Python机器学习基础篇一《为什么用Python进行机器学习》
机器学习(machine learning)是从数据中提取知识。它是统计学、人工智能和计算机科学交叉的研究领域,也被称为预测分析(predictive analytics)或统计学习(statistical learning)。近年来,机器学习方法已经应用到日常生活的方方面面。从自动推荐看什么电 影、点什么食物、买什么商品,到个性化的在线电台和从照片中识别好友,许多现代化网站和设备的核心都是机器学习算法。当你访问像 Facebook、Amazon 或 Netflix 这样的复杂 网站时,很可能网站的每一部分都包含多种机器学习模型。
除了商业应用之外,机器学习也对当前数据驱动的研究方法产生了很大影响。本书中介绍的工具均已应用在各种科学问题上,比如研究恒星、寻找遥远的行星、发现新粒子、分析 DNA 序列,以及提供个性化的癌症治疗方案。
不过,如果想受益于机器学习算法,你的应用无需像上面那些例子那样给世界带来重大改变,数据量也用不着那么大。本章将解释机器学习如此流行的原因,并探讨机器学习可以 解决哪些类型的问题。然后将向你展示如何构建第一个机器学习模型,同时介绍一些重要的概念。
1.1 为何选择机器学习
在“智能”应用的早期,许多系统使用人为制订的“if”和“else”决策规则来处理数据, 或根据用户输入的内容进行调整。想象有一个垃圾邮件过滤器,其任务是酌情将收到的某些邮件移动到垃圾邮件文件夹。你可以创建一个关键词黑名单,所有包含这些关键词的邮 件都会被标记为垃圾邮件。这是用专家设计的规则体系来设计“智能”应用的一个示例。 人为制订的决策规则对某些应用来说是可行的,特别是人们对其模型处理过程非常熟悉的 应用。但是,人为制订决策规则主要有两个缺点。
- 做决策所需要的逻辑只适用于单一领域和单项任务。任务哪怕稍有变化,都可能需要重写整个系统。
- 想要制订规则,需要对人类专家的决策过程有很深刻的理解。
这种人为制订规则的方法并不适用的一个例子就是图像中的人脸检测。如今,每台智能手机都能够检测到图像中的人脸。但直到 2001 年,人脸检测问题才得到解决。其主要问题 在于,计算机“感知”像素(像素组成了计算机中的图像)的方式与人类感知面部的方式有非常大的不同。正是由于这种表征差异,人类想要制订出一套好的规则来描述数字图像中的人脸构成,基本上是不可能的。
但有了机器学习算法,仅向程序输入海量人脸图像,就足以让算法确定识别人脸需要哪些特征。
1.1.1 机器学习能够解决的问题
最成功的机器学习算法是能够将决策过程自动化的那些算法,这些决策过程是从已知示例中泛化得出的。在这种叫作监督学习(supervised learning)的方法中,用户将成对的输入和预期输出提供给算法,算法会找到一种方法,根据给定输入给出预期输出。尤其是在没有人类帮助的情况下,给定前所未见的输入,算法也能够给出相应的输出。回到前面垃圾邮件分类的例子,利用机器学习算法,用户为算法提供大量电子邮件(作为输入),以及这些邮件是否为垃圾邮件的信息(作为预期输出)。给定一封新邮件,算法就能够预测它是否为垃圾邮件。
从输入 / 输出对中进行学习的机器学习算法叫作监督学习算法(supervised learning algorithm), 因为每个用于算法学习的样例都对应一个预期输出,好像有一个“老师”在监督着算法。虽然创建一个包含输入和输出的数据集往往费时又费力,但监督学习算法很好理解,其性能也易于测量。如果你的应用可以表示成一个监督学习问题,并且你能够创建包含预期输出的数据集, 那么机器学习很可能可以解决你的问题。
监督机器学习任务的示例如下:
1.识别信封上手写的邮政编码
这里的输入是扫描的手写数字,预期输出是邮政编码中的实际数字。想要创建用于构建机器学习模型的数据集,你需要收集许多信封。然后你可以自己阅读邮政编码,将数字保存为预期输出。
2.基于医学影像判断肿瘤是否为良性
这里的输入是影像,输出是肿瘤是否为良性。想要创建用于构建模型的数据集,你需要 一个医学影像数据库。你还需要咨询专家的意见,因此医生需要查看所有影像,然后判 断哪些肿瘤是良性的,哪些不是良性的。除了影像内容之外,甚至可能还需要做额外的诊断来判断影像中的肿瘤是否为癌变。
