分享 | masked自编码器(MAE):一种可扩展的用于计算机视觉任务的自监督学习器
本文证明了masked自编码器(MAE)是一种可扩展的用于计算机视觉任务的自监督学习器。作者的masked自编码器的方法很简单,作者随机mask掉输入图像patches,然后去重构丢失的像素(丢失的像素是被随机mask掉的图像patch)。
主要基于两个核心的设计,首先,作者开发了一个非对称编码器-解码器体系结构,其中编码器仅在可见的patch上运行(没有被mask的patch),同时还有一个轻量级解码器,用于从潜在表征和mask标记重建原始图像,到这里,我的理解,就是输入的是不完整的信息,然后通过编解码结构去重构原始信息,让编解码结构真正理解图像内容,毕竟有能力重构,那肯定是在理解的基础上的做到的。其次,作者发现mask高比例的输入图像(例如75%的patch都被mask)效果较佳。这样的设计,使作者能够高效地训练大型模型:加快训练速度(3倍或更多)并提高精度。
作者的可扩展方法允许学习具有良好通用性的高容量模型:例如,在仅使用ImageNet-1K数据的方法中,vanilla ViT大模型的精确度最高(87.8%)。下游任务中的迁移性能优于有监督的预训练。说白了,迁移性能比较好,对其他任务的帮助很大。
介绍
1. 深度学习见证了能力(简单理解为模型的性能)和容量(模型的复杂度和参数量等)不断增长的体系结构的爆炸式增长。在硬件快速增长的帮助下,如今的模型可以轻易过拟合超过一百万张图像。
2. 自然语言处理(NLP)通过自监督预训练成功地解决了这种对数据的偏好。基于GPT中的自回归语言建模和BERT中的masked自编码的解决方案在概念上很简单:它们删除部分数据并学习删除的内容。这些方法现在可以训练包含超过1000亿个参数的可推广NLP模型。Masked自编码已经有人在做了,并且这种方法比较好使。
3. mask自编码器是一种更通用的去噪自编码器,它的思想是自然的,也适用于计算机视觉(mask掉,然后让模型学习丢失的信息,常规理解,也就是能让模型理解我们的数据,所以说思想是非常自然的)。NLP中已经很早就在使用了,为什么计算机视觉中迟迟没有使用上呢,CV和NLP到底是因为哪些差异,导致在mask自编码的应用情况完全不同?作者从以下几个角度回答了问题:
(1)NLP和CV架构还是不同的。在CV上,卷积网络在过去十年中占主导地位。卷积通常在规则网格上运行(比如图像这种规则的结构化数据),将“指示符”(如掩码或位置)集成到卷积网络中并不容易。然而,随着transformer的引入,这一架构差距已经得到解决,不应再构成障碍。
