【赞】【转】CUI三部曲之语音识别——机器如何理解你的话?
在智能时代,以对话为主要交互形式的CUI会应用到越来越多的场景中。进行对话交互时,机器往往需要完成“听懂——理解——回答”的闭环。这个闭环涉及到三类技术:语音识别(ASR)、自然语言处理(NLP)以及语音合成(TTS)。
语音识别的任务是将用户所说的话从声音形式转变为文字形式,自然语言处理则是理解这些文字所要表达的意思(语义)。理解了用户的意图之后,机器同样会以语音的形式给出相应的回答,这就需要用到语音合成。

语音识别、自然语言理解与语音合成三者环环相扣,任何一环的失误都无法使产品获得良好的交互体验。而语音识别正是这一切的基础:识别成文字都出了问题,语义理解得再好也不可能正确到哪里去。
语音识别原理
语音识别已有数十年的发展历史,大体来看可以分为“传统”的识别方法和基于深度神经网络的“端到端”方法。
无论哪种方法,都会遵循“输入——编码——解码——输出”的流程。

语音识别的输入是声音,属于计算机无法直接处理的模拟信号,所以需要通过编码将其转变为数字信号,并提取其中的特征进行处理。编码时,一般会将声音信号按照很短的时间间隔(ms级别)切成一个个小段,称为帧;帧与帧之间会有一定的重叠。
对于得到的每一帧,可以通过某种规则(如依照人耳听声特点提出的MFCC规则),提取信号中的特征,将其变成一个多维向量。向量中的每一个维度可以看作描述了这帧信号中的一项特征。
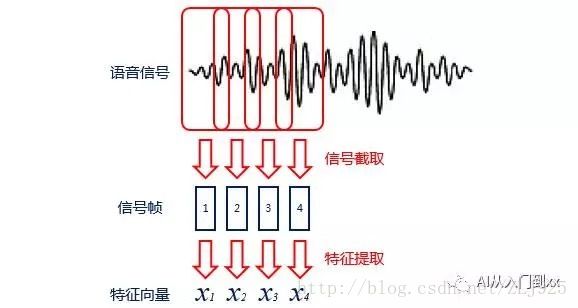
(编码过程)
解码则是将编码得到的向量变成文字的过程,其中需要用到两个模型:声学模型和语言模型。
声学模型通过处理编码得到的向量,将相邻的帧组合起来变成音素(如拼音中的声母韵母等),再组合起来变成单个的单词或汉字;
语言模型则用来调整声学模型所得到的不合逻辑的字词,使识别结果变得正确通顺。声学模型和语言模型都需要用大量的语音和语言数据来训练。

无论是编码过程中的特征提取规则,还是解码过程中的声学模型与语言模型,都有很多不同的种类。
而“传统”识别方式与“端到端”识别方式的主要差异就体现在声学模型上。
“传统”方式的声学模型一般采用隐马尔可夫模型(HMM),而“端到端”方式一般采用深度神经网络(DNN)。
对于“端到端”的识别方式,声学模型的输入通常可以使用更原始的信号特征(减少了编码阶段的工作),输出也不再必须经过音素等底层元素,可以直接是字母或者汉字。在计算资源与模型的训练数据充足的情况下,“端到端”方式往往能达到更好的效果。
语音识别的效果一般用“识别率”,即识别文字与标准文字相匹配的字数与标准文字总字数的比例来衡量。目前中文通用语音连续识别的识别率最高可以达到97%,已经能够应用到一些场景当中,但距离99%以上的“完美”效果还有很长的路要走。
从工具到交互
语音识别比较传统的应用是用作对语音信息的转录,或是在某些特定场景下作为向机器发送指令的方式,如通话质检、语音命令、语音输入法等。由于当时语音识别和自然语言处理技术水平的限制,这项技术的应用一直停留在单纯的工具层面。
近年来语音识别技术的研究取得突破,并有科大讯飞、云之声等企业将其产品化,使它的应用门槛明显降低。因此,作为人类最自然的交流方式与CUI的核心技术,语音识别的应用也正逐渐从工具层面向人机交互拓展。
然而,通过GUI和视觉传递信息是二维的,通过语音和听觉则是一维的,所以在大多数场景下语音的信息传递效率明显低于屏幕显示。而且,即便是CUI,有时也可以没有语音而通过文字来对话。所以问题来了,在什么样的场景下,语音交互是有明显需求的?

单纯通过GUI进行交互时,必须用手进行输入,用眼睛获取输出信息。所以在手的操作受到限制或者眼睛不方便一直注视屏幕时,仅仅通过GUI就很不方便;这就为使用语音进行交互创造了机会。
“手不方便”最典型的例子是智能家居,比如亚马逊的Echo:当你在沙发上葛优瘫的时候,是绝对不想起身去用手操作哪怕两米开外的设备的。“眼不方便”最典型的例子是智能车载:开车的时候如果总是盯着屏幕操作,即便是老司机也难免会翻车。
正因如此,智能家居与智能车载也成为了目前语音识别技术最受青睐的应用领域。几乎所有开展语音识别业务公司都将这两个领域作为重点战场。
当然,合适的场景肯定不止这两个,但总体而言都需要符合一个大的原则:不要在GUI本来就适合的场景下硬碰硬,而要寻找原有交互方式所不能完美满足的场景去替代,提升用户体验,从而形成突破。
交互场景的难点
当一项技术作为面向特定场景的工具时,面对的往往是相对专业的用户。哪怕此时的技术水平存在局限,用户也会尽可能地规避掉那些技术无法实现的情况。这时在用户心里,是存在着一种“正确打开方式”的。
但如果这项技术应用在了通用场景下的人机交互中,必然会面对形形色色的用户。他们心里根本不会将它当作是一项技术成果,而是和锅碗瓢盆冰箱彩电一样,想怎么用就怎么用,只要不爽,立马走掉。

