pytorch加载预训练模型(.pth格式)
0. 写在前面
pytorch自带模型网址:
https://pytorch-cn.readthedocs.io/zh/latest/torchvision/torchvision-models/
官方预训练模型调用代码:
https://github.com/pytorch/vision/tree/master/torchvision/models
官方文档地址 :
https://pytorch.org/docs/master/torchvision/models.html
1. 按官网加载预训练好的模型:
import torchvision.models as models
# pretrained=True就可以使用预训练的模型
resnet18 = models.resnet18(pretrained=True)
print(resnet18)报错如下:
requests.exceptions.ConnectionError: ('Connection aborted.', TimeoutError(10060, '由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。', None, 10060, None))
原因:
代码会去远端下载模型的参数,而国内的网一般连接不上,需要手动去下载你要的预训练网络。
解决方法:通过地址下载,地址的获取方式有下面几种。
(1)从报错里面获取
上述代码运行时会出现这样一行信息:
Downloading: "https://download.pytorch.org/models/resnet18-5c106cde.pth" to C:\Users\Luo/.torch\models\resnet18-5c106cde.pth复制到浏览器,有可能打不开,去掉https://,直接输入download.pytorch.org/models/resnet18-5c106cde.pth就可以下载了。
(2)通过model_urls中替换https为http进行下载
import torchvision.models as models
from torchvision.models.alexnet import model_urls
#AlexNet
model_urls['alexnet'] = model_urls['alexnet'].replace('https://', 'http://')
print("=> using pre-trained model '{}'".format('alexnet'))
model = models.__dict__['alexnet'](pretrained=True)(3)从pytorch的github下找模型的地址:https://github.com/pytorch/vision/tree/master/torchvision/models
找到对应模型名称点进去找地址,下载好后自行保存。
以squeezenet为例,pthfile写保存的模型的路径。
import torchvision.models as models
#全局取消证书验证,避免出现报错
## urllib.error.URLError:
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
#SqueezeNet
model = models.squeezenet1_1(pretrained=True)
pthfile = r'../../squeezenet1_1-f364aa15.pth'
model.load_state_dict(torch.load(pthfile))
print(model)
2. 运行.pth文件加载模型
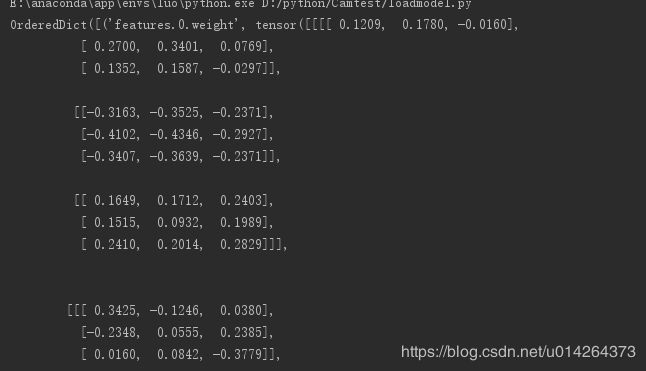
首先要判断是保存的整个网络结构加参数,还是只保存了参数,使用print打印进行测试。
import torch
pthfile = r'E:\anaconda\app\envs\luo\Lib\site-packages\torchvision\models\squeezenet1_1.pth'
net = torch.load(pthfile)
print(net)结果如下,只保存了参数没有保存网络结构。
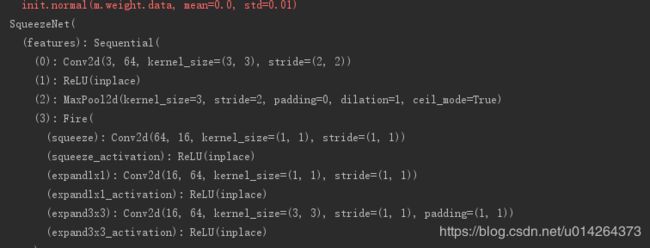
解决方法:换个方法加载模型,像加载自己训练好的网络那样加载预训练模型。
主要是把pretrain设成false,然后直接把路径指定到模型所在处,用load_state_dict程序进行加载。
import torch
import torchvision.models as models
# pretrained=True就可以使用预训练的模型
net = models.squeezenet1_1(pretrained=False)
pthfile = r'E:\anaconda\app\envs\luo\Lib\site-packages\torchvision\models\squeezenet1_1.pth'
net.load_state_dict(torch.load(pthfile))
print(net)结果显示出网络结构,成功。
3. pytorch预训练模型的使用可以参考官方网站FINETUNING TORCHVISION MODELS
https://pytorch.org/tutorials/beginner/finetuning_torchvision_models_tutorial.html#comparison-with-model-trained-from-scratch
4. 使用预训练模型进行迁移学习注意事项
使用squeezenet为例,代码如下:
model=models.squeezenet1_0(pretrained=True)#读取预训练模型参数
for param in model.parameters():#冻结所有参数,不被更新
param.requires_grad = False
model.classifier[1] = nn.Conv2d(512,CL,kernel_size=(1,1),stride=(1,1))#把分类器输出改为分类个数CL
model=model.cuda()#使用GPU加速
print("params to update:")
params_to_update=[]#用来保存需要更新的参数
for name,param in model.named_parameters():
if param.requires_grad==True:
params_to_update.append(param)
print("\t",name)
optimizer=t.optim.Adam(params_to_update,lr=LR)
loss_func=nn.CrossEntropyLoss().cuda()#使用GPU加速
vis=visdom.Visdom(env=u'window')
首先读取预训练模型的所有参数,然后将requires_grad设置为False,不让其更新,然后修改模型的classifier中的[1]层,把Conv2d的输出修改为分类个数。此时model.classifier[1]的参数的requires_grad自动为True,可以被更新。也即是说,squeezenet只训练model.classifier[1]中的参数,其他参数不变。
但是报错:RuntimeError: shape '[25, 1000]' is invalid for input of size 50
这里的1000仍然是squeezenet最初的分类数,虽然修改了model.classifier[1]的分类数,但其内部的参数self.num_classes还是1000,比较特殊,之前使用resnet18没有遇到这个问题。
因此还必须修改内部的参数self.num_classes。
代码如下(加一行修改self.num_classes的代码):
model=models.squeezenet1_0(pretrained=True)#读取预训练模型参数
for param in model.parameters():#冻结所有参数,不被更新
param.requires_grad = False
model.classifier[1] = nn.Conv2d(512,CL,kernel_size=(1,1),stride=(1,1))#把分类器输出改为分类个数CL
model.num_classes = CL #修改self.num_classes
model=model.cuda()#使用GPU加速
print("params to update:")
params_to_update=[]#用来保存需要更新的参数
for name,param in model.named_parameters():
if param.requires_grad==True:
params_to_update.append(param)
print("\t",name)
optimizer=t.optim.Adam(params_to_update,lr=LR)
loss_func=nn.CrossEntropyLoss().cuda()#使用GPU加速
vis=visdom.Visdom(env=u'window')
注⚠️:有一部分参考了 https://blog.csdn.net/u014264373/article/details/85332181
和 http://blog.sina.com.cn/s/blog_4b6a6ae50102yd9c.html