3.检测信用卡交易中的诈骗行为
这里的输入是信用卡交易记录,输出是该交易记录是否可能为诈骗。假设你是信用卡的发行单位,收集数据集意味着需要保存所有的交易,并记录用户是否上报过任何诈骗交易。
在这些例子中需要注意一个有趣的现象,就是虽然输入和输出看起来相当简单,但三个例 子中的数据收集过程却大不相同。阅读信封虽然很辛苦,却非常简单,也不用花多少钱。 与之相反,获取医学影像和诊断不仅需要昂贵的设备,还需要稀有又昂贵的专家知识,更不要说伦理问题和隐私问题了。在检测信用卡诈骗的例子中,收集数据要容易得多。你的顾客会上报诈骗行为,从而为你提供预期输出。要获取所有欺诈行为和非欺诈行为的输入 / 输出对,你只需等待即可。
本书会讲到的另一类算法是无监督学习算法(unsupervised learning algorithm)。在无监督学习中,只有输入数据是已知的,没有为算法提供输出数据。虽然这种算法有许多成功的 应用,但理解和评估这些算法往往更加困难。
无监督学习的示例如下:
1.确定一系列博客文章的主题
如果你有许多文本数据,可能想对其进行汇总,并找到其中共同的主题。事先你可能并不知道都有哪些主题,或者可能有多少个主题。所以输出是未知的。
2.将客户分成具有相似偏好的群组
给定一组客户记录,你可能想要找出哪些客户比较相似,并判断能否根据相似偏好对这 些客户进行分组。对于一家购物网站来说,客户分组可能是“父母”“书虫”或“游戏 玩家”。由于你事先并不知道可能有哪些分组,甚至不知道有多少组,所以并不知道输出是什么。
3.检测网站的异常访问模式
想要识别网站的滥用或 bug,找到异常的访问模式往往是很有用的。每种异常访问模式 都互不相同,而且你可能没有任何记录在案的异常行为示例。在这个例子中你只是观察流量,并不知道什么是正常访问行为和异常访问行为,所以这是一个无监督学习问题。
**无论是监督学习任务还是无监督学习任务,将输入数据表征为计算机可以理解的形式都是十分重要的。**通常来说,将数据想象成表格是很有用的。你想要处理的每一个数据点(每一封电子邮件、每一名客户、每一次交易)对应表格中的一行,描述该数据点的每一项属性(比如客户年龄、交易金额或交易地点)对应表格中的一列。你可能会从年龄、性别、 账号创建时间、在你的购物网站上的购买频率等方面来描述用户。你可能会用每一个像素的灰度值来描述肿瘤图像,也可能利用肿瘤的大小、形状和颜色进行描述。
在机器学习中,这里的每个实体或每一行被称为一个样本(sample)或数据点,而每一列 (用来描述这些实体的属性)则被称为特征(feature)。
本文后面会更详细地介绍如何构建良好的数据表征,这被称为特征提取(feature extraction)或特征工程(feature engineering)。但你应该记住,如果没有数据信息的话,所有机器学习算法都无法做出预测。举个例子,如果你只有病人的姓氏这一个特征,那么任何算法都无法预测其性别。这一信息并未包含在数据中。如果你添加另一个特征,里面包含病人的名字,那么你预测正确的可能性就会变大,因为通过一个人的名字往往可以判断其性别。
1.1.2 熟悉任务和数据
在机器学习过程中,最重要的部分很可能是理解你正在处理的数据,以及这些数据与你想要解决的任务之间的关系。随机选择一个算法并将你的数据输入进去,这种做法是不会有什么用的。在开始构建模型之前,你需要理解数据集的内容。**每一种算法的输入数据类型和最适合解决的问题都是不一样的。**在构建机器学习解决方案的过程中,你应该给出下列问题的答案,或者至少要将这些问题记在脑中。
- 我想要回答的问题是什么?已经收集到的数据能够回答这个问题吗?
- 要将我的问题表示成机器学习问题,用哪种方法最好?
- 我收集的数据是否足够表达我想要解决的问题?
- 我提取了数据的哪些特征?这些特征能否实现正确的预测?
- 如何衡量应用是否成功?
- 机器学习解决方案与我的研究或商业产品中的其他部分是如何相互影响的?
