本字符编码 为两种不同信号持续时间的标准化序列,称为点和破折号,或滴答声和达赫斯。
摩尔斯电码以电报的发明者之一塞缪尔·莫尔斯命名。
国际摩尔斯电码对 26 个基本拉丁字母 a到z、一个带重音符号的拉丁字母 ( é )、阿拉伯数字以及一小组标点符号和程序信号 ( prosigns ) 进行编码。大小写字母没有区别。
每个摩尔斯电码符号由一系列的dits和dahs组成。抖动持续时间是摩尔斯电码传输中时间测量的基本单位。dah的持续时间是dit持续时间的三倍。每滴滴或编码字符中的dah后面是一段没有信号的时间,称为空格,等于dit持续时间。一个单词的字母由一个持续时间等于三个点的空格分隔,而单词由一个等于七个点的空格分隔。

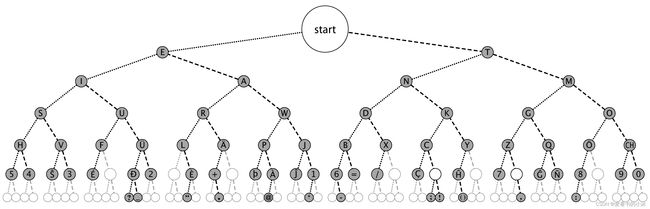
摩尔斯电码表 26 个字母和 10 个数字:

- International Morse code is composed of five elements:
- short mark, dot or dit ( ▄ ): “dit duration” is one time unit long
- long mark, dash or dah ( ▄▄▄ ): three time units long
- inter-element gap between the dits and dahs within a character: one dot duration or one unit long
- short gap (between letters): three time units long
- medium gap (between words): seven time units long
- 一些教授摩尔斯电码的方法使用二分搜索表。
3、语言字符集
3.1 地图分布
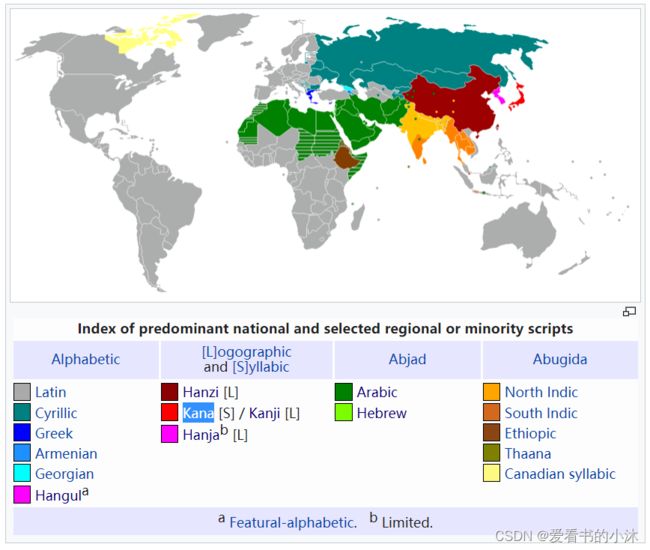
3.2 汉字
GB/T 2312-1980是中华人民共和国的主要官方字符集,用于简体中文字符。GB2312是EUC-CN的注册互联网名称,是其通常的编码形式。GB指的是国标(国家标准),而T后缀(推荐; tuījiàn;‘推荐’)表示非强制性标准。
截至 2021 年 11 月,GB2312 是网络上最流行的声明的中文特定编码,6.9% 的网页来自中国和声明它的地区,和全球所有网页的 0.1%,从 3.5% 下降在 2010 年 1 月。但是,请注意,所有主要的 Web 浏览器都将标记为“GB2312”或“ GB 2312 ”的文档解码(而不是全部用于“GB_2312”),就好像它被标记为“ gbk ”,是超集编码,GB 2312和 GBK 的份额合计为 9.1%(或全球不到 0.2%)。
中文、日文和韩文 ( CJK ) 文字具有共同的背景,统称为CJK 字符。在称为汉化的过程中,共同(共享)字符被识别并命名为CJK统一表意文字。从 Unicode 14.0 开始,Unicode 总共定义了 92,865 个 CJK 统一表意文字。
历史上,越南也使用汉字,因此有时使用缩写CJKV。越南语的使用在 1920 年代被基于拉丁语的越南字母表所取代。