(2)语言和视觉的信息密度是不同的。语言是人类产生的信号,具有高度的语义和信息密度。当训练一个模型来预测仅仅遗漏少量单词的句子时,因为语义和信息密度的原因,可能会完全曲解句子原有的意思。相反地,对于图像来说,具有高度空间冗余的自然信号,例如,如果图像缺少了一个patch。可以从该patch的邻居patch所富有的信息中恢复该patch的信息。为了克服NLP和CV的这种差异,作者展示了一种简单的策略,这种策略在计算机视觉中很有效:mask很高比例的随机patch。这一策略大大减少了冗余,并创建了一个具有挑战性的自监督任务,这个任务会学习从整体上理解图像,这种理解是超越了低层的像素认知,而是一种高层次上的场景理解,如下图2、图3和图4所示。

图2 ImageNet验证集图像的展示。对于每三对图像,最左边的是被mask之后的图像,中间的是MAE重构之后的图像,最右边的是原始图像。图像的掩盖率是80%(196个patch中仅剩下39个)

图3 COCO验证集图像的展示。这里所重构出来的图像(中间的那张)所使用的的模型是在ImageNet上训练得到的。和图2中所使用模型的权重一样。从图中可以看出,虽然重构出来图像和真值还是有差异的,但是语义上是合理的(小编觉得,何止是合理,简直神了)

图4 使用掩蔽率为75%的MAE预训练重建ImageNet验证图像,但应用于掩蔽率较高的输入。预测结果与原始图像不同但相似,表明该方法可以推广
(3)自编码器的解码器将潜在表征映射回输入,在重建文本和图像之间起着不同的作用。在视觉中,解码器重建像素,因此其输出的语义级别低于普通识别任务。这与语言相反,在语言中,解码器预测包含丰富语义信息的缺失单词。虽然在BERT中,解码器容量可能很小(一个MLP),但对于图像,解码器设计起着关键作用。解码器的设计,关乎能否将潜在表征(编码器提取的特征)映射回原始输入,不能像NLP那样设计,应该有其独特的风格。
4. 在这一分析的推动下,作者提出了一种简单、有效、可扩展的mask自编码器(MAE),用于视觉表征学习。作者的MAE从输入图像中mask随机patch,并在像素空间中重建丢失的patch。它有一个非对称的编解码器设计。作者的编码器只对可见的patch子集(不带掩码信息)进行操作,作者的解码器是轻量级的,可以从潜在表征和掩码信息重建输入(如图1)。在作者的非对称编码器-解码器中,将掩码信息转移到小型解码器会大大减少计算量。在这种设计下,非常高的掩蔽率(例如75%)优化了精度,同时允许编码器仅处理一小部分(例如25%)patch。这可以将总体预训练时间减少3倍或更多,同样可以减少内存消耗,能够轻松地将MAE扩展到大型模型。

图1 作者提出的整体架构 在预训练期间,原始图像被划分为若干个patch,然后会掩盖其中75%的patch,编码器应用在可见的patch上,编码完成之后,掩码令牌被引入,所有编码完成的patch和掩码令牌由一个小型解码器处理,该解码器以像素为单位重建原始图像。在预训练之后,解码器被丢弃,编码器被应用于未损。
