基于堆栈的缓冲区溢出
Let’s take a quick overview on Stack Overflow, before we dive deep into the project itself. Stack Overflow is one of the largest QA platform for computer programmers. People posts questions-queries associated with wide range of topics (mostly related to computer programming) and fellow users try to resolve queries in the most helpful manner.
在深入研究项目本身之前,让我们快速了解一下Stack Overflow 。 堆栈溢出是计算机程序员最大的质量检查平台之一。 人们发布与广泛主题(主要与计算机编程相关)相关的问题查询,而其他用户则尝试以最有用的方式解决问题。
指标:逐步方法 (INDEX : Step by step approach)
Section 1 : Brief overview1. Business problem : Need of search engine.2. 2.1. Dataset
2.2. The process flow
2.3. High level Overview3. Exploratory data analysis and Data pre-processing
-----------------------------------------------------
SECTION 2 : The attack plan
4. Modelling : The tag predictor
4.1. A TAG Predictor model
4.2. TRAIN_TEST_SPLIT
4.3 Time based splitting Modelling
4.4. GRU based Encoder-decoder seq2seq model
4.5. Model embedding
4.6. Word2Vec embedding
4.7. Multi-label target problem5. LDA (Latent Dirichlet allocation) : Topic Modelling6. Okapi BM25 Score : simplest searching technique7. Sentence embedding : BERT8. Sentence embedding : Universal sentence encoder
-----------------------------------------------------SECTION 3 : Productionizing the solution
9. Entire pipeline deployment on a remote server
9.1. A Cloud platform
9.2. Web App using Flask-----------------------------------------------------
SECTION 4 : Results and conclusion
10. Results and conclusion
10.1 Final Results : BERT
10.2. Final Results : USE
10.3. Final Inferences1. Business problem : Need of search engine.
1.业务问题:需要搜索引擎。
‘StackOverflow’ is sitting on the huge amount of information contributed by the public for the public. Nonetheless, large amounts of data also makes it very difficult to retrieve the exact solution one is looking for. Now, It becomes the primary duty of ‘StackOverflow’ (or any such facility provider) to serve the exact solution to which users are querying in the search bar on their website. Otherwise, the worst case scenario could be : even if ‘StackOverflow’ has the exact solution users are looking for, but ‘StackOverflow’ will not be able to serve the solution, just because of the weak search-engine mechanism OR No-searching mechanism. In simple words, out of terribly huge amounts of data, Search engine helps in finding exactly what users are looking for. One can understand the need of a ‘searching mechanism’ by imagining if Google was not there! or no product search bar on Amazon.
“ StackOverflow”坐拥公众为公众提供的大量信息。 尽管如此,大量的数据也使检索一个正在寻找的确切解决方案变得非常困难。 现在,“ StackOverflow”(或任何此类设施提供商)的主要职责是提供用户正在其网站搜索栏中查询的确切解决方案。 否则,最坏的情况可能是:即使'StackOverflow'具有用户正在寻找的确切解决方案,但是'StackOverflow'也将无法为该解决方案提供服务,这仅仅是因为搜索引擎机制或无搜索机制较弱。 简而言之,在非常庞大的数据量中,搜索引擎可帮助您准确找到用户要查找的内容。 可以想象一下Google是否不存在,从而了解“搜索机制”的必要性! 或亚马逊上没有产品搜索栏。
One line problem statement : “To build a ranking mechanism on the basis of ‘StackOverflow’ Questions-Answers data, which results in a set of related Questions for provided search-query”.
