01 Datafountain_云状识别_top1
01 Datafountain_云状识别_top1
- 摘要
- 1 云状识别算法总体思路和架构
- 2 云状识别算法具体实现过程
-
- 2.1 图像增强:
- 2.2 多图像尺寸训练:
- 2.3 选用densenet161预训练模型进行fine-tune:
- 2.4 差分学习率与余弦退火
- 2.5 TTA(test time augmentation):
- 2.6 模型融合:
- 致谢
- 参考
- 赛事地址:https://www.datafountain.cn/competitions/357
- 思路分析:https://discussion.datafountain.cn/questions/2152/answers/23219
- 比赛类型:图像多分类
我们参加了云状识别的比赛,取得了一定的成绩,这里感谢王博,栗宏海大佬,为了营造更好的学习氛围,我们把主要的思路以及学习参考分享给大家
摘要
细粒度图像分类是图像分类的子任务[1],主要区分同一类别下的不同子类,本次任务主要是识别3族29种云朵形状。与一般的分类任务不同,该分类任务具有类内差距小的特点,往往需要借助微小的局部细节差异才能分辨出不同的类别。因此,如何提高细粒度图像的分类准确率至关重要。
算法的整体结构包括两层,第一层是以densenet161作为基础模型,改变训练集的不同分割方式获得15个模型,第二层通过求取15个模型预测各个分类的概率均值,阈值为0.2进行选取,得到最后的分类结果。
其中,训练densenet161的时候,首先对数据图像进行了翻转,旋转,对比度和缩放的调整,增加数据的多样性,训练过程中采用差分学习率以及余弦退火的方式提高精度和减少训练时间,为了进一步提高模型的鲁棒性,采用了多尺寸图像训练,最后通过TTA进一步增加预测的稳定性。
关键词 云状识别,细粒度多分类,多尺寸图像,差分学习率,余弦退火
1 云状识别算法总体思路和架构
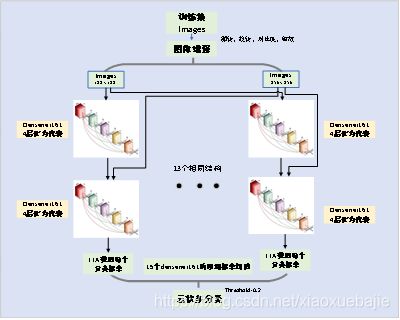
总体方案如图1所示:首先通过翻转,旋转,对比度和缩放对原始数据增强,然后分别调整为和,首先喂给模型的图片进行第一部分训练,然后再把的图片喂给模型进行第二部分的训练,每部分模型训练都分为两个阶段,第一阶段固定预训练模型参数,只改变后几层网络参数,第二阶段打开预训练模型,全部进行训练,每次训练采用差分学习率和余弦退火,提高精度,缩短训练时间,最后通过TTA对验证集进行处理,达到预测的稳定性。这样就产生了第一个densenet161模型,为了减少预测的抖动,通过对训练集中训练样本和验证样本的随机分割,产生15组分割方式,依次获取15个densenet161模型,每个模型给出的预测概率进行求均值处理,设置阈值为0.2进行划分,得到最后的预测分类结果。
2 云状识别算法具体实现过程
首先对模型进行初步筛选,筛选模型有以下11种:densenet121,densenet161,densenet169,densenet201,resnet18,resnet34,resnet50,resnet101,resnet152,vgg16,vgg19,从中选取表现最好的模型densenet161,把该模型作为基模型,进行后续的模型融合。

2.1 图像增强:
对输入图像进行水平,垂直翻转,任意旋转设置为15°,概率为0.75,最大缩放比例为1.05,最大随机光照对比度变化比例为0.1,概率为0.75。通过这种方式获取随机变化的训练集样本,增加数据的多样性,提高模型的鲁棒性。得到的训练集图片示例如图2所示。
2.2 多图像尺寸训练:
多图像尺寸训练,经常用来处理过拟合效应和提高准确性,它就是训练小尺寸图像,然后增大尺寸并再次训练相同模型。这种方法在imageNet比赛中得到应用,取得了很好的效果,这里我将这种方法迁移到云状识别的任务中,我首先将训练图片尺寸调整为,训练模型,然后将训练好的模型再次在图片为的训练集合中训练,得到精度更高,鲁棒性更好的最终单模型。
2.3 选用densenet161预训练模型进行fine-tune:
我们没有必要从头开始一个一个的参数去试验来构造一个深度网络,因为已经有很多公开发表的论文已经帮我们做了这些验证,我们只需要站在前人的肩膀上,去选择一个合适的网络结构就好了。且选择已经公认的网络结构另一个重要的原因是,这些网络几乎都提供了在大规模数据集ImageNet[2]上预先训练好的参数权重(Pre-trained Weights)。这一点非常重要!因为我们只有1万张训练样本,而深度网络的参数非常多,这就意味着训练图片的数量要远远小于参数搜索的空间,因此,如果只是随机初始化深度网络然后用这数千张图片进行训练,非常容易产生“过拟合”(Overfitting)的现象。
所谓过拟合,就是深度网络只看过了少量的样本,因而“坐井观天”,导致只能识别这小部分的图片,丧失了“泛化”(Generalization)能力,不能够识别其它没见过、但是也是相似的图片。为了解决这样的问题,我们一般都会使用那些已经在数百万甚至上千万上训练好的网络参数作为初始化参数,可以想象这样一组参数的网络已经“看过”了大量的图片,因此泛化能力大大提高了,提取出来的视觉特征也更加的鲁棒和有效。
DenseNet[3]的一个优点是网络更窄,参数更少,很大一部分原因得益于这种dense block的设计,dense block中每个卷积层的输出特征图的维度都很小。同时这种连接方式使得特征和梯度的传递更加有效,网络也就更加容易训练。梯度消失问题在网络深度越深的时候越容易出现,原因就是输入信息和梯度信息在很多层之间传递导致的,而现在这种dense连接方式相当于每一层都直接连接输入和输出,因此就可以减轻梯度消失现象,这样更深网络不是问题。另外这种dense连接还具有正则化的效果,对于过拟合有一定的抑制作用.