5. 作者的MAE学习非常高容量的模型,这些模型具有很好的通用性。通过MAE预训练,可以在ImageNet-1K上训练非常吃数据的模型,如ViT Large/-MARGE,提高其泛化性能。使用vanilla ViT大模型,在ImageNet-1K上进行微调时,实现了87.8%的精度。这比以前所有只使用ImageNet-1K数据的结果都要好(即以这种方式进行预训练,然后将其应用于下游任务效果更好)。作者还评估了迁移到目标检测、实例分割和语义分割方面的应用。在这些任务中,作者的预训练取得了更好的结果。
一些相关的工作
带有掩码的语言模型
带有掩码的语言模型及其对应的自回归方法,如BERT和GPT,是NLP中非常成功的预训练方法。这些方法保留了输入序列的一部分,并训练模型来预测缺失的内容。这些方法已被证明具有良好的可扩展性,大量证据表明,这些预先训练好的表示法可以很好地推广到各种下游任务。
自编码
自编码是学习特征的经典方法。它有一个将输入映射到潜在表征的编码器和一个重建输入的解码器。例如,PCA和k-均值是自编码器。去噪自编码器(DAE)是一类损坏输入信号并学习重建原始未损坏信号的自编码器。可以将一系列方法视为不同损坏情况下的广义DAE,例如掩蔽像素或移除颜色通道。作者的MAE是一种去噪自编码形式,但在许多方面与经典DAE不同。
带有掩码的图像编码器
带有mask的图像编码方法从被mask损坏的图像中学习表示。这项开创性的工作将mask作为DAE(去躁自编码)中的一种噪声类型。上下文编码器使用卷积网络修复大型缺失区域。由于NLP的成功,最近的相关方法都是基于transformer的。
自监督学习
自监督学习方法对计算机视觉产生了极大的兴趣,通常侧重于为不同的任务进行预训练。近年来,对比学习得到了广泛的应用,它对两个或多个视图之间的图像相似性和差异性(或仅相似性)进行建模。对比学习强烈依赖于数据扩充。而自编码致力于一个概念上不同的方向。
方法
作者的带有mask的自编码器(MAE)是一种简单的自编码方法,它根据原始信号的部分观测结果重建原始信号。像所有的自编码器一样,作者的方法有一个编码器将观察到的信号映射到潜在表征,还有一个解码器从潜在表征重建原始信号。与经典的自编码器不同,作者采用了一种非对称设计,允许编码器仅对部分观察信号(无掩码标记)进行操作,并采用一种轻量级解码器,从潜在表征和掩码标记重建完整信号。图1说明了下面介绍的想法。
掩码
像VIT一样,作者将图像分割为规则的非重叠patch。然后,作者对一个子集的patches进行采样,并mask(即移除)剩余的patch。作者的采样策略很简单:按照均匀分布随机对patch进行采样。作者简称其随机抽样。具有高掩蔽率(即移除的patch的比率)的随机采样在很大程度上消除了冗余,因此创建了一个无法通过从可见相邻patch外推来轻松解决的任务(见图2-4)。均匀分布可防止潜在的中心偏移(即图像中心附近有更多patch)。最后,高度稀疏的输入为设计高效编码器创造了机会。
