知物由学 | 弱监督语义分割:从图像级标注快进到像素级预测
语义分割,旨在将图像中的所有像素进行分类,一直是计算机视觉图像领域的主要任务之一。在实际应用中,由于能准确地定位到物体所在区域并以像素级的精度排除掉背景的影响,一直是精细化识别、图像理解的可靠方式。
但是,构建语义分割数据集需要对每张图像上的每个像素进行标注。据统计,单张1280*720像素的图像分割标注时间约1.5个小时[1],而动辄上万、十万才能产生理想效果的数据集标注,所需要的人力物力让实际业务项目投入产出比极低。
针对这个问题,仅需图像级标注即可达到接近的分割效果的弱监督语义分割是近年来语义分割相关方向研究的热点。该技术通过利用更简单易得的图像级标注,以训练分类模型的方式获取物体的种子分割区域并优化,从而实现图像的像素级、密集性预测。
易盾算法团队经过深入调研后在实践中分析弱监督语义分割技术方向的特点,以及在实际项目上验证了其有效性,从而成功将该技术落地到实际项目中,并取得了显著的项目指标提升,有效助力易盾内容安全服务的精细化识别。
本文将介绍弱监督语义分割的分类和常规流程,并选择该方向中有代表性的几篇论文进行简单介绍。
一、基本信息
1.# 分类 #
根据弱监督信号的形式,常见的弱监督语义分割可分为以下四类:
① 图像级标注:仅标注图像中相关物体所属的类别,是最简单的标注;
② 物体点标注:标注各个物体上某一点,以及相应类别;
③ 物体框标注:标注各个物体所在的矩形框,以及相应类别;
④ 物体划线标注:在各个物体上划一条线,以及相应类别。