(用户使用产品的方式)
这时,应用了这项技术的产品会碰到很多新的情况,对技术本身也必然会有更高更全面的要求,语音识别也不例外。智能家居与智能车载等适合语音交互的场景往往有这样两个特点:人与设备的距离相对较远、说话的环境相对嘈杂;所以就出现了下面一些技术难点。
(1)语音激活检测(VAD)
VAD指设备判断外界什么时候存在“有效语音”,什么时候不存在。当判断外界存在有效的语音时,机器才会对其进行后续的识别操作。
好比我们周围的环境中一直有各种声音,但绝大部分我们都会进行“屏蔽”,这样才能保证我们能够专心做自己的事情或者好好休息。对于机器来说也是一样,通过VAD把“无效”的声音信号(如风吹草动、宠物叫声、电视声音等)屏蔽掉,可以降低信号处理的计算量,也能减少噪声引起的误识别。
在近场识别(人与设备距离较近)中,VAD可有可无:比如可以通过设备上的一个按钮来控制它是否接受信号。即便需要,由于近场情况下信噪比(信号和噪声的比例)较高,简单的VAD算法也可以做到有效可靠。
但对于远场识别,用户无法方便地触摸设备,所以VAD必不可少;且由于环境干扰,信噪比较低,对VAD算法的复杂程度也要求更高,成为了一个具有挑战性的问题。
(2)语音唤醒(VT)
VT指设备通过识别“有效语音”中是否存在某个关键词(唤醒词),来判断用户接下来是否要对自己发出指令,以及自己是否需要进行响应。
好比我们在周围的环境中发现了可能和自己相关的声音(比如旁边人的谈话),就会去留意声音的内容是否和自己真的相关:如果别人的谈话中出现了自己的名字(唤醒词),那么很可能就需要自己去参与这次谈话了(响应)。
目前各家以对话为交互形式的产品都有自己的唤醒词,比如Google的“OK Google”、亚马逊Echo的“Alexa”等。
与VAD一样,VT在远场识别中必不可少,且对用户体验影响很大。如果唤醒词很长,用户唤醒设备就很麻烦,且容易被漏识别,很可能说了一串话,设备还是没有睬你;如果唤醒词很短,则容易出现误识别,也许用户什么都没说,设备自己开始说话了。
这个窘境也使得VT成为了语音识别中的又一个难点。为产品选择一个尽量短又朗朗上口的唤醒词,同时做到很低的误识率,也成为了各家公司技术实力的体现。
(3)语音打断
语音打断指在设备说话时,用户可以直接通过语音进行打断,而不需要通过用手按下停止键或是强行等设备把话说完。
在与用户交互的过程中,设备很可能出现错误理解用户意图的情况,而且很多回答听到一半就能大致明白它的意思。这时就可以通过语音,在发出新指令的同时打断设备正在说的话,不仅提高了效率,也更符合人类自身的交流方式。
显然,在设备自己说话的时候识别用户的语音会受到很大的干扰,如何从中分辨出用户的语音信号进行识别也对算法有较高的要求。
(4)低信噪比
在远场识别中,语音信号从用户传递到设备处的衰减非常明显;且对于某些场景(如驾驶汽车),环境噪音本来就比较大,这些都会使得语音信号的信噪比变低。
对于低信噪比语音信号的识别,单个麦克风已经不能胜任,需要多个麦克风按照一定规则排列组成的麦克风阵列,同时配合相应的算法。自行设计或选择一款合适的麦克风阵列已经逐渐成为语音交互产品的成功关键之一。
总结
在基于CUI的交互中,机器往往需要完成“听懂——理解——回答”的闭环,涉及到语音识别、自然语言理解与语音合成三类技术。其中,语音识别是机器完成这个闭环,为用户提供良好交互体验的基础。
语音识别有很多技术路线,大体可以分为“传统”的识别方式与“端到端”方式。不同的技术路线都遵循“输入——编码——解码——输出”的流程,只不过编码所用的规则与解码所用的模型有所区别。
随着技术的发展,语音识别的应用已经逐渐从单纯的工具层面拓展到人机交互。但语音传递信息的效率低于GUI,所以需要寻找不适合通过GUI进行交互的场景来突破,如智能家居与智能车载。
语音识别应用于人机交互必定会遇到各种复杂和奇葩的场景,从而遇到技术上的难点。目前这些难点主要由远场识别和环境嘈杂而引起,包括语音激活检测、语音唤醒、语音打断以及低信噪比情况下的识别。
最后,用一张图总结语音识别用于人机交互中的几个难点。