带有mask的自编码器
作者的编码器是ViT,但仅适用于可见的、无mask的patch。就像在标准ViT中一样,作者的编码器通过添加位置特征的线性映射编码patch,然后通过一系列transformer块处理结果集。然而,作者的编码器只在整个集合的一小部分(例如25%)上运行,去除被掩盖的patch;不使用掩码令牌(即编码的时候使用未被掩码的patch,解码的时候仅仅在可见的patch特征进行,并使用掩码信息)。这使能够用一小部分的计算和内存来训练非常大的编码器。整个集合由轻量级解码器处理
带有mask的解码器
MAE解码器的输入是由(i)编码好的未被mask掉的patch表征和(ii)掩码信息。见图1。每个掩码标记都是一个共享的可学习的向量,表示要被预测的缺失的patch的存在。解码器添加了一系列的mask位置信息。解码器由一系列transformer块组成。MAE解码器仅在预训练期间用于执行图像重建任务(仅编码器用于生成用于识别的图像表示)。因此,解码器架构可以在独立于编码器进行灵活设计。作者用非常小的解码器进行实验,比编码器更窄、更浅。这大大减少了预训练时间。
重建目标
作者的MAE通过预测每个mask后的patch的像素值来重建输入。解码器输出中的每个元素都是表示patch的像素值向量。解码器的最后一层是一个线性投影,其输出通道的数量等于patch中像素值的数量。解码器的输出被重塑以形成重构图像。作者的损失函数计算像素空间中重建图像和原始图像之间的均方误差(MSE)。作者仅在maksed的patch上计算loss,类似于BERT。作者还研究了重建目标是每个masked patch的归一化像素值。具体来说作者计算一个patch中所有像素的平均值和标准偏差,并使用它们来规范化该patch。在作者的实验中,使用归一化像素作为重建目标提高了表征质量
简单实现
作者的MAE预训练可以有效实施,而且重要的是,不需要任何专门的稀疏操作。首先,作者为每个输入patch生成一个token(通过添加位置嵌入的线性投影)。接下来,作者随机洗牌token列表,并根据掩蔽率删除列其中一部分。此过程为编码器生成一小部分的token。编码后,作者将掩码token列表附加到已编码patch列表中(并恢复原始位置),以将所有token与其目标对齐。解码器应用于这个完整列表(添加了位置嵌入)。如前所述,不需要稀疏操作。这个简单的实现引入了可忽略不计的开销,因为shuffle和取消洗牌操作速度很快。
实验
作者在ImageNet-1K训练集上做自监督预训练,为了评估这种预训练带来的好处,作者使用两种方式:(1)端到端的微调(2)线性探测。原始输入图像的尺寸是224X224。
Baseline:ViT-Large. 在消融实验中,作者使用Vit-large作为backbone。ViT-L非常大(比ResNet-50[24]大一个数量级)。