图1 | 弱监督语义分割的分类
本文主要关注标注最简单方便的、也是最难的基于图像级标注的弱监督语义分割。
2.# 基于图像级标注的弱监督语义分割步骤 #
基于图像级标注的弱监督语义分割大多采用多模块串联的形式进行,如图2[2]:
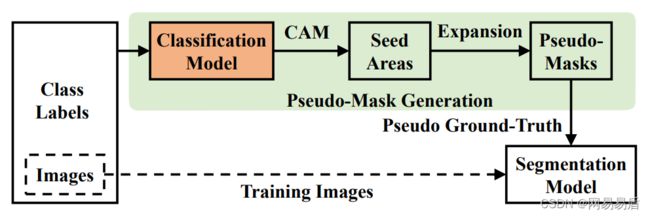
图2 | 弱监督语义分割的步骤
首先,利用图像级标注的图像类别标签,通过单标签或多标签分类的方式,训练出一个分类模型。该分类模型通过计算图像中相应类别的类别特征响应图 CAM[3]来当作分割伪标签的种子区域;接着,使用优化算法(如 CRF[4]、AffinityNet[5]等)优化和扩张种子区域,获得最终的像素级的分割伪标签;最后,使用图像数据集和分割伪标签训练传统的分割算法(如 Deeplab 系列[6])。
二、代表性工作
这部分主要介绍一下图像级弱监督分割中几篇典型的论文。首先介绍弱监督分割的基础论文 CAM[3],然后介绍2篇如何获取覆盖度更广、更精准的 CAM 的算法(OAA[7]、SEAM[8])作为分割伪标签的种子区域,最后介绍一篇典型的种子区域优化扩张算法 AffinityNet[5]。
1、CAM (Class Activation Mapping)
这篇文章是由周博磊在2016年的 CVPR 提出,作者发现了即使在没有定位标签的情况下训练好的 CNN 中间层也具备目标定位的特性,但是这种特性被卷积之后的向量拉伸和连续的全连接层破坏,但若是将最后的多个全连接层换成了全局平均池化层 GAP 和单个后接 Softmax 的全连接层,即可保留这种特性。同时,经过简单的计算,可以获取促使 CNN 用来确认图像属于某一类别的具有类别区分性的区域,即 CAM。
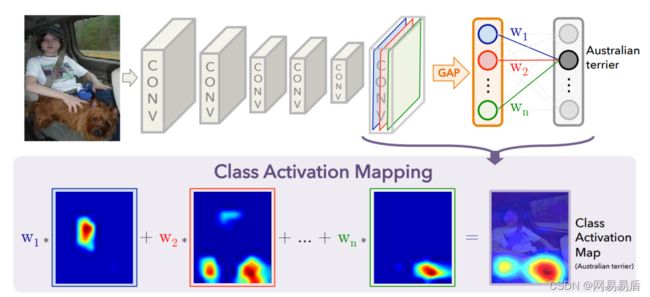
图3 | CAM
其中,CAM 的具体计算方式如下(如图3所示):
设为最后一层卷积层获取的第k个特征图在位置的值,是类别c对应最后一层全连接层第k个权重,则类别c的响应特征图 CAM 在位置的值为:
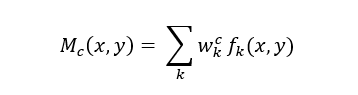
即为 CAM。最终 CAM 的值越大,表示对分类贡献度越高:如图3最后一幅图的热力图红色区域表示 CAM 值最大,也正是澳洲犬脸部区域。
在文章中,作者表示 CAM 所在区域可直接作为弱监督目标定位的预测,并进行了相关实验,不仅相比当时最好的弱监督定位算法效果提升明显,而且仅需单次前向推理过程即可得到定位框。
在弱监督语义分割中,CAM 一直是产生种子区域的核心算法。但是 CAM 缺点也很明显:仅关注最具辨别度的区域,无法覆盖到整个目标,后续的算法中大多是在解决这个问题或者对 CAM 进行后处理,接下来,会挑选几篇代表性的工作进行介绍。
2、获取更好的种子区域
(1)#OAA#
这篇文章的动机简单而直接,作者通过观察发现:在训练收敛前不同的训练阶段,模型所产生的 CAM 会在同一目标上的不同部位移动,如图4 中的b、c、d表示不同的训练阶段,其 CAM(高亮区域)在移动。当整合同一图像在不同阶段产生的 CAM 时,整合后的 CAM 更能覆盖完全整个目标,如图4-e。
 图4 | CAM 移动图
图4 | CAM 移动图
其算法示意图如下:
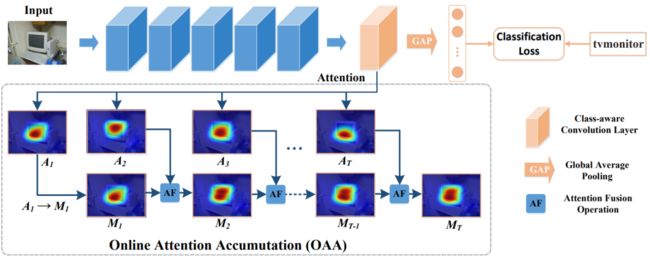
图5 | OAA算法示意图
对单张图像中的某个类别而言,在第t个 epoch 训练该图像时对其 CAM 特征图进行 ReLU 和标准化:
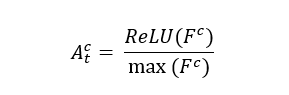
然后与前一 epoch 保存的特征图进行像素级比较,选择每个像素的最大值,最终输出为作为累积后的响应图。在训练完成后,即当作弱监督语义分割伪标签的种子区域。
OAA 算法简单且有效,当时在 VOC 弱监督分割数据集上取得了 SOTA 的表现;但笔者在实际项目尝试中发现其效果一般,原因在于多个 epoch 的 CAM 取最大值的方式容易使得种子区域出现较多噪声,而这些噪声是很难通过后处理消除的,最终导致分割精度明显下降。
(2)#SEAM#
该文章引入大火的自监督学习理念,通过观察发现同一图像经过不同的仿射变换所产生的 CAM 不一致这一特点(如图6-a中不同尺寸变换),利用隐式的等变换约束的方式建立类似自监督对比学习的一致性正则化学习机制,减少这种不一致程度来优化 CAM,从而得到高精度的种子区域(图6-b)。

图6 | 不同尺寸输入的图像的 CAM
SEAM 算法示意图如下:

图7 | SEAM 算法示意图
将原始图像和其经过简单的放射变换A(·)后(如缩小、左右翻转)的图像分别送入到共享参数的 CNN 中获取各自对应的 CAM 特征图和,这两个特征图再经过像素关系优化模块 Pixel Correlation Module (PCM) 的学习后分别得到优化后的 CAM 特征图和。其中,PCM 是类似于 self-attention 的操作,query 和 key 是 CNN 得到的特征图,value 是 CAM 特征。其 loss 由3部分构成:
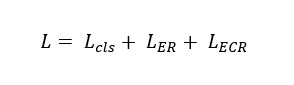
其中,是常用的多标签分类损失函数 multi-label soft margin loss,equivariant regularization (ER) loss 为:

equivariant cross regularization (ECR) loss 为:

推理时,采用多个尺度及其左右翻转后的图像产生的多个 CAM 加和、标准化后作为最终的 CAM。
SEAM 算法不仅在开放数据集相对其他算法取得了较大的提升,在易盾的实际项目中也取得较好的结果,其缺点是算法的训练和推理都比较耗时。
3、CAM后处理
在得到 CAM 种子区域后,可以直接作为语义分割伪标签进行训练,但为了更好的分割结果,通常会对种子区域进行优化,接下来会介绍一篇非常有效的算法 AffinityNet[5]。
该篇文章主要的做法是:对于一张图像和其相应的 CAM,建立所有像素与其周围一定半径的像素的邻接图,然后使用 AffinityNet 估计邻接图中像素对之间的语义密切关系以建立概率转移矩阵。对每个类别而言,邻接图中在目标边缘的点会根据概率转移矩阵以 random walk 鼓励该点扩散到相同语义的边缘位置,同时会惩罚扩散到其他类别的行为。这种语义的扩散和惩罚能显著优化 CAM,使其能较好地覆盖到整个目标,从而得到更精确、完整的伪标签。
该模型训练的主要难点在于如何不使用额外的监督信息,作者通过观察发现 CAM 可以作为产生训练 AffinityNet 监督信息的来源。虽然 CAM 存在覆盖不完全以及噪声问题,但是,CAM 依然会正确地覆盖局部区域并确认该区域像素间的语义密切关系,这正是 AffinityNet 所需要达成的目标。为了获取 CAM 可靠的标签,作者摒弃了 CAM 特征图分数相对较低的像素,只保留高得分和背景像素。在这些特征区域上采集像素对,如果它们属于同一类别则 label 为1,否则为0,如图8所示。

图8 | AffinityNet样本和标签示意图
在训练过程中图像经过 AffinityNet 得到特征图,则特征图上像素i和j的语义密切度计算方式如下:
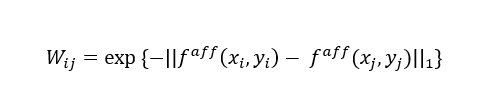
其中,表示第i个像素特征在特征图上的坐标位置。然后,利用交叉熵损失函数进行训练。
整体的训练和推理过程如下图所示:
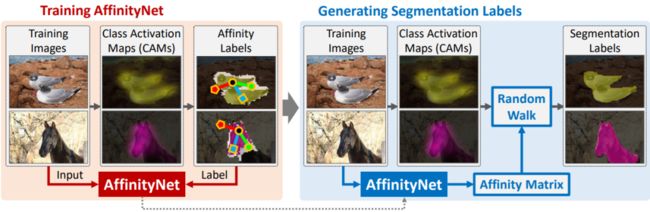
图9 | AffinityNet训练和推理示意图
首先利用训练图像的 CAM 选择多个像素对作为训练样本,并得到语义密切关系的 label,这些数据用来训练 AffinityNet(如图9左);然后使用训练好的 AffinityNet 在每张图像上进行推理计算以获取该图像邻接图的语义密切矩阵作为概率转移矩阵;最后在该图的 CAM 上以 random walk 的形式使用该矩阵,得到最终优化后的语义分割伪标签(如图9右)。
AffinityNet 算法思路清晰,结果可靠,常常作为 OAA 或 SEAM 等算法获取的 CAM 后处理方法用来优化伪标签精度和扩展伪标签覆盖区域,其提升效果在定性和定量分析中都很明显。
本文简单介绍了弱监督语义分割的概念和流程,并简单介绍了其中的几篇文章,以实践的角度分析了这些算法的落地优缺点。现有的弱监督语义分割也存在流程较为繁琐冗长的问题,在学界已经有一些工作提出端到端的解决方案,并取得了一定的效果(如[9][10])。未来,易盾算法团队会持续跟进学界最新方向,并尝试落地,以进一步提升内容安全服务精细化识别的效果。
四、参考文献
[1] Cordts M, Omran M, Ramos S, et al. The cityscapes dataset for semantic urban scene understanding[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 3213-3223.
[2] Zhang D, Zhang H, Tang J, et al. Causal intervention for weakly-supervised semantic segmentation[J]. Advances in Neural Information Processing Systems, 2020, 33: 655-666.
[3] Zhou B, Khosla A, Lapedriza A, et al. Learning deep features for discriminative localization[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2921-2929.
[4] Krähenbühl P, Koltun V. Efficient inference in fully connected crfs with gaussian edge potentials[J]. Advances in neural information processing systems, 2011, 24.
[5] Ahn J, Kwak S. Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 4981-4990.
[6] Chen L C, Papandreou G, Kokkinos I, et al. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 40(4): 834-848.
[7] Jiang P T, Hou Q, Cao Y, et al. Integral object mining via online attention accumulation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 2070-2079.
[8] Wang Y, Zhang J, Kan M, et al. Self-supervised equivariant attention mechanism for weakly supervised semantic segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 12275-12284.
[9] Zhang B, Xiao J, Wei Y, et al. Reliability does matter: An end-to-end weakly supervised semantic segmentation approach[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(07): 12765-12772.
[10] Araslanov N, Roth S. Single-stage semantic segmentation from image labels[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 4253-4262.