yolov5官网教程&kaggle海星目标检测赛&paddle钢铁缺陷检测赛(VOC格式)
文章目录
-
- 零、 前言
- 一、YOLOv5 Train Custom Data 教程
-
- 1.1 推理
- 1.2 验证精度
- 1.3 COCO 测试
- 1.4 训练demo
- 1.5 可视化
-
- 1.5.1 ClearML 日志记录和自动化 NEW
- 1.5.2 wandb记录权重&偏差
- 1.5.3 Local Logging
- 1.6 使用Roboflow训练自定义数据 NEW
- 二、Kaggle——海星目标检测比赛
- 三、paddle学习赛——钢铁目标检测(VOC数据集转yolo格式)
-
- 3.1 赛事简介
- 3.2 导入相关库
- 3.3 数据预处理
-
- 3.3.1 将数据集移动到work下的dataset文件夹
- 3.3.2 用pandas处理图片名和xml文件名
- 3.3.3 生成yolov5格式的标注文件
- 3.4 使用yolov5进行训练
-
- 3.4.1 安装[yolov5](https://github.com/ultralytics/yolov5)
- 3.4.2 yolov5训练函数说明
- 3.4.3 固定随机种子,设置超参数
- 3.4.4 启动wandb跟踪训练结果
- 四、 yolov5训练
-
- 4.1 yolov5s训练
-
- 4.1.1 VOC.yaml训练20个epoch
- 3.5.2 训练结果可视化
- 4.1.2 Objects365.yamll训练20个epoch,结果有提升
- 4.1.3 其它尝试:平衡明暗度
- 4.2 yolov5x训练
-
- 4.2.1 训练100个epoch
- 4.2.2 其它尝试
- 4.3 从头训练
-
- 4.3.1 yolov5l从头训练,hyp.scratch-med
- 4.3.1 yolov5l从头训练,hyp.scratch-low
- 3.7 测试集推理
-
- 3.7.1 测试集上推理
- 3.7.2 生成比赛结果
- 四、训练PASCL VOC2012数据集(以前写的教程,可以不看,数据预处理写的太麻烦了)
-
- 4.1 下载数据集和yolov5
-
- 4.1.1 安装yolov5并下载VOC2012数据集
- 4.1.2 将VOC标注数据转为YOLO标注数据
- 4.1.3 根据摆放好的数据集信息生成一系列相关准备文件
- 4.2 修改配置文件
-
- 4.2.1 修改coco.yaml文件
- 4.2.2 修改yolov5s.yaml
- 4.2.3 修改train.py
- 4.2.4 PyYAML报错
- 4.3 开始训练
-
- 4.3.1 开始训练
- 4.3.2 voc2coco数据转换脚本`trans_voc2yolo.py`、`calculate_dataset.py`和`pascal_voc_classes.json`
零、 前言
- 最近用了paddledetection和yolov5,感觉差的不是一星半点。还是PyTorch框架好用,暂时不想再碰paddle了。
- 钢铁缺陷检测赛,没注意数据格式问题,最后提交结果折腾了快一天,坑。
- 我这两天用yolov3_spp训练过VOC2012数据集的,本来想直接拿过来用yolov5训练,但是colab挂载device太慢了。复制过来后(在colab主界面直接拖动文件夹,而不是在本ipynb脚本里用cp命令复制,否则复制都很久)yolov5运行时要scan数据集,scan train文件夹要一个小时,太慢了(之前yolov3_spp 在voc数据集用trans_voc2yolo.py转换为coco数据集也是用了两个小时)。
- 实在忍不了,看csdn帖子也抱怨这个,准备tar打包复制到drive外面,但是打包还是慢啊,干脆再下载数据集自己转化一次好了
yolov5-github地址
一、YOLOv5 Train Custom Data 教程
在yolov5的《Train Custom Data》教程里,有完整的示例代码,这里简单介绍下。
1.1 推理
detect.py 可以在各种数据集上运行YOLOv5来做推理, 从最新的 YOLOv5 版本 自动下载模型,并将结果保存到 runs/detect,示例如下:
!python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images
#display.Image(filename='runs/detect/exp/zidane.jpg', width=600)
1.2 验证精度
在 COCO val或test-dev 数据集上验证模型的准确性。 模型会从最新的YOLOv5版本自动下载。要按class显示结果,请使用 --verbose 标志。
Download COCO val 2017 dataset (1GB - 5000 images), and test model accuracy.
