KNN 回归模型的认识与使用
KNN回归模型的认识与使用
写在前面:
emm,距离上次更新文章已经过去很长一段时间了,中间呢经历了一些曲折。人生嘛,总是被各种惊喜和意外肆意裹挟,等闲视之就好!“泰山崩于前而色不变”,就会有所成长。好了,闲话不多说,上干货!
初识KNN模型
KNN模型,是一种紧邻算法,也叫K紧邻(K-Nearest-Neighbor),在数据挖掘算法中是最简单并且基础的一种算法模型,在实际的运用中,不仅有分类方面的应用,也有回归方面的应用。本文从回归预测的角度出发,来介绍一下KNN算法。
KNN回归的原理
k紧邻,顾名思义,找到最近的点(最近邻)来确定新样本的回归值。k的意义确定算法要检查多少个紧邻,如果k=3,算法将检查3个最近的点的均值来作为新样本的预测值。
确定k值的方法
一般我们会次用交叉验证的方法,caret包中的train()函数可以建立计算最优k值得对象。当RMSE最小时,即为最优的k值。
实例场景
某公司平台12月份有线上活动推广,需要对活动进行成本计算,需要数据分析师给出12月份的活跃用户数。假设影响月度active_users的特征分别有se、ti、po、we、qu、cd。
首先呢,我们需要对数据进行预处理,由于特征之间可能受量纲的影响,导致数量级上会有很大差别,所以对数据数据标准化处理,处理方法有很多,比如最大最小标准化、z-score标准化等,一般使用z-score标准化。
##数据读入与标准化处理
data_m<- read.csv('E:\\R-Study\\数据\\data_train.csv',header = TRUE)
data_m_scale<-as.data.frame(scale(data_m[,c(-1:-2)],center = F,scale = T))
然后配一下训练集和测试集,我们按照7:3的比例来拆分。
##样本处理
set.seed(123)
ind<-sample(2,nrow(data_m_scale_1),replace = TRUE,prob = c(0.7,0.3))
train<-data_m_scale_1[ind==1,]
train_data<-train[,c(-1)]
str(train_data)
###测试样本处理
test<-data_m_scale_1[ind==2,]
test_data<-test[,c(-1)]
str(test_data)
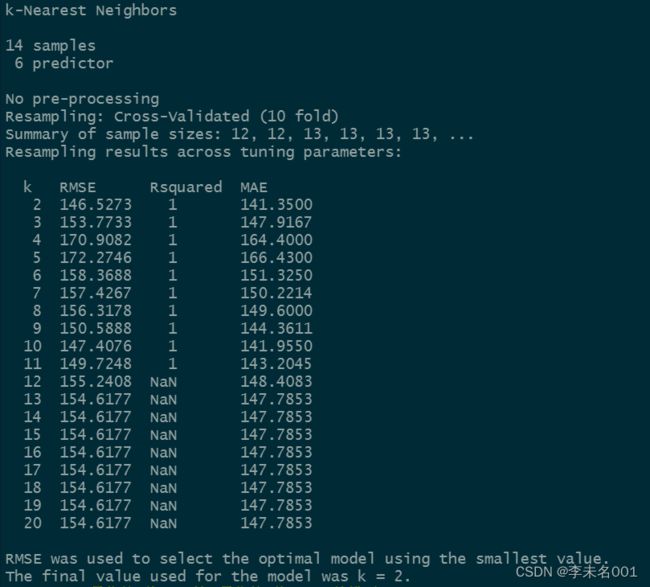
训练集和测试集有了之后,我们就开始进入建模阶段了。先确定k值,k值一般在20以下。
# 参数control
grid1<-expand.grid(.k=seq(2,20,by=1))
control<-trainControl(method = 'cv')
###训练
set.seed(123)
knn.train<-train(active_users~.,data=train_data,method='knn',trControl=control,tuneGrid=grid1)
knn.train
##获取最优的k值,并利用最优的K值重新训练模型
k_best<-knn.train$results$k[which.min(knn.train$results$RMSE)]
我们可以发现,RMSE最小时,k=2,最优的k值就是2,也就说在建模过程中,我们选取两个最近的点作为新样本预测值的参考点。
然后我们开始训练模型。
data_m_best<-knnreg(active_users~.,data=train_data,k=k_best)
data_m_best
结果如下:

接着我们可以看下模型在训练集上的表现。
test_pre<- predict(data_m_best,test_data)
test_mse<- sum(test_pre-test_data)^2/nrow(test_data)
test_mse
> test_mse<- sum(test_pre-test_data)^2/nrow(test_data)
> test_mse
[1] 59957303
在回归中,我们把MSE作为判断模型好坏的统计量,值越小说明模型的一般性越好。
回到实例中,预测12月份的活跃用户数,代码如下:
knn_pre<-predict(data_m_best,data_m_scale_0[,c(-1)])
all<-cbind(data_m,knn_pre)
all
> knn_pre<-predict(data_m_best,data_m_scale_0[,c(-1)])
> all<-cbind(data_m,knn_pre)
> all
month active_users se ti po we qu cd knn_pre
1 202101 264 121385 97059 121385 121385 1927 -12.80 366.0
2 202102 183 122841 98514 122841 122841 2127 -49.00 366.0
3 202103 468 124244 98321 124244 124244 2023 -14.90 366.0
4 202104 179 125017 99093 125017 125017 2023 8.59 366.0
5 202106 342 125604 99680 125604 125604 -1767 104.45 311.5
6 202107 293 126061 100138 126061 126061 -77 162.76 311.5
7 202108 330 127691 101768 127691 127691 873 143.42 311.5
8 202109 128 128548 102624 128548 128548 1223 151.13 311.5
9 202110 159 132604 103366 132604 132604 5438 115.98 287.0
10 202111 690 133831 104593 133831 133831 6238 17.42 594.5
11 202112 557 133687 103931 133687 133687 6956 -13.12 543.5
12 202201 397 138660 108746 138660 138660 7874 -21.89 417.5
13 202202 438 138883 108969 138883 138883 7114 -50.91 417.5
14 202203 600 141588 108992 141588 141588 9196 11.56 549.5
15 202204 499 141682 109086 141682 141682 8596 15.13 549.5
16 202205 290 144374 111777 144374 144374 8187 57.90 549.5
17 202206 415 143474 110877 143474 143474 6817 105.78 287.0
18 202207 615 146384 113788 146384 146384 7627 175.30 656.5
19 202208 698 146904 114308 146904 146904 7807 145.00 656.5
20 202209 726 147878 113611 147878 147878 9337 111.00 556.5
21 202210 579 148600 114177 148600 148600 10092 82.00 556.5
22 202211 549 149820 114639 149820 149820 12182 9.49 574.5
23 202212 NA 13679 12654 13609 120878 7975 67.00 424.5
从上表可知,12月份的活跃用户数约为424.5万人。
以上就是knn回归的整个建模流程了,knn是一种相对比较基础的机器学习模型,应用起来比较简单粗暴,不涉及参数估计问题。但这种算法在运行中会占用比较高的计算资源,k值也不固定,另外极易受极端值的影响,所以在数据量很大的时候慎用。
写在最后
欢迎大家一起来讨论数据分析领域的知识,下期分享knn模型分类的场景,希望我们可以一起成长、进步。