从更大的层面来看,机器学习算法和方法只是解决特定问题的过程中的一部分,一定要始 终牢记整个项目的大局。许多人浪费大量时间构建复杂的机器学习解决方案,最终却发现 没有解决正确的问题。
当深入研究机器学习的技术细节时(本书会讲到这些细节),很容易忽视最终目标。我们 虽然不会详细讨论上面列出的问题,但仍然鼓励你记住自己在开始构建机器学习模型时做 出的假设,无论是明确的还是隐含的假设。
1.2 为何选择Python
Python 已经成为许多数据科学应用的通用语言。它既有通用编程语言的强大功能,也有特定领域脚本语言(比如 MATLAB 或 R)的易用性。Python 有用于数据加载、可视化、统计、自然语言处理、图像处理等各种功能的库。这个大型工具箱为数据科学家提供了大量的通用功能和专用功能。使用 Python 的主要优点之一,就是利用终端或其他类似 Jupyter Notebook 的工具能够直接与代码进行交互;我们很快会讲到 Jupyter Notebook。机器学习 和数据分析本质上都是迭代过程,由数据驱动分析。这些过程必须要有快速迭代和易于交互的工具。
作为通用编程语言,Python 还可以用来创建复杂的图形用户界面(graphical user interface, GUI)和 Web 服务,也可以集成到现有系统中。
1.3 scikit-learn
scikit-learn 是一个开源项目,可以免费使用和分发,任何人都可以轻松获取其源代码来查看其背后的原理。scikit-learn 项目正在不断地开发和改进中,它的用户社区非常活跃。它包含许多目前最先进的机器学习算法,每个算法都有详细的文档(http://scikit-learn.org/stable/documentation)。scikit-learn 是一个非常流行的工具,也是最有名的 Python 机器学习库。它广泛应用于工业界和学术界,网上有大量的教程和代码片段。scikit-learn 也可以与其他大量 Python 科学计算工具一起使用,本章后面会讲到相关内容。
在阅读本书的过程中,我们建议你同时浏览 scikit-learn 用户指南(http://scikit-learn.org/stable/user_guide.html)和 API 文档,里面给出了每个算法的更多细节和更多选项。在线文档非常全面,而本书会介绍机器学习的所有必备知识,以便于你深入了解。
1.安装scikit-learn
scikit-learn 依赖于另外两个 Python 包:NumPy 和 SciPy。若想绘图和进行交互式开发, 还应该安装 matplotlib、IPython 和 Jupyter Notebook。我们推荐使用下面三个预先打包的 Python 发行版之一,里面已经装有必要的包。
Anaconda(https://store.continuum.io/cshop/anaconda/)
用于大规模数据处理、预测分析和科学计算的 Python 发行版。Anaconda 已经预先安装 好 NumPy、SciPy、matplotlib、pandas、IPython、Jupyter Notebook 和 scikit-learn。 它可以在 Mac OS、Windows 和 Linux 上运行,是一种非常方便的解决方案。对于尚未安装 Python 科学计算包的人,我们建议使用 Anaconda。Anaconda 现在还免费提供商用 的 Intel MKL 库。MKL(在安装 Anaconda 时自动安装)可以使 scikit-learn 中许多算法的速度大大提升。
Enthought Canopy(https://www.enthought.com/products/canopy/)
用于科学计算的另一款 Python 发行版。它已经预先装有 NumPy、SciPy、matplotlib、 pandas 和 IPython,但免费版没有预先安装 scikit-learn。如果你是能够授予学位的学术机构的成员,可以申请学术许可,免费使用 Enthought Canopy 的付费订阅版。 Enthought Canopy 适用于 Python 2.7.x,可以在 Mac OS、Windows 和 Linux 上运行。
Python(x,y)(http://python-xy.github.io/)
专门为 Windows 打造的 Python 科学计算免费发行版。Python(x,y) 已经预先装有 NumPy、 SciPy、matplotlib、pandas、IPython 和 scikit-learn。
如果你已经安装了 Python,可以用 pip 安装上述所有包:
$ pip install numpy scipy matplotlib ipython scikit-learn pandas
1.4 必要的库和工具
了解 scikit-learn 及其用法是很重要的,但还有其他一些库也可以改善你的编程体验。 scikit-learn 是基于 NumPy 和 SciPy 科学计算库的。除了 NumPy 和 SciPy,我们还会用 到 pandas 和 matplotlib。我们还会介绍 Jupyter Notebook,一个基于浏览器的交互编程环 境。简单来说,对于这些工具,你应该了解以下内容,以便充分利用 scikit-learn。
1.4.1 Jupyter Notebook
Jupyter Notebook 是可以在浏览器中运行代码的交互环境。这个工具在探索性数据分析方面非常有用,在数据科学家中广为使用。虽然 Jupyter Notebook 支持多种编程语言,但我们只需要支持 Python 即可。用 Jupyter Notebook 整合代码、文本和图像非常方便,实际上本教程所有内容都是以 Jupyter Notebook 的形式进行编写的。所有代码示例都可以在 GitHub 下 载(https://github.com/amueller/introduction_to_ml_with_python)。
1.4.2 NumPy
NumPy 是 Python 科学计算的基础包之一。它的功能包括多维数组、高级数学函数(比如线性代数运算和傅里叶变换),以及伪随机数生成器。
在 scikit-learn 中,NumPy 数组是基本数据结构。scikit-learn 接受 NumPy 数组格式的数据。你用到的所有数据都必须转换成 NumPy 数组。NumPy 的核心功能是 ndarray 类, 即多维(n 维)数组。数组的所有元素必须是同一类型。NumPy 数组如下所示:
In[2]:
import numpy as np
x = np.array([[1, 2, 3], [4, 5, 6]])
print("x:\n{}".format(x))
Out[2]:
x:
[[1 2 3]
[4 5 6]]
本文会经常用到 NumPy。对于 NumPy ndarray 类的对象,我们将其简称为“NumPy 数组” 或“数组”。
1.4.3 SciPy
SciPy 是 Python 中用于科学计算的函数集合。它具有线性代数高级程序、数学函数优化、信号处理、特殊数学函数和统计分布等多项功能。scikit-learn 利用 SciPy 中的函数集合来实现算法。对我们来说,SciPy 中最重要的是 scipy.sparse:它可以给出稀疏矩阵 (sparse matrice),稀疏矩阵是 scikit-learn 中数据的另一种表示方法。如果想保存一个大部分元素都是 0 的二维数组,就可以使用稀疏矩阵:
In[3]:
from scipy import sparse
# 创建一个二维NumPy数组,对角线为1,其余都为0
eye = np.eye(4)
print("NumPy array:\n{}".format(eye))
Out[3]:
NumPy array:
[[ 1. 0. 0. 0.]
