目录
一、概要分析
二、集成连接池durid
一、连接池分类
二、集成步骤
1、导入pom.xml
2、更改yml文件
三、测试
三、集成集成缓存redis
1、导入依赖
2、更改yml文件
3、写好配置类
CrossConfiguration:
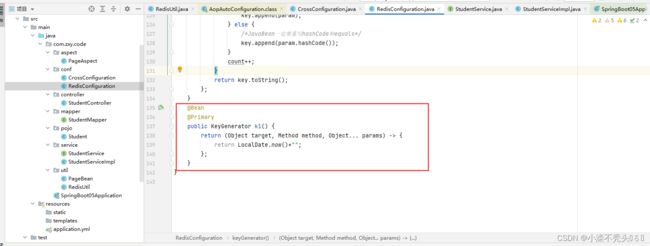
RedisConfiguration:
3.1 、实现类中使用@cacheable注解开启缓存
3.2、keyGenerator方法的使用
3.3、Template的使用
4、写好帮助类
RedisUtil:
一、概要分析
在日常敲代码的过程中,代码繁多以及运行速度慢,为了提高代码运行速度,优化代码性能,将提供一下两种方法来解决
二、集成连接池durid
一、连接池分类
C3P0 :是一个开放源代码的JDBC连接池,它在lib目录中与Hibernate一起发布,包括了实现jdbc3和jdbc2扩展规范说明的Connection 和Statement 池的DataSources 对象。
Proxool :是一个Java SQL Driver驱动程序,提供了对选择的其它类型的驱动程序的连接池封装。可以非常简单的移植到现存的代码中,完全可配置,快速、成熟、健壮。可以透明地为现存的JDBC驱动程序增加连接池功能。
Jakarta DBCP :DBCP是一个依赖Jakartacommons-pool对象池机制的数据库连接池。DBCP可以直接的在应用程序中使用。
BoneCP :是一个快速、开源的数据库连接池。帮用户管理数据连接,让应用程序能更快速地访问数据库。比C3P0/DBCP连接池速度快25倍。
Druid
二、集成步骤
1、新建模块
com.alibaba
druid-spring-boot-starter
1.2.8 3、更改yml文件
server:
port: 8080
spring:
datasource:
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/crm?useSSL=false&serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&allowPublicKeyRetrieval=true
type: com.alibaba.druid.pool.DruidDataSource
druid:
initial-size: 5 # 初始化大小
min-idle: 10 # 最小连接数
max-active: 20 # 最大连接数
max-wait: 60000 # 获取连接时的最大等待时间
min-evictable-idle-time-millis: 300000 # 一个连接在池中最小生存的时间,单位是毫秒
time-between-eviction-runs-millis: 60000 # 多久才进行一次检测需要关闭的空闲连接,单位是毫秒
filters: stat # 配置扩展插件:stat-监控统计,log4j-日志,wall-防火墙(防止SQL注入),去掉后,监控界面的sql无法统计 ,wall
validation-query: SELECT 1 # 检测连接是否有效的 SQL语句,为空时以下三个配置均无效
test-on-borrow: true # 申请连接时执行validationQuery检测连接是否有效,默认true,开启后会降低性能
test-on-return: true # 归还连接时执行validationQuery检测连接是否有效,默认false,开启后会降低性能
test-while-idle: true # 申请连接时如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效,默认false,建议开启,不影响性能
stat-view-servlet:
enabled: true # 是否开启 StatViewServlet
allow: 127.0.0.1 # 访问监控页面 白名单,默认127.0.0.1
deny: 192.168.56.1 # 访问监控页面 黑名单
login-username: admin # 访问监控页面 登陆账号
login-password: 123 # 访问监控页面 登陆密码
filter:
stat:
enabled: true # 是否开启 FilterStat,默认true
log-slow-sql: true # 是否开启 慢SQL 记录,默认false
slow-sql-millis: 5000 # 慢 SQL 的标准,默认 3000,单位:毫秒
merge-sql: false # 合并多个连接池的监控数据,默认false
redis:
database: 0 #数据库索引
host: 127.20.10.5 #主机位置
port: 6379 #端口
password: 123456 #密码
jedis:
pool:
max-active: 8 #最大连接数
max-wait: -1 #最大阻塞等待时间(负数表示没限制)
max-idle: 8 #最大空闲
min-idle: 0 #最小空闲
timeout: 10000 #连接超时时间
logging:
level:
com.zxy.code.mapper: debug
4、写实体类 package com.zxy.code.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;
/**
* 学生表 student
*/
@Data
@NoArgsConstructor
@AllArgsConstructor
@Accessors(chain = true)
public class Student {
/**
* 学生编号 主键 自增
*/
private Long stuId;
/**
* 学生名字
*/
private String stuName;
/**
* 学生电话
*/
private String stuPhone;
/**
* 学生班级
*/
private Long stuClass;
/**
* 学生地址
*/
private String stuAddress;
}5、mapper层
package com.zxy.code.mapper;
import com.zxy.code.pojo.Student;
import org.springframework.stereotype.Repository;
import tk.mybatis.mapper.common.Mapper;
//让当前类成为一个bean,被spring容器所管理
@Repository
public interface StudentMapper extends Mapper {
} 6、启动类进行管理mapper
Springboot05Application.java类:
package com.zxy.code;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.EnableAspectJAutoProxy;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import tk.mybatis.spring.annotation.MapperScan;
@SpringBootApplication
@MapperScan("com.zxy.code.mapper")
//开启切面的自动代理
@EnableAspectJAutoProxy
//开启事务管理器
@EnableTransactionManagement
public class Springboot05Application {
public static void main(String[] args) {
SpringApplication.run(Springboot05Application.class, args);
}
}7、service层
导入PageBean分页与PageAspect切面
PageBean分页:
package com.zxy.code.util;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import javax.servlet.http.HttpServletRequest;
import java.util.Map;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class PageBean {
private int total;
private int page = 1;
private int rows = 5;
private boolean pagination = true;
private String url;
private Map ms;
public void setMs(Map ms) {
this.ms = ms;
}
public int calcStartIndex() {
return (page - 1) * rows;
}
public int calcMaxPage() {
return total % rows == 0 ? total / rows : total / rows + 1;
}
public int nextPage() {
return page + 1 > calcMaxPage() ? calcMaxPage() : page + 1;
}
public int prevPage() {
return page - 1 > 1 ? page - 1 : 1;
}
public void setRequest(HttpServletRequest req) {
setUrl(req.getRequestURL().toString());
setMs(req.getParameterMap());
String page = req.getParameter("page");
if (page == null) {
setPage(1);
} else {
setPage(Integer.parseInt(page));
}
String rows = req.getParameter("rows");
if (rows == null) {
setRows(5);
} else {
setRows(Integer.parseInt(rows));
}
String pagination = req.getParameter("pagination");
if (pagination != null && "false".equals(pagination)) {
setPagination(false);
}
}
} PageAspect切面:
package com.zxy.code.aspect;
import com.github.pagehelper.Page;
import com.github.pagehelper.PageHelper;
import com.github.pagehelper.PageInfo;
import com.zxy.code.util.PageBean;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.stereotype.Component;
//让此类成为一个bean
@Component
@Aspect
@Slf4j
public class PageAspect {
@Around(value = "execution(* *..*Service.*Pager(..))")
public Object invoke(ProceedingJoinPoint point) throws Throwable {
PageBean pageBean = null;
for (Object e : point.getArgs()) {
if (e instanceof PageBean) {
pageBean = (PageBean) e;
break;
}
}
if (pageBean != null && pageBean.isPagination()) {
PageHelper.startPage(pageBean.getPage(), pageBean.getRows());
}
Object obj = point.proceed(point.getArgs());
if (obj != null) {
if (obj instanceof Page) {
Page page = (Page) obj;
PageInfo pageInfo = new PageInfo(page);
pageBean.setTotal(new Long(pageInfo.getTotal()).intValue());
return pageInfo.getList();
}
}
return obj;
}
}接口StudentService.java:
package com.zxy.code.service;
import com.zxy.code.pojo.Student;
import com.zxy.code.util.PageBean;
import java.util.List;
public interface StudentService {
List findPager(PageBean pageBean);
} 实现接口StudentServiceImpl:
package com.zxy.code.service;
import com.zxy.code.mapper.StudentMapper;
import com.zxy.code.pojo.Student;
import com.zxy.code.util.PageBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class StudentServiceImpl implements StudentService {
@Autowired
private StudentMapper mapper;
@Override
public List findPager(PageBean pageBean) {
return mapper.selectAll();
}
} 8、测试
Springboot05ApplicationTests :
package com.zxy.code;
import com.zxy.code.service.StudentService;
import com.zxy.code.util.PageBean;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class Springboot05ApplicationTests {
@Autowired
private StudentService service;
@Test
void contextLoads() {
PageBean pageBean=new PageBean();
service.findPager(pageBean).forEach(System.out::println);
}
}效果
数据查询出来后,下一步如果想知道查询了那些语句,那么这里就需要用到数据源连接池监控“监控地址( http://localhost:8080/druid/login.html) ”这里就可以看见你查询那些语句,和执行时间多久。好处是使用Druid在一定程度上可以提高数据库的访问技能.,方便对数据进行整理。
分页插件yml
pagehelper : # https://pagehelper.github.io/docs/howtouse
# 是否启用分页合理化。如果启用 , 当 page<1 时 , 会自动查询第一页的数据
# 当 page>maxPages 时 , 自动查询最后一页数据
# 不启用的 , 以上两种情况都会返回空数据
reasonable : true
# 分页插件会从查询方法的参数值中 , 自动根据上面 params 配置的字段中取值 , 查找到合适的值时就会
自动分页
supportMethodsArguments : true
# 默认值为 false, 当该参数设置为 true 时 , 如果 pageSize=0 或者 RowBounds.limit = 0 就
会查询出全部的结果
page-size-zero : true
# 指定数据库 , 不指定的话会默认自动检测数据库类型
helper-dialect : mysq
三、集成集成缓存redis
1、导入依赖
org.springframework.boot
spring-boot-starter-data-redis
2、更改yml文件
redis:
3、controller层
package com.lv.code.controller;
import com.lv.code.service.StudentService;
import com.lv.code.util.PageBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.servlet.http.HttpServletRequest;
//输出json数据
@RestController
//访问路径
@RequestMapping("stu")
public class StudentController {
@Autowired
private StudentService service;
@GetMapping("/all")
public Object index(HttpServletRequest request){
PageBean pageBean=new PageBean();
pageBean.setRequest(request);
return service.findPager(pageBean);
}
} 4、写好配置类
CrossConfiguration: package com.zxy.code.conf;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.CorsRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurerAdapter;
/**
* @author zjjt
*/
@Configuration
public class CrossConfiguration extends WebMvcConfigurerAdapter {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry
/*可以跨域的路径*/
.addMapping("/**")
/*可以跨域的ip*/
.allowedOrigins("*")
/*可以跨域的方法*/
.allowedMethods("*")
/*设置预检请求多就失效*/
.maxAge(6000)
/*允许携带的头部*/
.allowedHeaders("*");
}
}
RedisConfiguration: package com.zxy.code.conf;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.cache.interceptor.KeyGenerator;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import org.springframework.util.ClassUtils;
import java.lang.reflect.Array;
import java.lang.reflect.Method;
import java.time.Duration;
/**
* @author zjjt
*/
@Configuration
@EnableCaching //开启缓存
public class RedisConfiguration extends CachingConfigurerSupport {
//@Bean 相当于 @Component,只不过Bean可以写在方法上面,内在跟Component是一样的
@Bean
@Primary
CacheManager cacheManager(RedisConnectionFactory factory) {
RedisCacheConfiguration cacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()
.computePrefixWith(cacheName -> cacheName + ":-cache-:")
/*设置缓存过期时间*/
.entryTtl(Duration.ofHours(1))
/*禁用缓存空值,不缓存null校验*/
.disableCachingNullValues()
/*设置CacheManager的值序列化方式为json序列化,可使用加入@Class属性*/
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(
new GenericJackson2JsonRedisSerializer()
));
/*使用RedisCacheConfiguration创建RedisCacheManager*/
RedisCacheManager manager = RedisCacheManager.builder(factory)
.cacheDefaults(cacheConfiguration)
.build();
return manager;
}
@Bean
@Primary
public RedisTemplate redisTemplate(RedisConnectionFactory factory) {
RedisTemplate redisTemplate = new RedisTemplate();
redisTemplate.setConnectionFactory(factory);
RedisSerializer stringSerializer = new StringRedisSerializer();
/* key序列化 */
redisTemplate.setKeySerializer(stringSerializer);
/* value序列化 */
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
/* Hash key序列化 */
redisTemplate.setHashKeySerializer(stringSerializer);
/* Hash value序列化 */
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
@Bean
@Primary
@Override
public KeyGenerator keyGenerator() {
return (Object target, Method method, Object... params) -> {
final int NO_PARAM_KEY = 0;
final int NULL_PARAM_KEY = 53;
StringBuilder key = new StringBuilder();
/* Class.Method: */
key.append(target.getClass().getSimpleName())
.append(".")
.append(method.getName())
.append(":");
if (params.length == 0) {
return key.append(NO_PARAM_KEY).toString();
}
int count = 0;
for (Object param : params) {
/* 参数之间用,进行分隔 */
if (0 != count) {
key.append(',');
}
if (param == null) {
key.append(NULL_PARAM_KEY);
} else if (ClassUtils.isPrimitiveArray(param.getClass())) {
int length = Array.getLength(param);
for (int i = 0; i < length; i++) {
key.append(Array.get(param, i));
key.append(',');
}
} else if (ClassUtils.isPrimitiveOrWrapper(param.getClass()) || param instanceof String) {
key.append(param);
} else {
/*JavaBean一定要重写hashCode和equals*/
key.append(param.hashCode());
}
count++;
}
return key.toString();
};
}
}
cachemManager缓存管理器
redisTemplate直接用它操作redis里面的内容
keyGenerator 主键生成器
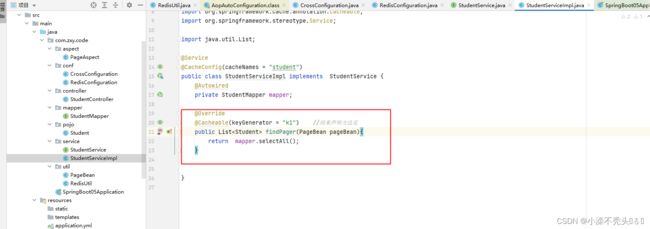
3.1 、实现类中使用@cacheable注解开启缓存
@Cacheable(cacheNames = "aa",cacheManager = "cacheManager") //用来声明方法是
public List findPager(PageBean pageBean){
return mapper.selectAll();
}
cacheNames是缓存的名字用来做分类的,查看缓存时方便,可以在类上进行注解,表示所有的方法的缓存名字都为指定名字
cacheManager是缓存管理器
第一次运行会出现sql语句,然后数据会进入redis缓存中
当修改cacheManager时
redis
keyGenerator方法的使用
redis:
key用来标识方法的结果,由键去找值,找不到进数据库,要去缓存用户信息,我们一般把用户的id作为键
spel表达式使用#取值
例如
@Override
@Cacheable(key ="#pageBean.page") //用来声明方法是
public List findPager(PageBean pageBean){
return mapper.selectAll();
}
cachePut用来更新缓存,用来做修改
cacheEvict用来删除缓存,通过键key
3.3、Template的使用
4、写好帮助类
RedisUtil: package com.zxy.code.util;
import com.fasterxml.jackson.databind.ObjectMapper;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeansException;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.data.redis.RedisSystemException;
import org.springframework.data.redis.connection.DataType;
import org.springframework.data.redis.connection.RedisConnection;
import org.springframework.data.redis.connection.RedisStringCommands;
import org.springframework.data.redis.connection.ReturnType;
import org.springframework.data.redis.connection.jedis.JedisConnection;
import org.springframework.data.redis.connection.lettuce.LettuceConnection;
import org.springframework.data.redis.core.Cursor;
import org.springframework.data.redis.core.RedisOperations;
import org.springframework.data.redis.core.ScanOptions;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.ZSetOperations.TypedTuple;
import org.springframework.data.redis.core.types.Expiration;
import org.springframework.stereotype.Component;
import java.nio.charset.StandardCharsets;
import java.time.Instant;
import java.util.*;
import java.util.Map.Entry;
import java.util.concurrent.TimeUnit;
/**
* Redis工具类
*
* 声明: 此工具只简单包装了redisTemplate的大部分常用的api,没有包装redisTemplate所有的api
* 如果对此工具类中的功能不太满意,或对StringRedisTemplate提供的api不太满意,
* 那么可自行实现相应的{@link StringRedisTemplate}类中的对应execute方法,以达
* 到自己想要的效果; 至于如何实现,则可参考源码或{@link LockOps}中的方法
*
* 注: 此工具类依赖spring-boot-starter-data-redis类库
* 注: 更多javadoc细节,可详见{@link RedisOperations}
*
* 统一说明一: 方法中的key、 value都不能为null
* 统一说明二: 不能跨数据类型进行操作,否者会操作失败/操作报错
* 如: 向一个String类型的做Hash操作,会失败/报错......等等
*/
@Slf4j
@Component
@SuppressWarnings("unused")
public class RedisUtil implements ApplicationContextAware {
/**
* 使用StringRedisTemplate(,其是RedisTemplate的定制化升级)
*/
private static StringRedisTemplate redisTemplate;
private static final ObjectMapper mapper = new ObjectMapper();
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
RedisUtil.redisTemplate = applicationContext.getBean(StringRedisTemplate.class);
}
/**
* key相关操作
*/
public static class KeyOps {
/**
* 根据key,删除redis中的对应key-value
*
* 注: 若删除失败,则返回false
*
* 若redis中,不存在该key,那么返回的也是false
* 所以,不能因为返回了false,就认为redis中一定还存
* 在该key对应的key-value
*
* @param key 要删除的key
* @return 删除是否成功
*/
public static Boolean delete(String key) {
log.info("delete(...) => key -> {}", key);
// 返回值只可能为true/false,不可能为null
Boolean result = redisTemplate.delete(key);
log.info("delete(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 根据keys,批量删除key-value
*
* 注: 若redis中,不存在对应的key,那么计数不会加1,即:
* redis中存在的key-value里,有名为a1、a2的key,
* 删除时,传的集合是a1、a2、a3,那么返回结果为2
*
* @param keys 要删除的key集合
* @return 删除了的key-value个数
*/
public static long delete(Collection keys) {
log.info("delete(...) => keys -> {}", keys);
Long count = redisTemplate.delete(keys);
log.info("delete(...) => count -> {}", count);
if (count == null) {
throw new RedisOpsResultIsNullException();
}
return count;
}
/**
* 将key对应的value值进行序列化,并返回序列化后的value值
*
* 注: 若不存在对应的key,则返回null
* 注: dump时,并不会删除redis中的对应key-value
* 注: dump功能与restore相反
*
* @param key 要序列化的value的key
* @return 序列化后的value值
*/
public static byte[] dump(String key) {
log.info("dump(...) =>key -> {}", key);
byte[] result = redisTemplate.dump(key);
log.info("dump(...) => result -> {}", result);
return result;
}
/**
* 将给定的value值,反序列化到redis中,形成新的key-value
*
* @param key value对应的key
* @param value 要反序列的value值
* 注: 这个值可以由{@link this#dump(String)}获得
* @param timeToLive 反序列化后的key-value的存活时长
* @param unit timeToLive的单位
* @throws RedisSystemException 如果redis中已存在同样的key时,抛出此异常
*/
public static void restore(String key, byte[] value, long timeToLive, TimeUnit unit) {
restore(key, value, timeToLive, unit, false);
}
/**
* 将给定的value值,反序列化到redis中,形成新的key-value
*
* @param key value对应的key
* @param value 要反序列的value值
* 注: 这个值可以由{@link this#dump(String)}获得
* @param timeout 反序列化后的key-value的存活时长
* @param unit timeout的单位
* @param replace 若redis中已经存在了相同的key,是否替代原来的key-value
* @throws RedisSystemException 如果redis中已存在同样的key,且replace为false时,抛出此异常
*/
public static void restore(String key, byte[] value, long timeout, TimeUnit unit, boolean replace) {
log.info("restore(...) => key -> {},value -> {},timeout -> {},unit -> {},replace -> {}",
key, value, timeout, unit, replace);
redisTemplate.restore(key, value, timeout, unit, replace);
}
/**
* redis中是否存在,指定key的key-value
*
* @param key 指定的key
* @return 是否存在对应的key-value
*/
public static boolean hasKey(String key) {
log.info("hasKey(...) => key -> {}", key);
Boolean result = redisTemplate.hasKey(key);
log.info("hasKey(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 给指定的key对应的key-value设置: 多久过时
*
* 注:过时后,redis会自动删除对应的key-value
* 注:若key不存在,那么也会返回false
*
* @param key 指定的key
* @param timeout 过时时间
* @param unit timeout的单位
* @return 操作是否成功
*/
public static boolean expire(String key, long timeout, TimeUnit unit) {
log.info("expire(...) => key -> {},timeout -> {},unit -> {}", key, timeout, unit);
Boolean result = redisTemplate.expire(key, timeout, unit);
log.info("expire(...) => result is -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 给指定的key对应的key-value设置: 什么时候过时
*
* 注:过时后,redis会自动删除对应的key-value
* 注:若key不存在,那么也会返回false
*
* @param key 指定的key
* @param date 啥时候过时
* @return 操作是否成功
*/
public static boolean expireAt(String key, Date date) {
log.info("expireAt(...) => key -> {},date -> {}", key, date);
Boolean result = redisTemplate.expireAt(key, date);
log.info("expireAt(...) => result is -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 找到所有匹配pattern的key,并返回该key的结合.
*
* 提示:若redis中键值对较多,此方法耗时相对较长,慎用!慎用!慎用!
*
* @param pattern 匹配模板
* 注: 常用的通配符有:
* ? 有且只有一个;
* * >=0个;
* @return 匹配pattern的key的集合 可能为null
*/
public static Set keys(String pattern) {
log.info("keys(...) => pattern -> {}", pattern);
Set keys = redisTemplate.keys(pattern);
log.info("keys(...) => keys -> {}", keys);
return keys;
}
/**
* 将当前数据库中的key对应的key-value,移动到对应位置的数据库中
*
* 注:单机版的redis,默认将存储分为16个db,index为0 到 15
* 注:同一个db下,key唯一; 但是在不同db中,key可以相同
* 注:若目标db下,已存在相同的key,那么move会失败,返回false
*
* @param key 定位要移动的key-value的key
* @param dbIndex 要移动到哪个db
* @return 移动是否成功
* 注: 若目标db下,已存在相同的key,那么move会失败,返回false
*/
public static boolean move(String key, int dbIndex) {
log.info("move(...) => key -> {},dbIndex -> {}", key, dbIndex);
Boolean result = redisTemplate.move(key, dbIndex);
log.info("move(...) =>result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 移除key对应的key-value的过期时间,使该key-value一直存在
*
* 注: 若key对应的key-value,本身就是一直存在(无过期时间的),那么persist方法会返回false;
* 若没有key对应的key-value存在,本那么persist方法会返回false;
*
* @param key 定位key-value的key
* @return 操作是否成功
*/
public static boolean persist(String key) {
log.info("persist(...) => key -> {}", key);
Boolean result = redisTemplate.persist(key);
log.info("persist(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 获取key对应的key-value的过期时间
*
* 注: 若key-value永不过期,那么返回的为-1
* 注: 若不存在key对应的key-value,那么返回的为-2
* 注:若存在零碎时间不足1 SECONDS,则(大体上)四舍五入到SECONDS级别
*
* @param key 定位key-value的key
* @return 过期时间(单位s)
*/
public static long getExpire(String key) {
return getExpire(key, TimeUnit.SECONDS);
}
/**
* 获取key对应的key-value的过期时间
*
* 注: 若key-value永不过期,那么返回的为-1
* 注: 若不存在key对应的key-value,那么返回的为-2
* 注:若存在零碎时间不足1 unit,则(大体上)四舍五入到unit别
*
* @param key 定位key-value的key
* @return 过期时间(单位unit)
*/
public static long getExpire(String key, TimeUnit unit) {
log.info("getExpire(...) =>key -> {},unit is -> {}", key, unit);
Long result = redisTemplate.getExpire(key, unit);
log.info("getExpire(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 从redis的所有key中,随机获取一个key
*
* 注: 若redis中不存在任何key-value,那么这里返回null
*
* @return 随机获取到的一个key
*/
public static String randomKey() {
String result = redisTemplate.randomKey();
log.info("randomKey(...) => result is -> {}", result);
return result;
}
/**
* 重命名对应的oldKey为新的newKey
*
* 注: 若oldKey不存在,则会抛出异常.
* 注: 若redis中已存在与newKey一样的key,
* 那么原key-value会被丢弃,
* 只留下新的key,以及原来的value
* 示例说明: 假设redis中已有 (keyAlpha,valueAlpha) 和 (keyBeta,valueBeat),
* 在使用rename(keyAlpha,keyBeta)替换后,redis中只会剩下(keyBeta,valueAlpha)
*
* @param oldKey 旧的key
* @param newKey 新的key
* @throws RedisSystemException 若oldKey不存在时,抛出此异常
*/
public static void rename(String oldKey, String newKey) {
log.info("rename(...) => oldKey -> {},newKey -> {}", oldKey, newKey);
redisTemplate.rename(oldKey, newKey);
}
/**
* 当redis中不存在newKey时,重命名对应的oldKey为新的newKey
* 否者不进行重命名操作
*
* 注: 若oldKey不存在,则会抛出异常.
*
* @param oldKey 旧的key
* @param newKey 新的key
* @throws RedisSystemException 若oldKey不存在时,抛出此异常
*/
public static boolean renameIfAbsent(String oldKey, String newKey) {
log.info("renameIfAbsent(...) => oldKey -> {},newKey -> {}", oldKey, newKey);
Boolean result = redisTemplate.renameIfAbsent(oldKey, newKey);
log.info("renameIfAbsent(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 获取key对应的value的数据类型
*
* 注: 若redis中不存在该key对应的key-value,那么这里返回NONE
*
* @param key 用于定位的key
* @return key对应的value的数据类型
*/
public static DataType type(String key) {
log.info("type(...) => key -> {}", key);
DataType result = redisTemplate.type(key);
log.info("type(...) => result -> {}", result);
return result;
}
}
/**
* string相关操作
*/
public static class StringOps {
/**
* 设置key-value
*
* 注: 若已存在相同的key,那么原来的key-value会被丢弃
*
* @param key key
* @param value key对应的value
*/
public static void set(String key, String value) {
log.info("set(...) => key -> {},value -> {}", key, value);
redisTemplate.opsForValue().set(key, value);
}
/**
* 处理redis中key对应的value值,将第offset位的值,设置为1或0
*
* 说明: 在redis中,存储的字符串都是以二级制的进行存在的; 如存储的key-value里,值为abc,实际上,
* 在redis里面存储的是011000010110001001100011,前8为对应a,中间8为对应b,后面8位对应c
* 示例:这里如果setBit(key,6,true)的话,就是将索引位置6的那个数,设置值为1,值就变成
* 了011000110110001001100011
* 追注:offset即index,从0开始
*
* 注: 参数value为true,则设置为1;参数value为false,则设置为0
*
* 注: 若redis中不存在对应的key,那么会自动创建新的
* 注: offset可以超过value在二进制下的索引长度
*
* @param key 定位value的key
* @param offset 要改变的bit的索引
* @param value 改为1或0,true - 改为1,false - 改为0
* @return set是否成功
*/
public static boolean setBit(String key, long offset, boolean value) {
log.info("setBit(...) => key -> {},offset -> {},value -> {}", key, offset, value);
Boolean result = redisTemplate.opsForValue().setBit(key, offset, value);
log.info("setBit(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 设置key-value
*
* 注: 若已存在相同的key,那么原来的key-value会被丢弃
*
* @param key key
* @param value key对应的value
* @param timeout 过时时长
* @param unit timeout的单位
*/
public static void setEx(String key, String value, long timeout, TimeUnit unit) {
log.info("setEx(...) => key -> {},value -> {},timeout -> {},unit -> {}",
key, value, timeout, unit);
redisTemplate.opsForValue().set(key, value, timeout, unit);
}
/**
* 若不存在key时,向redis中添加key-value,返回成功/失败
* 若存在,则不作任何操作,返回false
*
* @param key key
* @param value key对应的value
* @return set是否成功
*/
public static boolean setIfAbsent(String key, String value) {
log.info("setIfAbsent(...) => key -> {},value -> {}", key, value);
Boolean result = redisTemplate.opsForValue().setIfAbsent(key, value);
log.info("setIfAbsent(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 若不存在key时,向redis中添加一个(具有超时时长的)key-value,返回成功/失败
* 若存在,则不作任何操作,返回false
*
* @param key key
* @param value key对应的value
* @param timeout 超时时长
* @param unit timeout的单位
* @return set是否成功
*/
public static boolean setIfAbsent(String key, String value, long timeout, TimeUnit unit) {
log.info("setIfAbsent(...) => key -> {},value -> {},key -> {},value -> {}", key, value, timeout, unit);
Boolean result = redisTemplate.opsForValue().setIfAbsent(key, value, timeout, unit);
log.info("setIfAbsent(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 从(redis中key对应的)value的offset位置起(包含该位置),用replaceValue替换对应长度的值
*
* 举例说明:
* 1.假设redis中存在key-value ("ds","0123456789"); 调
* 用setRange("ds","abcdefghijk",3)后,redis中该value值就变为了[012abcdefghijk]
*
* 2.假设redis中存在key-value ("jd","0123456789");调
* 用setRange("jd","xyz",3)后,redis中该value值就变为了[012xyz6789]
*
* 3.假设redis中存在key-value ("ey","0123456789");调
* 用setRange("ey","qwer",15)后,redis中该value值就变为了[0123456789 qwer]
* 注:case3比较特殊,offset超过了原value的长度了,中间就会有一些空格来填充,但是如果在程序
* 中直接输出的话,中间那部分空格可能会出现乱码
*
* @param key 定位key-value的key
* @param replaceValue 要替换的值
* @param offset 起始位置
*/
public static void setRange(String key, String replaceValue, long offset) {
log.info("setRange(...) => key -> {},replaceValue -> {},offset -> {}", key, replaceValue, offset);
redisTemplate.opsForValue().set(key, replaceValue, offset);
}
/**
* 获取到key对应的value的长度
*
* 注: 长度等于{@link String#length}
* 注: 若redis中不存在对应的key-value,则返回值为0.
*
* @param key 定位value的key
* @return value的长度
*/
public static long size(String key) {
log.info("size(...) => key -> {}", key);
Long result = redisTemplate.opsForValue().size(key);
log.info("size(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 批量设置 key-value
*
* 注: 若存在相同的key,则原来的key-value会被丢弃
*
* @param maps key-value 集
*/
public static void multiSet(Map maps) {
log.info("multiSet(...) => maps -> {}", maps);
redisTemplate.opsForValue().multiSet(maps);
}
/**
* 当redis中,不存在任何一个keys时,才批量设置 key-value,并返回成功/失败.
* 否者,不进行任何操作,并返回false
*
* 即: 假设调用此方法时传入的参数map是这样的: {k1=v1,k2=v2,k3=v3}
* 那么redis中,k1、k2、k3都不存在时,才会批量设置key-value;
* 否则不会设置任何key-value
*
* 注: 若存在相同的key,则原来的key-value会被丢弃
*
* 注:
*
* @param maps key-value 集
* @return 操作是否成功
*/
public static boolean multiSetIfAbsent(Map maps) {
log.info("multiSetIfAbsent(...) => maps -> {}", maps);
Boolean result = redisTemplate.opsForValue().multiSetIfAbsent(maps);
log.info("multiSetIfAbsent(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 增/减 整数
*
* 注: 负数则为减
* 注: 若key对应的value值不支持增/减操作(即: value不是数字),那么会
* 抛出org.springframework.data.redis.RedisSystemException
*
* @param key 用于定位value的key
* @param increment 增加多少
* @return 增加后的总值
* @throws RedisSystemException key对应的value值不支持增/减操作时
*/
public static long incrBy(String key, long increment) {
log.info("incrBy(...) => key -> {},increment -> {}", key, increment);
Long result = redisTemplate.opsForValue().increment(key, increment);
log.info("incrBy(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 增/减 浮点数
*
* 注: 慎用浮点数,会有精度问题
* 如: 先 RedisUtil.StringOps.set("ds","123");
* 然后再RedisUtil.StringOps.incrByFloat("ds",100.6);
* 就会看到精度问题
* 注: 负数则为减
* 注: 若key对应的value值不支持增/减操作(即: value不是数字),那么会
* 抛出org.springframework.data.redis.RedisSystemException
*
* @param key 用于定位value的key
* @param increment 增加多少
* @return 增加后的总值
* @throws RedisSystemException key对应的value值不支持增/减操作时
*/
public static double incrByFloat(String key, double increment) {
log.info("incrByFloat(...) => key -> {},increment -> {}", key, increment);
Double result = redisTemplate.opsForValue().increment(key, increment);
log.info("incrByFloat(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 追加值到末尾
*
* 注: 当redis中原本不存在key时,那么(从效果上来看)此方法就等价于{@link this#set(String, String)}
*
* @param key 定位value的key
* @param value 要追加的value值
* @return 追加后, 整个value的长度
*/
public static int append(String key, String value) {
log.info("append(...) => key -> {},value -> {}", key, value);
Integer result = redisTemplate.opsForValue().append(key, value);
log.info("append(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 根据key,获取到对应的value值
*
* @param key key-value对应的key
* @return 该key对应的值
* 注: 若key不存在,则返回null
*/
public static String get(String key) {
log.info("get(...) => key -> {}", key);
String result = redisTemplate.opsForValue().get(key);
log.info("get(...) => result -> {} ", result);
return result;
}
/**
* 对(key对应的)value进行截取,截取范围为[start,end]
*
* 注: 若[start,end]的范围不在value的范围中,那么返回的是空字符串 ""
* 注: 若value只有一部分在[start,end]的范围中,那么返回的是value对应部分的内容(即:不足的地方,并不会以空来填充)
*
* @param key 定位value的key
* @param start 起始位置 (从0开始)
* @param end 结尾位置 (从0开始)
* @return 截取后的字符串
*/
public static String getRange(String key, long start, long end) {
log.info("getRange(...) => kry -> {}", key);
String result = redisTemplate.opsForValue().get(key, start, end);
log.info("getRange(...) => result -> {} ", result);
return result;
}
/**
* 给指定key设置新的value,并返回旧的value
*
* 注: 若redis中不存在key,那么此操作仍然可以成功,不过返回的旧值是null
*
* @param key 定位value的key
* @param newValue 要为该key设置的新的value值
* @return 旧的value值
*/
public static String getAndSet(String key, String newValue) {
log.info("getAndSet(...) => key -> {},value -> {}", key, newValue);
String oldValue = redisTemplate.opsForValue().getAndSet(key, newValue);
log.info("getAndSet(...) => oldValue -> {}", oldValue);
return oldValue;
}
/**
* 获取(key对应的)value在二进制下,offset位置的bit值
*
* 注: 当offset的值在(二进制下的value的)索引范围外时,返回的也是false
*
* 示例:
* RedisUtil.StringOps.set("akey","a");
* 字符串a,转换为二进制为01100001
* 那么getBit("akey",6)获取到的结果为false
*
* @param key 定位value的key
* @param offset 定位bit的索引
* @return offset位置对应的bit的值(true - 1, false - 0)
*/
public static boolean getBit(String key, long offset) {
log.info("getBit(...) => key -> {},offset -> {}", key, offset);
Boolean result = redisTemplate.opsForValue().getBit(key, offset);
log.info("getBit(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 批量获取value值
*
* 注: 若redis中,对应的key不存在,那么该key对应的返回的value值为null
*
* @param keys key集
* @return value值集合
*/
public static List multiGet(Collection keys) {
log.info("multiGet(...) => keys -> {}", keys);
List result = redisTemplate.opsForValue().multiGet(keys);
log.info("multiGet(...) => result -> {}", result);
return result;
}
}
/**
* hash相关操作
*
* 提示: 简单的,可以将redis中hash的数据结构看作是 Map>
*/
public static class HashOps {
/**
* 向key对应的hash中,增加一个键值对entryKey-entryValue
*
* 注: 同一个hash里面,若已存在相同的entryKey,那么此操作将丢弃原来的entryKey-entryValue,
* 而使用新的entryKey-entryValue
*
* @param key 定位hash的key
* @param entryKey 要向hash中增加的键值对里的 键
* @param entryValue 要向hash中增加的键值对里的 值
*/
public static void hPut(String key, String entryKey, String entryValue) {
log.info("hPut(...) => key -> {},entryKey -> {},entryValue -> {}", key, entryKey, entryValue);
redisTemplate.opsForHash().put(key, entryKey, entryValue);
}
/**
* 向key对应的hash中,增加maps(即: 批量增加entry集)
*
* 注: 同一个hash里面,若已存在相同的entryKey,那么此操作将丢弃原来的entryKey-entryValue,
* 而使用新的entryKey-entryValue
*
* @param key 定位hash的key
* @param maps 要向hash中增加的键值对集
*/
public static void hPutAll(String key, Map maps) {
log.info("hPutAll(...) => key -> {},maps -> {}", key, maps);
redisTemplate.opsForHash().putAll(key, maps);
}
/**
* 当key对应的hash中,不存在entryKey时,才(向key对应的hash中,)增加entryKey-entryValue
* 否则,不进行任何操作
*
* @param key 定位hash的key
* @param entryKey 要向hash中增加的键值对里的 键
* @param entryValue 要向hash中增加的键值对里的 值
* @return 操作是否成功
*/
public static boolean hPutIfAbsent(String key, String entryKey, String entryValue) {
log.info("hPutIfAbsent(...) => key -> {},entryKey -> {},entryValue -> {}",
key, entryKey, entryValue);
Boolean result = redisTemplate.opsForHash().putIfAbsent(key, entryKey, entryValue);
log.info("hPutIfAbsent(...) => result -> {}", result);
if (result != null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 获取到key对应的hash里面的对应字段的值
*
* 注: 若redis中不存在对应的key,则返回null
* 若key对应的hash中不存在对应的entryKey,也会返回null
*
* @param key 定位hash的key
* @param entryKey 定位hash里面的entryValue的entryKey
* @return key对应的hash里的entryKey对应的entryValue值
*/
public static Object hGet(String key, String entryKey) {
log.info("hGet(...) => key -> {},entryKey -> {}", key, entryKey);
Object entryValue = redisTemplate.opsForHash().get(key, entryKey);
log.info("hGet(...) => entryValue -> {}", entryValue);
return entryValue;
}
/**
* 获取到key对应的hash(即: 获取到key对应的Map)
*
* 注: 若redis中不存在对应的key,则返回一个没有任何entry的空的Map(,而不是返回null)
*
* @param key 定位hash的key
* @return key对应的hash
*/
public static Map hGetAll(String key) {
log.info("hGetAll(...) => key -> {}", key);
Map result = redisTemplate.opsForHash().entries(key);
log.info("hGetAll(...) => result -> {}", result);
return result;
}
/**
* 批量获取(key对应的)hash中的entryKey的entryValue
*
* 注: 若hash中对应的entryKey不存在,那么返回的对应的entryValue值为null
* 注: redis中key不存在,那么返回的List中,每个元素都为null
* 追注: 这个List本身不为null,size也不为0,只是每个list中的每个元素为null而已
*
* @param key 定位hash的key
* @param entryKeys 需要获取的hash中的字段集
* @return hash中对应entryKeys的对应entryValue集
*/
public static List hMultiGet(String key, Collection entryKeys) {
log.info("hMultiGet(...) => key -> {},entryKeys -> {}", key, entryKeys);
List entryValues = redisTemplate.opsForHash().multiGet(key, entryKeys);
log.info("hMultiGet(...) => entryValues -> {}", entryValues);
return entryValues;
}
/**
* (批量)删除(key对应的)hash中的对应entryKey-entryValue
*
* 注: 1、若redis中不存在对应的key,则返回0;
* 2、若要删除的entryKey,在key对应的hash中不存在,在count不会+1,如:
* RedisUtil.HashOps.hPut("ds","name","邓沙利文");
* RedisUtil.HashOps.hPut("ds","birthday","1994-02-05");
* RedisUtil.HashOps.hPut("ds","hobby","女");
* 则调用RedisUtil.HashOps.hDelete("ds","name","birthday","hobby","non-exist-entryKey")
* 的返回结果为3
* 注: 若(key对应的)hash中的所有entry都被删除了,那么该key也会被删除
*
* @param key 定位hash的key
* @param entryKeys 定位要删除的entryKey-entryValue的entryKey
* @return 删除了对应hash中多少个entry
*/
public static long hDelete(String key, Object... entryKeys) {
log.info("hDelete(...) => key -> {},entryKeys -> {}", key, entryKeys);
Long count = redisTemplate.opsForHash().delete(key, entryKeys);
log.info("hDelete(...) => count -> {}", count);
if (count == null) {
throw new RedisOpsResultIsNullException();
}
return count;
}
/**
* 查看(key对应的)hash中,是否存在entryKey对应的entry
*
* 注: 若redis中不存在key,则返回false
* 注: 若key对应的hash中不存在对应的entryKey,也会返回false
*
* @param key 定位hash的key
* @param entryKey 定位hash中entry的entryKey
* @return hash中是否存在entryKey对应的entry.
*/
public static boolean hExists(String key, String entryKey) {
log.info("hDelete(...) => key -> {},entryKeys -> {}", key, entryKey);
Boolean exist = redisTemplate.opsForHash().hasKey(key, entryKey);
log.info("hDelete(...) => exist -> {}", exist);
return exist;
}
/**
* 增/减(hash中的某个entryValue值) 整数
*
* 注: 负数则为减
* 注: 若key不存在,那么会自动创建对应的hash,并创建对应的entryKey、entryValue,entryValue的初始值为increment
* 注: 若entryKey不存在,那么会自动创建对应的entryValue,entryValue的初始值为increment
* 注: 若key对应的value值不支持增/减操作(即: value不是数字),那么会
* 抛出org.springframework.data.redis.RedisSystemException
*
* @param key 用于定位hash的key
* @param entryKey 用于定位entryValue的entryKey
* @param increment 增加多少
* @return 增加后的总值
* @throws RedisSystemException key对应的value值不支持增/减操作时
*/
public static long hIncrBy(String key, Object entryKey, long increment) {
log.info("hIncrBy(...) => key -> {},entryKey -> {},increment -> {}",
key, entryKey, increment);
Long result = redisTemplate.opsForHash().increment(key, entryKey, increment);
log.info("hIncrBy(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 增/减(hash中的某个entryValue值) 浮点数
*
* 注: 负数则为减
* 注: 若key不存在,那么会自动创建对应的hash,并创建对应的entryKey、entryValue,entryValue的初始值为increment
* 注: 若entryKey不存在,那么会自动创建对应的entryValue,entryValue的初始值为increment
* 注: 若key对应的value值不支持增/减操作(即: value不是数字),那么会
* 抛出org.springframework.data.redis.RedisSystemException
* 注: 因为是浮点数,所以可能会和{@link StringOps#incrByFloat(String, double)}一样,出现精度问题
* 追注: 本人简单测试了几组数据,暂未出现精度问题
*
* @param key 用于定位hash的key
* @param entryKey 用于定位entryValue的entryKey
* @param increment 增加多少
* @return 增加后的总值
* @throws RedisSystemException key对应的value值不支持增/减操作时
*/
public static double hIncrByFloat(String key, Object entryKey, double increment) {
log.info("hIncrByFloat(...) => key -> {},entryKey -> {},increment -> {}",
key, entryKey, increment);
Double result = redisTemplate.opsForHash().increment(key, entryKey, increment);
log.info("hIncrByFloat(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 获取(key对应的)hash中的所有entryKey
*
* 注: 若key不存在,则返回的是一个空的Set(,而不是返回null)
*
* @param key 定位hash的key
* @return hash中的所有entryKey
*/
public static Set hKeys(String key) {
log.info("hKeys(...) => key -> {}", key);
Set entryKeys = redisTemplate.opsForHash().keys(key);
log.info("hKeys(...) => entryKeys -> {}", entryKeys);
return entryKeys;
}
/**
* 获取(key对应的)hash中的所有entryValue
*
* 注: 若key不存在,则返回的是一个空的List(,而不是返回null)
*
* @param key 定位hash的key
* @return hash中的所有entryValue
*/
public static List hValues(String key) {
log.info("hValues(...) => key -> {}", key);
List entryValues = redisTemplate.opsForHash().values(key);
log.info("hValues(...) => entryValues -> {}", entryValues);
return entryValues;
}
/**
* 获取(key对应的)hash中的所有entry的数量
*
* 注: 若redis中不存在对应的key,则返回值为0
*
* @param key 定位hash的key
* @return (key对应的)hash中, entry的个数
*/
public static long hSize(String key) {
log.info("hSize(...) => key -> {}", key);
Long count = redisTemplate.opsForHash().size(key);
log.info("hSize(...) => count -> {}", count);
if (count == null) {
throw new RedisOpsResultIsNullException();
}
return count;
}
/**
* 根据options匹配到(key对应的)hash中的对应的entryKey,并返回对应的entry集
*
*
* 注: ScanOptions实例的创建方式举例:
* 1、ScanOptions.NONE
* 2、ScanOptions.scanOptions().match("n??e").build()
*
* @param key 定位hash的key
* @param options 匹配entryKey的条件
* 注: ScanOptions.NONE表示全部匹配
* 注: ScanOptions.scanOptions().match(pattern).build()表示按照pattern匹配,
* 其中pattern中可以使用通配符 * ? 等,
* * 表示>=0个字符
* ? 表示有且只有一个字符
* 此处的匹配规则与{@link KeyOps#keys(String)}处的一样
* @return 匹配到的(key对应的)hash中的entry
*/
@SneakyThrows
public static Cursor> hScan(String key, ScanOptions options) {
log.info("hScan(...) => key -> {},options -> {}", key, mapper.writeValueAsString(options));
Cursor> cursor = redisTemplate.opsForHash().scan(key, options);
log.info("hScan(...) => cursor -> {}", mapper.writeValueAsString(cursor));
return cursor;
}
}
/**
* list相关操作
*
* 提示: 列表中的元素,可以重复
*
* 提示: list是有序的
*
* 提示: redis中的list中的索引,可分为两类,这两类都可以用来定位list中元素:
* 类别一: 从left到right,是从0开始依次增大: 0, 1, 2, 3...
* 类别二: 从right到left,是从-1开始依次减小: -1,-2,-3,-4...
*/
public static class ListOps {
/**
* 从左端推入元素进列表
*
* 注: 若redis中不存在对应的key,那么会自动创建
*
* @param key 定位list的key
* @param item 要推入list的元素
* @return 推入后, (key对应的)list的size
*/
public static long lLeftPush(String key, String item) {
log.info("lLeftPush(...) => key -> {},item -> {}", key, item);
Long size = redisTemplate.opsForList().leftPush(key, item);
log.info("lLeftPush(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 从左端批量推入元素进列表
*
* 注: 若redis中不存在对应的key,那么会自动创建
* 注: 这一批item中,先push左侧的,后push右侧的
*
* @param key 定位list的key
* @param items 要批量推入list的元素集
* @return 推入后, (key对应的)list的size
*/
public static long lLeftPushAll(String key, String... items) {
log.info("lLeftPushAll(...) => key -> {},items -> {}", key, items);
Long size = redisTemplate.opsForList().leftPushAll(key, items);
log.info("lLeftPushAll(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 从左端批量推入元素进列表
*
* 注: 若redis中不存在对应的key,那么会自动创建
* 注: 这一批item中,那个item先从Collection取出来,就先push哪个
*
* @param key 定位list的key
* @param items 要批量推入list的元素集
* @return 推入后, (key对应的)list的size
*/
public static long lLeftPushAll(String key, Collection items) {
log.info("lLeftPushAll(...) => key -> {},items -> {}", key, items);
Long size = redisTemplate.opsForList().leftPushAll(key, items);
log.info("lLeftPushAll(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 如果redis中存在key,则从左端批量推入元素进列表;
* 否则,不进行任何操作
*
* @param key 定位list的key
* @param item 要推入list的项
* @return 推入后, (key对应的)list的size
*/
public static long lLeftPushIfPresent(String key, String item) {
log.info("lLeftPushIfPresent(...) => key -> {},item -> {}", key, item);
Long size = redisTemplate.opsForList().leftPushIfPresent(key, item);
log.info("lLeftPushIfPresent(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 若key对应的list中存在pivot项,那么将item放入第一个pivot项前(即:放在第一个pivot项左边);
* 若key对应的list中不存在pivot项,那么不做任何操作,直接返回-1
*
* 注: 若redis中不存在对应的key,那么会自动创建
*
* @param key 定位list的key
* @param item 要推入list的元素
* @return 推入后, (key对应的)list的size
*/
public static long lLeftPush(String key, String pivot, String item) {
log.info("lLeftPush(...) => key -> {},pivot -> {},item -> {}", key, pivot, item);
Long size = redisTemplate.opsForList().leftPush(key, pivot, item);
log.info("lLeftPush(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 与{@link ListOps#lLeftPush(String, String)}类比即可,不过是从list右侧推入元素
*/
public static long lRightPush(String key, String item) {
log.info("lRightPush(...) => key -> {},item -> {}", key, item);
Long size = redisTemplate.opsForList().rightPush(key, item);
log.info("lRightPush(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 与{@link ListOps#lLeftPushAll(String, String...)}类比即可,不过是从list右侧推入元素
*/
public static long lRightPushAll(String key, String... items) {
log.info("lRightPushAll(...) => key -> {},items -> {}", key, items);
Long size = redisTemplate.opsForList().rightPushAll(key, items);
log.info("lRightPushAll(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 与{@link ListOps#lLeftPushAll(String, Collection)}类比即可,不过是从list右侧推入元素
*/
public static long lRightPushAll(String key, Collection items) {
log.info("lRightPushAll(...) => key -> {},items -> {}", key, items);
Long size = redisTemplate.opsForList().rightPushAll(key, items);
log.info("lRightPushAll(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 与{@link ListOps#lLeftPushIfPresent(String, String)}类比即可,不过是从list右侧推入元素
*/
public static long lRightPushIfPresent(String key, String item) {
log.info("lRightPushIfPresent(...) => key -> {},item -> {}", key, item);
Long size = redisTemplate.opsForList().rightPushIfPresent(key, item);
log.info("lRightPushIfPresent(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 与{@link ListOps#lLeftPush(String, String, String)}类比即可,不过是从list右侧推入元素
*/
public static long lRightPush(String key, String pivot, String item) {
log.info("lLeftPush(...) => key -> {},pivot -> {},item -> {}", key, pivot, item);
Long size = redisTemplate.opsForList().rightPush(key, pivot, item);
log.info("lLeftPush(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 【非阻塞队列】 从左侧移出(key对应的)list中的第一个元素,并将该元素返回
*
* 注: 此方法是非阻塞的,即: 若(key对应的)list中的所有元素都被pop移出了,此时,再进行pop的话,会立即返回null
* 注: 此方法是非阻塞的,即: 若redis中不存在对应的key,那么会立即返回null
* 注: 若将(key对应的)list中的所有元素都pop完了,那么该key会被删除
*
* @param key 定位list的key
* @return 移出的那个元素
*/
public static String lLeftPop(String key) {
log.info("lLeftPop(...) => key -> {}", key);
String item = redisTemplate.opsForList().leftPop(key);
log.info("lLeftPop(...) => item -> {}", item);
return item;
}
/**
* 【阻塞队列】 从左侧移出(key对应的)list中的第一个元素,并将该元素返回
*
* 注: 此方法是阻塞的,即: 若(key对应的)list中的所有元素都被pop移出了,此时,再进行pop的话,
* 会阻塞timeout这么久,然后返回null
* 注: 此方法是阻塞的,即: 若redis中不存在对应的key,那么会阻塞timeout这么久,然后返回null
* 注: 若将(key对应的)list中的所有元素都pop完了,那么该key会被删除
*
* 提示: 若阻塞过程中,目标key-list出现了,且里面有item了,那么会立马停止阻塞,进行元素移出并返回
*
* @param key 定位list的key
* @param timeout 超时时间
* @param unit timeout的单位
* @return 移出的那个元素
*/
public static String lLeftPop(String key, long timeout, TimeUnit unit) {
log.info("lLeftPop(...) => key -> {},timeout -> {},unit -> {}", key, timeout, unit);
String item = redisTemplate.opsForList().leftPop(key, timeout, unit);
log.info("lLeftPop(...) => item -> {}", item);
return item;
}
/**
* 与{@link ListOps#lLeftPop(String)}类比即可,不过是从list右侧移出元素
*/
public static String lRightPop(String key) {
log.info("lRightPop(...) => key -> {}", key);
String item = redisTemplate.opsForList().rightPop(key);
log.info("lRightPop(...) => item -> {}", item);
return item;
}
/**
* 与{@link ListOps#lLeftPop(String, long, TimeUnit)}类比即可,不过是从list右侧移出元素
*/
public static String lRightPop(String key, long timeout, TimeUnit unit) {
log.info("lRightPop(...) => key -> {},timeout -> {},unit -> {}", key, timeout, unit);
String item = redisTemplate.opsForList().rightPop(key, timeout, unit);
log.info("lRightPop(...) => item -> {}", item);
return item;
}
/**
* 【非阻塞队列】 从sourceKey对应的sourceList右侧移出一个item,并将这个item推
* 入(destinationKey对应的)destinationList的左侧
*
* 注: 若sourceKey对应的list中没有item了,则立马认为(从sourceKey对应的list中pop出来的)item为null,
* null并不会往destinationKey对应的list中push
* 追注: 此时,此方法的返回值是null
*
* 注: 若将(sourceKey对应的)list中的所有元素都pop完了,那么该sourceKey会被删除
*
* @param sourceKey 定位sourceList的key
* @param destinationKey 定位destinationList的key
* @return 移动的这个元素
*/
public static String lRightPopAndLeftPush(String sourceKey, String destinationKey) {
log.info("lRightPopAndLeftPush(...) => sourceKey -> {},destinationKey -> {}",
sourceKey, destinationKey);
String item = redisTemplate.opsForList().rightPopAndLeftPush(sourceKey, destinationKey);
log.info("lRightPopAndLeftPush(...) => item -> {}", item);
return item;
}
/**
* 【阻塞队列】 从sourceKey对应的sourceList右侧移出一个item,并将这个item推
* 入(destinationKey对应的)destinationList的左侧
*
* 注: 若sourceKey对应的list中没有item了,则阻塞等待,直到能从sourceList中移出一个非null的item(或等待时长超时);
* case1: 等到了一个非null的item,那么继续下面的push操作,并返回这个item
* case2: 超时了,还没等到非null的item,那么pop出的结果就未null,此时并不会往destinationList进行push
* 此时,此方法的返回值是null
*
* 注: 若将(sourceKey对应的)list中的所有元素都pop完了,那么该sourceKey会被删除
*
* @param sourceKey 定位sourceList的key
* @param destinationKey 定位destinationList的key
* @param timeout 超时时间
* @param unit timeout的单位
* @return 移动的这个元素
*/
public static String lRightPopAndLeftPush(String sourceKey, String destinationKey, long timeout,
TimeUnit unit) {
log.info("lRightPopAndLeftPush(...) => sourceKey -> {},destinationKey -> {},timeout -> {},"
+ " unit -> {}", sourceKey, destinationKey, timeout, unit);
String item = redisTemplate.opsForList().rightPopAndLeftPush(sourceKey, destinationKey, timeout, unit);
log.info("lRightPopAndLeftPush(...) => item -> {}", item);
return item;
}
/**
* 设置(key对应的)list中对应索引位置index处的元素为item
*
* 注: 若key不存在,则会抛出org.springframework.data.redis.RedisSystemException
* 注: 若索引越界,也会抛出org.springframework.data.redis.RedisSystemException
*
* @param key 定位list的key
* @param index 定位list中的元素的索引
* @param item 要替换成的值
*/
public static void lSet(String key, long index, String item) {
log.info("lSet(...) => key -> {},index -> {},item -> {}", key, index, item);
redisTemplate.opsForList().set(key, index, item);
}
/**
* 通过索引index,获取(key对应的)list中的元素
*
* 注: 若key不存在 或 index超出(key对应的)list的索引范围,那么返回null
*
* @param key 定位list的key
* @param index 定位list中的item的索引
* @return list中索引index对应的item
*/
public static String lIndex(String key, long index) {
log.info("lIndex(...) => key -> {},index -> {}", key, index);
String item = redisTemplate.opsForList().index(key, index);
log.info("lIndex(...) => item -> {}", item);
return item;
}
/**
* 获取(key对应的)list中索引在[start,end]之间的item集
*
* 注: 含start、含end
* 注: 当key不存在时,获取到的是空的集合
* 注: 当获取的范围比list的范围还要大时,获取到的是这两个范围的交集
*
* 提示: 可通过RedisUtil.ListOps.lRange(key,0,-1)来获取到该key对应的整个list
*
* @param key 定位list的key
* @param start 起始元素的index
* @param end 结尾元素的index
* @return 对应的元素集合
*/
public static List lRange(String key, long start, long end) {
log.info("lRange(...) => key -> {},start -> {},end -> {}", key, start, end);
List result = redisTemplate.opsForList().range(key, start, end);
log.info("lRange(...) => result -> {}", result);
return result;
}
/**
* 获取(key对应的)list
*
* @param key 定位list的key
* @return (key对应的)list
* @see ListOps#lRange(String, long, long)
*/
public static List lWholeList(String key) {
log.info("lWholeList(...) => key -> {}", key);
List result = redisTemplate.opsForList().range(key, 0, -1);
log.info("lWholeList(...) => result -> {}", result);
return result;
}
/**
* 获取(key对应的)list的size
*
* 注: 当key不存在时,获取到的size为0.
*
* @param key 定位list的key
* @return list的size
*/
public static long lSize(String key) {
log.info("lSize(...) => key -> {}", key);
Long size = redisTemplate.opsForList().size(key);
log.info("lSize(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 删除(key对应的)list中,前expectCount个值等于item的项
*
* 注: 若expectCount == 0,则表示删除list中所有的值等于item的项.
* 注: 若expectCount > 0, 则表示删除从左往右进行
* 注: 若expectCount < 0, 则表示删除从右往左进行
*
* 注: 若list中,值等于item的项的个数少于expectCount时,那么会删除list中所有的值等于item的项
* 注: 当key不存在时,返回0
* 注: 若lRemove后,将(key对应的)list中没有任何元素了,那么该key会被删除
*
* @param key 定位list的key
* @param expectCount 要删除的item的个数
* @param item 要删除的item
* @return 实际删除了的item的个数
*/
public static long lRemove(String key, long expectCount, String item) {
log.info("lRemove(...) => key -> {},expectCount -> {},item -> {}", key, expectCount, item);
Long actualCount = redisTemplate.opsForList().remove(key, expectCount, item);
log.info("lRemove(...) => actualCount -> {}", actualCount);
if (actualCount == null) {
throw new RedisOpsResultIsNullException();
}
return actualCount;
}
/**
* 裁剪(即: 对list中的元素取交集)
*
* 举例说明: list中的元素索引范围是[0,8],而这个方法传入的[start,end]为 [3,10],
* 那么裁剪就是对[0,8]和[3,10]进行取交集,得到[3,8],那么裁剪后
* 的list中,只剩下(原来裁剪前)索引在[3,8]之间的元素了
*
* 注: 若裁剪后的(key对应的)list就是空的,那么该key会被删除
*
* @param key 定位list的key
* @param start 要删除的item集的起始项的索引
* @param end 要删除的item集的结尾项的索引
*/
public static void lTrim(String key, long start, long end) {
log.info("lTrim(...) => key -> {},start -> {},end -> {}", key, start, end);
redisTemplate.opsForList().trim(key, start, end);
}
}
/**
* set相关操作
*
* 提示: set中的元素,不可以重复
* 提示: set是无序的
* 提示: redis中String的数据结构可参考resources/data-structure/Set(集合)的数据结构(示例一).png
* redis中String的数据结构可参考resources/data-structure/Set(集合)的数据结构(示例二).png
*/
public static class SetOps {
/**
* 向(key对应的)set中添加items
*
* 注: 若key不存在,则会自动创建
* 注: set中的元素会去重
*
* @param key 定位set的key
* @param items 要向(key对应的)set中添加的items
* @return 此次添加操作, 添加到set中的元素的个数
*/
public static long sAdd(String key, String... items) {
log.info("sAdd(...) => key -> {},items -> {}", key, items);
Long count = redisTemplate.opsForSet().add(key, items);
log.info("sAdd(...) => count -> {}", count);
if (count == null) {
throw new RedisOpsResultIsNullException();
}
return count;
}
/**
* 从(key对应的)set中删除items
*
* 注: 若key不存在,则返回0
* 注: 若已经将(key对应的)set中的项删除完了,那么对应的key也会被删除
*
* @param key 定位set的key
* @param items 要移除的items
* @return 实际删除了的个数
*/
public static long sRemove(String key, Object... items) {
log.info("sRemove(...) => key -> {},items -> {}", key, items);
Long count = redisTemplate.opsForSet().remove(key, items);
log.info("sRemove(...) => count -> {}", count);
if (count == null) {
throw new RedisOpsResultIsNullException();
}
return count;
}
/**
* 从(key对应的)set中随机移出一个item,并返回这个item
*
* 注: 因为set是无序的,所以移出的这个item,是随机的; 并且,哪怕
* 是数据一样的set,多次测试移出操作,移除的元素也是随机的
*
* 注: 若已经将(key对应的)set中的项pop完了,那么对应的key会被删除
*
* @param key 定位set的key
* @return 移出的项
*/
public static String sPop(String key) {
log.info("sPop(...) => key -> {}", key);
String popItem = redisTemplate.opsForSet().pop(key);
log.info("sPop(...) => popItem -> {}", popItem);
return popItem;
}
/**
* 将(sourceKey对应的)sourceSet中的元素item,移动到(destinationKey对应的)destinationSet中
*
* 注: 当sourceKey不存在时,返回false
* 注: 当item不存在时,返回false
* 注: 若destinationKey不存在,那么在移动时会自动创建
* 注: 若已经将(sourceKey对应的)set中的项move出去完了,那么对应的sourceKey会被删除
*
* @param sourceKey 定位sourceSet的key
* @param item 要移动的项目
* @param destinationKey 定位destinationSet的key
* @return 移动成功与否
*/
public static boolean sMove(String sourceKey, String item, String destinationKey) {
Boolean result = redisTemplate.opsForSet().move(sourceKey, item, destinationKey);
log.info("sMove(...) => sourceKey -> {},destinationKey -> {},item -> {}",
sourceKey, destinationKey, item);
log.info("sMove(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 获取(key对应的)set中的元素个数
*
* 注: 若key不存在,则返回0
*
* @param key 定位set的key
* @return (key对应的)set中的元素个数
*/
public static long sSize(String key) {
log.info("sSize(...) => key -> {}", key);
Long size = redisTemplate.opsForSet().size(key);
log.info("sSize(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 判断(key对应的)set中是否含有item
*
* 注: 若key不存在,则返回false
*
* @param key 定位set的key
* @param item 被查找的项
* @return (key对应的)set中是否含有item
*/
public static boolean sIsMember(String key, Object item) {
log.info("sSize(...) => key -> {},size -> {}", key, item);
Boolean result = redisTemplate.opsForSet().isMember(key, item);
log.info("sSize(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 获取两个(key对应的)Set的交集
*
* 注: 若不存在任何交集,那么返回空的集合(,而不是null)
* 注: 若其中一个key不存在(或两个key都不存在),那么返回空的集合(,而不是null)
*
* @param key 定位其中一个set的键
* @param otherKey 定位其中另一个set的键
* @return item交集
*/
public static Set sIntersect(String key, String otherKey) {
log.info("sIntersect(...) => key -> {},otherKey -> {}", key, otherKey);
Set intersectResult = redisTemplate.opsForSet().intersect(key, otherKey);
log.info("sIntersect(...) => intersectResult -> {}", intersectResult);
return intersectResult;
}
/**
* 获取多个(key对应的)Set的交集
*
* 注: 若不存在任何交集,那么返回空的集合(,而不是null)
* 注: 若>=1个key不存在,那么返回空的集合(,而不是null)
*
* @param key 定位其中一个set的键
* @param otherKeys 定位其它set的键集
* @return item交集
*/
public static Set sIntersect(String key, Collection otherKeys) {
log.info("sIntersect(...) => key -> {},otherKeys -> {}", key, otherKeys);
Set intersectResult = redisTemplate.opsForSet().intersect(key, otherKeys);
log.info("sIntersect(...) => intersectResult -> {}", intersectResult);
return intersectResult;
}
/**
* 获取两个(key对应的)Set的交集,并将结果add到storeKey对应的Set中
*
* case1: 交集不为空,storeKey不存在,则 会创建对应的storeKey,并将交集添加到(storeKey对应的)set中
* case2: 交集不为空,storeKey已存在,则 会清除原(storeKey对应的)set中所有的项,然后将交集添加到(storeKey对应的)set中
* case3: 交集为空,则不进行下面的操作,直接返回0
*
* 注: 求交集的部分,详见{@link SetOps#sIntersect(String, String)}
*
* @param key 定位其中一个set的键
* @param otherKey 定位其中另一个set的键
* @param storeKey 定位(要把交集添加到哪个)set的key
* @return add到(storeKey对应的)Set后, 该set对应的size
*/
public static long sIntersectAndStore(String key, String otherKey, String storeKey) {
log.info("sIntersectAndStore(...) => key -> {},otherKey -> {},storeKey -> {}",
key, otherKey, storeKey);
Long size = redisTemplate.opsForSet().intersectAndStore(key, otherKey, storeKey);
log.info("sIntersectAndStore(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 获取多个(key对应的)Set的交集,并将结果add到storeKey对应的Set中
*
* case1: 交集不为空,storeKey不存在,则 会创建对应的storeKey,并将交集添加到(storeKey对应的)set中
* case2: 交集不为空,storeKey已存在,则 会清除原(storeKey对应的)set中所有的项,然后将交集添加到(storeKey对应的)set中
* case3: 交集为空,则不进行下面的操作,直接返回0
*
* 注: 求交集的部分,详见{@link SetOps#sIntersect(String, Collection)}
*/
public static long sIntersectAndStore(String key, Collection otherKeys, String storeKey) {
log.info("sIntersectAndStore(...) => key -> {},otherKeys -> {},storeKey -> {}", key, otherKeys, storeKey);
Long size = redisTemplate.opsForSet().intersectAndStore(key, otherKeys, storeKey);
log.info("sIntersectAndStore(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 获取两个(key对应的)Set的并集
*
* 注: 并集中的元素也是唯一的,这是Set保证的
*
* @param key 定位其中一个set的键
* @param otherKey 定位其中另一个set的键
* @return item并集
*/
public static Set sUnion(String key, String otherKey) {
log.info("sUnion(...) => key -> {},otherKey -> {}", key, otherKey);
Set unionResult = redisTemplate.opsForSet().union(key, otherKey);
log.info("sUnion(...) => unionResult -> {}", unionResult);
return unionResult;
}
/**
* 获取两个(key对应的)Set的并集
*
* 注: 并集中的元素也是唯一的,这是Set保证的
*
* @param key 定位其中一个set的键
* @param otherKeys 定位其它set的键集
* @return item并集
*/
public static Set sUnion(String key, Collection otherKeys) {
log.info("sUnion(...) => key -> {},otherKeys -> {}", key, otherKeys);
Set unionResult = redisTemplate.opsForSet().union(key, otherKeys);
log.info("sUnion(...) => unionResult -> {}", unionResult);
return unionResult;
}
/**
* 获取两个(key对应的)Set的并集,并将结果add到storeKey对应的Set中
*
* case1: 并集不为空,storeKey不存在,则 会创建对应的storeKey,并将并集添加到(storeKey对应的)set中
* case2: 并集不为空,storeKey已存在,则 会清除原(storeKey对应的)set中所有的项,然后将并集添加到(storeKey对应的)set中
* case3: 并集为空,则不进行下面的操作,直接返回0
*
* 注: 求并集的部分,详见{@link SetOps#sUnion(String, String)}
*
* @param key 定位其中一个set的键
* @param otherKey 定位其中另一个set的键
* @param storeKey 定位(要把并集添加到哪个)set的key
* @return add到(storeKey对应的)Set后, 该set对应的size
*/
public static long sUnionAndStore(String key, String otherKey, String storeKey) {
log.info("sUnionAndStore(...) => key -> {},otherKey -> {},storeKey -> {}",
key, otherKey, storeKey);
Long size = redisTemplate.opsForSet().unionAndStore(key, otherKey, storeKey);
log.info("sUnionAndStore(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 获取两个(key对应的)Set的并集,并将结果add到storeKey对应的Set中
*
* case1: 并集不为空,storeKey不存在,则 会创建对应的storeKey,并将并集添加到(storeKey对应的)set中
* case2: 并集不为空,storeKey已存在,则 会清除原(storeKey对应的)set中所有的项,然后将并集添加到(storeKey对应的)set中
* case3: 并集为空,则不进行下面的操作,直接返回0
*
* 注: 求并集的部分,详见{@link SetOps#sUnion(String, Collection)}
*
* @param key 定位其中一个set的键
* @param otherKeys 定位其它set的键集
* @param storeKey 定位(要把并集添加到哪个)set的key
* @return add到(storeKey对应的)Set后, 该set对应的size
*/
public static long sUnionAndStore(String key, Collection otherKeys, String storeKey) {
log.info("sUnionAndStore(...) => key -> {},otherKeys -> {},storeKey -> {}",
key, otherKeys, storeKey);
Long size = redisTemplate.opsForSet().unionAndStore(key, otherKeys, storeKey);
log.info("sUnionAndStore(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 获取 (key对应的)Set 减去 (otherKey对应的)Set 的差集
*
* 注: 如果被减数key不存在,那么结果为空的集合(,而不是null)
* 注: 如果被减数key存在,但减数key不存在,那么结果即为(被减数key对应的)Set
*
* @param key 定位"被减数set"的键
* @param otherKey 定位"减数set"的键
* @return item差集
*/
public static Set sDifference(String key, String otherKey) {
log.info("sDifference(...) => key -> {},otherKey -> {}",
key, otherKey);
Set differenceResult = redisTemplate.opsForSet().difference(key, otherKey);
log.info("sDifference(...) => differenceResult -> {}", differenceResult);
return differenceResult;
}
/**
* 获取 (key对应的)Set 减去 (otherKeys对应的)Sets 的差集
*
* 注: 如果被减数key不存在,那么结果为空的集合(,而不是null)
* 注: 如果被减数key存在,但减数key不存在,那么结果即为(被减数key对应的)Set
*
* 提示: 当有多个减数时,被减数先减去哪一个减数,后减去哪一个减数,是无所谓的,是不影响最终结果的
*
* @param key 定位"被减数set"的键
* @param otherKeys 定位"减数集sets"的键集
* @return item差集
*/
public static Set sDifference(String key, Collection otherKeys) {
log.info("sDifference(...) => key -> {},otherKeys -> {}", key, otherKeys);
Set differenceResult = redisTemplate.opsForSet().difference(key, otherKeys);
log.info("sDifference(...) => differenceResult -> {}", differenceResult);
return differenceResult;
}
/**
* 获取 (key对应的)Set 减去 (otherKey对应的)Set 的差集,并将结果add到storeKey对应的Set中
*
* case1: 差集不为空,storeKey不存在,则 会创建对应的storeKey,并将差集添加到(storeKey对应的)set中
* case2: 差集不为空,storeKey已存在,则 会清除原(storeKey对应的)set中所有的项,然后将差集添加到(storeKey对应的)set中
* case3: 差集为空,则不进行下面的操作,直接返回0
*
* 注: 求并集的部分,详见{@link SetOps#sDifference(String, String)}
*
* @param key 定位"被减数set"的键
* @param otherKey 定位"减数set"的键
* @param storeKey 定位(要把差集添加到哪个)set的key
* @return add到(storeKey对应的)Set后, 该set对应的size
*/
public static long sDifferenceAndStore(String key, String otherKey, String storeKey) {
log.info("sDifferenceAndStore(...) => key -> {},otherKey -> {},storeKey -> {}",
key, otherKey, storeKey);
Long size = redisTemplate.opsForSet().differenceAndStore(key, otherKey, storeKey);
log.info("sDifferenceAndStore(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 获取 (key对应的)Set 减去 (otherKey对应的)Set 的差集,并将结果add到storeKey对应的Set中
*
* case1: 差集不为空,storeKey不存在,则 会创建对应的storeKey,并将差集添加到(storeKey对应的)set中
* case2: 差集不为空,storeKey已存在,则 会清除原(storeKey对应的)set中所有的项,然后将差集添加到(storeKey对应的)set中
* case3: 差集为空,则不进行下面的操作,直接返回0
*
* 注: 求并集的部分,详见{@link SetOps#sDifference(String, String)}
*
* @param key 定位"被减数set"的键
* @param otherKeys 定位"减数集sets"的键集
* @param storeKey 定位(要把差集添加到哪个)set的key
* @return add到(storeKey对应的)Set后, 该set对应的size
*/
public static long sDifferenceAndStore(String key, Collection otherKeys, String storeKey) {
log.info("sDifferenceAndStore(...) => key -> {},otherKeys -> {},storeKey -> {}",
key, otherKeys, storeKey);
Long size = redisTemplate.opsForSet().differenceAndStore(key, otherKeys, storeKey);
log.info("sDifferenceAndStore(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 获取key对应的set
*
* 注: 若key不存在,则返回的是空的set(,而不是null)
*
* @param key 定位set的key
* @return (key对应的)set
*/
public static Set sMembers(String key) {
log.info("sMembers(...) => key -> {}", key);
Set members = redisTemplate.opsForSet().members(key);
log.info("sMembers(...) => members -> {}", members);
return members;
}
/**
* 从key对应的set中随机获取一项
*
* @param key 定位set的key
* @return 随机获取到的项
*/
public static String sRandomMember(String key) {
log.info("sRandomMember(...) => key -> {}", key);
String randomItem = redisTemplate.opsForSet().randomMember(key);
log.info("sRandomMember(...) => randomItem -> {}", randomItem);
return randomItem;
}
/**
* 从key对应的set中获取count次随机项(,set中的同一个项可能被多次获取)
*
* 注: count可大于set的size
* 注: 取出来的结果里可能存在相同的值
*
* @param key 定位set的key
* @param count 要取多少项
* @return 随机获取到的项集
*/
public static List sRandomMembers(String key, long count) {
log.info("sRandomMembers(...) => key -> {},count -> {}", key, count);
List randomItems = redisTemplate.opsForSet().randomMembers(key, count);
log.info("sRandomMembers(...) => randomItems -> {}", randomItems);
return randomItems;
}
/**
* 从key对应的set中随机获取count个项
*
* 注: 若count >= set的size,那么返回的即为这个key对应的set
* 注: 取出来的结果里没有重复的项
*
* @param key 定位set的key
* @param count 要取多少项
* @return 随机获取到的项集
*/
public static Set sDistinctRandomMembers(String key, long count) {
log.info("sDistinctRandomMembers(...) => key -> {},count -> {}", key, count);
Set distinctRandomItems = redisTemplate.opsForSet().distinctRandomMembers(key, count);
log.info("sDistinctRandomMembers(...) => distinctRandomItems -> {}", distinctRandomItems);
return distinctRandomItems;
}
/**
* 根据options匹配到(key对应的)set中的对应的item,并返回对应的item集
*
*
* 注: ScanOptions实例的创建方式举例:
* 1、ScanOptions.NONE
* 2、ScanOptions.scanOptions().match("n??e").build()
*
* @param key 定位set的key
* @param options 匹配set中的item的条件
* 注: ScanOptions.NONE表示全部匹配
* 注: ScanOptions.scanOptions().match(pattern).build()表示按照pattern匹配,
* 其中pattern中可以使用通配符 * ? 等,
* * 表示>=0个字符
* ? 表示有且只有一个字符
* 此处的匹配规则与{@link KeyOps#keys(String)}处的一样
* @return 匹配到的(key对应的)set中的项
*/
@SneakyThrows
public static Cursor sScan(String key, ScanOptions options) {
log.info("sScan(...) => key -> {},options -> {}", key, mapper.writeValueAsString(options));
Cursor cursor = redisTemplate.opsForSet().scan(key, options);
log.info("sScan(...) => cursor -> {}", mapper.writeValueAsString(cursor));
return cursor;
}
}
/**
* ZSet相关操作
*
* 特别说明: ZSet是有序的,
* 不仅体现在: redis中的存储上有序
* 还体现在: 此工具类ZSetOps中返回值类型为Set的方法,实际返回类型是LinkedHashSet
*
* 提示: redis中的ZSet,一定程度等于redis中的Set + redis中的Hash的结合体
* 提示: redis中String的数据结构可参考resources/data-structure/ZSet(有序集合)的数据结构(示例一).png
* redis中String的数据结构可参考resources/data-structure/ZSet(有序集合)的数据结构(示例二).png
* 提示: ZSet中的entryKey即为成员项,entryValue即为这个成员项的分值,ZSet根据成员的分值,来堆成员进行排序
*/
public static class ZSetOps {
/**
* 向(key对应的)zset中添加(item,score)
*
* 注: item为entryKey成员项,score为entryValue分数值
*
* 注: 若(key对应的)zset中已存在(与此次要添加的项)相同的item项,那么此次添加操作会失败,返回false;
* 但是!!! zset中原item的score会被更新为此次add的相同item项的score
* 所以,也可以通过zAdd达到更新item对应score的目的
*
* 注: score可为正、可为负、可为0; 总之,double范围内都可以
*
* 注: 若score的值一样,则按照item排序
*
* @param key 定位set的key
* @param item 要往(key对应的)zset中添加的成员项
* @param score item的分值
* @return 是否添加成功
*/
public static boolean zAdd(String key, String item, double score) {
log.info("zAdd(...) => key -> {},item -> {},score -> {}", key, item, score);
Boolean result = redisTemplate.opsForZSet().add(key, item, score);
log.info("zAdd(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 批量添加entry
*
* 注: 若entry集中存在item相同的项(,score不一样),那么redis在执行真正的批量add操作前,会
* 将其中一个item过滤掉
* 注: 同样的,若(key对应的)zset中已存在(与此次要添加的项)相同的item项,那么此次批量添加操作中,
* 对该item项的添加会失败,会失败,成功计数器不会加1;但是!!! zset中原item的score会被更新为此
* 次add的相同item项的score所以,也可以通过zAdd达到更新item对应score的目的
*
* @param key 定位set的key
* @param entries 要添加的entry集
* @return 本次添加进(key对应的)zset中的entry的个数
*/
@SneakyThrows
public static long zAdd(String key, Set> entries) {
log.info("zAdd(...) => key -> {},entries -> {}", key, mapper.writeValueAsString(entries));
Long count = redisTemplate.opsForZSet().add(key, entries);
log.info("zAdd(...) => count -> {}", count);
if (count == null) {
throw new RedisOpsResultIsNullException();
}
return count;
}
/**
* 从(key对应的)zset中移除项
*
* 注:若key不存在,则返回0
*
* @param key 定位set的key
* @param items 要移除的项集
* @return 实际移除了的项的个数
*/
public static long zRemove(String key, Object... items) {
log.info("zRemove(...) => key -> {},items -> {}", key, items);
Long count = redisTemplate.opsForZSet().remove(key, items);
log.info("zRemove(...) => count -> {}", count);
if (count == null) {
throw new RedisOpsResultIsNullException();
}
return count;
}
/**
* 移除(key对应的)zset中,排名范围在[startIndex,endIndex]内的item
*
* 注:默认的,按score.item升序排名,排名从0开始
*
* 注: 类似于List中的索引,排名可以分为多个方式:
* 从前到后(正向)的排名: 0、1、2...
* 从后到前(反向)的排名: -1、-2、-3...
*
* 注: 不论是使用正向排名,还是使用反向排名,使用此方法时,应保证 startRange代表的元素的位置
* 在endRange代表的元素的位置的前面,如:
* 示例一: RedisUtil.ZSetOps.zRemoveRange("name",0,2);
* 示例二: RedisUtil.ZSetOps.zRemoveRange("site",-2,-1);
* 示例三: RedisUtil.ZSetOps.zRemoveRange("foo",0,-1);
*
* 注:若key不存在,则返回0
*
* @param key 定位set的key
* @param startRange 开始项的排名
* @param endRange 结尾项的排名
* @return 实际移除了的项的个数
*/
public static long zRemoveRange(String key, long startRange, long endRange) {
log.info("zRemoveRange(...) => key -> {},startRange -> {},endRange -> {}",
key, startRange, endRange);
Long count = redisTemplate.opsForZSet().removeRange(key, startRange, endRange);
log.info("zRemoveRange(...) => count -> {}", count);
if (count == null) {
throw new RedisOpsResultIsNullException();
}
return count;
}
/**
* 移除(key对应的)zset中,score范围在[minScore,maxScore]内的item
*
* 提示: 虽然删除范围包含两侧的端点(即:包含minScore和maxScore),但是由于double存在精度问题,所以建议:
* 设置值时,minScore应该设置得比要删除的项里,最小的score还小一点
* maxScore应该设置得比要删除的项里,最大的score还大一点
* 追注: 本人简单测试了几组数据,暂未出现精度问题
*
* 注:若key不存在,则返回0
*
* @param key 定位set的key
* @param minScore score下限(含这个值)
* @param maxScore score上限(含这个值)
* @return 实际移除了的项的个数
*/
public static long zRemoveRangeByScore(String key, double minScore, double maxScore) {
log.info("zRemoveRangeByScore(...) => key -> {},startIndex -> {},startIndex -> {}",
key, minScore, maxScore);
Long count = redisTemplate.opsForZSet().removeRangeByScore(key, minScore, maxScore);
log.info("zRemoveRangeByScore(...) => count -> {}", count);
if (count == null) {
throw new RedisOpsResultIsNullException();
}
return count;
}
/**
* 增/减 (key对应的zset中,)item的分数值
*
* @param key 定位zset的key
* @param item 项
* @param delta 变化量(正 - 增,负 - 减)
* @return 修改后的score值
*/
public static double zIncrementScore(String key, String item, double delta) {
log.info("zIncrementScore(...) => key -> {},item -> {},delta -> {}", key, item, delta);
Double scoreValue = redisTemplate.opsForZSet().incrementScore(key, item, delta);
log.info("zIncrementScore(...) => scoreValue -> {}", scoreValue);
if (scoreValue == null) {
throw new RedisOpsResultIsNullException();
}
return scoreValue;
}
/**
* 返回item在(key对应的)zset中的(按score从小到大的)排名
*
* 注: 排名从0开始 即意味着,此方法等价于: 返回item在(key对应的)zset中的位置索引
* 注: 若key或item不存在,返回null
* 注: 排序规则是score,item,即:优先以score排序,若score相同,则再按item排序
*
* @param key 定位zset的key
* @param item 项
* @return 排名(等价于 : 索引)
*/
public static long zRank(String key, Object item) {
log.info("zRank(...) => key -> {},item -> {}", key, item);
Long rank = redisTemplate.opsForZSet().rank(key, item);
log.info("zRank(...) => rank -> {}", rank);
if (rank == null) {
throw new RedisOpsResultIsNullException();
}
return rank;
}
/**
* 返回item在(key对应的)zset中的(按score从大到小的)排名
*
* 注: 排名从0开始补充: 因为是按score从大到小排序的,所以最大score对应的item的排名为0
* 注: 若key或item不存在,返回null
* 注: 排序规则是score,item,即:优先以score排序,若score相同,则再按item排序
*
* @param key 定位zset的key
* @param item 项
* @return 排名(等价于 : 索引)
*/
public static long zReverseRank(String key, Object item) {
log.info("zReverseRank(...) => key -> {},item -> {}", key, item);
Long reverseRank = redisTemplate.opsForZSet().reverseRank(key, item);
log.info("zReverseRank(...) => reverseRank -> {}", reverseRank);
if (reverseRank == null) {
throw new RedisOpsResultIsNullException();
}
return reverseRank;
}
/**
* 根据索引位置,获取(key对应的)zset中排名处于[start,end]中的item项集
*
* 注: 不论是使用正向排名,还是使用反向排名,使用此方法时,应保证 startIndex代表的元素的
* 位置在endIndex代表的元素的位置的前面,如:
* 示例一: RedisUtil.ZSetOps.zRange("name",0,2);
* 示例二: RedisUtil.ZSetOps.zRange("site",-2,-1);
* 示例三: RedisUtil.ZSetOps.zRange("foo",0,-1);
*
* 注: 若key不存在,则返回空的集合
*
* 注: 当[start,end]的范围比实际zset的范围大时,返回范围上"交集"对应的项集合
*
* @param key 定位zset的key
* @param start 排名开始位置
* @param end 排名结束位置
* @return 对应的item项集
*/
public static Set zRange(String key, long start, long end) {
log.info("zRange(...) => key -> {},start -> {},end -> {}", key, start, end);
Set result = redisTemplate.opsForZSet().range(key, start, end);
log.info("zRange(...) => result -> {}", result);
return result;
}
/**
* 获取(key对应的)zset中的所有item项
*
* @param key 定位zset的键
* @return (key对应的)zset中的所有item项
* @see ZSetOps#zRange(String, long, long)
*/
public static Set zWholeZSetItem(String key) {
log.info("zWholeZSetItem(...) => key -> {}", key);
Set result = redisTemplate.opsForZSet().range(key, 0, -1);
log.info("zWholeZSetItem(...) =>result -> {}", result);
return result;
}
/**
* 根据索引位置,获取(key对应的)zset中排名处于[start,end]中的entry集
*
* 注: 不论是使用正向排名,还是使用反向排名,使用此方法时,应保证 startIndex代表的元素的
* 位置在endIndex代表的元素的位置的前面,如:
* 示例一: RedisUtil.ZSetOps.zRange("name",0,2);
* 示例二: RedisUtil.ZSetOps.zRange("site",-2,-1);
* 示例三: RedisUtil.ZSetOps.zRange("foo",0,-1);
*
* 注: 若key不存在,则返回空的集合
*
* 注: 当[start,end]的范围比实际zset的范围大时,返回范围上"交集"对应的项集合
*
* 注: 此方法和{@link ZSetOps#zRange(String, long, long)}类似,不过此方法返回的不是item集,而是entry集
*
* @param key 定位zset的key
* @param start 排名开始位置
* @param end 排名结束位置
* @return 对应的entry集
*/
@SneakyThrows
public static Set> zRangeWithScores(String key, long start, long end) {
log.info("zRangeWithScores(...) => key -> {},start -> {},end -> {}", key, start, end);
Set> entries = redisTemplate.opsForZSet().rangeWithScores(key, start, end);
log.info("zRangeWithScores(...) => entries -> {}", mapper.writeValueAsString(entries));
return entries;
}
/**
* 获取(key对应的)zset中的所有entry
*
* @param key 定位zset的键
* @return (key对应的)zset中的所有entry
* @see ZSetOps#zRangeWithScores(String, long, long)
*/
@SneakyThrows
public static Set> zWholeZSetEntry(String key) {
log.info("zWholeZSetEntry(...) => key -> {}", key);
Set> entries = redisTemplate.opsForZSet().rangeWithScores(key, 0, -1);
log.info("zWholeZSetEntry(...) => entries -> {}", key, mapper.writeValueAsString(entries));
return entries;
}
/**
* 根据score,获取(key对应的)zset中分数值处于[minScore,maxScore]中的item项集
*
* 注: 若key不存在,则返回空的集合
* 注: 当[minScore,maxScore]的范围比实际zset中score的范围大时,返回范围上"交集"对应的项集合
*
* 提示: 虽然删除范围包含两侧的端点(即:包含minScore和maxScore),但是由于double存在精度问题,所以建议:
* 设置值时,minScore应该设置得比要删除的项里,最小的score还小一点
* maxScore应该设置得比要删除的项里,最大的score还大一点
* 追注: 本人简单测试了几组数据,暂未出现精度问题
*
* @param key 定位zset的key
* @param minScore score下限
* @param maxScore score上限
* @return 对应的item项集
*/
public static Set zRangeByScore(String key, double minScore, double maxScore) {
log.info("zRangeByScore(...) => key -> {},minScore -> {},maxScore -> {}", key, minScore, maxScore);
Set items = redisTemplate.opsForZSet().rangeByScore(key, minScore, maxScore);
log.info("zRangeByScore(...) => items -> {}", items);
return items;
}
/**
* 根据score,获取(key对应的)zset中分数值处于[minScore,maxScore]中的,score处于[minScore,
* 排名大于等于offset的count个item项
*
* 特别注意: 对于不是特别熟悉redis的人来说,offset 和 count最好都使用正数,避免引起理解上的歧义
*
* 注: 若key不存在,则返回空的集合
*
* 提示: 虽然删除范围包含两侧的端点(即:包含minScore和maxScore),但是由于double存在精度问题,所以建议:
* 设置值时,minScore应该设置得比要删除的项里,最小的score还小一点
* maxScore应该设置得比要删除的项里,最大的score还大一点
* 追注: 本人简单测试了几组数据,暂未出现精度问题
*
* @param key 定位zset的key
* @param minScore score下限
* @param maxScore score上限
* @param offset 偏移量(即:排名下限)
* @param count 期望获取到的元素个数
* @return 对应的item项集
*/
public static Set zRangeByScore(String key, double minScore, double maxScore,
long offset, long count) {
log.info("zRangeByScore(...) => key -> {},minScore -> {},maxScore -> {},offset -> {},"
+ "count -> {}", key, minScore, maxScore, offset, count);
Set items = redisTemplate.opsForZSet().rangeByScore(key, minScore, maxScore, offset, count);
log.info("zRangeByScore(...) => items -> {}", items);
return items;
}
/**
* 获取(key对应的)zset中的所有score处于[minScore,maxScore]中的entry
*
* @param key 定位zset的键
* @param minScore score下限
* @param maxScore score上限
* @return (key对应的)zset中的所有score处于[minScore, maxScore]中的entry
* @see ZSetOps#zRangeByScore(String, double, double)
*
* 注: 若key不存在,则返回空的集合
* 注: 当[minScore,maxScore]的范围比实际zset中score的范围大时,返回范围上"交集"对应的项集合
*/
@SneakyThrows
public static Set> zRangeByScoreWithScores(String key, double minScore, double maxScore) {
log.info("zRangeByScoreWithScores(...) => key -> {},minScore -> {},maxScore -> {}",
key, minScore, maxScore);
Set> entries = redisTemplate.opsForZSet().rangeByScoreWithScores(key, minScore, maxScore);
log.info("zRangeByScoreWithScores(...) => entries -> {}", mapper.writeValueAsString(entries));
return entries;
}
/**
* 获取(key对应的)zset中,score处于[minScore,maxScore]里的、排名大于等于offset的count个entry
*
* 特别注意: 对于不是特别熟悉redis的人来说,offset 和 count最好都使用正数,避免引起理解上的歧义
*
* @param key 定位zset的键
* @param minScore score下限
* @param maxScore score上限
* @param offset 偏移量(即:排名下限)
* @param count 期望获取到的元素个数
* @return [startIndex, endIndex] & [minScore,maxScore]里的entry
*/
@SneakyThrows
public static Set> zRangeByScoreWithScores(String key, double minScore,
double maxScore, long offset,
long count) {
log.info("zRangeByScoreWithScores(...) => key -> {},minScore -> {},maxScore -> {},"
+ " offset -> {},count -> {}",
key, minScore, maxScore, offset, count);
Set> entries = redisTemplate.opsForZSet().rangeByScoreWithScores(key, minScore,
maxScore, offset, count);
log.info("zRangeByScoreWithScores(...) => entries -> {}", mapper.writeValueAsString(entries));
return entries;
}
/**
* 获取时,先按score倒序,然后根据索引位置,获取(key对应的)zset中排名处于[start,end]中的item项集
*
* @see ZSetOps#zRange(String, long, long) 只是zReverseRange这里会提前多一个倒序
*/
public static Set zReverseRange(String key, long start, long end) {
log.info("zReverseRange(...) => key -> {},start -> {},end -> {}", key, start, end);
Set entries = redisTemplate.opsForZSet().reverseRange(key, start, end);
log.info("zReverseRange(...) => entries -> {}", entries);
return entries;
}
/**
* 获取时,先按score倒序,然后根据索引位置,获取(key对应的)zset中排名处于[start,end]中的entry集
*
* @see ZSetOps#zRangeWithScores(String, long, long) 只是zReverseRangeWithScores这里会提前多一个倒序
*/
@SneakyThrows
public static Set> zReverseRangeWithScores(String key, long start, long end) {
log.info("zReverseRangeWithScores(...) => key -> {},start -> {},end -> {}", key, start, end);
Set> entries = redisTemplate.opsForZSet().reverseRangeWithScores(key, start, end);
log.info("zReverseRangeWithScores(...) => entries -> {}", mapper.writeValueAsString(entries));
return entries;
}
/**
* 获取时,先按score倒序,然后根据score,获取(key对应的)zset中分数值处于[minScore,maxScore]中的item项集
*
* @see ZSetOps#zRangeByScore(String, double, double) 只是zReverseRangeByScore这里会提前多一个倒序
*/
public static Set zReverseRangeByScore(String key, double minScore, double maxScore) {
log.info("zReverseRangeByScore(...) => key -> {},minScore -> {},maxScore -> {}",
key, minScore, maxScore);
Set items = redisTemplate.opsForZSet().reverseRangeByScore(key, minScore, maxScore);
log.info("zReverseRangeByScore(...) => items -> {}", items);
return items;
}
/**
* 获取时,先按score倒序,然后获取(key对应的)zset中的所有score处于[minScore,maxScore]中的entry
*
* @see ZSetOps#zRangeByScoreWithScores(String, double, double) 只是zReverseRangeByScoreWithScores这里会提前多一个倒序
*/
@SneakyThrows
public static Set> zReverseRangeByScoreWithScores(String key, double minScore, double maxScore) {
log.info("zReverseRangeByScoreWithScores(...) => key -> {},minScore -> {},maxScore -> {}",
key, minScore, maxScore);
Set> entries = redisTemplate.opsForZSet().reverseRangeByScoreWithScores(key,
minScore, maxScore);
log.info("zReverseRangeByScoreWithScores(...) => entries -> {}", mapper.writeValueAsString(entries));
return entries;
}
/**
* 获取时,先按score倒序,然后根据score,获取(key对应的)zset中分数值处于[minScore,maxScore]中的,
* score处于[minScore,排名大于等于offset的count个item项
*
* @see ZSetOps#zRangeByScore(String, double, double, long, long) 只是zReverseRangeByScore这里会提前多一个倒序
*/
public static Set zReverseRangeByScore(String key, double minScore, double maxScore, long offset, long count) {
log.info("zReverseRangeByScore(...) => key -> {},minScore -> {},maxScore -> {},offset -> {},"
+ "count -> {}", key, minScore, maxScore, offset, count);
Set items = redisTemplate.opsForZSet().reverseRangeByScore(key, minScore, maxScore, offset, count);
log.info("items -> {}", items);
return items;
}
/**
* 统计(key对应的zset中)score处于[minScore,maxScore]中的item的个数
*
* @param key 定位zset的key
* @param minScore score下限
* @param maxScore score上限
* @return [minScore, maxScore]中item的个数
*/
public static long zCount(String key, double minScore, double maxScore) {
log.info("zCount(...) => key -> {},minScore -> {},maxScore -> {}", key, minScore, maxScore);
Long count = redisTemplate.opsForZSet().count(key, minScore, maxScore);
log.info("zCount(...) => count -> {}", count);
if (count == null) {
throw new RedisOpsResultIsNullException();
}
return count;
}
/**
* 统计(key对应的)zset中item的个数
*
* 注: 此方法等价于{@link ZSetOps#zZCard(String)}
*
* @param key 定位zset的key
* @return zset中item的个数
*/
public static long zSize(String key) {
log.info("zSize(...) => key -> {}", key);
Long size = redisTemplate.opsForZSet().size(key);
log.info("zSize(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 统计(key对应的)zset中item的个数
*
* 注: 此方法等价于{@link ZSetOps#zSize(String)}
*
* @param key 定位zset的key
* @return zset中item的个数
*/
public static long zZCard(String key) {
log.info("zZCard(...) => key -> {}", key);
Long size = redisTemplate.opsForZSet().zCard(key);
log.info("zZCard(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 统计(key对应的)zset中指定item的score
*
* @param key 定位zset的key
* @param item zset中的item
* @return item的score
*/
public static double zScore(String key, Object item) {
log.info("zScore(...) => key -> {},item -> {}", key, item);
Double score = redisTemplate.opsForZSet().score(key, item);
log.info("zScore(...) => score -> {}", score);
if (score == null) {
throw new RedisOpsResultIsNullException();
}
return score;
}
/**
* 获取两个(key对应的)ZSet的并集,并将结果add到storeKey对应的ZSet中
*
* 注: 和set一样,zset中item是唯一的,在多个zset进行Union时,处理相同的item时,score的值会变为对应的score之和,如:
* RedisUtil.ZSetOps.zAdd("name1","a",1);和RedisUtil.ZSetOps.zAdd("name2","a",2);
* 对(name1和name2对应的)zset进行zUnionAndStore之后,新的zset中的项a,对应的score值为3
*
* case1: 交集不为空,storeKey不存在,则 会创建对应的storeKey,并将并集添加到(storeKey对应的)ZSet中
* case2: 交集不为空,storeKey已存在,则 会清除原(storeKey对应的)ZSet中所有的项,然后将并集添加到(storeKey对应的)ZSet中
* case3: 交集为空,则不进行下面的操作,直接返回0
*
* @param key 定位其中一个zset的键
* @param otherKey 定位另外的zset的键
* @param storeKey 定位(要把交集添加到哪个)set的key
* @return add到(storeKey对应的)ZSet后, 该ZSet对应的size
*/
public static long zUnionAndStore(String key, String otherKey, String storeKey) {
log.info("zUnionAndStore(...) => key -> {},otherKey -> {},storeKey -> {}", key, otherKey, storeKey);
Long size = redisTemplate.opsForZSet().unionAndStore(key, otherKey, storeKey);
log.info("zUnionAndStore(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 获取两个(key对应的)ZSet的并集,并将结果add到storeKey对应的ZSet中
*
* 注: 和set一样,zset中item是唯一的,在多个zset进行Union时,处理相同的item时,score的值会变为对应的score之和,如:
* RedisUtil.ZSetOps.zAdd("name1","a",1);和RedisUtil.ZSetOps.zAdd("name2","a",2);
* 对(name1和name2对应的)zset进行zUnionAndStore之后,新的zset中的项a,对应的score值为3
*
* case1: 并集不为空,storeKey不存在,则 会创建对应的storeKey,并将并集添加到(storeKey对应的)ZSet中
* case2: 并集不为空,storeKey已存在,则 会清除原(storeKey对应的)ZSet中所有的项,然后将并集添加到(storeKey对应的)ZSet中
* case3: 并集为空,则不进行下面的操作,直接返回0
*
* @param key 定位其中一个set的键
* @param otherKeys 定位其它set的键集
* @param storeKey 定位(要把并集添加到哪个)set的key
* @return add到(storeKey对应的)ZSet后, 该ZSet对应的size
*/
public static long zUnionAndStore(String key, Collection otherKeys, String storeKey) {
log.info("zUnionAndStore(...) => key -> {},otherKeys -> {},storeKey -> {}", key, otherKeys, storeKey);
Long size = redisTemplate.opsForZSet().unionAndStore(key, otherKeys, storeKey);
log.info("zUnionAndStore(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 获取两个(key对应的)ZSet的交集,并将结果add到storeKey对应的ZSet中
*
* 注: 和set一样,zset中item是唯一的,在多个zset进行Intersect时,处理相同的item时,score的值会变为对应的score之和,如:
* RedisUtil.ZSetOps.zAdd("name1","a",1);
* RedisUtil.ZSetOps.zAdd("name1","b",100);
* 和R
* edisUtil.ZSetOps.zAdd("name2","a",2);
* edisUtil.ZSetOps.zAdd("name2","c",200);
* 对(name1和name2对应的)zset进行zIntersectAndStore之后,新的zset中的项a,对应的score值为3
*
* case1: 交集不为空,storeKey不存在,则 会创建对应的storeKey,并将交集添加到(storeKey对应的)ZSet中
* case2: 交集不为空,storeKey已存在,则 会清除原(storeKey对应的)ZSet中所有的项,然后将交集添加到(storeKey对应的)ZSet中
* case3: 交集为空,则不进行下面的操作,直接返回0
*
* @param key 定位其中一个ZSet的键
* @param otherKey 定位其中另一个ZSet的键
* @param storeKey 定位(要把交集添加到哪个)ZSet的key
* @return add到(storeKey对应的)ZSet后, 该ZSet对应的size
*/
public static long zIntersectAndStore(String key, String otherKey, String storeKey) {
log.info("zIntersectAndStore(...) => key -> {},otherKey -> {},storeKey -> {}", key, otherKey, storeKey);
Long size = redisTemplate.opsForZSet().intersectAndStore(key, otherKey, storeKey);
log.info("zIntersectAndStore(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
/**
* 获取多个(key对应的)ZSet的交集,并将结果add到storeKey对应的ZSet中
*
* case1: 交集不为空,storeKey不存在,则 会创建对应的storeKey,并将交集添加到(storeKey对应的)ZSet中
* case2: 交集不为空,storeKey已存在,则 会清除原(storeKey对应的)ZSet中所有的项,然后将交集添加到(storeKey对应的)ZSet中
* case3: 交集为空,则不进行下面的操作,直接返回0
*
* @param key 定位其中一个set的键
* @param otherKeys 定位其它set的键集
* @param storeKey 定位(要把并集添加到哪个)set的key
* @return add到(storeKey对应的)ZSet后, 该ZSet对应的size
*/
public static long zIntersectAndStore(String key, Collection otherKeys, String storeKey) {
log.info("zIntersectAndStore(...) => key -> {},otherKeys -> {},storeKey -> {}",
key, otherKeys, storeKey);
Long size = redisTemplate.opsForZSet().intersectAndStore(key, otherKeys, storeKey);
log.info("zIntersectAndStore(...) => size -> {}", size);
if (size == null) {
throw new RedisOpsResultIsNullException();
}
return size;
}
}
/**
* redis分布式锁(单机版).
*
* 使用方式(示例):
* boolean flag = false;
* String lockName = "sichuan:mianyang:fucheng:ds";
* String lockValue = UUID.randomUUID().toString();
* try {
* // 非阻塞获取(锁的最大存活时间采用默认值)
* flag = RedisUtil.LockOps.getLock(lockName,lockValue);
* // 非阻塞获取e.g.
* flag = RedisUtil.LockOps.getLock(lockName,lockValue,3,TimeUnit.SECONDS);
* // 阻塞获取(锁的最大存活时间采用默认值)
* flag = RedisUtil.LockOps.getLockUntilTimeout(lockName,lockValue,2000);
* // 阻塞获取e.g.
* flag = RedisUtil.LockOps.getLockUntilTimeout(lockName,lockValue,2,TimeUnit.SECONDS,2000);
* if (!flag) {
* throw new RuntimeException(" obtain redis-lock[" + lockName + "] fail");
* }
* // your logic
* // ...
* } finally {
* if (flag) {
* RedisUtil.LockOps.releaseLock(lockName,lockValue);
* }
* }
*
* |--------------------------------------------------------------------------------------------------------------------|
* |单机版分布式锁、集群版分布式锁,特别说明: |
* | - 此锁是针对单机Redis的分布式锁; |
* | - 对于Redis集群而言,此锁可能存在失效的情况考虑如下情况: |
* | 首先,当客户端A通过key-value(假设为key名为key123)在Master上获取到一个锁 |
* | 然后,Master试着把这个数据同步到Slave的时候突然挂了(此时Slave上没有该分布式锁的key123) |
* | 接着,Slave变成了Master |
* | 不巧的是,客户端B此时也一以相同的key去获取分布式锁; |
* | 因为现在的Master上没有key123代表的分布式锁, |
* | 所以客户端B此时再通过key123去获取分布式锁时, |
* | 就能获取成功 |
* | 那么此时,客户端A和客户端B同时获取到了同一把分布式锁,分布式锁失效 |
* | - 在Redis集群模式下,如果需要严格的分布式锁的话,可使用Redlock算法来实现Redlock算法原理简述: |
* | - 获取分布式锁: |
* | 1. 客户端获取服务器当前的的时间t0 |
* | 2. 使用相同的key和value依次向5个实例获取锁 |
* | 注:为了避免在某个redis节点耗时太久而影响到对后面的Redis节点的锁的获取; |
* | 客户端在获取每一个Redis节点的锁的时候,自身需要设置一个较小的等待获取锁超时的时间, |
* | 一旦都在某个节点获取分布式锁的时间超过了超时时间,那么就认为在这个节点获取分布式锁失败, |
* | (不把时间浪费在这一个节点上),继续获取下一个节点的分布式锁 |
* | 3. 客户端通过当前时间(t1)减去t0,计算(从所有redis节点)获取锁所消耗的总时间t2(注:t2=t1-t0) |
* | 只有t2小于锁本身的锁定时长(注:若锁的锁定时长是1小时,假设下午一点开始上锁,那么锁会在下午两点 |
* | 的时候失效,而你却在两点后才获取到锁,这个时候已经没意义了),并且,客户端在至少在多半Redis |
* | 节点上获取到锁,我们才认为分布式锁获取成功 |
* | 5. 如果锁已经获取,那么 锁的实际有效时长 = 锁的总有效时长 - 获取分布式锁所消耗的时长; 锁的实际有效时长 应保证 > 0 |
* | 注: 也就是说,如果获取锁失败,那么 |
* | A. 可能是 获取到的锁的个数,不满足大多数原则 |
* | B. 也可能是 锁的实际有效时长不大于0 |
* | - 释放分布式锁: 在每个redis节点上试着删除锁(,不论有没有在该节点上获取到锁) |
* | - 集群下的分布式锁,可直接使用现有类库
* 注: 获取结果是即时返回的、是非阻塞的
*
* @see LockOps#getLock(String, String, long, TimeUnit)
*/
public static boolean getLock(final String key, final String value) {
return getLock(key, value, DEFAULT_LOCK_TIMEOUT, DEFAULT_TIMEOUT_UNIT);
}
/**
* 获取(分布式)锁
* 若成功,则直接返回;
* 若失败,则进行重试,直到成功 或 超时为止
*
* 注: 获取结果是阻塞的,要么成功,要么超时,才返回
*
* @param retryTimeoutLimit 重试的超时时长(ms)
* 其它参数可详见:
* @return 是否成功
* @see LockOps#getLock(String, String, long, TimeUnit)
*/
public static boolean getLockUntilTimeout(final String key, final String value,
final long retryTimeoutLimit) {
return getLockUntilTimeout(key, value, DEFAULT_LOCK_TIMEOUT, DEFAULT_TIMEOUT_UNIT, retryTimeoutLimit);
}
/**
* 获取(分布式)锁
* 若成功,则直接返回;
* 若失败,则进行重试,直到成功 或 超时为止
*
* 注: 获取结果是阻塞的,要么成功,要么超时,才返回
*
* @param retryTimeoutLimit 重试的超时时长(ms)
* 其它参数可详见:
* @return 是否成功
* @see LockOps#getLock(String, String, long, TimeUnit, boolean)
*/
public static boolean getLockUntilTimeout(final String key, final String value,
final long timeout, final TimeUnit unit,
final long retryTimeoutLimit) {
log.info("getLockUntilTimeout(...) => key -> {},value -> {},timeout -> {},unit -> {},"
+ "retryTimeoutLimit -> {}ms", key, value, timeout, unit, retryTimeoutLimit);
long startTime = Instant.now().toEpochMilli();
long now = startTime;
do {
try {
boolean alreadyGotLock = getLock(key, value, timeout, unit, false);
if (alreadyGotLock) {
log.info("getLockUntilTimeout(...) => consume time -> {}ms,result -> true", now - startTime);
return true;
}
} catch (Exception e) {
log.warn("getLockUntilTimeout(...) => try to get lock failure! e.getMessage -> {}",
e.getMessage());
}
now = Instant.now().toEpochMilli();
} while (now < startTime + retryTimeoutLimit);
log.info("getLockUntilTimeout(...) => consume time -> {}ms,result -> false", now - startTime);
return false;
}
/**
* 获取(分布式)锁
*
* 注: 获取结果是即时返回的、是非阻塞的
*
* @see LockOps#getLock(String, String, long, TimeUnit, boolean)
*/
public static boolean getLock(final String key, final String value,
final long timeout, final TimeUnit unit) {
return getLock(key, value, timeout, unit, true);
}
/**
* 获取(分布式)锁
*
* 注: 获取结果是即时返回的、是非阻塞的
*
* @param key 锁名
* @param value 锁名对应的value
* 注: value一般采用全局唯一的值,如: requestId、uuid等
* 这样,释放锁的时候,可以再次验证value值,
* 保证自己上的锁只能被自己释放,而不会被别人释放
* 当然,如果锁超时时,会被redis自动删除释放
* @param timeout 锁的(最大)存活时长
* 注: 一般的,获取锁与释放锁 都是成对使用的,在锁在达到(最大)存活时长之前,都会被主动释放
* 但是在某些情况下(如:程序获取锁后,释放锁前,崩了),锁得不到释放,这时就需要等锁过
* 了(最大)存活时长后,被redis自动删除清理了这样就能保证redis中不会留下死数据
* @param unit timeout的单位
* @param recordLog 是否记录日志
* @return 是否成功
*/
public static boolean getLock(final String key, final String value,
final long timeout, final TimeUnit unit,
boolean recordLog) {
if (recordLog) {
log.info("getLock(...) => key -> {},value -> {},timeout -> {},unit -> {},recordLog -> {}",
key, value, timeout, unit, recordLog);
}
Boolean result = redisTemplate.execute((RedisConnection connection) ->
connection.set(key.getBytes(StandardCharsets.UTF_8),
value.getBytes(StandardCharsets.UTF_8),
Expiration.seconds(unit.toSeconds(timeout)),
RedisStringCommands.SetOption.SET_IF_ABSENT)
);
if (recordLog) {
log.info("getLock(...) => result -> {}", result);
}
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 释放(分布式)锁
*
* 注: 此方式能(通过value的唯一性)保证: 自己加的锁,只能被自己释放
* 注: 锁超时时,也会被redis自动删除释放
*
* @param key 锁名
* @param value 锁名对应的value
* @return 释放锁是否成功
*/
public static boolean releaseLock(final String key, final String value) {
log.info("releaseLock(...) => key -> {},lockValue -> {}", key, value);
Boolean result = redisTemplate.execute((RedisConnection connection) ->
connection.eval(RELEASE_LOCK_LUA.getBytes(),
ReturnType.BOOLEAN, 1,
key.getBytes(StandardCharsets.UTF_8), value.getBytes(StandardCharsets.UTF_8))
);
log.info("releaseLock(...) => result -> {}", result);
if (result == null) {
throw new RedisOpsResultIsNullException();
}
return result;
}
/**
* 释放锁,不校验该key对应的value值
*
* 注: 此方式释放锁,可能导致: 自己加的锁,结果被别人释放了
* 所以不建议使用此方式释放锁
*
* @param key 锁名
*/
@Deprecated
public static void releaseLock(final String key) {
KeyOps.delete(key);
}
}
/**
* 当使用Pipeline 或 Transaction操作redis时,(不论redis中实际操作是否成功,这里)结果(都)会返回null
* 此时,如果试着将null转换为基本类型的数据时,会抛出此异常
*
* 即: 此工具类中的某些方法,希望不要使用Pipeline或Transaction操作redis
*
* 注: Pipeline 或 Transaction默认是不启用的,可详见源码:
*
* @see LettuceConnection#isPipelined()
* @see LettuceConnection#isQueueing()
* @see JedisConnection#isPipelined()
* @see JedisConnection#isQueueing()
*/
public static class RedisOpsResultIsNullException extends NullPointerException {
public RedisOpsResultIsNullException() {
super();
}
public RedisOpsResultIsNullException(String message) {
super(message);
}
}
/**
* 提供一些基础功能支持
*/
public static class Helper {
/**
* 默认拼接符
*/
public static final String DEFAULT_SYMBOL = ":";
/**
* 拼接args
*
* @see Helper#joinBySymbol(String, String...)
*/
public static String join(String... args) {
return Helper.joinBySymbol(DEFAULT_SYMBOL, args);
}
/**
* 使用symbol拼接args
*
* @param symbol 分隔符,如: 【:】
* @param args 要拼接的元素数组,如: 【a b c】
* @return 拼接后的字符串, 如 【a:b:c】
*/
public static String joinBySymbol(String symbol, String... args) {
if (symbol == null || symbol.trim().length() == 0) {
throw new RuntimeException(" symbol must not be empty!");
}
if (args == null || args.length == 0) {
throw new RuntimeException(" args must not be empty!");
}
StringBuilder sb = new StringBuilder(16);
for (String arg : args) {
sb.append(arg).append(symbol);
}
sb.replace(sb.length() - symbol.length(), sb.length(), "");
return sb.toString();
}
}
}
@Configuration 用于定义配置类,可替换 xml 配置文件,被注解的类内部包含有一个或多个被 @Bean 注解的
方法
@Bean 用于定义加载类型
@CacheConfig 一个类级别的注解,允许共享缓存的 cacheNames 、 KeyGenerator 、 CacheManager 和
CacheResolver.
Cacheable 用来声明方法是可缓存的。将结果存储到缓存中以便后续使用相同参数调用时不需执行实际的方
法。直接从缓存中取值
@CachePut 标注的方法在执行前不会去检查缓存中是否存在之前执行过的结果,而是每次都会执行该方法,
并将执行结果以键值对的形式存入指定的缓存中。
@CacheEvict 的作用 主要针对方法配置,能够根据一定的条件对缓存进行清空
项目整体结构:
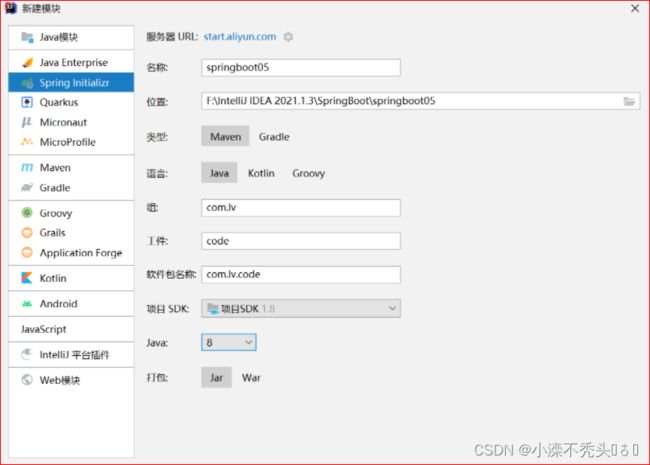
 2、导入pom依赖
2、导入pom依赖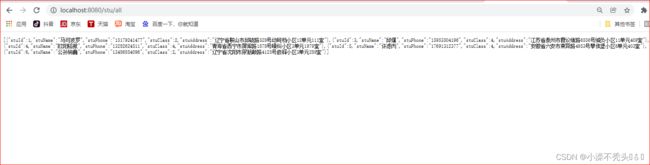
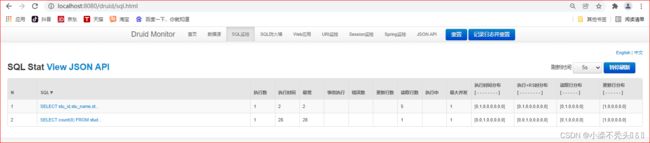

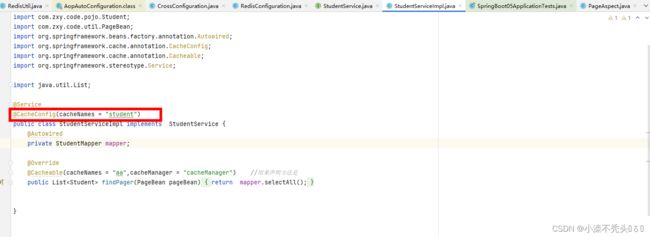

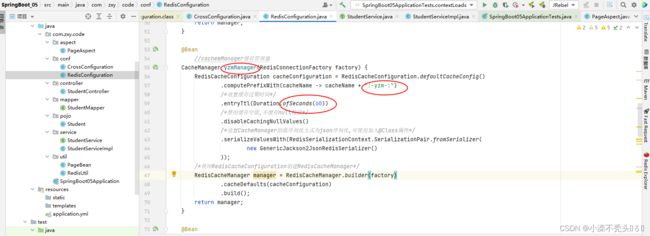
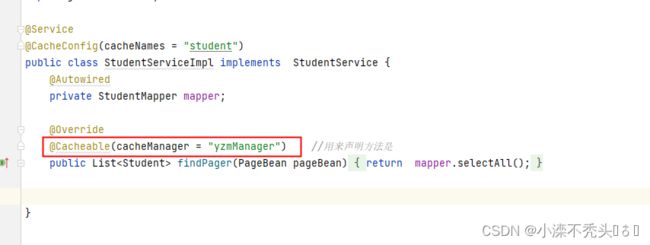
 3.2、keyGenerator方法的使用
3.2、keyGenerator方法的使用