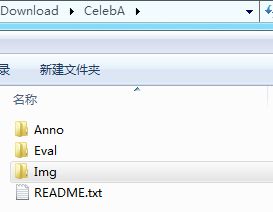
关于Celeba人脸数据集的介绍
CeleA是香港中文大学的开放数据,包含10177个名人身份的202599张图片,并且都做好了特征标记,这对人脸相关的训练是非常好用的数据集。
官网链接
网盘链接
别看只是一堆人脸,他们很贴心地做好了特征标记,也就是说,你可以找到类似下面这些标签:

40种属性:
01 5_o_Clock_Shadow 胡子,(清晨刮脸的人傍晚已长出的短髭 ) -1
02 Arched_Eyebrows 柳叶眉 1
03 Attractive 有魅力的 1
04 Bags_Under_Eyes 眼袋 -1
05 Bald 秃头的 -1
06 Bangs 刘海 -1
07 Big_Lips 大嘴唇 -1
08 Big_Nose 大鼻子 -1
09 Black_Hair 黑发 -1
10 Blond_Hair 金发 -1
11 Blurry 睡眼惺松的 -1
12 Brown_Hair 棕发 1
13 Bushy_Eyebrows 浓眉 -1
14 Chubby 丰满的 -1
15 Double_Chin 双下巴 -1
16 Eyeglasses 眼镜 -1
17 Goatee 山羊胡子 -1
18 Gray_Hair 白发,灰发 -1
19 Heavy_Makeup 浓妆 1
20 High_Cheekbones 高颧骨 1
21 Male 男性 -1
22 Mouth_Slightly_Open 嘴轻微的张开 1
23 Mustache 胡子 -1
24 Narrow_Eyes 窄眼 -1
25 No_Beard 没有胡子 1
26 Oval_Face 瓜子脸,鹅蛋脸 -1
27 Pale_Skin 白皮肤 -1
28 Pointy_Nose 尖鼻子 1
29 Receding_Hairline 发际线; 向后梳得发际线 -1
30 Rosy_Cheeks 玫瑰色的脸颊 -1
31 Sideburns 连鬓胡子,鬓脚 -1
32 Smiling 微笑的 1
33 Straight_Hair 直发 1
34 Wavy_Hair 卷发; 波浪发 -1
35 Wearing_Earrings 戴耳环 1
36 Wearing_Hat 带帽子 -1
37 Wearing_Lipstick 涂口红 1
38 Wearing_Necklace 带项链 -1
39 Wearing_Necktie 戴领带 -1
40 Young 年轻人 1
文件含义
进入百度网盘可以看到多个文件,但是都是干什么的呢?应该下载哪个来用呢?

在动手下载之前,最好先读读README文件,里面有比较详细的描述,这里只简单介绍一下:
- Img文件夹下是所有图片,图片又分三类文件:

| img_celeba.7z | 纯“野生”文件,也就是从网络爬取的没有做裁剪的图片 |
| img_align_celeba_png.7z | 把“野生”文件裁剪出人脸部分之后的图片,png格式 |
| img_align_celeba.zip | jpg格式的,比较小(推荐使用,直接解压即可) |

图中可以看到,人脸图片的名字只是简单的编号,那肤色、发色、眼镜、性别等特征标签在哪呢,在之前的“Anno”文件夹中:
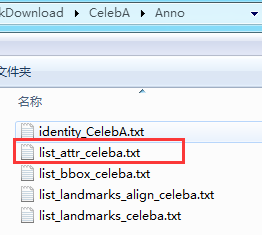
第一个“list_attr_celeba.txt”文本文件就记录了每一张图片的特征标签:
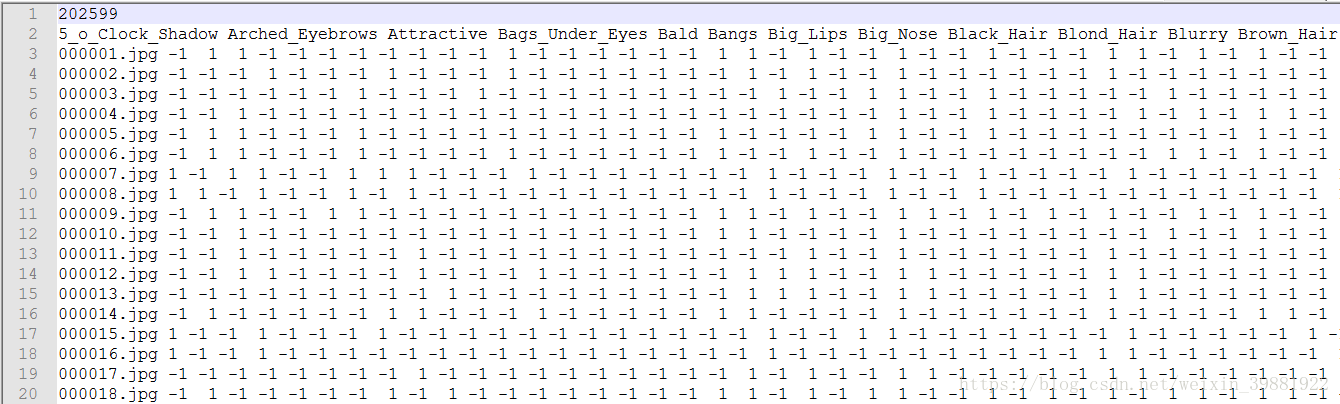
如图所示,第一行表示图片个数,第二行是特征类型,以空格分开,可以看到有超多特征。下面的行就是每张图片的标记了,第一列是图片名,后面的每个数字对应每一个特征,1表示正例,-1表示反例。
这样我们就有了图片和特征描述了,那怎么筛选出我们要的人脸图片呢?
假设我们要把所有人脸分成戴了眼镜的和没戴眼镜的两份集合,来训练从戴眼镜到不戴眼镜的转换。一个个地人眼去看去分类显然是不现实的,描述文件的意义就在于此。
我们可以写一份Python代码来遍历txt中每一张图片对应的“Eyeglasses”属性列,看是不是1,从而判断对应图片是否戴了眼镜。
数一数可以知道“Eyeglasses”是第16个属性,这样,我们可以读取这份属性描述txt,遍历每一行,看对应列是否是1,从而将图片名筛分到两个txt中去:
-
f =
open(
"list_attr_celeba.txt")
-
newTxt =
"glass.txt"
-
newf =
open(newTxt,
"a+")
-
newNoTxt =
"noGlass.txt"
-
newNof =
open(newNoTxt,
"a+")
-
-
#跳过第一行
202599
-
line = f.readline()
-
#跳过第二行属性名称
-
line = f.readline()
-
#第三行开始操作
-
line = f.readline()
-
while line:
-
array = line.split()
-
-
if (array[
16] ==
"-1"):
-
new_context = array[
0] +
'\n'
-
newNof.
write(new_context)
-
else:
-
new_context = array[
0] +
'\n'
-
newf.
write(new_context)
-
line = f.readline()
-
-
lines =
len(newf.readlines())
-
print (
"There are %d lines in %s" % (
lines, newTxt))
-
lines =
len(newNof.readlines())
-
print (
"There are %d lines in %s" % (
lines, newNoTxt))
-
-
f.
close()
-
newf.
close()
-
newNof.
close()