[ 0. 1. 0. 0.]
[ 0. 0. 1. 0.]
[ 0. 0. 0. 1.]]
In[4]:
# 将NumPy数组转换为CSR格式的SciPy稀疏矩阵
# 只保存非零元素
sparse_matrix = sparse.csr_matrix(eye)
print("\nSciPy sparse CSR matrix:\n{}".format(sparse_matrix))
Out[4]:
SciPy sparse CSR matrix:
(0, 0) 1.0
(1, 1) 1.0
(2, 2) 1.0
(3, 3) 1.0
通常来说,创建稀疏数据的稠密表示(dense representation)是不可能的(因为太浪费内存),所以我们需要直接创建其稀疏表示(sparse representation)。下面给出的是创建同一 稀疏矩阵的方法,用的是 COO 格式:
In[5]:
data = np.ones(4)
row_indices = np.arange(4)
col_indices = np.arange(4)
eye_coo = sparse.coo_matrix((data, (row_indices, col_indices)))
print("COO representation:\n{}".format(eye_coo))
Out[5]:
COO representation:
(0, 0) 1.0
(1, 1) 1.0
(2, 2) 1.0
(3, 3) 1.0
关于 SciPy 稀疏矩阵的更多内容可查阅 SciPy 讲稿(http://www.scipy-lectures.org/)。
1.4.4 matplotlib
matplotlib 是 Python 主要的科学绘图库,其功能为生成可发布的可视化内容,如折线图、直方图、散点图等。将数据及各种分析可视化,可以让你产生深刻的理解,而我们将用 matplotlib 完 成 所 有 的 可 视 化 内 容。 在 Jupyter Notebook 中, 你可以使用 %matplotlib notebook 和 %matplotlib inline 命令,将图像直接显示在浏览器中。我们推荐使用 %matplotlib notebook 命令,它可以提供交互环境(虽然在写作本书时我们用的是 %matplotlib inline)。举个例子,下列代码会生成图 1-1 中的图像:
In[6]:
%matplotlib inline
import matplotlib.pyplot as plt
# 在-10和10之间生成一个数列,共100个数
x = np.linspace(-10, 10, 100)
# 用正弦函数创建第二个数组
y = np.sin(x)
# plot函数绘制一个数组关于另一个数组的折线图
plt.plot(x, y, marker="x")
图 1-1:用 matplotlib 画出正弦函数的简单折线图
1.4.5 pandas
pandas 是用于处理和分析数据的 Python 库。它基于一种叫作 DataFrame 的数据结构,这 种数据结构模仿了 R 语言中的 DataFrame。简单来说,一个 pandas DataFrame 是一张表格,类似于 Excel 表格。pandas 中包含大量用于修改表格和操作表格的方法,尤其是可以像 SQL 一样对表格进行查询和连接。NumPy 要求数组中的所有元素类型必须完全相同,而 pandas 不是这样,每一列数据的类型可以互不相同(比如整型、日期、浮点数和字 符串)。pandas 的另一个强大之处在于,它可以从许多文件格式和数据库中提取数据,如 SQL、Excel 文件和逗号分隔值(CSV)文件。pandas 的详细功能介绍已经超出了本书的范围。但 Wes McKinney 的《Python 数据处理》 一书是很好的参考指南。下面是利用字典 创建 DataFrame 的一个小例子:
In[7]:
import pandas as pd
from IPython.display import display
# 创建关于人的简单数据集
data = {'Name': ["John", "Anna", "Peter", "Linda"],
'Location' : ["New York", "Paris", "Berlin", "London"],
'Age' : [24, 13, 53, 33]
}
data_pandas = pd.DataFrame(data)
# IPython.display可以在Jupyter Notebook中打印出“美观的”DataFrame
display(data_pandas)
上述代码的输出如下:
| Age | Location | Name | |
|---|---|---|---|
| 0 | 24 | New York | John |
| 1 | 13 | Paris | Anna |
| 2 | 53 | Berlin | Peter |
| 3 | 33 | London | Linda |
查询这个表格的方法有很多种。举个例子:
In[8]:
# 选择年龄大于30的所有行
display(data_pandas[data_pandas.Age > 30])
输出结果如下:
| Age | Location | Name | |
|---|---|---|---|
| 2 | 53 | Berlin | Peter |
| 3 | 33 | London | Linda |
1.5 Python 2与Python 3的对比
