自监督入门(对比学习:INS+Disc,InvaSpread,SimCLR,MoCo系列)
自监督入门
本人从图像分割入门自监督过程记录
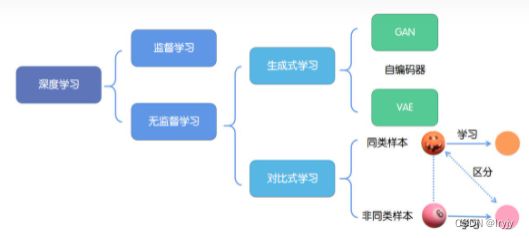
文章目录
- 自监督入门
- 前言
- 一、自监督学习背景及应用
- 二、对比学习
-
- 1.Contrastive Learning Framework
- 初阶
-
- 一. Ins+Disc
- 二.InvaSpread
-
- Motivation and Contribution:
- Method:
- 中阶
-
- 一.MoCov1
- 二.SimCLRv1
-
- 1.Abstract
- 2.Introduction
- 3.Method
-
- 3.1 The Contrastive Learning Framework
- 3.2 Training with Large Batch Size
- 4. Data Augmentation for Contrastive Representation Learning
- 5. Architectures for Encoder and Head
- 6. Loss Functions and Batch Size
- 7. Comparison with State-of-the-art
- 高阶
-
- 一. MoCoV2
- 二.SimCLRv2
-
- 1.Abstract
- 2.Introduction
- 2.Method
- 3.实验
- 总结
前言
咨询师兄了解了一下自监督的方向:经典的方法大都是基于对比学习的(对比学习是特征学习),后来又提出了基于生成学习的(生成就是GAN的生成器在做的事情),于是准备先从对比学习方法入门。
机器学习大致分为分类和生成两大类,目标分类,检测,分割这些都是分类,图像复原,去雾霾这些都是生成。在概率论里,生成是后验概率,可以理解成你知道某个数据的分部,然后生成一个新的,服从这个分部,GAN就是在做这个事情,它先学习数据的分布,然后生成器再去生成这个分布。
一般的机器学习分为监督学习、非监督学习和强化学习。自监督学习希望通过学习到一种通用的特征表达于下层任务。自监督学习的思想非常简单,对于输入的一堆无监督的数据,通过数据本身的结构或者特性,人为构造标签出来。之后类似监督学习一样进行训练。现有的自监督学习通常分为两大类,生成方法(Generative Methods)和对比方法(Contrastive Methods)。
- 对比学习
- 经典论文:moco,simclr、byol、simsiam,今年的mae,基于Transformer的等
一、自监督学习背景及应用
(TPAMI:Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey)
参考:https://mp.weixin.qq.com/s/VvUj0S2OTf8BowGRjDuVag
动机:
要在深度神经网络中应用监督学习,我们需要足够的标记数据。但是人工手动标记数据既耗时又昂贵。 对于一些特殊的领域,比如医学领域获取足够的数据本身就是一个挑战。 因此,监督学习当前的主要瓶颈是标签生成和标注。
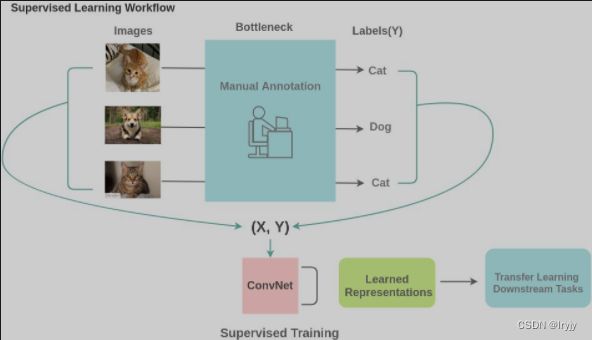
方案:
自监督学习是通过以下方式将无监督学习问题转化为有监督问题的方法:我们是否可以通过特定的方式设计任务,即可以从现有图像中生成几乎无限的标签,并以此来学习特征表示?
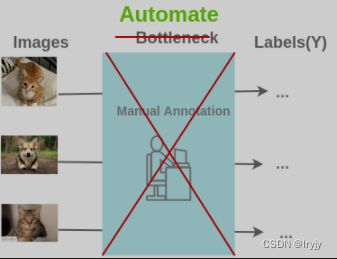
在自监督学习中,我们通过利用数据的某些属性来设置伪监督任务来替换人类注释。 例如,这里我们可以将图片旋转 0/90/180/270 度,然后训练模型来预测旋转的角度,而不是将图像标记为 cat / dog。如果将图片标记为 cat / dog 是需要人的参与,而将图片进行旋转并记录其旋转的角度作为标签写个脚本就能完成,并且我们可以从互联网上找到数百万张图像生成几乎无限的训练数据。
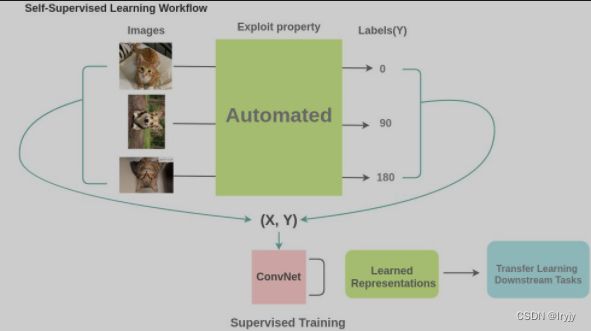
应用:
-
图像着色
我们将数百万张图像转化成灰色的,以此来构建成对的(灰度,彩色)图像作为数据。