筛选图片
得到两个记录了有无戴眼镜的图片名集合txt后,我们就可以根据这个来筛选图片了。
图片共二十多万张,我们如果采用针对一个txt中每个图片名都去从头到尾到文件夹里找一次的方案,处理起来就太慢了。
这里我们采取更快速的方法,遍历文件夹中所有图片,对于遇到的每个图片名(当然,因为文件夹中不止图片,所以先判断是否是图片,也就是后缀是否是.jpg),去记录有无戴眼镜的两个txt中分别找是否包含该图片名,哪个包含,则把该图片移动到对应文件夹下去。
这里还可以优化的是,在txt中找图片名时,也不能每次要找都从头到尾找,而要记录上次找到的位置,因为图片名时按顺序排好的,所以下一张要找的图片名一定会在下面的行,而不会在之前出现过的行,这样也可以提速。
由于两个txt中行数不一致(有无戴眼镜的图片数量不同),所以要判断当一个txt全部找完后,之后就不要再去该txt中找了,更不要继续往后移动行,这样会出错的。
整体优化完成后代码如下:
-
mport
os
-
import
shutil
-
-
nof =
open("noGlass.txt")
-
hasf =
open("glass.txt")
-
-
noLine =
nof.readline()
-
hasLine =
hasf.readline()
-
-
list =
os.listdir("./CelebA/Img/img_align_celeba")
-
hasGo =
True
-
noGo =
True
-
for
i in range(0, len(list)):
-
imgName =
os.path.basename(list[i])
-
if
(os.path.splitext(imgName)[1] != ".jpg"): continue
-
-
noArray =
noLine.split()
-
if
(len(noArray) < 1): noGo = False
-
hasArray =
hasLine.split()
-
if
(len(hasArray) < 1): hasGo = False
-
-
if
(noGo and (imgName == noArray[0])):
-
oldname=
"./CelebA/Img/img_align_celeba/"+imgName
-
newname=
"./data/noGlass/"+imgName
-
shutil.move(oldname,
newname)
-
noLine =
nof.readline()
-
elif
(hasGo and (imgName == hasArray[0])):
-
oldname=
"./CelebA/Img/img_align_celeba/"+imgName
-
newname=
"./data/hasGlass/"+imgName
-
shutil.move(oldname,
newname)
-
hasLine =
hasf.readline()
-
-
print(imgName)
-
-
nof.close()
-
hasf.close()
方形脸部截取
-
from
PIL import Image
-
import
face_recognition
-
import
os
-
-
list =
os.listdir("./")
-
for
i in range(0, len(list)):
-
imgName =
os.path.basename(list[i])
-
if
(os.path.splitext(imgName)[1] != ".jpg"): continue
-
-
image =
face_recognition.load_image_file(imgName)
-
-
face_locations =
face_recognition.face_locations(image)
-
-
for
face_location in face_locations:
-
-
# Print the location of each face in this image
-
top,
right, bottom, left = face_location
-
# print("A face is located at pixel location Top: {}, Left: {}, Bottom: {}, Right: {}".format(top, left, bottom, right))
-
-
# You can access the actual face itself like this:
-
width =
right - left
-
height =
bottom - top
-
if
(width > height):
-
right
-= (width - height)
-
elif
(height > width):
-
bottom
-= (height - width)
-
face_image =
image[top:bottom, left:right]
-
pil_image =
Image.fromarray(face_image)
-
pil_image.save('face%s'%imgName)
这份代码就是遍历文件夹中的所有图片,用face_recognition库去识别出人脸位置的上下左右坐标,基本识别得出的坐标就已经是方形的了,特殊情况下会有一个像素的误差,所以我强制对比了一次宽高,不一样就改成一样的,对裁剪的影响也不会很大。需注意的是要运行这份代码需要安装face_recognition库和PIL库,如何安装就可以直接搜索教程了。
这里我们就得到了所有高宽相等的人脸二次裁剪图片。
还要注意的一点是这里只保证了每张图片自身高宽相等,图片之间的尺寸并不一定是同样大小的。
参考:
https://blog.csdn.net/Cloudox_/article/details/78432517