目前 Python 主要有两大版本广为使用:Python 2(更确切地说是 Python 2.7)和 Python 3 (写作本书时的最新版本是 Python 3.5)。有时这会造成一些混乱。Python 2 已经停止开发, 但由于 Python 3 包含许多重大变化,所以 Python 2 的代码通常无法在 Python 3 中运行。如果你是 Python 新手,或者要从头开发一个新项目,我们强烈推荐使用最新版本的 Python 3, 你无需做任何更改。如果你要依赖一个用 Python 2 编写的大型代码库,可以暂时不升级。
但你应该尽快迁移到 Python 3。在编写任何新代码时,想要编写能够在 Python 2 和 Python 3 中同时运行的代码,大多数情况下都是很容易的。3 如果你无需与旧版软件进行交互的话, 一定要使用 Python 3。本书所有代码在两个版本下都可以运行,但具体的输出在 Python 2 中可能会略有不同。
1.6 本书用到的版本
对于前面提到的这些库,本书用到的版本如下:
In[9]:
import sys
print("Python version: {}".format(sys.version))
import pandas as pd
print("pandas version: {}".format(pd.__version__))
import matplotlib
print("matplotlib version: {}".format(matplotlib.__version__))
import numpy as np
print("NumPy version: {}".format(np.__version__))
import scipy as sp
print("SciPy version: {}".format(sp.__version__))
import IPython
print("IPython version: {}".format(IPython.__version__))
import sklearn
print("scikit-learn version: {}".format(sklearn.__version__))
Out[9]:
Python version: 3.5.2 |Anaconda 4.1.1 (64-bit)| (default, Jul 2 2016, 17:53:06)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-1)]
pandas version: 0.18.1
matplotlib version: 1.5.1
NumPy version: 1.11.1
SciPy version: 0.17.1
IPython version: 5.1.0
scikit-learn version: 0.18
这些版本不一定要精确匹配,但 scikit-learn 的版本不应低于本书使用的版本。 现在都已经安装完毕,我们来学习第一个机器学习应用。
本书假设你的 scikit-learn 版本不低于 0.18。0.18 版新增了 model_ selection 模块,如果你用的是较早版本的 scikit-learn,那么需要修改从 这个模块导入的内容。
1.7 第一个应用:鸢尾花分类
本节我们将完成一个简单的机器学习应用,并构建我们的第一个模型。同时还将介绍一些核心概念和术语。
假设有一名植物学爱好者对她发现的鸢尾花的品种很感兴趣。她收集了每朵鸢尾花的一些 测量数据:花瓣的长度和宽度以及花萼的长度和宽度,所有测量结果的单位都是厘米(见 图 1-2)。
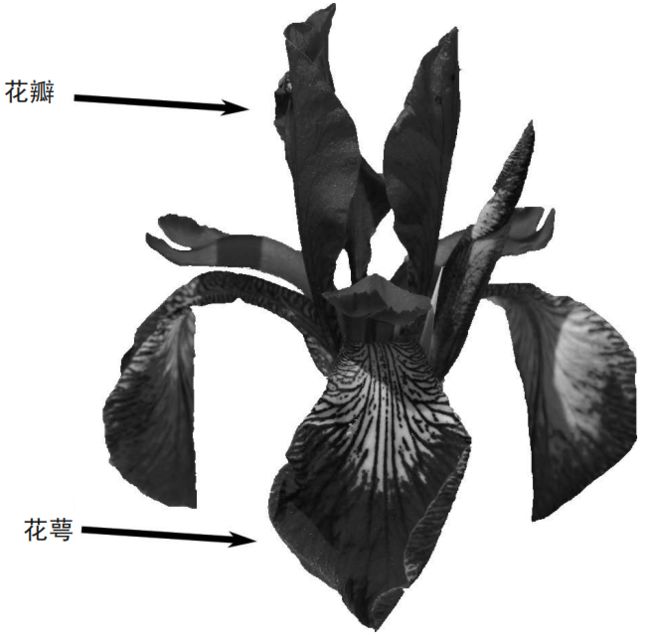
图 1-2:鸢尾花局部
她还有一些鸢尾花的测量数据,这些花之前已经被植物学专家鉴定为属于 setosa、 versicolor 或 virginica 三个品种之一。对于这些测量数据,她可以确定每朵鸢尾花所属的品种。我们假设这位植物学爱好者在野外只会遇到这三种鸢尾花。
我们的目标是构建一个机器学习模型,可以从这些已知品种的鸢尾花测量数据中进行学习,从而能够预测新鸢尾花的品种。
因为我们有已知品种的鸢尾花的测量数据,所以这是一个监督学习问题。在这个问题中, 我们要在多个选项中预测其中一个(鸢尾花的品种)。这是一个分类(classification)问题 的示例。可能的输出(鸢尾花的不同品种)叫作类别(class)。数据集中的每朵鸢尾花都属于三个类别之一,所以这是一个三分类问题。
单个数据点(一朵鸢尾花)的预期输出是这朵花的品种。对于一个数据点来说,它的品种 叫作标签(label)。
1.7.1 初识数据
本例中我们用到了鸢尾花(Iris)数据集,这是机器学习和统计学中一个经典的数据集。它包含在 scikit-learn 的 datasets 模块中。我们可以调用 load_iris 函数来加载数据:
In[10]:
from sklearn.datasets import load_iris
iris_dataset = load_iris()
load_iris 返回的 iris 对象是一个 Bunch 对象,与字典非常相似,里面包含键和值:
In[11]:
print("Keys of iris_dataset: \n{}".format(iris_dataset.keys()))
Out[11]:
Keys of iris_dataset:
dict_keys(['target_names', 'feature_names', 'DESCR', 'data', 'target'])
DESCR 键对应的值是数据集的简要说明。我们这里给出说明的开头部分(你可以自己查看其余的内容):
In[12]:
print(iris_dataset['DESCR'][:193] + "\n...")