一个简单的问题陈述 :“基于'StackOverflow'Questions-Answers数据建立排名机制,从而为提供的搜索查询生成一组相关的Questions”。
2. Dataset :
2.数据集:
‘StackOverflow’ has a giant amount of Questions asked by various specialized or in general communities, also answers and comments associated with each Question. Usually, Answers and the Comments are contributed on the platform by experts, or community enthusiasts. Basically It’s public Q-A forum. ‘StackOverflow’ has made sample of it’s large ‘Question-Answer’ data publically available for research and development in the data-community, which is available at : https://archive.org/details/stackexchange
“ StackOverflow”具有大量由各个专业或普通社区提出的问题,以及与每个问题相关的答案和评论。 通常,答案和评论是由专家或社区爱好者在平台上提供的。 基本上是公开的质量检查论坛。 “ StackOverflow”已将其庞大的“ Question-Answer”数据样本公开提供给数据社区进行研究和开发,可在以下网址获取: https : //archive.org/details/stackexchange
The data from below StackExchange properties are used :
使用以下StackExchange属性中的数据:
1. cs.stackexchange.com.7z
2. datascience.stackexchange.com.7z
3. ai.stackexchange.com.7z
4. stats.stackexchange.com.7z
The process flow :
处理流程:
The flow of solution is mainly broken into two parts :
解决方案的流程主要分为两个部分:
- Cutting down all the available no.of questions into smaller chunk of questions. 将所有可用的问题数减少为较小的问题块。
- Ranking the results based on the semantic similarity. In order to finalize the ranking system with specific scoring mechanisms, it is required to convert text documents into high dimensional vector representations. There are several pretrained sentence embeddings which are popular for their semantic results e.g., BERT, USE. 根据语义相似度对结果进行排名。 为了最终确定具有特定评分机制的排名系统,需要将文本文档转换为高维向量表示。 有几种预训练的句子嵌入因其语义结果而很流行,例如BERT,USE。
High level Overview :
高层概述:
Acquisition of appropriate data from Archive.org
从Archive.org获取适当的数据
- Exploratory data analysis and Data pre-processing. 探索性数据分析和数据预处理。
- Training a tag-predictor model |gathering chunk of questions associated with predicted ‘tag’. 训练标签预测器模型,收集与预测的“标签”相关的问题。
- LDA topic modelling | gathering chunk of questions associated with predicted ‘topic’. LDA主题建模| 收集与预测的“主题”相关的问题。
- BM25 results | gathering chunk of questions associated with BM25 results. BM25结果| 收集与BM25结果相关的大部分问题。
- Combining all three chunks of questions. 结合所有三个问题。
- Sentence embedding : BERT/Universal sentence encoder (Vectorization) 句子嵌入:BERT /通用句子编码器(矢量化)
- Ranking the results based on the metric : ‘cosine_distance’ 根据指标对结果进行排名:“ cosine_distance”
3. Exploratory data analysis and Data pre-processing :
3.探索性数据分析和数据预处理:
Lets take a look at all available features and checking for the missing values.
让我们看一下所有可用功能并检查缺失值。
# Merging all dataFrames into one dataframe
df = pd.concat([df_ai, df_cs, df_ds, df_stats])
df.info()
Our dataset has three prominent features on which we are building the searching mechanism: Question-Title, Question-Body, Question-Tags. Each question can have one to five tags along with the question title and its descriptive text. For the purpose of case study I chose to go with 216k unique questions only.
我们的数据集具有构建搜索机制的三个突出特征:问题标题,问题正文,问题标签。 每个问题可以带有一到五个标签,以及问题标题及其描述性文本。 出于案例研究的目的,我选择仅回答216k个独特的问题。
Now, we are ready to move onto the data cleaning and further data processing steps…
现在,我们准备着手进行数据清理和进一步的数据处理步骤…
- remove html tags, html urls, replace html comparison operators. 删除html标签,html url,替换html比较运算符。
- remove latex. 去除乳胶。
- all lowercase. 全部小写。
- decontraction. 解构。
- remove all special-characters. 删除所有特殊字符。
- remove extra white-spaces. 删除多余的空格。
All stack exchange properties are nothing but web pages, web based data usually has html tags, html comparisons. These tags and special symbols does not contribute any information to the end task, hence I decided to remove them. If you observe closely, some data points are closely related to mathematics domain, For this experiment I chose to remove latex, formulae too. Its proven empirical result in the previous state of the art NLP experiments that applying ‘decontractions’ tend to to give better results.
所有堆栈交换属性仅是网页,基于Web的数据通常具有html标签,html比较。 这些标签和特殊符号对最终任务没有任何帮助,因此我决定将其删除。 如果仔细观察,某些数据点与数学领域密切相关。对于本实验,我选择了删除乳胶,也删除了公式。 在以前的最新NLP实验中,其经过验证的经验结果表明,应用“解压缩”往往会产生更好的结果。


Since StackExchange has questions-answer in the range of technical subjects, Also community uses its own set of words i.e., vocabulary. To avoid losing that subjects specific crucial information avoid using Lemmatization/Stemming.
由于StackExchange在技术主题范围内具有问答功能,因此社区也使用自己的一组单词,即词汇表。 为了避免失去主题,特定的关键信息应避免使用Lemmatization / Stemming 。
Full EDA with inferences can be found out here on my github profile.
带有推论的完整EDA可以在我的github个人资料中找到 。
4. A TAG Predictor model :
4. TAG预测器模型:
Tag can be considered as a kind of topic/subject for any posted question is given by the (publisher) user himself. Sometimes tags are system generated too. It is important to note that our problem is not only a multi-class problem, it’s a multi-label problem i.e., each datapoint can have one or more than tags.
对于(发布者)用户本人给出的任何发布的问题,可以将标签视为一种主题/主题。 有时标签也是系统生成的。 重要的是要注意,我们的问题不仅是多类问题,还是多标签问题,即每个数据点可以有一个或多个标签。
There were some tags in the dataset are too frequent than other tags, since highly frequent target tags will dominate over the model hence I chose to go with a threshold value of 7000 tags. I removed tags which are occurring more than 7000 times in the dataset. Also some tags are very less frequent, so model couldn’t have learnt anything from such target labels. Hence, remove the tags which are occurring less than 500 times in the dataset.
数据集中的某些标签比其他标签过于频繁,因为高频率的目标标签将在模型中占主导地位,因此我选择阈值为7000个标签。 我删除了在数据集中出现超过7000次的标签。 另外,某些标签的使用频率不太高,因此模型无法从此类目标标签中学到任何东西。 因此,删除在数据集中出现少于500次的标签。
TRAIN_TEST_SPLIT : Time based splitting
TRAIN_TEST_SPLIT:基于时间的拆分
The questions and answers on the public QA platforms like Stack Overflow usually evolve over the period of the time. If we would not have considered the dependency of the data over the ‘time function’, generalization accuracy (accuracy on unseen data) will no longer be able to stay close to cross validation accuracy in the production environment. Whenever timestamp is available and data is time dependent — often it’s best choice to split dataset ‘based on time’ than ‘random_split’.
诸如Stack Overflow之类的公共质量检查平台上的问题和答案通常会随着时间的推移而变化。 如果我们不考虑数据对“时间函数”的依赖性,那么泛化精度(对看不见的数据的准确性)将不再能够接近生产环境中的交叉验证精度。 只要有时间戳并且数据取决于时间,通常最好是“基于时间”拆分数据集而不是“ random_split”。
Modelling : GRU based Encoder-decoder seq2seq model
建模:基于GRU的编解码器seq2seq模型
# Constructing a seq2seq model
tf.keras.backend.clear_session()
enc_inputs = Input(name = 'text_seq', shape = (250,))
enc_embed = text_embedding_layer(enc_inputs)
encoder = Bidirectional(GRU(name = 'ENCODER', units = 128, dropout = 0.2))
enc_out = encoder(enc_embed)
dec_lstm = GRU(name = 'DECODER', units = 256, dropout = 0.2, return_sequences= True, return_state= True)
repeat = RepeatVector(5)(enc_out)
dec_out, dec_hidden = dec_lstm(repeat)
dec_dense = Dense(units = len(tar_vocab)+1, activation = 'softmax')
out = dec_dense(dec_out)
model = Model(inputs = enc_inputs, outputs = out)
model.summary()
Model embedding : Word2Vec embedding
模型嵌入:Word2Vec嵌入