我们可以使用基于全卷积神经网络的编码器-解码器(encoder-decoder)体系结构,并计算预测彩色图像与实际彩色图像之间的L2损失。
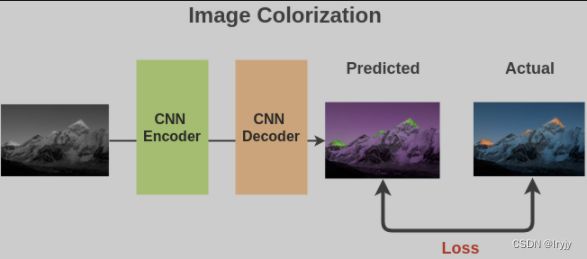
为了解决此任务,模型必须了解图像中存在的不同对象以及相关组件,以便进行上色。 因此,学习到的特征表示对于下游任务很有用。

论文:Colorful Image Colorization | Real-Time User-Guided Image Colorization with Learned Deep Priors | Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous Classification -
图像超分辨率
通过对数百万张图像进行降采样来准备训练对(小尺寸,放大图像),作为训练数据。

基于 GAN 的模型,例如 SRGAN 很适合该任务。 Generator 基于全卷积网络获取低分辨率图像并输出高分辨率图像。 使用均方误差和内容损失来比较实际图像和生成的图像。 二分类器会输入一张图像,然后将其分类为实际的高分辨率图像还是伪造的超分辨率图像。 这两个模型之间的相互对抗作用导致 Generator 学习生成具有精细细节的图像。

生成器和判别器都学到了可以用于下游任务的语义特征。
论文:Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network -
图像修复
通过随机删除部分图像来准备训练对(损坏的,固定的)作为训练数据。

与超分辨率任务相似,我们可以利用基于GAN的体系架构,在该架构中 Generator 可以学习重建图像,而 Discriminator 则可以将真实图像和生成的图像分开。

对于下游任务,Pathak等人表明,在PASCAL VOC 2012语义分割的比赛上,生成器学到的语义特征相比随机初始化有10.2%的提升,对于分类和物体检测有<4%的提升。
论文:Context encoders: Feature learning by inpainting -
图像拼图
通过随机交换图像块生成训练对

即使只有9个 patch,也可能存在 362880 个排列方式。 为了克服这个问题,仅仅选取具有最大汉明距离的 64 个排列。
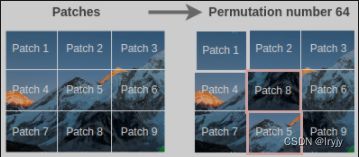
假设我们使用如下所示的重排来更改图像。我们用64个排列中的第64个排列。
现在,为了恢复原始的小块,Noroozi等人提出了一个称为上下文无关网络(CFN)的神经网络,如下图所示。在这里,各个小块通过相同的共享权值的siamese卷积层传递。然后,将这些特征组合在一个全连接的层中。在输出中,模型必须预测在64个可能的排列类别中使用了哪个排列。如果我们知道排列的方式,我们就能解决这个难题。
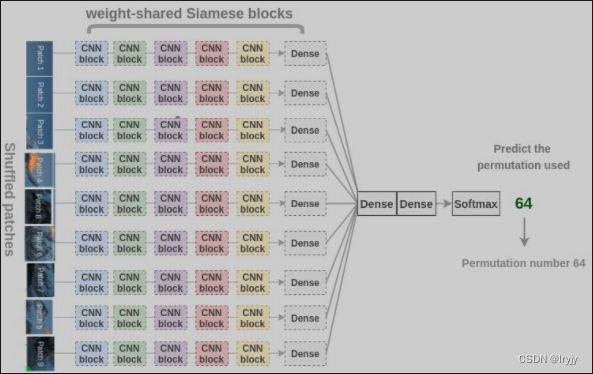
为了解决拼图问题,模型需要学习识别零件是如何在一个物体中组装的,物体不同部分的相对位置和物体的形状。因此,这些表示对于下游的分类和检测任务是有用的。
论文:Unsupervised learning of visual representations by solving jigsaw puzzles -
上下文预测
我们随机选取一个图像块以及其附近的一个图像块来组成训练图像对。

为了解决这个文本前的任务,Doersch等人使用了类似于拼图游戏的架构。我们通过两个siamese卷积神经网络传递图像块来提取特征,连接特征并对8个类进行分类,表示8个可能的邻居位置。
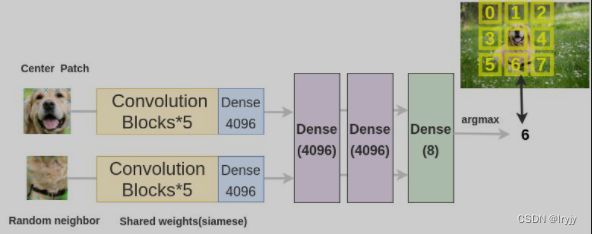
论文:Unsupervised Visual Representation Learning by Context Prediction -
几何变换识别
我们通过随机的旋转图像来生成有标注的图像(旋转图像,旋转角度)。
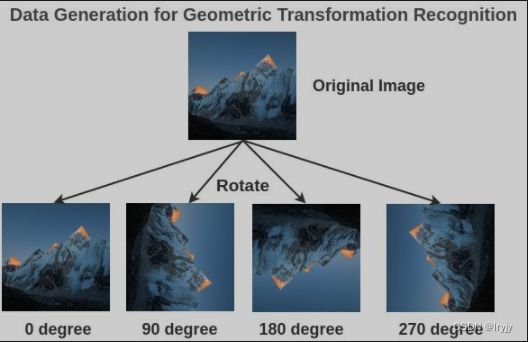
为了解决这个文本前的任务,Gidaris et al.提出了一种架构,其中旋转后的图像通过一个卷积神经网络,网络需要把它分成4类(0/90/270/360度)。

虽然这是一个非常简单的想法,但模型必须理解图像中物体的位置、类型和姿态才能完成这项任务,因此,学习到的表示方法对后续任务非常有用。
论文:Unsupervised Representation Learning by Predicting Image Rotations -
图像聚类
把聚类的结果作为图像的标签生成训练图像样本和标注。