名为CJK Unified Ideographs (4E00–9FFF) 的基本块包含U+4E00 到 U+9FFF 范围内的20,992 个基本汉字。该块不仅包括中国文字系统中使用的字符,还包括日本文字系统中使用的汉字和汉字,这些文字在韩国的使用正在减少。
3.3 拉丁语
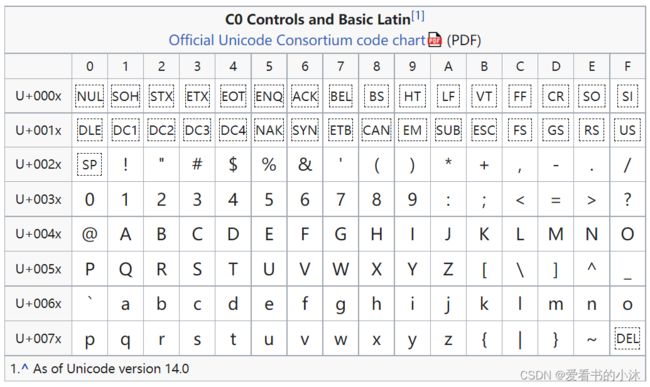
Basic Latin或C0 Controls 和 Basic Latin Unicode 块是Unicode标准的第一个块,也是唯一在UTF-8中以一个字节编码的块。该块包含 ASCII 编码的所有字母和控制代码。它的范围从 U+0000 到 U+007F,包含 128 个字符,包括C0 控件、ASCII标点和符号、ASCII 数字、英文字母的大写和小写以及一个控制字符。
基本拉丁语块从 Unicode 标准 1.0.0 版开始以目前的形式包含在内,没有添加或更改字符库。[3]它在 Unicode 1.0 中的块名称是ASCII。
3.4 希腊语
希腊语和科普特语是表示现代(单调)希腊语的Unicode 块。它最初用于编写科普特语,[1]使用类似的希腊字母,除了独特的科普特语添加。从Unicode标准 4.1 版开始,Unicode 中包含了一个单独的科普特语块,允许在风格上形成对比的混合希腊语/科普特语文本,这是学术作品中的惯例。

