Python数据分析实战之物流行业数据分析
任务1: 数据预处理
表格数据资源如下百度网盘
链接:https://pan.baidu.com/s/1tB7Pt-Mpk-WBSLSSAewo6A 提取码:rx3k
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 为了确保中文能正常显示,设置 plt 绘制图像的字体为黑体
plt.rcParams['font.sans-serif'] = 'SimHei'
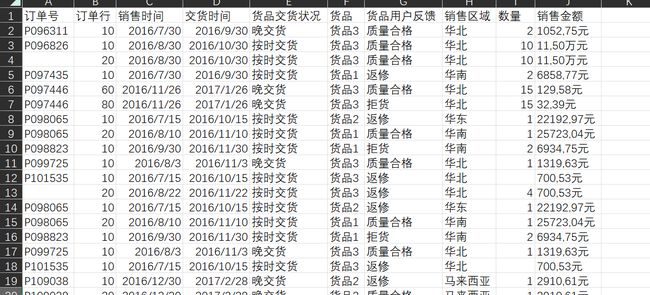
1.1 筛选掉重复值,缺失值,空值
# 使用 gbk 编码是为了中文正常显示
data = pd.read_csv('data_wuliu.csv',encoding='gbk')
# first 参数表示当有多行相同时,只保留第一行;inplace=True 表示在原数据上进行修改
data.drop_duplicates(keep='first',inplace=True)
# axis=0 代表按行删除空值,any 代表一行中只要出现空值就进行整行删除
# axis=0,how='any' 是 dropna() 方法的默认参数
data.dropna(axis=0,how='any',inplace=True)
data
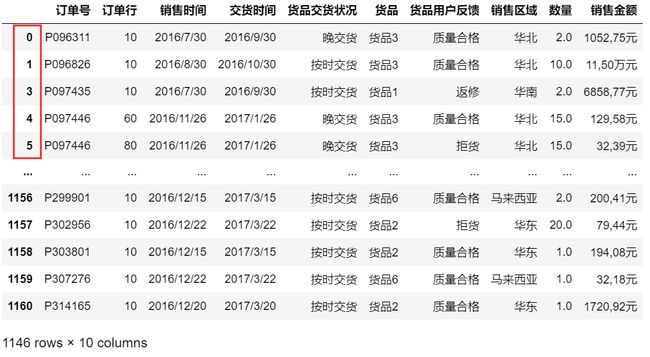
索引是在删除元素前创建的,因此删除后会出现索引值不连续的问题,可以通过更新索引来解决
# drop=True 即重新建立索引
data.reset_index(drop=True,inplace=True)
data # 更新后索引恢复正常
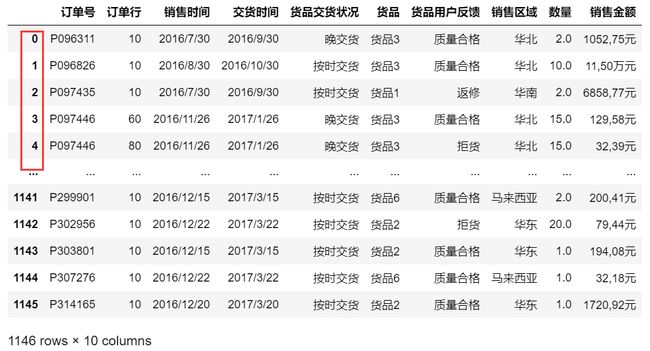
1.2 删除“订单行”列
# 删除订单行这列
data.drop(columns=['订单行'],axis=1,inplace=True)
data

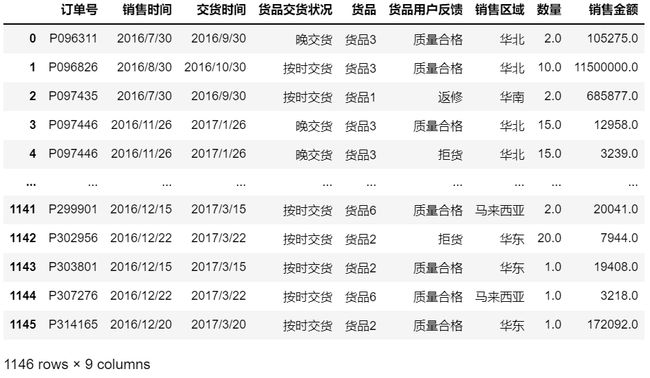
1.3 规整化”销售金额“列
# 对“销售金额”列的处理方法:规整为单位(元)且为浮点型
def data_deal(number):
# 说明包含'万元'
if number.find('万元')!= -1:
# 切片去除“万元”两个字,去除逗号,同时扩大一万倍
number=float(number[:-2].replace(',',''))*10000
else:
# 切片去除“元”这个字,去除逗号
number=float(number[:-1].replace(',',''))
return number
# 通过 map 将 data_deal(number) 函数作用在一整列上
data['销售金额']=data['销售金额'].map(data_deal)
data
1.4 删除销售金额为0的行
# 将销售金额为 0 的行进行删除
data=data[data['销售金额']!=0]
1.5 增添月份列
# 将其转换为日期类型
data['销售时间']=pd.to_datetime(data['销售时间'])
# 日期对象中 month 属性存放的就是当前日期的月份
data['月份']=data['销售时间'].map(lambda x:x.month)
data

任务2:分析每个月交货情况
# 处理掉'货品交货状况'中前后缀空格
data['货品交货状况'] = data['货品交货状况'].str.strip()
# 按照'月份','货品交货状况'两个关键词进行分组
# size()得到各个组的数量;unstack()使结果以 DataFrame 结构展示
data1=data.groupby(['月份','货品交货状况']).size().unstack()
# 添加'按时交货率'这列
data1['按时交货率']=data1['按时交货']/(data1['按时交货']+data1['晚交货'])
data1
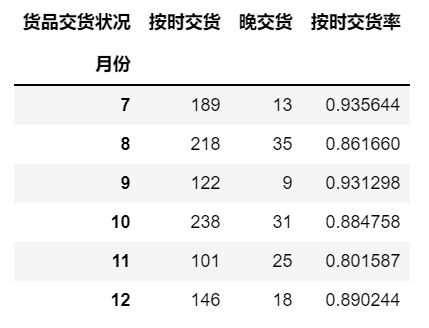
从中可以发现,7,8,9月交货率较高,而10,11,12月交货率较低,可以推测交货率可能有季节有关。
通过类似的方法同样可以对销售区域,具体货品等因素进行分析,此处不多赘述!
任务3:分析货品销售与区域及月份的关系
# 将'月份','销售区域','货品'相同的数据分为一组,其中对同组'数量'求和处理
data2=data.groupby(['月份','销售区域','货品'])['数量'].sum().unstack()
data2.head(8)
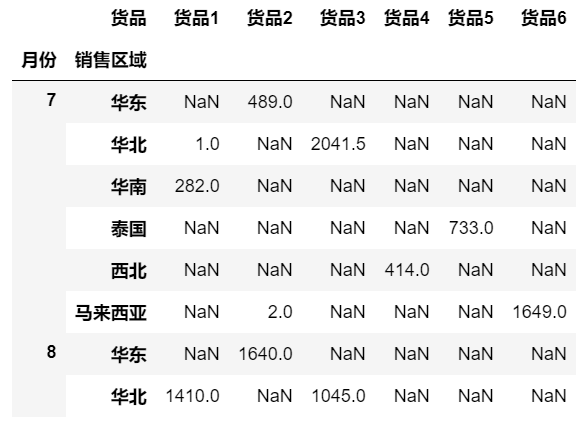
通过对具体的列进行观察,可以得知货品在哪个月份,哪个区域的销量最好,从而调节销售方案
任务4:统计不同货品在不同区域的用户反馈情况
# value_counts()统计同组的属性出现次数
data3=data.groupby(['货品','销售区域'])['货品用户反馈'].value_counts().unstack()
# sum默认按列求和,按行求和即当前货品在此销售区域的“货品用户反馈”总数
sums=data3.sum(axis=1)
# xx率=当前xx数量/总数量
data3['拒货率']=data3['拒货']/sums
data3['返修率']=data3['返修']/sums
data3['合格率']=data3['质量合格']/sums
# 依次按照'合格率','返修率','拒货率'进行降序排序;inplace=True表示在原数据上修改
data3.sort_values(['合格率','返修率','拒货率'],ascending=False,inplace=True)
data3