Out[12]:
Iris Plants Database
====================
Notes
----
Data Set Characteristics:
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive att
...
----
target_names 键对应的值是一个字符串数组,里面包含我们要预测的花的品种:
In[13]:
print("Target names: {}".format(iris_dataset['target_names']))
Out[13]:
Target names: ['setosa' 'versicolor' 'virginica']
feature_names 键对应的值是一个字符串列表,对每一个特征进行了说明:
In[14]:
print("Feature names: \n{}".format(iris_dataset['feature_names']))
Out[14]:
Feature names:
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)',
'petal width (cm)']
数据包含在 target 和 data 字段中。data 里面是花萼长度、花萼宽度、花瓣长度、花瓣宽度的测量数据,格式为 NumPy 数组:
In[15]:
print("Type of data: {}".format(type(iris_dataset['data'])))
Out[15]:
Type of data: <class 'numpy.ndarray'>
data 数组的每一行对应一朵花,列代表每朵花的四个测量数据:
In[16]:
print("Shape of data: {}".format(iris_dataset['data'].shape))
Out[16]:
Shape of data: (150, 4)
可以看出,数组中包含 150 朵不同的花的测量数据。前面说过,机器学习中的个体叫作样本(sample),其属性叫作特征(feature)。data 数组的形状(shape)是样本数乘以特征数。这是 scikit-learn 中的约定,你的数据形状应始终遵循这个约定。下面给出前 5 个样本的特征数值:
In[17]:
print("First five rows of data:\n{}".format(iris_dataset['data'][:5]))
Out[17]:
First five rows of data:
[[ 5.1 3.5 1.4 0.2]
[ 4.9 3. 1.4 0.2]
[ 4.7 3.2 1.3 0.2]
[ 4.6 3.1 1.5 0.2]
[ 5. 3.6 1.4 0.2]]
从数据中可以看出,前 5 朵花的花瓣宽度都是 0.2cm,第一朵花的花萼最长,是 5.1cm。
target 数组包含的是测量过的每朵花的品种,也是一个 NumPy 数组:
In[18]:
print("Type of target: {}".format(type(iris_dataset['target'])))
Out[18]:
Type of target: <class 'numpy.ndarray'>
target 是一维数组,每朵花对应其中一个数据:
In[19]:
print("Shape of target: {}".format(iris_dataset['target'].shape))
Out[19]:
Shape of target: (150,)
品种被转换成从 0 到 2 的整数:
In[20]:
print("Target:\n{}".format(iris_dataset['target']))
Out[20]:
Target:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
上述数字的代表含义由 iris[‘target_names’] 数组给出:0 代表 setosa,1 代表 versicolor, 2 代表 virginica。
1.7.2 衡量模型是否成功:训练数据与测试数据
我们想要利用这些数据构建一个机器学习模型,用于预测新测量的鸢尾花的品种。但在将模型应用于新的测量数据之前,我们需要知道模型是否有效,也就是说,我们是否应该相信它的预测结果。
不幸的是,我们不能将用于构建模型的数据用于评估模型。因为我们的模型会一直记住整 个训练集,所以对于训练集中的任何数据点总会预测正确的标签。这种“记忆”无法告诉我们模型的泛化(generalize)能力如何(换句话说,在新数据上能否正确预测)。
**我们要用新数据来评估模型的性能。**新数据是指模型之前没有见过的数据,而我们有这些新数据的标签。通常的做法是将收集好的带标签数据(此例中是 150 朵花的测量数据) 分成两部分。一部分数据用于构建机器学习模型,叫作训练数据(training data)或训练集(training set)。其余的数据用来评估模型性能,叫作测试数据(test data)、测试集(test set)或留出集(hold-out set)。
scikit-learn 中的 train_test_split 函数可以打乱数据集并进行拆分。这个函数将 75% 的 行数据及对应标签作为训练集,剩下 25% 的数据及其标签作为测试集。训练集与测试集的分配比例可以是随意的,但使用 25% 的数据作为测试集是很好的经验法则。