For a encoder decoder model I trained custom W2V embedding on StackExchange data. Word2Vec embedding technique needs huge amount of textual data to learn good quality of word vectors. To gather huge amount of data, I decided to merge ‘clean_title + clean_body + clean_comments’ together, to train w2v embeddings upon. Also, used skip-gram W2V instead of CBOW, which has ability to provide better results over smaller amount of data too. Manually trained w2v embedding has given good results :
对于编码器解码器模型,我训练了在StackExchange数据上嵌入的自定义W2V。 Word2Vec嵌入技术需要大量的文本数据才能学习高质量的词向量。 为了收集大量数据,我决定将“ clean_title + clean_body + clean_comments”合并在一起,以训练w2v嵌入。 同样,使用跳过语法W2V代替CBOW,它也能够在更少量的数据上提供更好的结果。 手动训练的w2v嵌入效果良好:
w2v_model_sg.most_similar('sigmoid')
Multi-label target problem :
多标签目标问题:
In deep learning modelling, There are many ways to handle multi label target features few of them are listed below:
在深度学习建模中,有多种处理多标签目标特征的方法,以下仅列出其中几种:
- Dense output layer with sigmoid activation units and loss function with ‘binary_crossentropy’. 具有S型激活单元的密集输出层和具有'binary_crossentropy'的损失函数。
- Use ‘Recurrent neural networks(RNN) + Dense’ at output layer, each time_step as a target label. loss function with ‘categorical_crossentropy’ 在输出层使用“递归神经网络(RNN)+密集”,每个time_step都用作目标标签。 具有'categorical_crossentropy'的损失函数
For the current project work, I tried both methods. In the end 2nd method has been employed as it gave better results.
对于当前的项目工作,我尝试了两种方法。 最后,由于使用了第二种方法,因此效果更好。
Note : For the complete data handling and tweaking with code — visit my github_profile.
注意:有关代码的完整数据处理和调整,请访问我的github_profile 。
5. LDA (Latent Dirichlet allocation) : Topic Modelling
5. LDA(潜在狄利克雷分配):主题建模
There are many approaches to topic modeling, Latent Dirichlet Allocation is the most popular topic modeling technique amongst all. Basically LDA is an application of mathematical matrix factorization technique in order to generate labels or topics for each document in the corpus. LDA takes a word frequency matrix as below, and tries to factorize a given matrix into two more matrices.
主题建模的方法很多,其中潜在的Dirichlet分配是最流行的主题建模技术。 基本上,LDA是数学矩阵分解技术的一种应用,目的是为语料库中的每个文档生成标签或主题。 LDA采取如下所示的字频矩阵,并尝试将给定的矩阵分解为另外两个矩阵。

6. Okapi BM25 Score :
6.霍加api BM25得分:
Okapi BM25 is simplest search engine introduced in 1990’s for information retrieval. The formulation of BM25 is very similar to TF-IDF. BM25 technique is such a effective searching algorithm used in very popular Elasticsearch software too.
Okapi BM25是1990年代推出的用于信息检索的最简单的搜索引擎。 BM25的配方与TF-IDF非常相似。 BM25技术也是一种非常流行的Elasticsearch软件中使用的有效搜索算法。


7. Sentence embedding : BERT
7.句子嵌入:BERT
BERT (Bidirectional Encoder Representations from Transformers) is language representation deep neural networks based technique. The biggest advantage of BERT over most of the previously found embedding techniques (except: w2v, but its word embedding) is ‘Transfer learning’ and ‘sentence-embeddings’. In 2014 VGG16 had made its own place in the space of computer vision community because of its ‘Transfer learning’ advantage, which was not possible in Natural language processing space at early stages. There are two existing strategies for applying pre-trained language representations: ‘feature-based’ and ‘fine-tuning’. Since the dataset has mathematics and computer science specific documents most likely ‘fine-tuning’ will help for semantic searching, But because of computational expenses I am limiting ourselves to ‘feature-based’ embedding only. This model has been pre-trained for English on the Wikipedia and BooksCorpus databases. BERT pretrained model architecture : here we get 2 options
