CVPR2020 Improving Convolutional Networks with Self-Calibrated Convolutions论文详解 SC-Net 注意力机制
论文:http://mftp.mmcheng.net/Papers/20cvprSCNet.pdf
代码:https://github.com/MCG-NKU/SCNet
《Improving Convolutional Networks with Self-calibrated Convolutions》 CVPR2020 南开大学程明明团队(将多尺度引入Resnet中的Res2Net)
CNN的最新进展主要致力于设计更复杂的体系结构,以增强其特征表示能力,各种卷积模块工作层出不穷,性能涨点明显,包括李沐等人大神提出的ResNeSt、华为提出的DyNet、谷歌提出的CondConv、清华大学提出的XSepConv与ACNet等工作,大量新工作涌现,说明backbone的改进应该是近期的热点方向。
0.摘要
在本文中,考虑在不调整模型架构的情况下改进CNN的基本卷积特征转换过程。为此,本文提出了一种新颖的自校正卷积,该卷积它可以通过特征的内在通信达到扩增卷积感受野的目的,进而增强输出特征的多样性。不同于标准卷积采用小尺寸核(例如3×3卷积),同时融合空间维度域与通道维度的信息,
本文所设计的SC Net可以通过自校正操作自适应地在每个空间位置周围建立了远程空间和通道间依存关系;设计简单且通用,可以轻松增强标准卷积层的性能,而不会引入额外的参数和复杂性。
作者希望这项工作可以为未来的研究提供一种设计新颖的卷积特征变换以改善卷积网络的方法。
1.简介
在本文中,不是设计复杂的网络体系结构来增强特征表示,而是引入了自校正卷积作为一种有效的方法来帮助卷积网络通过增加每层的基本卷积变换来学习判别表示。类似于分组卷积,它将特定层的卷积核分为多个部分,但不均匀地每个部分中的卷积核以异构方式被利用。具体而言,自校正卷积不是通过均匀地对原始空间中的输入执行所有卷积,而是首先通过下采样将输入转换为低维嵌入。采用由一个卷积核变换的低维嵌入来校准另一部分中卷积核的卷积变换。得益于这种异构卷积和卷积核间通信,可以有效地扩大每个空间位置的感受野。空间上的每一个点都有附近区域的信息和通道上的交互信息,同时也避免了整个全局信息中无关区域的干扰,
作为标准卷积的增强版本,自校正卷积具有两个贡献:
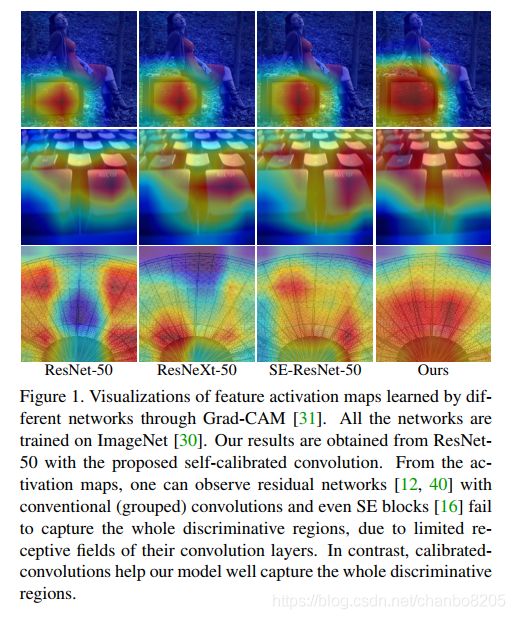
1. 它使每个空间位置能自适应地编码远距离区域的信息上下文,打破了在小区域内(3*3)进行卷积操作的传统。这使得自校准卷积产生的特征表示更具区别性。在下图中,我们可视化了具有不同类型卷积的ResNets产生的特征激活图。如图所示,可以观察到具有常规卷积的残差网络ResNet以及具有分组卷积的残差网络ResNeXt网络的卷积层感受野有限,甚至SE模块也无法捕获整个判别区域;采用自校正卷积的ResNet具有较大的感受野,自校正卷积有助于很好地捕获整个判别区域,可以更准确、更完整地定位目标物,并且采用SCNet的输出对前景有明显的分割。
2. 提出的自校准卷积具有通用性,可以很容易地应用于标准卷积层,而无需引入任何参数和复杂性开销,也无需改变超参数。
当前CNN网络的优化主要有两个方面:
1.结构设计:Alext-VGG-GoogleNet-ResNet-DenseNet-ResNeXt-NasNet。
作为早期工作,与AlexNet相比,VGGNet使用更小的内核大小(3*3)的卷积过滤器构建更深层次的网络,使用更少的参数获得更好的性能。ResNets通过引入剩余连接和使用BN改进了顺序结构,使建立非常深的网络成为可能。ResNeXt和Wide ResNet[通过分组3*3个卷积层或增加它们的宽度来扩展ResNet。GoogLeNet和Inceptions使用了精心设计的Inception模块,该模块带有多个平行路径的专用卷积核集合(3*3等),用于特征转换。NASNet通过探索预定义的搜索空间来构建模型体系结构,支持可转移性。DenseNet和DLA通过复杂的自下而上跳跃连接聚合特性。双路径网络(DPNs)利用残差连接和密集连接来构建强特征表示。SENet引入了通道注意力机制来显式地建模通道之间的相互依赖关系
2.长距离依赖建模(注意力机制):SENet-GENet-CBAM-GCNet-GALA-AA-NLNet
SENet采用Squeeze-and-Excitation模块来建立通道尺寸之间的相互依赖关系。后来的网络如GENet、CBAM、GCNet、GALA、AA和NLNet,通过引入空间注意机制或设计高级注意块,进一步扩展了这一理念。另一种建模远程依赖关系的方法是利用空间池化或带有大窗口的卷积核。一些典型的示例(如PSPNet)采用不同大小的多个空间池化运算来捕获多尺度上下文。还有利用大型卷积内核或扩展卷积进行远程上下文聚合。我们的工作也不同于Octave convolution,它的目的是减少空间冗余和计算成本。
与上述所有专注于优化网络架构或添加额外手工设计的块来改进卷积网络的方法不同,我们的方法考虑更有效地利用卷积层中的卷积过滤器,并设计强大的特征变换来生成更有表现力的特征表示。
2.GC Net方法说明
2.0 常规卷积
假设输入特征为X ,输出特征为 Y,那么传统的2D卷积 由一组滤波器集合 构成。此时常规卷积公式可以描述如下:

输入C X H X W ,在输出通道也为C的卷积中,卷积核K的维度为C X C X H X W。
缺点:这种卷积的卷积核学习模式都具有相似性。此外,卷积特征变换中,每个空间位置的视野主要由预定义的内核大小控制,由此类卷积层的堆叠组成的网络也缺少大的感受野,无法捕获足够的高级语义。以上两个缺点都可能导致特征图的辨识度较低。
2.1 自校正卷积 SCConv(Self-Calibrated Convolutions)
自校正卷积具体步骤如图所示:
第一步,输入特征图X为C * H * W大小,拆分为两个C/2 * H * W大小的X1,X2;
第二步,卷积核K的维度为C * C * H * W,将K分为4个部分,每份的作用各不相同,分别记为K1,K2,K3,K4,其维度均为C/2 * C/2 * H * W,来收集不同类型的上下文信息。(K1,K2,K3)对X1进行自校正操作,得到Y1。此外,我们进行了一个简单的卷积操作:Y2 = F1(X2) = X2 * K1,目的是保留原始的空间背景。

为了有效地收集每个空间位置的丰富的上下文信息,作者提出在两个不同的尺度空间中进行卷积特征转换:原始尺度空间中的特征图(输入共享相同的分辨率)和下采样后的具有较小分辨率的潜在空间(用于自校正) 。利用下采样后特征具有较大的感受野,因此在较小的潜在空间中进行变换后的嵌入将用作参考,以指导原始特征空间中的特征变换过程。
第三步,对自校正尺度空间进行处理(Self-Calibration)