scikit-learn 中的数据通常用大写的 X 表示,而标签用小写的 y 表示。这是受到了数学 标准公式 f(x)=y 的启发,其中 x 是函数的输入,y 是输出。我们用大写的 X 是因为数据是一个二维数组(矩阵),用小写的 y 是因为目标是一个一维数组(向量),这也是数学中的约定。
对数据调用 train_test_split,并对输出结果采用下面这种命名方法:
In[21]:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
iris_dataset['data'], iris_dataset['target'], random_state=0)
在对数据进行拆分之前,train_test_split 函数利用伪随机数生成器将数据集打乱。如果 我们只是将最后 25% 的数据作为测试集,那么所有数据点的标签都是 2,因为数据点是按标签排序的(参见之前 iris['target'] 的输出)。测试集中只有三个类别之一,这无法告诉我们模型的泛化能力如何,所以我们将数据打乱,确保测试集中包含所有类别的数据。
为了确保多次运行同一函数能够得到相同的输出,我们利用 random_state 参数指定了随机数生成器的种子。这样函数输出就是固定不变的,所以这行代码的输出始终相同。本书用到随机过程时,都会用这种方法指定 random_state。
train_test_split 函数的输出为 X_train、X_test、y_train 和 y_test,它们都是 NumPy 数组。X_train 包含 75% 的行数据,X_test 包含剩下的 25%:
In[22]:
print("X_train shape: {}".format(X_train.shape))
print("y_train shape: {}".format(y_train.shape))
Out[22]:
X_train shape: (112, 4)
y_train shape: (112,)
In[23]:
print("X_test shape: {}".format(X_test.shape))
print("y_test shape: {}".format(y_test.shape))
Out[23]:
X_test shape: (38, 4)
y_test shape: (38,)
1.7.3 要事第一:观察数据
在构建机器学习模型之前,通常最好检查一下数据,看看如果不用机器学习能不能轻松完 成任务,或者需要的信息有没有包含在数据中。 此外,检查数据也是发现异常值和特殊值的好方法。举个例子,可能有些鸢尾花的测量单 位是英寸而不是厘米。在现实世界中,经常会遇到不一致的数据和意料之外的测量数据。
检查数据的最佳方法之一就是将其可视化。一种可视化方法是绘制散点图(scatter plot)。 数据散点图将一个特征作为 x 轴,另一个特征作为 y 轴,将每一个数据点绘制为图上的一 个点。不幸的是,计算机屏幕只有两个维度,所以我们一次只能绘制两个特征(也可能是 3 个)。用这种方法难以对多于 3 个特征的数据集作图。解决这个问题的一种方法是绘制散点图矩阵(pair plot),从而可以两两查看所有的特征。如果特征数不多的话,比如我们这里有 4 个,这种方法是很合理的。但是你应该记住,散点图矩阵无法同时显示所有特征之间的关系,所以这种可视化方法可能无法展示数据的某些有趣内容。
图 1-3 是训练集中特征的散点图矩阵。数据点的颜色与鸢尾花的品种相对应。为了绘制这张图,我们首先将 NumPy 数组转换成 pandas DataFrame。pandas 有一个绘制散点图矩阵的 函数,叫作 scatter_matrix。矩阵的对角线是每个特征的直方图:
In[24]:
# 利用X_train中的数据创建DataFrame
# 利用iris_dataset.feature_names中的字符串对数据列进行标记
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
# 利用DataFrame创建散点图矩阵,按y_train着色
grr = pd.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o',
hist_kwds={'bins': 20}, s=60, alpha=.8, cmap=mglearn.cm3)
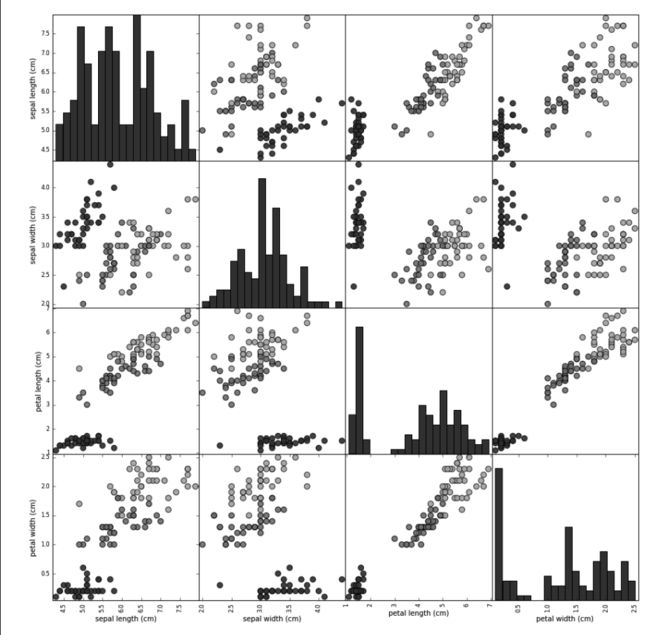
图 1-3:Iris 数据集的散点图矩阵,按类别标签着色
从图中可以看出,利用花瓣和花萼的测量数据基本可以将三个类别区分开。这说明机器学习模型很可能可以学会区分它们。
1.7.4 构建第一个模型:k近邻算法
现在我们可以开始构建真实的机器学习模型了。scikit-learn 中有许多可用的分类算法。
这里我们用的是 k 近邻分类器,这是一个很容易理解的算法。构建此模型只需要保存训练集即可。要对一个新的数据点做出预测,算法会在训练集中寻找与这个新数据点距离最近的数据点,然后将找到的数据点的标签赋值给这个新数据点。