2.4 差分学习率与余弦退火
差分学习率(Differential Learning rates)[4]意味着在训练时变换网络层比提高网络深度更重要。基于已有模型来训练深度学习网络,这是一种被验证过很可靠的方法,可以在计算机视觉任务中得到更好的效果。大部分已有网络(如Resnet、VGG和Inception等)都是在ImageNet数据集训练的,因此我们要根据所用数据集与ImageNet图像的相似性,来适当改变网络权重。在修改这些权重时,我们通常要对模型的最后几层进行修改,因为这些层被用于检测基本特征(如边缘和轮廓),不同数据集有着不同基本特征。创建学习对象之后,通过快速冻结前面网络层并微调后面网络层来解决问题:当后面网络层产生了良好效果,我们会应用差分学习率来改变前面网络层。在实际中,一般将学习率的缩小倍数设置为10倍。
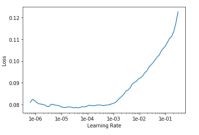

图中A是保持预训练模型不变,训练后几层时候不同学习率下损失函数的变化,为了提高收敛速度,可以选取下降且变化速率最快的学习率,但考虑到多图像尺寸训练的因素,为了保证一定的泛化程度,本文选择了学习率为1e-2,当解冻预训练模型的时候变化关系如图B,这时选用了一定的经验值,其中预训练层部分学习率选择为1e-6, 后几层学习率选择为1e-2/5。选择的学习率作为该网络层的最大学习率,真实的学习率,以1e-2为例,如图4所示
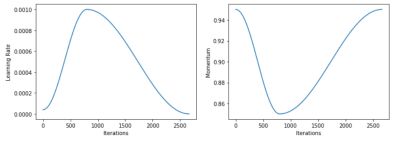
采用学习率先增加后减少的方式,可以有效的提高训练速度,同时学习率增加段可以规避掉一些局部最小值,后续的利用余弦函数降低学习率的方式,在神经网络越来越接近Loss值的全局最小值的时候,保证模型不会超调且尽可能接近这一点。而且余弦值首先缓慢下降,然后加速下降,再次缓慢下降。这种下降模式能和学习率配合,以一种十分有效的计算方式来产生很好的效果,这是由于这种特殊的学习率调节方式,一般最好的loss函数会呈现如图5所示
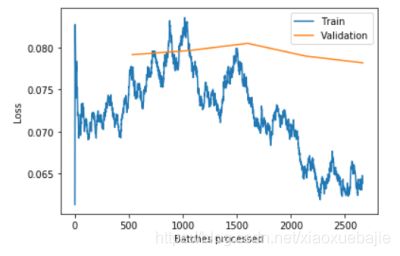
Loss函数会先上升一小段,然后大幅度下降。这种方法既可以提高精度又可以大幅缩减训练时间。
2.5 TTA(test time augmentation):
TTA作为一种先进技巧,可将准确率提高若干个百分点,它就是测试时增强(test time augmentation, TTA)。这里会为原始图像造出多个不同版本,包括不同区域裁剪和更改缩放程度等,并将它们输入到模型中;然后对多个版本进行计算得到平均输出,作为图像的最终输出分数。
2.6 模型融合:
最后由于本次云状分类任务中,样本类别分布极其不均匀,预测的评估分数抖动很大,为了提高模型的稳定性,这里我没有采用常规的多模型融合,再增加机器学习的Stack方法,而是首先对训练集进行随机分割15次,训练集和测试集的比例都为4:1,然后利用最优单模型分别训练,得到15个不同的densnet161模型,把每一个单模型的预测概率值进行求均值,得到最后的各分类概率值,然后设定阈值为0.2,进行最后的多分类可信值。
致谢
在这里首先感谢中国气象局,Datafountain和组委会给我们这样的机会和舞台,来磨练和展示自己。其次要感谢队友的无私奉献,吃苦耐劳,开拓进取,以及互相的扶持与砥砺前行。
参考
[1]蒋杰, 熊昌镇. 一种数据增强和多模型集成的细粒度分类算法[J]. 图学学报, v.39;No.138(2):68-74.
[2]Alex Krizhevsky, I Sutskever, G Hinton. ImageNet Classification with Deep Convolutional Neural Networks[J]. Advances in neural information processing systems, 2012, 25(2).
[3]Huang, Gao, Liu, Zhuang, van der Maaten, Laurens, etc. Densely Connected Convolutional Networks[J].
[4]Smith L N . Cyclical Learning Rates for Training Neural Networks[J]. Computer Science, 2015:464-472.
觉得有用可以关注我的公众号CV伴读社,微博CV七少