为了解决这个预备任务,Caron et al.提出了一种称为深度聚类的架构。在这里,首先对图像进行聚类,把聚类出的类别用作分类的类别。卷积神经网络的任务是预测输入图像的聚类标签。
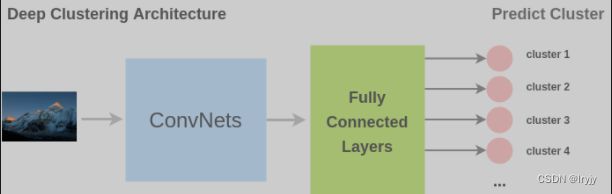
论文:Deep clustering for unsupervised learning of visual features -
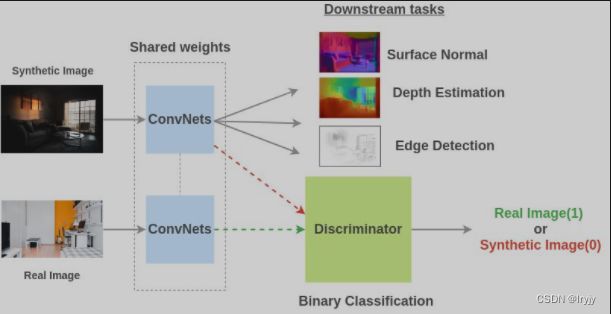
图像合成
通过使用游戏引擎生成合成图像并将其调整为真实图像来准备训练对(图像,属性)。

为了解决此前置任务,Ren等人 提出一个架构,使用共享权值的卷积网络在合成和真实图像上进行训练,然后鉴别器学会分类合成图像是否是一个真正的图像。由于对抗性,真实图像和合成图像之间的共享表示变得更好。
-
视频帧顺序识别
通过打乱视频中的视频帧来生成训练对(视频帧,正确的顺序)。
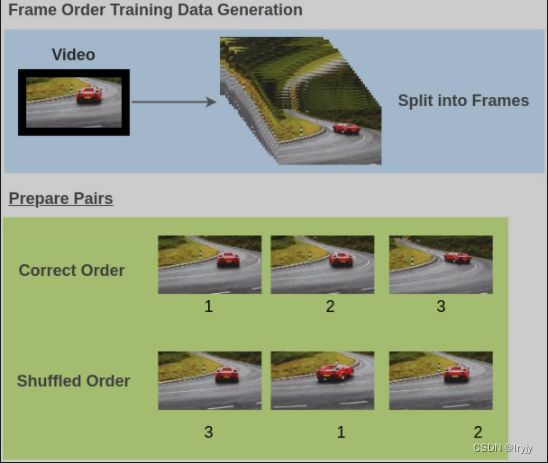
为了解决这个预备任务,Misra等人提出了一个架构,其中视频帧通过共享权重的ConvNets传递,模型必须确定帧的顺序是否正确。在此过程中,该模型不仅学习了空间特征,还考虑了时间特征。
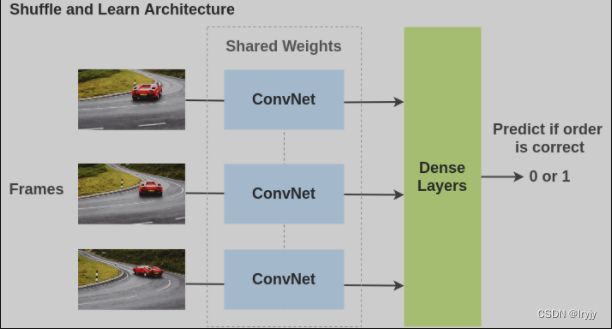
论文:Shuffle and Learn: Unsupervised Learning using Temporal Order Verification
二、对比学习
参考:https://zhuanlan.zhihu.com/p/141141365
对比式学习着重于学习同类实例之间的共同特征,区分非同类实例之间的不同之处。
与生成式学习比较,对比式学习不需要关注实例上繁琐的细节,只需要在抽象语义级别的特征空间上学会对数据的区分即可,因此模型以及其优化变得更加简单,且泛化能力更强(对比学习算法并不一定要关注到样本的每一个细节,只要学到的特征能够使其和其他样本区别开来就行)。
对比学习的目标是学习一个编码器,此编码器对同类数据进行相似的编码,并使不同类的数据的编码结果尽可能的不同。
1.Contrastive Learning Framework
我们的核心就是要学习一个映射函数 f f f,把样本 x x x编码成其表示 f ( x ) f(x) f(x),对比学习的核心就是使得这个 f f f 满足下面这个式子:
![]()
这里的 x + x^+ x+ 就是和 x x x类似的样本, x − x^- x− 就是和 x x x不相似的样本, s ( ⋅ , ⋅ ) s(\cdot ,\cdot) s(⋅,⋅) 这是一个度量样本之间相似程度的函数,一个比较典型的 score 函数就是就是向量内积,即优化下面这一期望:
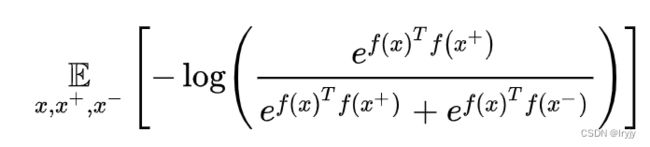
如果对于一个x,我们有1 个正例和 N − 1 N-1 N−1个负例,那么这个 loss 就可以看做是一个 N 分类问题,实际上就是一个交叉熵,而这个函数在对比学习的文章中被称之为 InfoNCE。事实上,最小化这一 loss 能够最大化 f ( x ) f(x) f(x) 和 f ( x + ) f(x^+) f(x+)相互信息的下界,让二者的表示更为接近。理解了这个式子其实就理解了整个对比学习的框架,后续研究的核心往往就聚焦于这个式子的两个方面:
∙ \bullet ∙ 如何定义目标函数?最简单的一种就是上面提到的内积函数,另外一种 triplet 的形式就是 l = m a x ( 0 , η + s ( x , x + ) − s ( x , x − ) ) l=max(0,\eta+s(x,x^+)-s(x,x^-)) l=max(0,η+s(x,x+)−s(x,x−)) ,直观上理解,就是希望正例 pair 和负例 pair 隔开至少 η \eta η的距离,这一函数同样可以写成另外一种形式,让正例 pair 和负例 pair 采用不同的 s s s 函数,例如, s ( x , x + ) = ∣ ∣ m a x ( 0 , f ( x ) − f ( x + ) ) ∣ ∣ s(x,x^+)=||max(0,f(x)-f(x^+))|| s(x,x+)=∣∣max(0,f(x)−f(x+))∣∣ , s ( x , x + ) = ∣ ∣ m a x ( η , f ( x ) − f ( x − ) ) ∣ ∣ s(x,x^+)=||max(\eta,f(x)-f(x^-))|| s(x,x+)=∣∣max(η,f(x)−f(x−))∣∣。
∙ \bullet ∙ 如何构建正例和负例?针对不同类型数据,例如图像、文本和音频,如何合理的定义哪些样本应该被视作是 x + x^+ x+,哪些该被视作是 x − x^- x−,;如何增加负例样本的数量,也就是上面式子里的 N N N?这个问题是目前很多 paper 关注的一个方向,因为虽然自监督的数据有很多,但是设计出合理的正例和负例 pair,并且尽可能提升 pair 能够 cover 的 semantic relation,才能让得到的表示在 downstream task 表现的更好。
初阶
一. Ins+Disc
论文标题:Unsupervised Feature Learning via Non-Parametric Instance-level Discrimination
论文链接:https://arxiv.org/abs/1805.01978
个体判别任务
动机:

数据本身的明显相似性使某些类比其他类更接近。无监督方法即将对类的监督发挥到了极致,并学习了在各个实例之间进行区分的特征表示。
方法:(通过一个卷积神经网络,把所有的图片编码成一个特征。使得这些特征能够在最后的特征空间中可以被区分。通过对比学习去学习这个神经网络。)
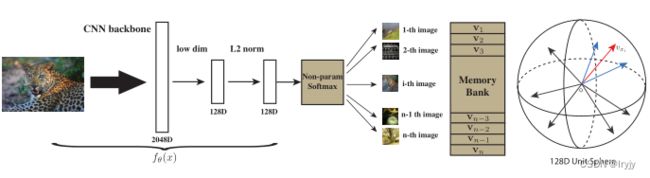
(1)正样本为图像本身(可能经过了数据增强),负样本为数据集里的其它图片。大量的负样本特征存在‘Memory Bank’字典里。
(2)具体来说,256维度的正样本作为CNN backbone的输入,输出为2048维度特征,再下降到128维,再归一化。这里抽出了4096个负样本,然后通过NCE Loss计算对比学习的目标函数。最后把更新完网络后本次minibatch中的特征替换掉‘Memory Bank’字典里的对应特征。
亮点:提出了个体判别这个代理任务,并且用这个代理任务和NCE loss做对比学习,取得了不错的表征学习结果。提出了用别的数据结构去存储大量的负样本,以及如何对这些特征进行动量更新。
二.InvaSpread
论文标题:Unsupervised Embedding Learning via Invariant and Spreading Instance Feature
论文链接:https://arxiv.org/abs/1904.03436
个体判别任务
Motivation and Contribution:

相似的图片,它们之间的特征应该保持不变。不同的图片之间的特征应该尽量散开。
∙ \bullet ∙ 我们提出了一种新的基于实例特征的softmax嵌入方法来学习数据扩充不变量和实例展开特征。它实现了比所有竞争方法更快的学习速度和更高的准确性。
∙ \bullet ∙我们证明了数据扩充不变量和实例扩展属性对于实例智能无监督嵌入学习都是重要的。它们有助于捕获样本之间明显的视觉相似性,并很好地概括了看不见的测试类别。
∙ \bullet ∙与其他无监督学习方法相比,该方法在综合图像分类和嵌入学习实验中取得了最新的性能。
Method:

(1)前向过程:256张图片作为输入,经过数据增强下面得到256张图片。对于 x 1 x_1 x1来说, x ^ 1 \hat{x}_1 x^1是它的正样本,负样本为剩下的所有图片,图中即 [ x 2 , x 3 ] [x_2,x_3] [x2,x3]和 [ x ^ 2 , x ^ 3 ] [\hat{x}_2,\hat{x}_3] [x^2,x^3]。现在,正样本数为256,负样本数为 ( 256 − 1 ) × 2 (256-1)\times 2 (256−1)×2。
(2)端到端的训练:从同一个mini batch中选取正负样本,可以用一个编码器做端到端的训练。目标函数为NCE loss的一个变体。
(3)目标函数:
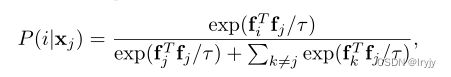
batch size=64
中阶
一.MoCov1
论文标题:Momentum Contrast for Unsupervised Visual Representation Learning
论文链接:https://arxiv.org/abs/1911.05722
代码链接:https://github.com/facebookresearch/moco