BERT(来自变压器的双向编码器表示)是基于语言表示深度神经网络的技术。 BERT与以前发现的大多数嵌入技术(w2v除外,但其词嵌入)相比,最大的优势是“转移学习”和“句子嵌入”。 2014年,VGG16因其“转移学习”优势而在计算机视觉社区中占据了自己的一席之地,这在早期自然语言处理领域是不可能的。 现有两种应用预训练语言表示的策略:“基于功能”和“微调”。 由于数据集包含数学和计算机科学方面的特定文档,因此很可能“微调”将有助于语义搜索。但是由于计算量大,我将自己仅限于“基于功能”的嵌入。 该模型已在Wikipedia和BooksCorpus数据库上进行了英语预训练。 BERT预训练模型架构:在这里我们有2个选择
I. BASE : (L=12, H=768, A=12, Total Parameters=110M)
I.BASE:(L = 12,H = 768,A = 12,总参数= 110M)
II. LARGE : (L=24, H=1024, A=16, Total Parameters=340M)
二。 大:(L = 24,H = 1024,A = 16,总参数= 340M)
where; L = no.of transformer blocks,
哪里; L =变压器块数
H = Hidden layer size | A = number of self-attention heads
H =隐藏层大小| A =自我注意的负责人数量
8. Sentence embedding : Universal sentence encoder
8.句子嵌入:通用句子编码器
As the name (UNIVERSAL SENTENCE ENCODER) itself is self explanatory, ‘USE’ takes sentences as input and gives high dimensional vector representations of input text sentences. The input can be a variable length English text and the output will be a 512 dimensional vector. The universal-sentence-encoder model has two variants in it. one is trained with a deep averaging network (DAN) encoder, and another is trained with a Transformer. In this paper authors have mentioned that Transformer based USE tends to give better results than DAN. But it comes with price in terms of computational resources and run time complexity. The USE model is trained on the sources which are Wikipedia, web news, e Stanford Natural Language Inference (SNLI) corpus, web question-answer pages and discussion forums etc. The Author explains the USE model was created by keeping in mind unsupervised NLP tasks like Transfer learning using sentence embeddings, Hence it makes complete sense to use USE in our semantic search task.
由于名称(UNIVERSAL SENTENCE ENCODER)本身是不言自明的,因此“ USE”将句子作为输入,并提供输入文本句子的高维向量表示。 输入可以是可变长度的英文文本,输出是512维向量。 通用语句编码器模型具有两个变体。 一个受过深度平均网络(DAN)编码器的培训,另一受过变压器的培训。 在本文中,作者提到基于Transformer的USE往往比DAN提供更好的结果。 但是,它在计算资源和运行时间复杂性方面都付出了代价。 USE模型在以下方面进行了培训:维基百科,网络新闻,斯坦福自然语言推理(SNLI)语料库,网络问答页面和讨论论坛等。例如使用句子嵌入进行转移学习,因此在我们的语义搜索任务中使用USE完全有意义。

9. Entire pipeline deployment on a remote server :
9.整个管道在远程服务器上的部署:
A Cloud platform :
一个云平台:
To serve the purpose for the current project work, I deployed the entire pipeline on Google cloud platform (gcp). Launching a virtual machine with google cloud platform or Amazon web services (AWS) is way easy. I used very basic virtual machine instance with following specs :
为了达到当前项目工作的目的,我将整个管道部署在G oogle云平台 (gcp)上 。 使用Google Cloud Platform启动虚拟机 或Amazon Web Services (AWS)很简单。 我使用了具有以下规格的非常基本的虚拟机实例:
- OS image : Linux for deep learning 操作系统映像:用于深度学习的Linux
- 8 GB ram 8 GB内存
- 2 CPU 2个CPU
- 50 GB HDD 50 GB硬盘
Web App using Flask :
使用Flask的Web应用程序:
# Flask app
import flask
app = Flask(__name__)
@app.route('/index')
def index():
return flask.render_template('index.html')
@app.route('/predict', methods=['POST'])
def predict():
lst = request.form.to_dict()
print(lst)
results = USE_results(query = lst['query'], n = 10).tolist()
return jsonify({'Search_results' : results})To develop a web app with python and HTML, Flask is the easy and light weight open source framework. I’ve pasted required web app deployment code for any virtual machine my github, feel free to visit my profile.