3.5 阿拉伯语
Thaana是一个Unicode 块,包含用于在马尔代夫编写迪维希语和阿拉伯语的Thaana 脚本字符。

3.6 西里尔文
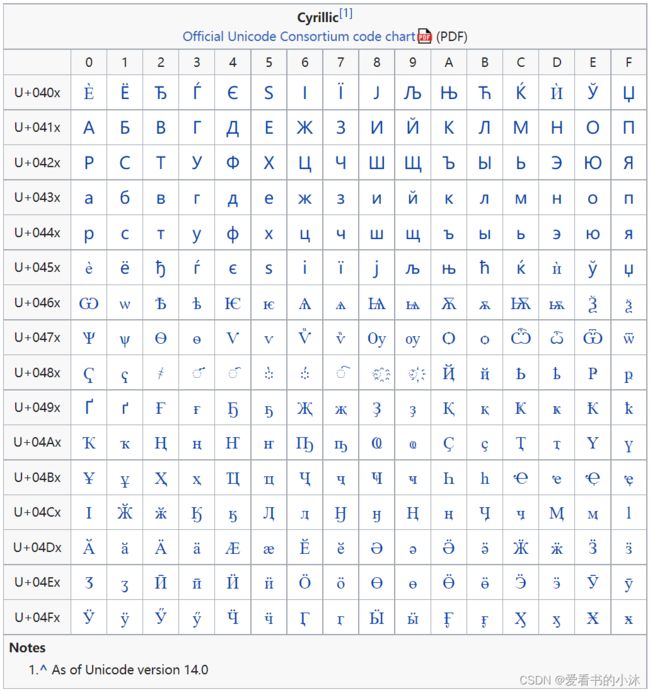
西里尔文是一个Unicode 块,其中包含用于使用西里尔拼写法编写最广泛使用的语言的字符。该块的核心基于ISO 8859-5标准,并增加了少数民族语言和历史正字法。
3.7 蒙古文
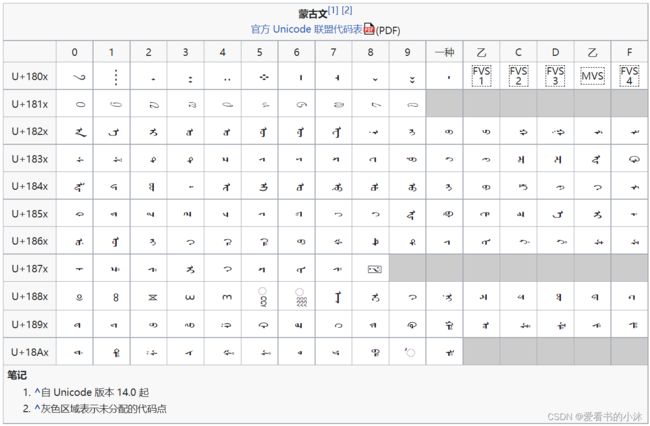
蒙古语是一个包含蒙古语、满语和锡伯语方言字符的Unicode 块。它传统上是在文字方向 TDright.svg页面上自上而下以垂直线书写,尽管 Unicode 代码图表引用旋转到水平方向的字符,因为这是支持垂直方向布局的字体中字形的方向。
3.8 日语
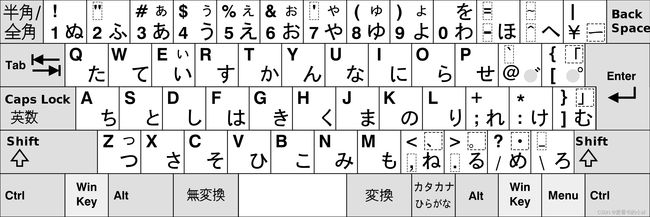
片假名是一个Unicode 块,其中包含日语和阿伊努语的片假名字符。
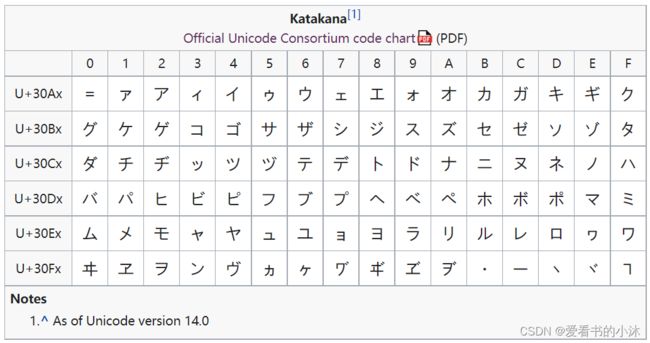
平假名是包含日语平假名字符的Unicode 块。
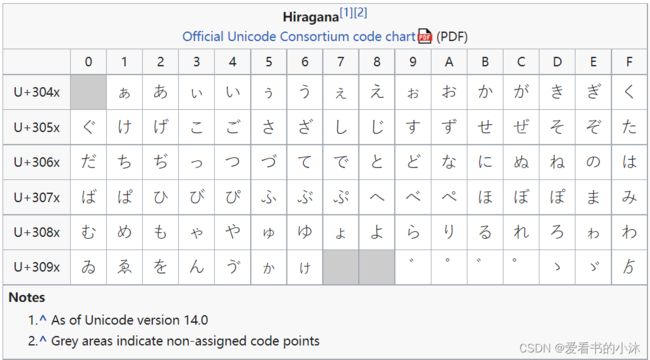
片假名语音扩展是一个Unicode 块,除了片假名块中的字符之外,还包含用于书写阿伊努语的附加片假名小字符。

3.9 韩语
韩语的书写系统是由字符部分( jamo )组成的“音节字母表”,这些字符部分被组织成代表音节的字符“块”(geulja ) ,这些字符部分不能在计算机上从左到右书写,就像在许多西方语言。因此,韩语中每个可能的音节都必须由字体呈现为“音节块” ,或者每个字符部分单独编码。
Unicode有这两种选择,例如,字符部分 ㅎ (h) 和 ㅏ (a) 分别编码,还有组合音节 하 (ha)。