k 近邻算法中 k 的含义是,我们可以考虑训练集中与新数据点最近的任意 k 个邻居(比如 说,距离最近的 3 个或 5 个邻居),而不是只考虑最近的那一个。然后,我们可以用这些邻居中数量最多的类别做出预测。第 2 篇会进一步介绍这个算法的细节,现在我们只考虑 一个邻居 的情况。
scikit-learn 中所有的机器学习模型都在各自的类中实现,这些类被称为 Estimator 类。k 近邻分类算法是在 neighbors 模块的 KNeighborsClassifier 类中实现的。我们需要将这个类实例化为一个对象,然后才能使用这个模型。这时我们需要设置模型的参数。 KNeighborsClassifier 最重要的参数就是邻居的数目,这里我们设为 1:
In[25]:
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1)
knn 对象对算法进行了封装,既包括用训练数据构建模型的算法,也包括对新数据点进行预测的算法。它还包括算法从训练数据中提取的信息。对于 KNeighborsClassifier 来说,里面只保存了训练集。
想要基于训练集来构建模型,需要调用 knn 对象的 fit 方法,输入参数为 X_train 和 y_ train,二者都是 NumPy 数组,前者包含训练数据,后者包含相应的训练标签:
In[26]:
knn.fit(X_train, y_train
Out[26]:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')
fit 方法返回的是 knn 对象本身并做原处修改,因此我们得到了分类器的字符串表示。 从中可以看出构建模型时用到的参数。几乎所有参数都是默认值,但你也会注意到 n_ neighbors=1,这是我们传入的参数。scikit-learn 中的大多数模型都有很多参数,但多用 于速度优化或非常特殊的用途。你无需关注这个字符串表示中的其他参数。打印 scikitlearn 模型会生成非常长的字符串,但不要被它吓到。我们会在第 2 章讲到所有重要的参数。在本书的其他章节中,我们不会给出 fit 的输出,因为里面没有包含任何新的信息。
1.7.5 做出预测
现在我们可以用这个模型对新数据进行预测了,我们可能并不知道这些新数据的正确标 签。想象一下,我们在野外发现了一朵鸢尾花,花萼长 5cm 宽 2.9cm,花瓣长 1cm 宽 0.2cm。这朵鸢尾花属于哪个品种?我们可以将这些数据放在一个 NumPy 数组中,再次计 算形状,数组形状为样本数(1)乘以特征数(4):
In[27]:
X_new = np.array([[5, 2.9, 1, 0.2]])
print("X_new.shape: {}".format(X_new.shape))
Out[27]:
X_new.shape: (1, 4)
注意,我们将这朵花的测量数据转换为二维 NumPy 数组的一行,这是因为 scikit-learn 的输入数据必须是二维数组。
我们调用 knn 对象的 predict 方法来进行预测:
In[28]:
prediction = knn.predict(X_new)
print("Prediction: {}".format(prediction))
print("Predicted target name: {}".format(
iris_dataset['target_names'][prediction]))
Out[28]:
Prediction: [0]
Predicted target name: ['setosa']
根据我们模型的预测,这朵新的鸢尾花属于类别 0,也就是说它属于 setosa 品种。但我们 怎么知道能否相信这个模型呢?我们并不知道这个样本的实际品种,这也是我们构建模型的重点啊!
1.7.6 评估模型
这里需要用到之前创建的测试集。这些数据没有用于构建模型,但我们知道测试集中每朵 鸢尾花的实际品种。
因此,我们可以对测试数据中的每朵鸢尾花进行预测,并将预测结果与标签(已知的品种)进行对比。我们可以通过计算精度(accuracy)来衡量模型的优劣,精度就是品种预测正确的花所占的比例:
In[29]:
y_pred = knn.predict(X_test)
print("Test set predictions:\n {}".format(y_pred))
Out[29]:
Test set predictions:
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0 2]
In[30]:
print("Test set score: {:.2f}".format(np.mean(y_pred == y_test)))
Out[30]:
Test set score: 0.97
我们还可以使用 knn 对象的 score 方法来计算测试集的精度:
In[31]:
print("Test set score: {:.2f}".format(knn.score(X_test, y_test)))
Out[31]:
Test set score: 0.97
对于这个模型来说,测试集的精度约为 0.97,也就是说,对于测试集中的鸢尾花,我们的预测有 97% 是正确的。根据一些数学假设,对于新的鸢尾花,可以认为我们的模型预测结果有 97% 都是正确的。对于我们的植物学爱好者应用程序来说,高精度意味着模型足够可信,可以使用。在后续章节中,我们将讨论提高性能的方法,以及模型调参时的注意事项。