问题一:动量过程,如果在SGD中选择动量参数,是不是就不用强调此处的动量机制了
问题二:这里的输入都为x,做了两个不同的数据增强后生成 x q x_q xq与 x k x_k xk,正样本为 N 1 N_1 N1,负样本为 N 2 − N N_{2-N} N2−N。如何在构造目标函数时体现学习正样本表征的。
二.SimCLRv1
论文标题:A Simple Framework for Contrastive Learning of Visual Representations
论文链接:https://arxiv.org/abs/2002.05709
代码链接:https://github.com/google-research/simclr
1.Abstract
本文简化了最近提出的对比自监督学习算法,无需specialized architectures or a memory bank。为了理解对比预测任务学习有用表征的原因,本文系统的研究了框架的主要组成部分:(1)数据扩充的组合在定义有效的预测任务中起着关键作用,(2)在表示和对比损失之间引入可学习的非线性转换,大大提高了学习表示的质量,与监督学习相比,对比学习受益于更大的批量和更多的训练步骤。
2.Introduction
在无监督的情况下学习有效的视觉表征是一个长期存在的问题。大多数主流方法分为两类:生成性(generativ)和区别性(discriminative)。生成方法学习在输入空间中生成或以其他方式建模像素。然而,像素级的生成在计算上是昂贵的,并且对于表示学习可能不是必需的。区别性方法使用与监督学习类似的目标函数学习表示,但训练网络执行代理任务,其中输入和标签都来自未标记的数据集。许多这样的方法依赖于 启发式( heuristics)来设计代理任务,这可能会限制所学表示的通用性。 最近,基于潜在空间对比学习的鉴别方法(contrastive learning in the latent space)显示出巨大的潜力,取得了一流的结果 。
为了理解是什么促成了良好的对比表征学习,我们系统地研究了我们框架的主要组成部分,并表明:
(1) 多个数据扩充操作的组合对于定义产生有效表示的对比预测任务至关重要。此外,与监督学习相比,无监督对比学习从更强的数据扩充中获益。
(2)在表征和对比损失之间引入可学习的非线性变换,可以显著提高学习表征的质量。
(3)具有对比交叉熵损失的表征学习得益于归一化嵌入和适当调整的参数。
(4)与有监督的对比学习相比,对比学习受益于更大的批量和更长的培训时间。与监督学习一样,对比学习也得益于更深更广的网络。
3.Method
3.1 The Contrastive Learning Framework
受最新对比学习算法的启发,SimCLR通过潜在空间中的对比损失最大化相同数据示例的不同增强视图之间的一致性来学习表示。如下图所示,该框架包括以下四个主要组件。

视觉表征对比学习的简单框架。从同一个增广族(t∼ T和t0∼ T)并应用于每个数据示例,以获得两个相关视图。训练一个基本编码器网络f(·)和一个投影头g(·),以使用对比损耗最大化一致性。训练完成后,我们扔掉投影头g(·),使用编码器f(·)和表示h执行下游任务。

(1) 一种随机数据扩充模块,它随机变换任何给定的数据示例,从而生成同一示例的两个相关视图,表示为 x ~ i \tilde{x}_i x~i和 x ~ j \tilde{x}_j x~j,我们将其视为正对。在这项工作中,我们依次应用了三种简单的增强:随机裁剪,然后调整回原始大小,随机颜色扭曲和随机高斯模糊。我们随机抽取了一个由N个样本组成的小批量,并定义了从该小批量派生的成对增广样本的对比预测任务,得到 2 N 2N 2N个数据点。我们并没有明确列举负样本,与InvaSpread相似,当给定一对正样本时,那么我们对这个小批量中的其它 2 ( N − 1 ) 2(N-1) 2(N−1)个增强样本作为负样本。
实验表明,随机裁剪和颜色失真的组合对于获得良好的性能至关重要。
(2)一种基于神经网络的编码器 f ( ⋅ ) f(\cdot) f(⋅),用于从增强数据示例中提取表示向量。我们的框架允许在不受任何限制的情况下选择各种网络架构。我们选择简单,并采用常用的ResNet 去获得 h i = f ( x i ) = R e s N e t ( x i ) h_i=f(x_i)=ResNet(x_i) hi=f(xi)=ResNet(xi),其中 h i ∈ R d h_i∈ R_d hi∈Rd是平均池化层之后的输出。 本文使用了 ResNet-50 作为 Encoder,输出是 2048 维的向量 h h h。
(3)一种小型神经网络预测头 g ( ⋅ ) g(\cdot) g(⋅),将表示映射到应用对比损失的空间。我们使用具有一个隐藏层的MLP来获得 z i = g ( h i ) = W ( 2 ) σ ( W ( 1 ) h i ) z_i=g(h_i)=W(2)σ(W(1)h_i) zi=g(hi)=W(2)σ(W(1)hi),其中σ是ReLU非线性。这是一个 2 层的MLP,将上一步中2048维的向量 h i , h j h_i, h_j hi,hj进一步映射到128维的隐空间中,得到新的特征表达 z i , z j z_i, z_j zi,zj。最后利用 z i , z j z_i, z_j zi,zj去求loss 完成训练,训练完毕后扔掉预测头,保留编码器用于获取视觉表达(visual representation)。
实验所示,我们发现在 z i z_i zi上而不是 h i h_i hi上定义对比损失是有益的。
(4)为对比预测任务定义的对比损失函数。给定一个集合 x ~ k {\tilde{x}_k} x~k,包括一对正的示例 x ~ i \tilde{x}_i x~i和 x ~ j \tilde{x}_j x~j,对比预测任务旨在定义给定 x ~ i \tilde{x}_i x~i的 x ~ k ≠ i {\tilde{x}_{k \neq i}} x~k=i中的 x ~ j \tilde{x}_j x~j。
重点理解损失的建模过程:
∙ \bullet ∙ 获取样本对之间的表征
图片最后的表征以样本对的方式呈现:

∙ \bullet ∙ 如何衡量样本对之间的相似性
每对样本以及不同对样本之间需要用到余弦相似度来衡量相似关系:
设置 s i m ( u , v ) = u t v / ∣ ∣ u ∣ ∣ ∣ ∣ v ∣ ∣ sim(u,v)=u^tv/||u||||v|| sim(u,v)=utv/∣∣u∣∣∣∣v∣∣表示 l 2 l_2 l2归一化 u u u和 v v v之间的点积(即余弦相似性)。

