超详细爬取中国天气网最低气温信息并进行数据可视化
Ide:pycharm
python:Python3.6
Browser:Chrome
一:分析网站
目标地址:http://www.weather.com.cn/textFC/hb.shtml
我们想要爬取全国城市的最低气温,观察网站。
![]()
全国的城市分为华北,东北等8个区,分别点开观察url,
'http://www.weather.com.cn/textFC/hb.shtml', 华北 'http://www.weather.com.cn/textFC/db.shtml', 东北 'http://www.weather.com.cn/textFC/hd.shtml', 华东 'http://www.weather.com.cn/textFC/hz.shtml', 华中 'http://www.weather.com.cn/textFC/hn.shtml', 华南 'http://www.weather.com.cn/textFC/xb.shtml', 西北 'http://www.weather.com.cn/textFC/xn.shtml', 西南 'http://www.weather.com.cn/textFC/gat.shtml', 港澳台
可以观察基础URL是http://www.weather.com.cn/textFC/,后面跟上地区缩写就行。
F12继续分析网页。

观察到北京,天津以及其他省份都处于conMidtab下,至于那个style=“display:none”是其他日期的所以为none,这个我们不管。继续分析单个北京的格式,点开conMidtab2。

观察到北京的天气信息是由一个table组成的。ok,继续点开分析。
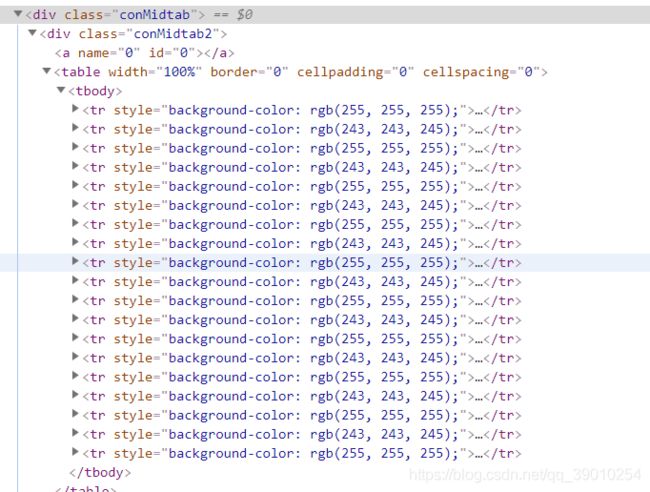
观察到table下有许多tr标签与省/直辖市下面的城市一一对应,仔细观察发现第一个tr和第二个tr是对应表头,我们后面代码的时候要注意从第三个tr开始处理。继续点开tr分析。

第三个tr点开,观察法下面是一个个td标签,很好,我们所需要的td标签是第一个,和倒数第二个,可以继续点开观察,我们直接上手代码。
二:爬取网页
新建项目,导入我们的最基本的两个库,(requests,BeauyifulSoup),没安装的朋友pip安装下。
先测试网站有没有反爬措施(像这种网站一般没有,因为他的网站代码都是乱七八糟的,我们后面再讲)
"""
Created by Young on 2019/1/17 10:04
"""
import requests
from bs4 import BeautifulSoup
url = 'http://www.weather.com.cn/textFC/hb.shtml'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'}
def getHtmlText(url):
try:
wb_data = requests.get(url, timeout=30, headers=headers)
wb_data.encoding = "utf-8" # 解决乱码
soup = BeautifulSoup(wb_data.text, 'lxml', from_encoding="utf8")
print(soup)
except:
return '产生异常'
def main():
getHtmlText(url)
if __name__ == '__main__':
main()
测试没有反爬措施,很完美的输出了网站的代码。

继续编写我们的代码,获取conMidtab下的信息。
"""
Created by Young on 2019/1/17 10:04
"""
import requests
from bs4 import BeautifulSoup
url = 'http://www.weather.com.cn/textFC/hb.shtml'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'}
def getHtmlText(url):
try:
wb_data = requests.get(url, timeout=30, headers=headers)
wb_data.encoding = "utf-8" # 解决乱码
soup = BeautifulSoup(wb_data.text, 'lxml', from_encoding="utf8")
conMidtab = soup.find('div', class_='conMidtab')
tables = soup.find_all('table')
print(tables)
except:
return '产生异常'
def main():
getHtmlText(url)
if __name__ == '__main__':
main()
先获取table的信息,输出看下。
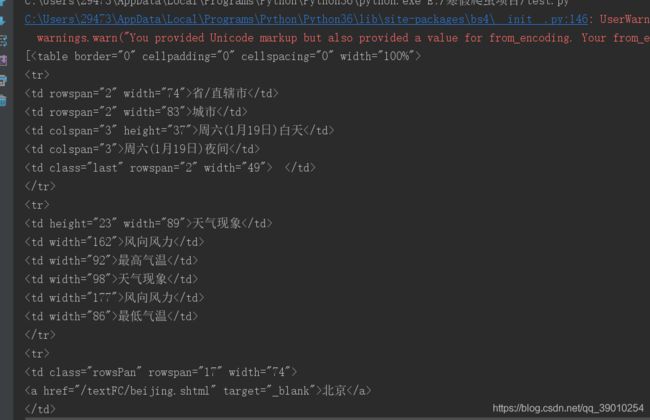
观察到一个个列表,for循环输出,然后继续寻找下一级节点。直接截图代码块,不贴代码了哈。

输出结果:

华北地区信息被我们很完美的输出了,接着测试东北地区。

发现东北地区的第一个城市出现错误。我们回到网页观察。

发现这第一个td标签就是黑龙江,之前正好是北京名字重复了,我们采取enuumerate函数。
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
Python 2.3. 以上版本可用,2.6 添加 start 参数。
上代码

很好的处理了这个问题,输出看下。

基本没啥问题了,一直测试到了港澳台,这就回到了我为什么说这是个乱七八糟的网站,观察港澳台页面,table标签不完整,所以这里就不能采用lxml解析方式,我们采取和浏览器一样的解析方式html5lib,一样pip安装,然后用这种方式速度虽然满了一点,但是可以帮我们补全table。
三:数据可视化
这里我们采取一个库,pyecharts。
这里贴出官方文档:http://pyecharts.org/#/zh-cn/charts_base
数据可视化没什么好讲的,直接上代码。
上一个效果图。

新手编程,存在问题,请各位大佬不吝赐教。。
有问题,vx:ysc294736613
代码地址:https://github.com/MayYoung1/weather1