从头开始训练Vit-large与使用作者提出的MAE方法微调的比较结果如下图,左边是原始的效果,中间是作者的复现结果(用了一个具有强正则化的方法),最右边的是作者提出的MAE的效果。即使如此,作者的MAE预训练也有很大的改进。在这里,微调只适用于50个epoch(与从头开始的200个相比,训练更快了),这意味着微调精度在很大程度上取决于预训练。
![]()
实验的设置如下,灰色背景的为默认配置:
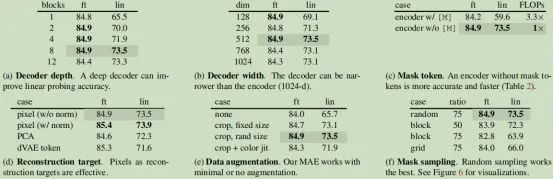
表1 使用ViT-L/16在ImageNet-1K上进行MAE消融实验。我们报告了微调(ft)和线性探测(lin)精度(%)。如果未指定,默认值为:解码器的深度为8,宽度为512,重建目标为非标准化像素,数据增强为随机调整大小的裁剪,掩蔽率为75%,预训练长度为800个epoch。默认设置以灰色标记
图5展示了掩码率的影响,最佳比率出人意料地高。75%的比率适用于线性探测和微调。这种行为与BERT相反,BERT典型掩蔽率为15%。作者的掩蔽率也远高于相关工作中的掩蔽率(20%至50%)。该模型推断缺失的patch会产生不同但相似的输出(图4)。它可以理解物体和场景,而这不能简单地通过延伸线条或纹理来完成。作者假设这种类似推理的行为与学习有用的表征有关。
图5还显示了线性探测和微调结果遵循不同的趋势。对于线性探测,精度随着掩蔽率的增加而稳定增加,直到达到最低点:精度差距达到20%(54.6%对73.5%)。对于微调,结果对比率的敏感度较低,并且大范围的掩蔽比率(40–80%)效果较好。图5中的所有微调结果都优于从头开始的训练(82.5%)。
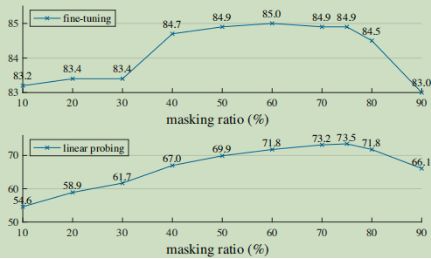
图5 掩蔽比。高掩蔽率(75%)适用于微调(顶部)和线性探测(底部)。本文中所有图的y轴均为ImageNet-1K验证精度(%)
作者:张强
|深延科技|
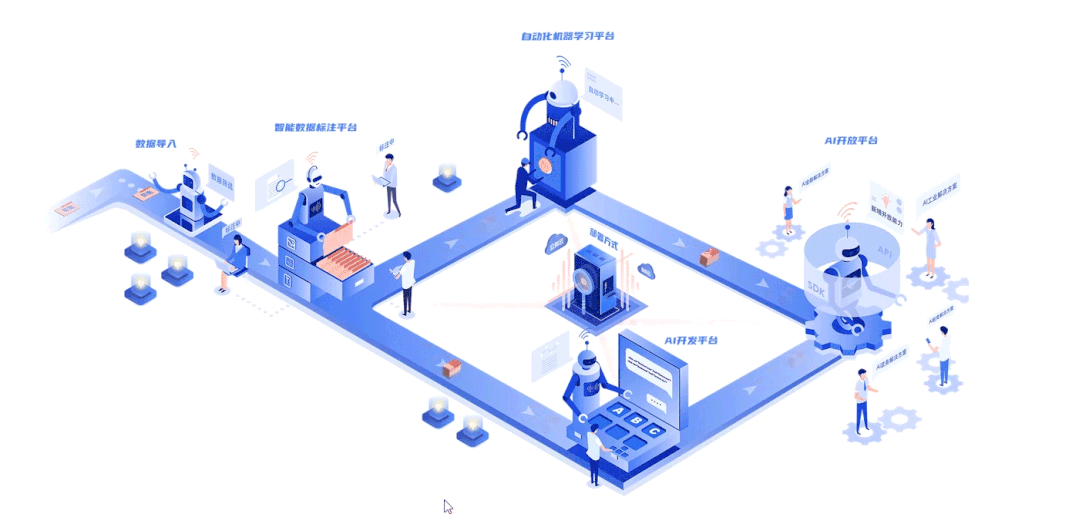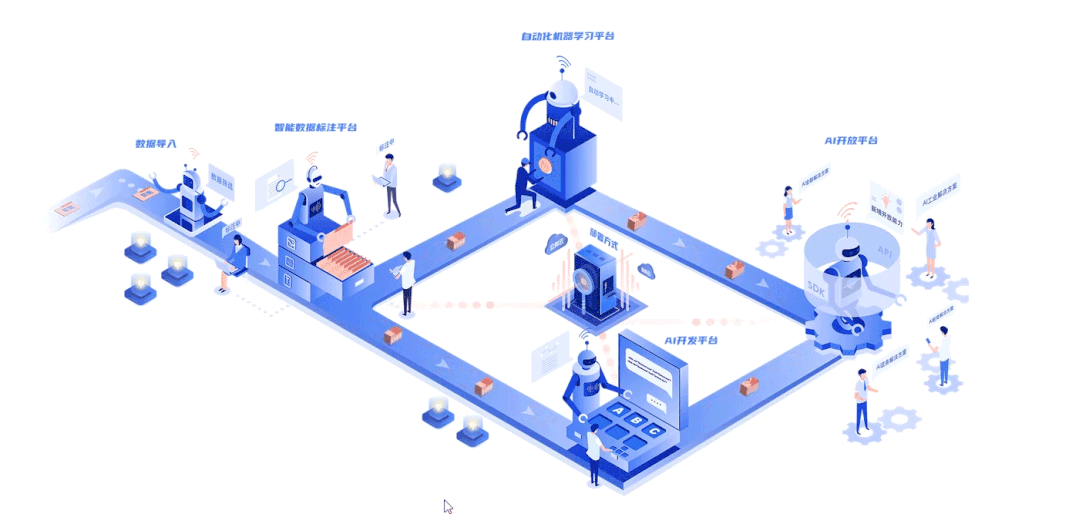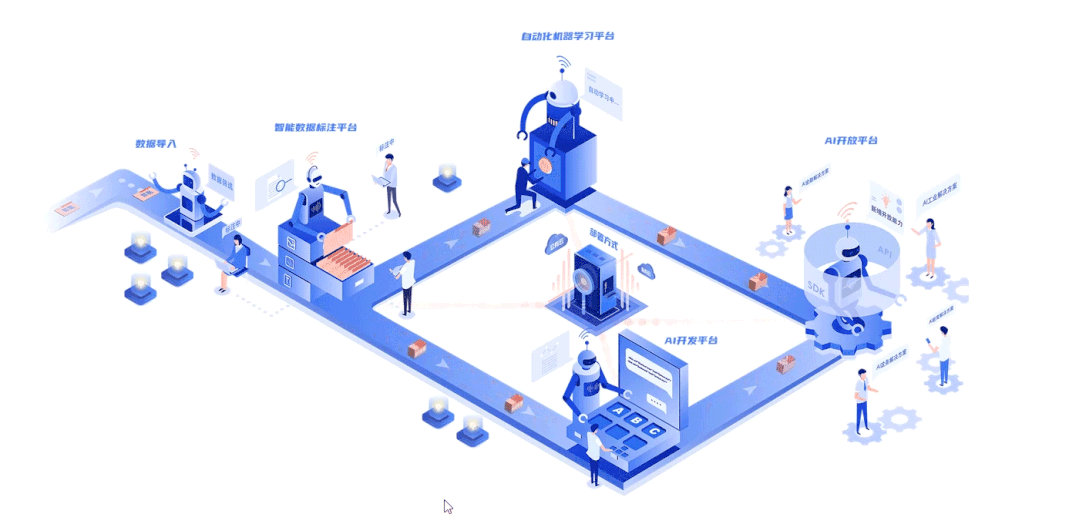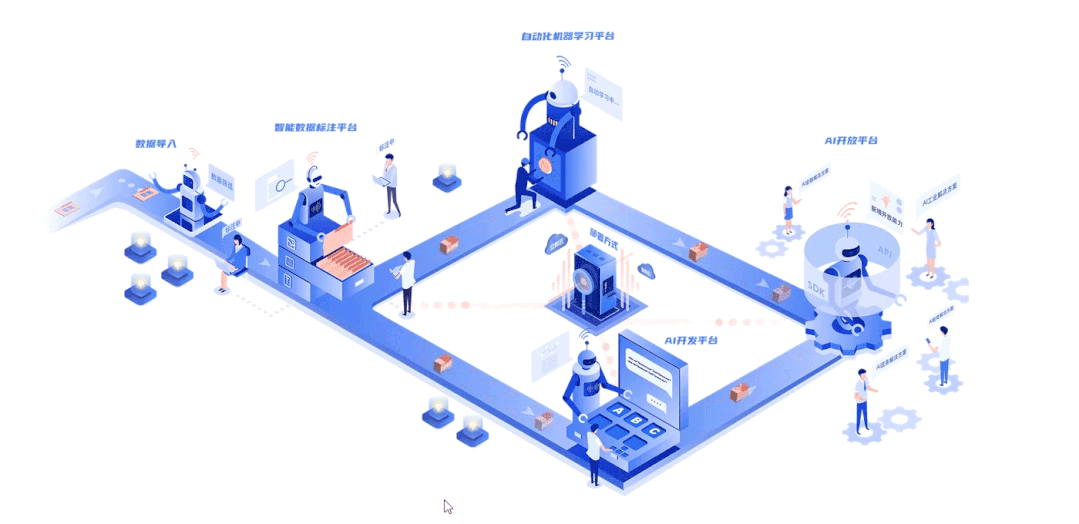
深延科技成立于2018年,是深兰科技(DeepBlue)旗下的子公司,以“人工智能赋能企业与行业”为使命,助力合作伙伴降低成本、提升效率并挖掘更多商业机会,进一步开拓市场,服务民生。公司推出四款平台产品——深延智能数据标注平台、深延AI开发平台、深延自动化机器学习平台、深延AI开放平台,涵盖从数据标注及处理,到模型构建,再到行业应用和解决方案的全流程服务,一站式助力企业“AI”化。