余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似。越接近-1,就表明夹角越接近180度,也就是两个向量越不相似。 s i m ( u , v ) sim(u,v) sim(u,v)取值范围是 [ − 1 , 1 ] [-1,1] [−1,1], e x p ( s i m ( u , v ) ) exp(sim(u,v)) exp(sim(u,v))取值范围是 [ − 1 / e , e ] [-1/e,e] [−1/e,e](这里没考虑 τ \tau τ)。
某一对图像的相似性loss描述为:
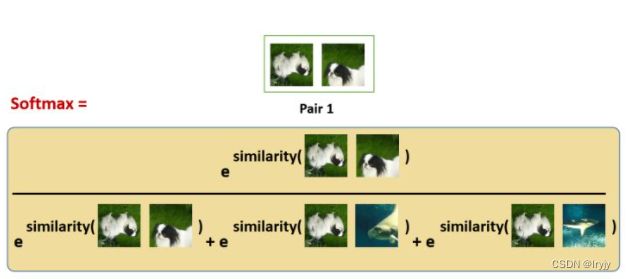
这种 softmax 计算等价于获得第2张增强的狗的图像与该对中的第1张狗的图像最相似的概率。 在这里,分母中的其余的项都是其他图片的增强之后的图片,也是negative samples。
所以我们希望上面的softmax的结果尽量大,所以损失函数取了softmax的负对数:
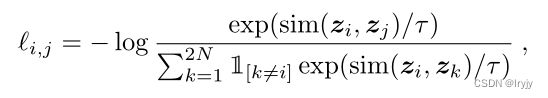
τ \tau τ是可调节的Temperature 参数。它能够scale 输入并扩展余弦相似度 [ − 1 , 1 ] [-1, 1] [−1,1]这个范围。这里可以看出,我们用余弦相似度来衡量相似性,交叉熵loss是用信息熵来衡量相似性,已知余弦相似度的label为0,可以进行数学转化。
∙ \bullet ∙ 任意对图像之间的相似性
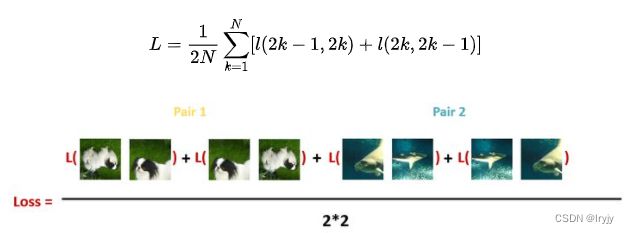
我们知道了衡量一对图像之间的相似性还不够,我们需要对着2N张图像进行建模,并转化成一个能学习每一对的Loss Function。

最后,计算每个Batch里面的所有Pair的损失之和取平均:
∙ \bullet ∙ 整个对比学习的伪代码为

3.2 Training with Large Batch Size
我们将训练批大小N从256更改为8192。从两个扩充视图来看,8192的批大小为每个正对提供16382个负示例。当使用标准SGD /动量和线性学习率缩放时,大批量的培训可能不稳定。为了稳定培训,我们对所有批量使用LARS优化器。
全局的BN。在具有数据并行性的分布式训练中,BN均值和方差通常在每个设备上进行局部聚合。在我们的对比学习中,由于**正对是在同一个设备中计算的,因此该模型可以利用局部信息泄漏来提高预测精度,而无需改进表示。**我们通过在训练期间汇总所有设备的BN均值和方差来解决这个问题。其他方法包括跨设备洗牌数据示例,或用LN范替换BN。
4. Data Augmentation for Contrastive Representation Learning
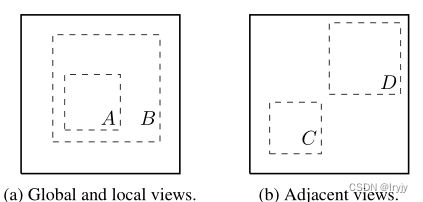
数据增强还没有被认为是一种系统的方法来定义对比预测任务。许多现有方法通过改变体系结构来定义对比预测任务。例如,Hjelm等人(2018年);Bachman et al.(2019)通过限制网络架构中的感受野实现全局到局部的视图预测,而Oord et al.(2018);Hénaff等人(2019年)通过固定的图像分割程序和上下文聚合网络实现相邻视图预测。我们表明,通过对目标图像执行简单的随机裁剪(调整大小),可以避免这种复杂性,这将创建一系列包含上述两个任务的预测任务,如上图所示。这种简单的设计选择方便地将预测任务与其他组件(如神经网络体系结构)解耦。更广泛的对比预测任务可以通过扩展扩充家族并随机组合来定义。
(1)数据扩充操作的组合对于学习良好的表示至关重要
∙ \bullet ∙ 一种类型的增强涉及数据的空间/几何变换,例如裁剪和调整大小(水平翻转)、旋转和剪切 。
∙ \bullet ∙ 另一种类型的增强涉及外观变换,例如颜色失真(包括颜色下降、亮度、对比度、饱和度、色调)(Howard,2013;Szegedy等人,2015)、高斯模糊和Sobel滤波。
为了了解单个数据扩充的效果和扩充组合的重要性,我们研究了单独或成对应用扩充时框架的性能。

上图显示了单个和组合变换下的线性评估结果。我们观察到,没有任何单一的转换足以学习良好的表征,即使该模型几乎可以完美地识别对比任务中的正对。在组合增强方案时,对比预测任务变得更加困难,但表示质量显著提高。
(2)对比学习比监督学习需要更强的数据扩充