对特征X1采用平均池化下采样r倍(论文r=4,公式2),再进行特征提取及上采样(双线性插值,公式3),经过Sigmoid激活函数对K3卷积提取后的特征进行校准得到输出特征Y1。σ为sigmoid函数,UP为上采样。
第四步,对原尺度特征空间进行处理,对特征X2经过K1卷积提取得到特征Y2;
第五步,对两个尺度空间输出特征Y1,Y2进行拼接操作,得到最终输出特征Y。
附代码
class SCConv(nn.Module):
def __init__(self, planes, stride, pooling_r):
super(SCConv, self).__init__()
self.k2 = nn.Sequential(
nn.AvgPool2d(kernel_size=pooling_r, stride=pooling_r),
conv3x3(planes, planes),
nn.BatchNorm2d(planes),
)
self.k3 = nn.Sequential(
conv3x3(planes, planes),
nn.BatchNorm2d(planes),
)
self.k4 = nn.Sequential(
conv3x3(planes, planes, stride),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True),
)
def forward(self, x):
identity = x
out = torch.sigmoid(torch.add(identity, F.interpolate(self.k2(x), identity.size()[2:]))) # sigmoid(identity + k2)
out = torch.mul(self.k3(x), out) # k3 * sigmoid(identity + k2)
out = self.k4(out) # k4
return out
优势:
1、与传统的卷积相比,通过采用校正操作允许每个空间位置不仅将其周围的信息环境自适应地视为来自低分辨率潜在空间的嵌入,以作为来自原始比例空间的响应中的输入,还可以对通道间依赖性进行建模。因此,可以有效地扩大具有自校准的卷积层的感受野。如下图所示,具有自校准功能的卷积层编码更大但更准确的区分区域。

2、自校准操作不收集全局上下文,而仅考虑每个空间位置周围的上下文,避免了不相关区域的无用信息。
3、自校准操作对多尺度信息进行编码,这是与目标检测相关的任务非常需要的。
总的来说,文中的self-Calibrated Convolutions就是一个多尺度特征提取模块。作者通过特征图下采样来增大CNN的感受野,每个空间位置都可以通过自校准操作融合来自两个不同空间尺度空间的信息。而且从图中可以看出,Self-Calibrated Convolutions没有引入额外的可学习参数,但是其计算量还是会增大。
文中采用resnet及其变种网络进行试验,考虑了50层和101层的瓶颈结构,只将每个模块的中3*3卷积层中的卷积操作替换为 自校准卷积操作,并保持所有相关超参数不变。默认情况下,自校准卷积的下采样率r设置为4。
3.实验结果
ImageNet上的测试,实验中的训练过程参考ResNeXt文章中的训练,避免因Tricks导致性能的较大差异。相关实验结果见下图。

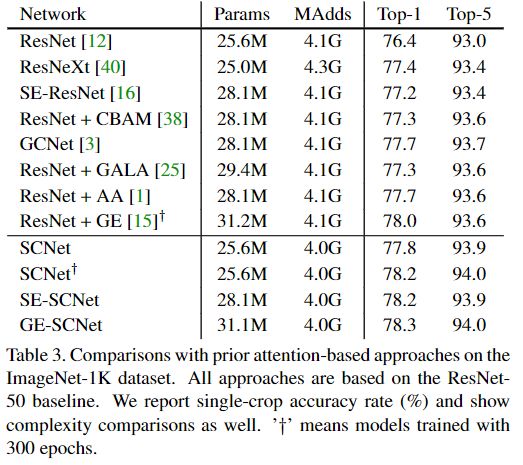
将SCNet引入其他backbone,无论ResNet、ResNeXt还是SE-ResNet均可得到一定程度的性能提升。
消融实验:当下采样率为4,池化方式为均值池化时具有最佳性能。

对比实验:将其与其他注意力机制(CBAM、SENet、GALA、AA、GE等)方法进行了性能对比。其他注意力机制方法大多需要额外的可学习参数,而本文所提方法则无需额外可学习参数。
扩展实验:将所提方案拓展到目标检测、关键点检测、实例分割等应用领域,进一步验证了所提方案的性能,可以一致性的提升改善模型的性能。

参考:
https://blog.csdn.net/sinat_17456165/article/details/106536610