- Unicode 中的韩文 jamo 字符

- Unicode 中的韩文兼容性 Jamo 块

4、其他字符集
4.1 易经卦符
Yijing Hexagram Symbols是一个Unicode 块,包含来自《易经》的 64 个卦。

4.2 太玄经符号
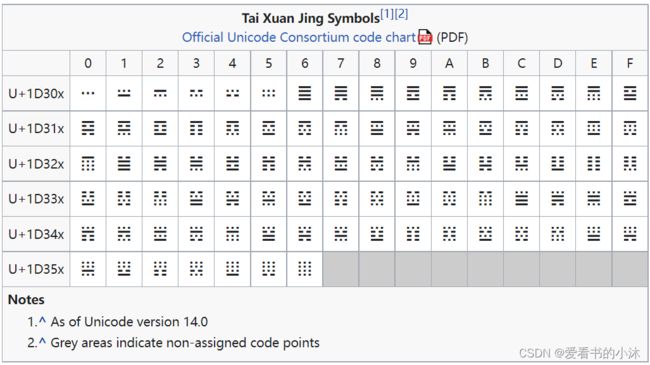
太玄经是一种类似于易经(易经)并受其启发的占卜文字。《易经》以六十四卦为基础(六横行的序列,每行可断或不断),《太玄经》采用八十一三卦(四行的序列,每行可不断、断一次或断)两次)。就像《易经》一样,它可以通过铸造蓍草茎或六面骰子来生成定义四边形线条的数字来作为神谕进行咨询,然后可以在文本中查找这些数字。[需要进一步解释] 无动线绘制的四角星是指四角星描述,而动线绘制的四角星是指特定的线。
4.3 音乐符号
Musical Symbols是一个Unicode 块,包含用于表示现代音乐符号的字符。支持它的字体包括Bravura、Euterpe、FreeSerif、Musica和Symbola。MusicXML格式支持的标准音乐字体布局 ( SMuFL )通过使用基本多语言平面中的私人使用区域扩展了音乐符号 Unicode 块的 220 个字形,允许接近 2600 个字形。

4.4 象棋符号
Chess Symbols是一个Unicode 块,其中包含除了Miscellaneous Symbols块中基本的西洋象棋符号之外的国际象棋符号字符,以及代表象棋(中国象棋)棋子的符号。

4.5 炼金术符号
炼金术符号是一个Unicode 块,其中包含古代和中世纪炼金术文本中使用的化学物质和物质的符号。
截至 2021 年,很少有字体支持此块中的多个字符。可以免费供个人使用的一种是Symbola 14.0。

4.6 多米诺骨牌
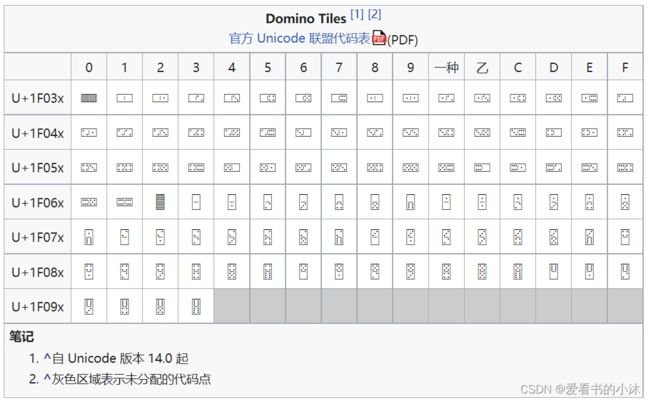
Domino Tiles是一个Unicode 块,包含用于在多米诺骨牌中表示游戏情况的字符。该块包括标准六点拼贴组的符号以及水平和垂直方向的背面。
4.7 麻将牌
麻将牌是一个Unicode 块,包含描述麻将游戏中使用的标准牌组的字符。

4.8 扑克牌
Unicode是用于处理字体和符号的计算行业标准。在它里面是一组描绘扑克牌的图像,以及另一个描绘法国纸牌套装的图像。
Unicode 6.0 添加了以下图片:标准法式牌组的 52 张牌、4张塔罗牌骑士、一张牌的背面,以及 U+1F0A0–1F0FF 区块中的黑色和白色(或红色)小丑两张。Unicode 7.0 增加了一个特定的红色百搭牌和二十二张通用王牌,其参考描述不是意大利套牌马赛塔罗牌或其衍生品(通常用于纸牌术),而是法国新塔罗牌用来玩塔罗牌。

4.9 盲文
Unicode 块 盲文模式(U+2800…U+28FF) 包含 8 点盲文单元格的所有 256 种可能模式,从而包括完整的 6 点单元格范围。在 Unicode 中,盲文单元格没有定义字母或含义。例如,Unicode没有定义U+2817 ⠗ 成为“R”。

结语
如果您觉得该方法或代码有一点点用处,可以给作者点个赞,或打赏杯咖啡;╮( ̄▽ ̄)╭
如果您感觉方法或代码不咋地//(ㄒoㄒ)//,就在评论处留言,作者继续改进。o_O???
如果您需要相关功能的代码定制化开发,可以私聊留言作者。(✿◡‿◡)
感谢各位童鞋们的支持!( ´ ▽´ )ノ ( ´ ▽´)っ!!!