更强的颜色增强显著改善了学习的无监督模型的线性评估。这种情况下,AutoAugment(Cubuk et al.,2019)是一种使用监督学习发现的复杂增强策略,其效果并不比简单裁剪+颜色失真(更强)效果更好。当使用相同的增广集训练监督模型时,我们观察到更强的颜色增广不会改善甚至损害其性能。因此,我们的实验表明,与监督学习相比,无监督对比学习从更强的(颜色)数据扩充中获益。
5. Architectures for Encoder and Head
(1)无监督对比学习从更大的模型中获益(更多)
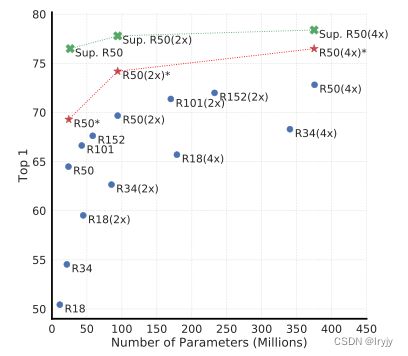
(蓝色为我们迭代100epoch,红色为迭代1000epoch,绿色为有监督训练。)
我们发现,随着模型大小的增加,监督模型与在无监督模型上训练的线性分类器之间的差距缩小,这表明无监督学习从更大的模型中比从监督模型中获益更多。
(2)非线性预测头可以改善前一层的表示质量(这应该是加激活函数的作用大)
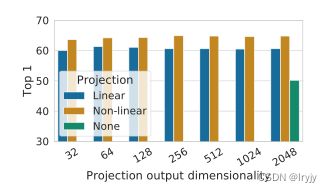
这里的非线性为ReLU。我们观察到,非线性投影比线性投影好(+3%),比无投影好得多(>10%)。使用投影头时,无论输出尺寸如何,都可以观察到类似的结果。此外,即使使用非线性投影,投影头之前的层h仍然比之后的层z=g(h)好得多(>10%),这表明投影头之前的隐藏层比之后的层更好。
我们推测,在非线性投影之前使用表示的重要性是由于对比损失导致的信息损失。(作用和神经网络中使用非线性激活函数作用相似,非线性可分更多维度的信息,线性可分的信息有限。)
6. Loss Functions and Batch Size
(1)温度( τ \tau τ)可调的归一化交叉熵损失比其他方法效果更好

第一二个损失有效地加权了不同的样本,适当的温度( τ \tau τ)可以帮助模型从硬负片中学习; 与交叉熵不同,其他目标函数不通过其相对硬度来衡量负项。因此,必须对这些损失函数应用半硬负挖掘(Schroff et al.,2015):不是计算所有损失项上的梯度,而是可以使用半硬负项计算梯度(即,那些在损失幅度内且距离最近,但比正例更远的项)。

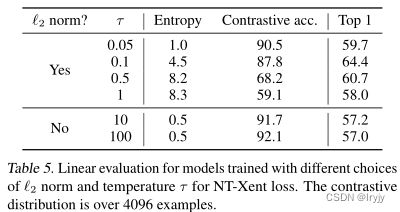
上图所示,如果没有标准化和适当的温度缩放,性能会显著下降。如果没有l2 normalization,对比任务的准确性较高,但在线性评估下,结果表现较差。
为了使比较公平,我们对所有损失函数使用相同的l2归一化,并调整超参数,并报告其最佳结果。虽然(半硬)负挖掘有帮助,但最好的结果仍然比我们默认的NT Xent损失糟糕得多。
(2)对比学习从更大的批量和更长的培训中获益(更多)
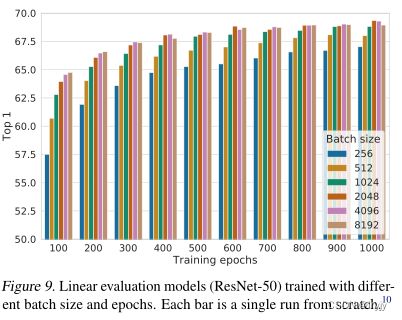
我们发现,当训练次数较少(例如100个)时,较大的批量比较小的批量具有显著的优势。随着训练步骤的增多,如果批次被随机重新采样,不同批次大小之间的差距就会减小或消失。相比于监督学习,在对比学习中,较大的批量提供了更多的负面示例,促进了收敛(即,为获得给定的准确度,采用较少的时间和步骤)。更长时间的培训也会提供更多的负面例子,从而改善结果。
7. Comparison with State-of-the-art
高阶
一. MoCoV2
二.SimCLRv2
论文标题:Big Self-Supervised Models are Strong Semi-Supervised Learners
论文链接:https://arxiv.org/abs/2006.10029
代码链接:https://github.com/google-research/simclr
1.Abstract
在充分利用大量未标记数据的同时,从少数标记示例中学习的一个范例是无监督的预训练,然后是有监督的微调。虽然这种范式以任务无关的方式使用未标记的数据,但与计算机视觉中常用的半监督学习方法相比,我们发现它对于ImageNet上的半监督学习非常有效。我们方法的一个关键要素是在预训练和微调期间使用大型(深度和广度)网络。我们发现,标签越少,这种方法(未标记数据的任务无关使用)从更大的网络中获益越多。在微调之后,通过第二次使用未标记的样本,但以特定于任务的方式,可以进一步改进大网络并将其提取为更小的网络,而分类精度几乎没有损失。所提出的半监督学习算法可归纳为三个步骤:**使用SimCLRv2对大型ResNet模型进行无监督预训练,对几个标记的示例进行监督微调,以及使用未标记的示例进行蒸馏,以提炼和传递特定于任务的知识。**此过程仅使用1%的标签即可实现73.9%的ImageNet top-1精度(≤每类13个标记图像)使用ResNet-50,标签效率比以前的技术状态提高了10倍。对于10%的标签,用我们的方法训练的ResNet-50达到77.5%的top-1准确率,优于所有标签的标准监督训练。
2.Introduction
在机器学习中,一个长期存在的问题是在充分利用大量未标记数据的同时,仅从几个标记的示例中学习。半监督学习的一种方法包括无监督或自我监督的预训练,然后是监督微调。该方法在预训练期间以任务无关的方式利用未标记的数据,因为受监督的标签仅在微调期间使用。虽然这种方法在计算机视觉中很少受到关注,但它在自然语言处理中已占主导地位,首先在未标记文本(如维基百科)上训练一个大型语言模型,然后在几个标记示例上微调模型。计算机视觉中常见的另一种方法是在监督学习期间直接利用未标记的数据,作为一种正则化形式。这种方法以特定于任务的方式使用未标记数据,以鼓励在不同模型之间或在不同数据扩充下对未标记数据的类标签预测一致性。
受视觉表征自我监督学习最新进展的推动,本文首先对ImageNet上半监督学习的“无监督预训练,监督微调”范式进行了深入研究。在自监督的预训练过程中,使用的图像没有类别标签(以任务无关的方式),因此表征不是直接针对特定的分类任务定制的。通过对未标记数据的不可知任务使用,我们发现网络大小很重要:使用大型(深度和广度)神经网络进行自我监督的预训练和微调,可以大大提高精度。除了网络大小之外,我们还描述了一些有利于监督微调和半监督学习的对比表征学习的重要设计选择。
一旦对卷积网络进行了预训练和微调,我们发现其特定于任务的预测可以进一步改进并提炼成更小的网络。为此,我们第二次使用未标记的数据来鼓励学生网络模仿教师网络的标签预测。因此,我们使用未标记数据的方法的蒸馏阶段让人想起在自训练中使用伪标记,但没有太多额外的复杂性。
总之,被提出的半监督学习框架包括三个步骤,如下图所示:(1)无监督或自监督的预训练(2)有监督的微调(3)使用未标记数据的蒸馏。我们开发了最近提出的对比学习框架SimCLR的一个改进变体,用于对ResNet体系结构进行无监督的预训练。我们将此框架称为SimCLRv2。我们在ImageNet ILSVRC-2012上评估了我们的方法的有效性,只有1%和10%的标记图像可用。我们的主要发现和贡献总结如下:

∙ \bullet ∙ 我们的实验结果表明,对于半监督学习(通过对未标记数据的任务不可知使用),标签越少,越有可能从更大的模型中获益(下图)。更大的自我监督模型更有标签效率,在仅对少数标记的示例进行微调时,性能会显著提高,即使它们有更大的潜在过度拟合能力。

∙ \bullet ∙ 我们表明,虽然大型模型对于学习一般(视觉)表示很重要,但对于特定的目标任务,可能不需要额外的能力。因此,通过特定任务使用未标记数据,可以进一步提高模型的预测性能,并将其传输到较小的网络中。
∙ \bullet ∙ 我们进一步证明了在SimCLR中使用卷积层进行半监督学习后,非线性变换(也称为投影头)的重要性。更深的投影头不仅提高了通过线性评估测量的表示质量,而且在从投影头的中间层进行微调时,还提高了半监督性能。
2.Method
(1)self-supervised pretraining with SimCLRv2
这是SimCLRv1的建模过程:

在这项工作中,我们提出了SIMCLR2,它在三个主要方面对SimCLR进行了改进。1.为了充分利用预训练的力量,我们探索了更大的ResNet模型(SimCLR的最大模型是ResNet-50(4×),我们训练的模型更深,但宽度更小。我们训练的最大模型是一个152层的ResNet)。2.我们还通过加深非线性网络 g ( ⋅ ) g(\cdot) g(⋅)(也称为投影头)的容量来增加其容量。此外,与SimCLR中的预训练后完全丢弃 g ( ⋅ ) g(\cdot) g(⋅)不同,我们从中间层进行微调(稍后详述)。这一微小的变化使得线性评估和微调都有了显著的改进,只需使用几个标记的示例(与具有2层投影头的SimCLR相比,通过使用3层投影头并从投影头的第一层进行微调,当对1%的标记示例进行微调时,它在top-1精度方面的相对提高高达14%)。3.我们还结合了MoCo中的记忆机制,该机制指定了一个记忆网络(具有用于稳定的权值移动平均值),其输出将作为负面样本进行缓冲。(由于我们的训练是基于已经提供了许多对比负面样本的大型minibatch,因此此更改将改进∼1%用于线性评估,以及微调1%的标记示例时)
(2)Fine-tuning
微调是使任务不可知预训练网络适应特定任务的常用方法。在SimCLR中,MLP投影头 g ( ⋅ ) g(\cdot) g(⋅)在预训练后被完全丢弃,而在微调期间仅使用ResNet编码器 f ( ⋅ ) f(\cdot) f(⋅)。我们建议在微调期间将MLP投影头的一部分合并到基本编码器中,而不是将其全部丢弃。换句话说,我们从投影头的中间层微调模型,而不是像SimCLR中那样从投影头的输入层微调模型。请注意,从MLP头的第一层进行微调与向基本网络添加一个全连接层并从头中移除一个完连接层是相同的,并且这个额外层的影响取决于微调期间标记的示例的数量。
(3)Self-training / knowledge distillation via unlabeled examples
为了进一步改进目标任务的网络,这里我们直接为目标任务使用未标记的数据。我们使用微调网络作为教师来估算标签,以训练学生网络。具体而言,在没有使用真正标签的情况下,我们将以下蒸馏损失降至最低:
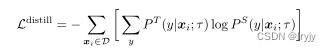
上面是一个交叉熵loss, P T ( ⋅ ) P^T(\cdot) PT(⋅)为教师网络, P S ( ⋅ ) P^S(\cdot) PS(⋅)为学生网络。
虽然我们在这项工作中只关注使用未标记样本的蒸馏,但当标记样本的数量很大时,也可以使用加权组合将蒸馏损失与标签标记示例相结合:
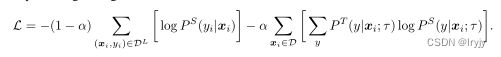
3.实验
总结
对比方法部分持续更新中…