层次聚类算法实例分析
层次聚类算法
层次聚类算法又称为树聚类算法,它根据数据之间的距离,通过一种层次架构方式,反复将数据进行聚合,创建一个层次以分解给定的数据集。
在sklearn模块中,使用AgglomerativeClustering 函数进行层次聚类。常用参数如下:
sklearn.cluster.AgglomerativeClustering(n_clusters = 2)
| 参数 | 说明 |
|---|---|
| n_clusters | 分组个数,默认分为两组 |
基于运营商基站信息挖掘商圈案例
部分数据如下:
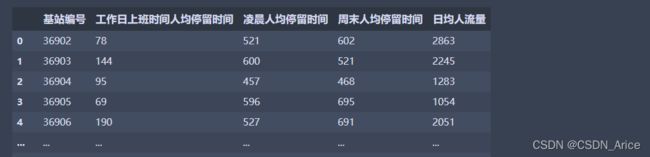
现在需要对这份数据进行聚类,将这些基站划分为不同的商圈。
首先,导入数据:
import pandas as pd
data = pd.read_csv('D:\example_csv\层次聚类.csv')
使用散点图把数据表示出来:
数据标准化(Z-Score)
import matplotlib.pyplot as plt
from pandas.plotting import scatter_matrix
from sklearn.preprocessing import scale
fColumns = [
'工作日上班时间人均停留时间','凌晨人均停留时间',
'周末人均停留时间','日均人流量'
]
#由于人流量和时间属于不同的计量单位,因此需要对这份数据进行标准化
scaleData = pd.DataFrame(
scale(data[fColumns]),columns = fColumns)
#绘制散点矩阵图
from pylab import mpl
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
#防止中文和负号乱码
axes = scatter_matrix(
scaleData,diagonal = 'hist')
执行代码,得到散点矩阵图:

从散点矩阵图可以看出,4个特征之间基本不存在线性关系,因此不用去掉共线性特征。
然后,使用降维,把四个特征压缩为2个特征,并使用散点图把数据展现出来。
降维(主成分分析)
from sklearn.decomposition import PCA
pca_2 = PCA(n_components = 2)
data_pca_2 = pd.DataFrame(
pca_2.fit_transform(scaleData))
plt.scatter(
data_pca_2[0],
data_pca_2[1])
执行代码:

从数据的二维散点图可以很明显地看出,数据应该聚类为3类,因此AgglomerativeClustering函数的n_clusters参数应该设置为3。
from sklearn.cluster import AgglomerativeClustering
#进行层次聚类,并预测样本的分组
agglomerativeClustering = AgglomerativeClustering(n_clusters = 3)
pTarget = agglomerativeClustering.fit_predict(scaleData)
plt.figure()
plt.scatter(
data_pca_2[0],
data_pca_2[1],c = pTarget)
执行代码,聚类效果如图:

可以看到,这个层次聚类的效果非常不错。
如果我们需要画出层次聚类的树结构图形,则可以使用scipy模块中的dendrogram函数绘图:
import scipy.cluster.hierarchy as hulcuster
#构建层次聚类树
linkage = hulcuster.linkage(
scaleData,method = 'centroid')
#绘制层次聚类图形
plt.figure()
hulcuster.dendrogram(
linkage,leaf_font_size = 10)
#计算层次聚类结果
_pTraget = hulcuster.fcluster(
linkage,3,criterion = 'maxclust')
执行代码,得到以下所示的聚类树图形:

最后使用平行坐标图来解读聚类后每个分组的主要特征:
import seaborn as sns
from pandas.plotting import parallel_coordinates
fColumns = [
'工作日上班时间人均停留时间','凌晨人均停留时间',
'周末人均停留时间','日均人流量','类型'
]
data['类型'] = pTarget
plt.figure()
ax = parallel_coordinates(
data[fColumns],'类型',color = sns.color_palette(),)
执行代码,得到如下所示的平行坐标图:

从平行坐标图可以看出,在每个特征上,聚类的分组都有很明确的界限,我们可以很容易识别不同的分组,因此,每个特征都可以用来解读聚类结果。