MMselfSup自监督预训练模型的评估:“检测”下游任务
1.提取自监督预训练模型的 backbone 权值
python tools/model_converters/extract_backbone_weights.py {CHECKPOINT} {MODEL_FILE} 参数:
CHECKPOINT:自监督预训练过程中保存下来(名为epoch_*.pth)的模型文件路径
MODEL_FILE:输出 backbone 权重文件的保存路径。

生成的 backbone 权值文件

2. 配置环境
创建虚拟环境
conda create --name openmmlab python=3.8 -y
激活虚拟环境:
conda activate openmmlab
安装pytorch、torchvision
根据自己的配置安装相应版本
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 -f https://download.pytorch.org/whl/torch_stable.html
或手动下载,地址:https://download.pytorch.org/whl/torch_stable.html
下载I MMEngine 和 MMCV
pip install -U openmim
mim install mmengine
mim install 'mmcv>=2.0.0rc1'
注:推荐使用命令:pip install mmcv==2.0.0rc1 -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.7/index.html进行下载
安装mmdetection3.0版本
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
pip install -v -e .
3.写目标检测任务的配置文件
在路径:/configs/faster_rcnn/下
新建一个名为faster_rcnn_simclr-pretrained_r50_fpn_9k_coco.py 的配置文件。
写入内容
_base_ = 'faster_rcnn_r50_fpn_90k_coco.py'
model = dict(
backbone=dict(
frozen_stages=-1,
init_cfg=dict(
type='Pretrained',
checkpoint='checkpoints/200.pth')
))
# optimizer
optimizer = dict(
lr=0.02 * (1 / 8))
# Runner type
runner = dict(_delete_=True, type='IterBasedRunner', max_iters=9000)
checkpoint_config = dict(interval=3000)
evaluation = dict(interval=3000)
4.修改coco_detection.py.py文件
主要修改coco数据集路径

5.修改coco.py
主要修改CLASSES

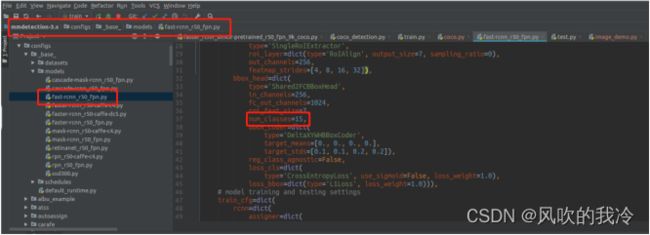
6.修改基础backbones网络
主要修改num_classes
7.训练

8.测试
使用tool/test.py

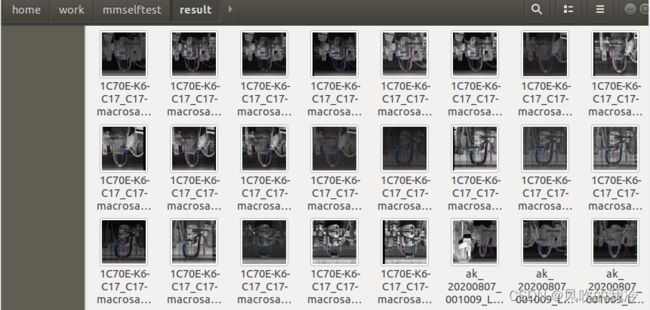
结果

修改image_demo.py可进行批量检测,代码如下:
import asyncio
from argparse import ArgumentParser
import mmcv
from mmdet.apis import (async_inference_detector, inference_detector,
init_detector)
from mmdet.registry import VISUALIZERS
from mmdet.utils import register_all_modules
import os
import cv2
def parse_args():
parser = ArgumentParser()
parser.add_argument('img', help='Image file')
parser.add_argument('config', help='Config file')
parser.add_argument('checkpoint', help='Checkpoint file')
parser.add_argument('--out-file', default=None, help='Path to output file')
parser.add_argument(
'--device', default='cuda:0', help='Device used for inference')
parser.add_argument(
'--palette',
default='coco',
choices=['coco', 'voc', 'citys', 'random'],
help='Color palette used for visualization')
parser.add_argument(
'--score-thr', type=float, default=0.3, help='bbox score threshold')
parser.add_argument(
'--async-test',
action='store_true',
help='whether to set async options for async inference.')
args = parser.parse_args()
return args
def main(args):
register_all_modules()
file_name = os.listdir(args.img)
model = init_detector(
args.config, args.checkpoint,palette=args.palette, device=args.device)
visualizer = VISUALIZERS.build(model.cfg.visualizer)
visualizer.dataset_meta = model.dataset_meta
for images in file_name:
name = images
images = os.path.join(args.img, images)
result = inference_detector(model, images)
img = mmcv.imread(images)
img = mmcv.imconvert(img, 'bgr', 'rgb')
visualizer.add_datasample(
name,
img,
data_sample=result,
draw_gt=False,
show=args.out_file is None,
wait_time=0,
out_file=args.out_file + name,
pred_score_thr=args.score_thr)
async def async_main(args):
model = init_detector(args.config, args.checkpoint, device=args.device)
visualizer = VISUALIZERS.build(model.cfg.visualizer)
visualizer.dataset_meta = model.dataset_meta
tasks = asyncio.create_task(async_inference_detector(model, args.img))
result = await asyncio.gather(tasks)
img = mmcv.imread(args.img)
img = mmcv.imconvert(img, 'bgr', 'rgb')
visualizer.add_datasample(
'result',
img,
pred_sample=result[0],
show=args.out_file is None,
wait_time=0,
out_file=args.out_file,
pred_score_thr=args.score_thr,
)
if __name__ == '__main__':
args = parse_args()
assert not args.async_test, 'async inference is not supported yet.'
if args.async_test:
asyncio.run(async_main(args))
else:
main(args)
运行:
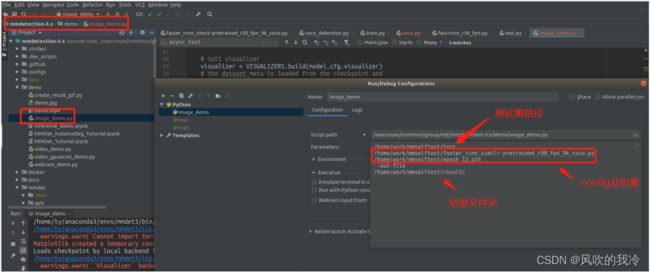
批量测试结果: