八大排序算法
文章目录
-
八大排序算法
-
- 一 冒泡排序
-
- 二 选择排序
-
- 三 插入排序
-
- 四 希尔排序
-
- 五 快速排序
-
- 六 归并排序
-
- 七 基数排序
-
- 八 堆排序
-
- 九 常用排序算法对比
| 资料 |
| 来源:【尚硅谷】数据结构与算法(Java数据结构与算法) |
| 课件:数据结构和算法.exe |
| 图解排序 |
一 冒泡排序
- 基本介绍
冒泡排序( bubble sorting )
- 基本思想
通过对待排序序列从前向后(从下标较小的元素开始),依次比较相邻元素的值,若发现逆序则交换,使值较大的元素逐渐从前移向后部,就象水底下的气泡一样逐渐向上冒。
因为排序的过程中,各元素不断接近自己的位置,如果一趟比较下来没有进行过交换,就说明序列有序,因此要在排序过程中设置一个标志flag判断元素是否进行过交换。从而减少不必要的比较。(这里说的优化,可以在冒泡排序写好后,在进行)
代码实现
public void bubbleSort(int[] arr){
int temp=0;
boolean flag=false;
for(int i=0;i<arr.length-1;i++){
for(int j=0;j<arr.length-1-i;j++){
if(arr[j]>arr[j+1]){
temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
flag=true;
}
}
if(!flag) break;
flag=false;
}
}
- 性能
- 时间复杂度为 O(n^2)
- 8 万个数据用时 16s / 23s
- 总结
第一个 for 循环实现第几趟大的排序,第二个 for 循环实现在一次大的排序中,进行几次比较。第一个 for 循环,如果有 5 个数,则进行 5-1=4 次循环。第二个 for 循环可以将所有的数进行比较,但是比较浪费时间,因此比较次数可以根据比较的趟数依次递减
二 选择排序
- 基本介绍
选择排序( select sorting )也属于内部排序法,是从欲排序的数据中,按指定的规则选出某一元素,再依规定交换位置后达到排序的目的。
- 基本思想
第一次从 arr[0]~arr[n-1] 中选取最小值,与 arr[0] 交换,第二次从 arr[1]~arr[n-1] 中选取最小值,与 arr[1] 交换,第三次从 arr[2]~arr[n-1] 中选取最小值,与 arr[2] 交换,…,第 i 次从 arr[i-2]~arr[n-1] 中选取最小值,与 arr[i-1] 交换,…,第 n-1 次从 arr[n-2]~arr[n-1] 中选取最小值,与 arr[n-2] 交换,总共通过 n-1 次,得到一个按排序码从小到大排列的有序序列
代码实现
public void selectSort(int[] arr){
int minIndex,temp;
for(int i=0;i<arr.length-1;i++){
minIndex=i;
for(int j=i+1;j<arr.length;j++){
if(arr[minIndex]>arr[j]){
minIndex=j;
}
}
if(minIndex!=i){
temp=arr[minIndex];
arr[minIndex]=arr[i];
arr[i]=temp;
}
}
}
- 性能
- 时间复杂度为 O(n^2)
- 8 万个数据用时 2s / 3s
- 总结
第一个 for 循环假定为待插入的位置,同时假定它为当次循环中最小的值的下标,该 for 循环的次数为 arr.length-1 次。第二个 for 循环在待插入位置的后一位开始一直查找完整个数组,来更新最小值的下标,该 for 循环结束一轮后,将待插入位置与最小值下标的值进行交换
三 插入排序
- 基本介绍
插入排序( insertion sorting)属于内部排序法,是对于欲排序的元素以插入的方式找寻该元素的适当位置,以达到排序的目的
- 基本思想
把 n 个待排序的元素看成为一个有序表和一个无序表,开始时有序表中只包含一个元素,无序表中包含有 n-1 个元素,排序过程中每次从无序表中取出第一个元素,把它的排序码依次与有序表元素的排列码进行比较,将它插入到有序表中的适当位置,使之成为新的有序表
代码实现
public void insertSort(int[] arr){
int insertVal,insertIndex;
for(int i=1;i<arr.length;i++){
insertVal=arr[i];
insertIndex=i-1;
- 性能
- 总结
该 for 循环代表无序表中的第一个数( for 循环从数组下标 1 开始,一直循环完整个数组中的数据 ),从 1 开始是因为第 0 个位置刚开始就被当成有序表的数据。待插入位置为有序表最后一位,即 i-1 。当 insertIndex 下标的值不符和插入的条件时,就把当前 insertIndex 所指的值赋值给它所在的后一位下标上。
最后赋值需要 insertIndex+1 ,是因为此时 insertIndex 所指的值小于待插入的值(也可能是由于 insertIndex>=0 这个条件不满足,此时 insertIndex=-1,代表此时待插入数据在有序表中最小,需要插入到 0 这个位置,此时 insertIndex+1=0 ),所以待插入的值需要插入到此时 insertIndex 所指的值的后面(此时 insertIndex+1 下标的值已经保存在 insertIndex+1+1 这个下标所在的位置了)
四 希尔排序
- 基本介绍
希尔排序是希尔( Donald Shell )于 1959 年提出的一种排序算法。希尔排序也是一种 插入排序 ,提示简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序
- 基本思想
把记录按下标的一定增量分组,对每组使用直接插入排序算法排序,随着增量逐渐减少,每组包含的关键词越来越多,当增量减至 1 时,整个文件恰被分成一组,算法便终止
代码实现(交换法)
public void shellSort(int[] arr){
int temp;
for(int gap=arr.length/2;gap>0;gap/=2){
for(int i=gap;i<arr.length;i++){
for(int j=i-gap;j>=0;j-=gap){
if(arr[j]>arr[j+gap]){
temp=arr[j];
arr[j]=arr[j+gap];
arr[j+gap]=temp;
}
}
}
}
}
public void shellSort(int[] arr){
int temp;
for(int gap=arr.length/2;gap>0;gap/=2){
for(int i=0;i<arr.length-gap;i++){
for(int j=0;j<arr.length-gap;j+=gap){
if(arr[j]>arr[j+gap]){
temp=arr[j];
arr[j]=arr[j+gap];
arr[j+gap]=temp;
}
}
}
}
}
代码实现(移位法)
public void shellSort(int[] arr){
for(int gap=arr.length/2;gap>0;gap/=2){
for(int i=gap;i<arr.length;i++){
int insertIndex=i;
int insertVal=arr[i];
if(arr[insertIndex]<arr[insertIndex-gap]){
while(insertIndex-gap>=0 && insertVal<arr[insertIndex-gap]){
arr[insertIndex]=arr[insertIndex-gap];
insertIndex-=gap;
}
arr[insertIndex]=insertVal;
}
}
}
}
public void shellSort(int[] arr){
for(int gap=arr.length/2;gap>0;gap/=2){
for(int i=gap;i<arr.length;i++){
int insertIndex=i-gap;
int insertVal=arr[i];
while(insertIndex>=0 && arr[insertIndex]>insertVal){
arr[insertIndex+gap]=arr[insertIndex];
insertIndex-=gap;
}
arr[insertIndex+gap]=insertVal;
}
}
}
- 性能
- 交换法
- 移位法
- 8 万个数据用时 0s / 1s
- 80 万个数据用时 1s
- 800 万个数据用时 4s
- 总结
根据步长分组,通过算法将每一组实现有序(交换法相当于冒泡排序,移位法相当于插入排序),实现有序后再缩小步长,当步长为 1 时,相当于整个数组了,此时再次进行排序后即为最终答案
五 快速排序
- 基本介绍
快速排序( Quicksort )是对冒泡排序的一种改进
- 基本思想
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列
代码实现
public void quickSort(int[] arr,int left,int right){
int l=left;
int r=right;
int pivot=arr[(left+right)/2];
int temp;
while(l<r){
while(arr[l]<pivot) l++;
while(arr[r]>pivot) r--;
if(l>=r) break;
temp=arr[l];
arr[l]=arr[r];
arr[r]=temp;
if(arr[l]==pivot) r--;
if(arr[r]==pivot) l++;
}
if(l==r){
l++;
r--;
}
if(left<r) quickSort(arr,left,r);
if(right>l) quickSort(arr,l,right);
}
- 性能
- 8 万个数据用时 0s / 1s
- 80 万个数据用时 0s
- 800 万个数据用时 2s / 4s
- 总结
六 归并排序
- 基本介绍
归并排序( MERGE-SORT )是利用归并的思想实现的排序方法,该算法采用经典的分治( divide-and-conquer )策略(分治法将问题分( divide )成一些小的问题然后递归求解,而治( conquer )的阶段则将分的阶段得到的各答案“修补”在一起,即分而治之)
- 基本思想
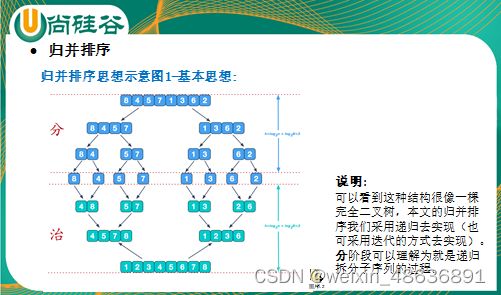
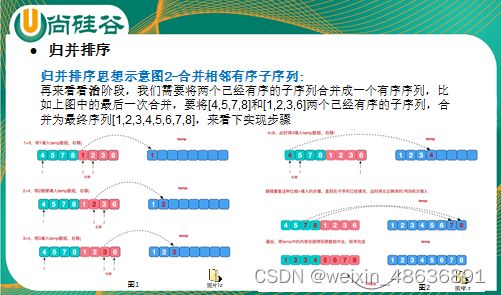
代码实现
public void mergeSort(int[] arr,int left,int right,int[] temp){
if(left<right){
int mid=(left+right)/2;
mergeSort(arr,left,mid,temp);
mergeSort(arr,mid+1,right,temp);
merge(arr,left,mid,right,temp);
}
}
public static void merge(int[] arr,int left,int mid,int right,int[] temp){
int i=left;
int j=mid+1;
int t=0;
while(i<=mid && j<=right){
if(arr[i]<=arr[j]){
temp[t]=arr[i];
t++;
i++;
}else{
temp[t]=arr[j];
t++;
j++;
}
}
while(i<=mid){
temp[t]=arr[i];
t++;
i++;
}
while(j<=right){
temp[t]=arr[j];
t++;
j++;
}
t=0;
int tempLeft=left;
while(tempLeft<=right){
arr[tempLeft]=temp[t];
t++;
tempLeft++;
}
}
- 性能
- 8 万个数据用时 0s / 1s
- 80 万个数据用时 1s
- 800 万个数据用时 3s / 4s
- 总结
七 基数排序
- 基本介绍
- 基数排序( radix sort )属于“分配式排序”( distributio sort ),又称“桶子法”( bucket sort )或 bin sort ,顾名思义,它是通过键值的各个位的值,将要排序的元素分配至某些“桶”中,达到排序的作用
- 基数排序法属于稳定性的排序,基数排序法是效率高的稳定性排序法
- 基数排序( Radix Sort )是桶排序的扩展
- 基数排序是 1887 年郝尔曼.何乐礼发明的。它是这样实现的:将整数按位数切割成不同的数字,然后按每个位数分别比较
- 基本思想
将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行依次排序,这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列
代码实现
public void radixSort(int[] arr){
int max=arr[0];
for(int i=1;i<arr.length;i++){
if(arr[i]>max) max=arr[i];
}
int maxLength=(max+"").length();
int[][] bucket=new int[10][arr.length];
int[] bucketElementCounts=new int[10];
for(int i=0,n=1;i<maxLength;i++,n*=10){
for(int j=0;j<arr.length;j++){
int digitOfElement=arr[j]/n % 10;
bucket[digitOfElement][bucketElementCounts[digitOfElement]]=arr[j];
bucketElementCounts[digitOfElement]++;
}
int index=0;
for(int k=0;k<bucketElementCounts.length;k++){
if(bucketElementCounts[k]!=0){
for(int l=0;l<bucketElementCounts[k];l++){
arr[index++]=bucket[k][l];
}
}
bucketElementCounts[k]=0;
}
}
}
- 性能
- 8 万个数据用时 0s / 1s
- 80 万个数据用时 0s
- 800 万个数据用时 1s
- 8000 万个数据报错 OutOfMemoryError
- 总结
根据各个数据指定位数的大小将各个数据放入到合适的桶中,全部放完后,从第 0 个桶开始依次取出数据到原数组,当一个桶中有多个数据时,根据先放入先取出的原则来进行转移
整个大的循环次数是根据数组中最大值的位数来确定的
- 补充
- 基数排序是对传统桶排序的扩展,速度很快
- 基数排序是经典的空间换时间的方式,占用内存很大,当对海量数据排序时,容易造成 OutOfMemoryError
- 技术排序是稳定的 [注:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且 r[i] 在 r[j] 之前,而在排序后的序列中,r[i] 仍在 r[j] 之前,则称这种排序算法是稳定的,否则称为不稳定的]
- 有负数的数组,我们不用基数排序来进行排序,如果要支持负数,参考:链接
八 堆排序
- 基本介绍
- 堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏、最好、平均时间复杂度均为 O(nlogn),它也是不稳定排序
- 堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆,注意:没有要求结点的左孩子的值和右孩子的值的大小关系
- 每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆
- 大顶堆举例说明:

- 小顶堆举例说明:
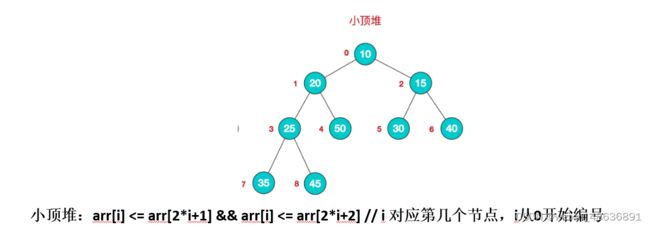
- 一般升序采用大顶堆,降序采用小顶堆
- 基本思想
- 将待排序序列构造成一个大顶堆
- 此时,整个序列的最大值就是堆顶的根结点
- 将其与末尾元素进行交换,此时末尾就为最大值
- 然后将剩余 n-1 个元素重新构造成一个堆,这样会得到 n 个元素的次大值。如此反复执行,便能得到一个有序序列了
可以看到在构建大顶堆的过程中,元素的个数逐渐减少,最后就得到一个有序序列了
代码实现
public void heapSort(int[] arr){
int temp;
for(int i=arr.length/2-1;i>=0;i--){
adjustHeap(arr,i,arr.length);
}
for(int i=arr.length-1;i>0;i--){
temp=arr[i];
arr[i]=arr[0];
arr[0]=temp;
adjustHeap(arr,0,i);
}
}
public static void adjustHeap(int arr[],int i,int length){
int temp=arr[i];
for(int k=i*2+1;k<length;k=k*2+1){
if(k+1<length && arr[k]<arr[k+1]){
k++;
}
if(arr[k]>temp){
arr[i]=arr[k];
i=k;
}else{
break;
}
}
arr[i]=temp;
}
- 性能
- 8 万个数据用时 0s / 1s
- 80 万个数据用时 0s
- 800 万个数据用时 4s / 5s
- 总结
九 常用排序算法对比
| 排序算法 |
平均时间复杂度 |
最好情况 |
最坏情况 |
空间复杂度 |
排序方式 |
稳定性 |
| 冒泡排序 |
O(n²) |
O(n) |
O(n²) |
O(1) |
In-place |
稳定 |
| 选择排序 |
O(n²) |
O(n²) |
O(n²) |
O(1) |
In-place |
不稳定 |
| 插入排序 |
O(n²) |
O(n) |
O(n²) |
O(1) |
In-place |
稳定 |
| 希尔排序 |
O(n log n) |
O(n log² n) |
O(n log² n) |
O(1) |
In-place |
不稳定 |
| 归并排序 |
O(n log n) |
O(n log n) |
O(n log n) |
O(n) |
Out-place |
稳定 |
| 快速排序 |
O(n log n) |
O(n log n) |
O(n²) |
O(log n) |
In-place |
不稳定 |
| 堆排序 |
O(n log n) |
O(n log n) |
O(n log n) |
O(1) |
In-place |
不稳定 |
| 计数排序 |
O(n+k) |
O(n+k) |
O(n+k) |
O(k) |
Out-place |
稳定 |
| 桶排序 |
O(n+k) |
O(n+k) |
O(n²) |
O(n+k) |
Out-place |
稳定 |
| 基数排序 |
O(n+k) |
O(n+k) |
O(n+k) |
O(n+k) |
Out-place |
稳定 |
相关术语解释:
- 稳定:如果 a 原本在 b 前面,而 a=b,排序之后 a 仍然在 b 的前面
- 不稳定:如果 a 原本在 b 的前面,而 a=b,排序之后 a 可能会出现在 b 的后面
- 内排序:所有排序操作都在内存中完成
- 外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行
- 时间复杂度:一个算法执行所耗费的时间
- 空间复杂度:运行完一个程序所需内存的大小
- n:数据规模
- k:“桶”的个数
- In-place:不占用额外内存
- Out-place:占用额外内存