要开发使用python和HTML的Web应用程序,Flask是简单轻便的开源框架。 我已经为github上的任何虚拟机粘贴了必需的Web应用程序部署代码,请随时访问我的个人资料。
10.1 Final Results : BERT
10.1最终结果:BERT
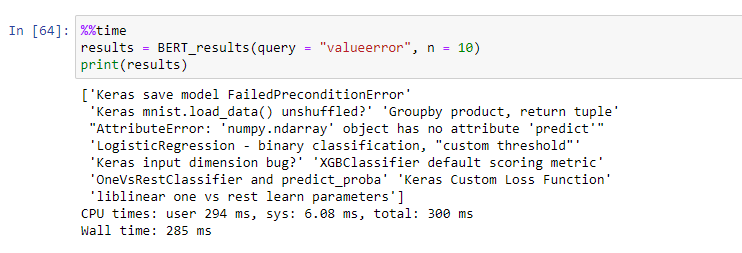
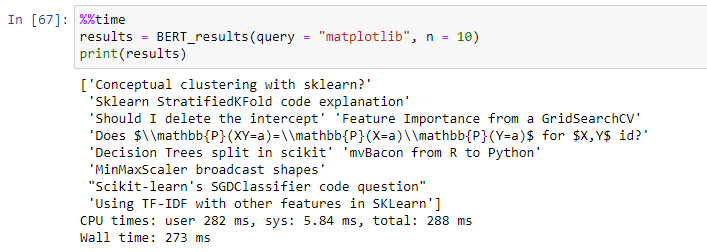
10.2. Final Results : USE
10.2。 最终结果:USE
10.3. Final Inferences :
10.3。 最终推断:
- In our case USE embeddings outperformed. A searching mechanism with USE vectors gives great reults with ‘semantic relationship’ between query and resulting results. 在我们的案例中,USE嵌入的效果要好。 使用USE向量的搜索机制对查询和结果之间的“语义关系”产生了很大的影响。
- The purpose of this case study is to build simple search engine with LOW latency. By using ‘right data structures’ in our mechanism, we make it happen to get results under 800–900 milliseconds on a normal 8 gb machine. 本案例研究的目的是构建具有低延迟的简单搜索引擎。 通过在我们的机制中使用“正确的数据结构”,我们可以在一台普通的8 gb机器上获得800-900毫秒以下的结果。
Please find complete code with documentation : https://github.com/vispute/StackOverflow_semantic_search_engine
请找到包含文档的完整代码: https : //github.com/vispute/StackOverflow_semantic_search_engine
Feel free to connect with me on LinkedIn : https://www.linkedin.com/in/akshay-vispute-a34bb5136/
随时在LinkedIn上与我联系 : https : //www.linkedin.com/in/akshay-vispute-a34bb5136/
Future work :
未来的工作 :
1. Take up to some million no.of datapoints into use.
1.最多使用数百万个数据点。
2. Pretrain BERT, USE sentence embedding on StackExchange data or downstream task.
2.预训练BERT,将USE语句嵌入到StackExchange数据或下游任务上。
3. Tutorial for ‘entire pipeline deployment on a remove web server like gcp or AWS or Azure’.
3.“在删除的Web服务器(如gcp或AWS或Azure)上进行整个管道部署”的教程。
References :
参考文献:
1. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding — https://arxiv.org/pdf/1810.04805.pdf
1. BERT:用于语言理解的深度双向变压器的预训练— https://arxiv.org/pdf/1810.04805.pdf
2. USE : UNIVERSAL SENTENCE ENCODER https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/4 6808.pdf
2.用途:通用句子编码器https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/4 6808.pdf
3. Topic Modelling — LDA (Latent Dirichlet Allocation) — LDA paper : http://link.springer.com/chapter/10.1007%2F978-3-642-13657-3_43
3.主题建模-LDA(潜在狄利克雷分配)-LDA论文: http : //link.springer.com/chapter/10.1007%2F978-3-642-13657-3_43
4. Improvements to BM25 and Language Models Examined : http://www.cs.otago.ac.nz/homepages/andrew/papers/2014-2.pdf
4.审查的BM25和语言模型的改进: http : //www.cs.otago.ac.nz/homepages/andrew/papers/2014-2.pdf
翻译自: https://medium.com/@vispute.ak/build-a-search-engine-based-on-stack-overflow-questions-88a4bc0c195c
基于堆栈的缓冲区溢出