# Download COCO val
torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip')
!unzip -q tmp.zip -d ../datasets && rm tmp.zip
# Run YOLOv5x on COCO val
!python val.py --weights yolov5x.pt --data coco.yaml --img 640 --iou 0.65 --half
1.3 COCO 测试
下载COCO test2017数据集 (7GB - 40,000张图片), 在test-dev上测试模型精度(20,000张图片,无标签). 结果保存为一个*.json文件,这个文件会压缩并提交到https://competitions.codalab.org/competitions/20794 上的评估器。
# Download COCO test-dev2017
torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017labels.zip', 'tmp.zip')
!unzip -q tmp.zip -d ../datasets && rm tmp.zip
!f="test2017.zip" && curl http://images.cocodataset.org/zips/$f -o $f && unzip -q $f -d ../datasets/coco/images
# Run YOLOv5x on COCO test
!python val.py --weights yolov5x.pt --data coco.yaml --img 640 --iou 0.65 --half --task test
1.4 训练demo
在COCO128数据集上用 --data coco128.yaml训练一个yolov5模型, --weights yolov5s.pt来使用预训练权重, 或者用--weights '' --cfg yolov5s.yaml.来随机初始化权重(不推荐)。
- 预训练Models 从最新版本YOLOv5自动下载
- 可自动下载的Datasets 包括: COCO, COCO128, VOC, Argoverse, VisDrone, GlobalWheat, xView, Objects365, SKU-110K.
- 训练结果 保存到
runs/train/,例如runs/train/exp2,runs/train/exp3等。 - 下面会启动tensorboard和ClearML跟踪训练。ClearML安装运行
clearml-init后会连接到一个ClearML服务器,此时会弹出一个窗口,需要用户凭证。点击你自己的开源服务器,按Create new credentials新建项目,然后弹出窗口点击复制信息,复制到刚才弹出的窗口就行。后面还会弹出三个窗口,全部回车确认就行,这样ClearML就启动成功了。 - ClearML不启动
--data coco128.yaml训练会报错,估计可以改配置取消,还没有仔细看。
# 启动tensorboard
%load_ext tensorboard
%tensorboard --logdir runs/train
# ClearML (optional)
%pip install -q clearml
!clearml-init
运行显示如下:
ClearML SDK setup process
Please create new clearml credentials through the settings page in your `clearml-server` web app (e.g. http://localhost:8080//settings/workspace-configuration)
Or create a free account at https://app.clear.ml/settings/workspace-configuration
In settings page, press "Create new credentials", then press "Copy to clipboard".
Paste copied configuration here:
Detected credentials key="XXXX" secret="1gq6***"
WEB Host configured to: [https://app.clear.ml] #此处弹出窗口直接回车确认,下面两个也是
API Host configured to: [https://api.clear.ml]
File Store Host configured to: [https://files.clear.ml]
ClearML Hosts configuration:
Web App: https://app.clear.ml
API: https://api.clear.ml
File Store: https://files.clear.ml
Verifying credentials ...
Credentials verified!
New configuration stored in /root/clearml.conf
ClearML setup completed successfully.
# Weights & Biases (optional)
"""这步一运行colab就断了。所以我直接跳过,训练正常进行"""
%pip install -q wandb
import wandb
wandb.login()
# Train YOLOv5s on COCO128 for 3 epochs
!python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt --cache
1.5 可视化
1.5.1 ClearML 日志记录和自动化 NEW
ClearML 完全集成到 YOLOv5 中,以跟踪您的实验、管理数据集版本,甚至远程执行训练运行。启用ClearML运行(使用你自己的开源服务器,或者我们免费托管的服务器):
pip install clearml
clearml-init #连接到一个ClearML服务器
您可以使用 ClearML Data 对数据集进行版本控制,然后只需使用其唯一 ID 将其传递给 YOLOv5。这将帮助您跟踪数据,而不会增加额外的麻烦。查看ClearML Tutorial获取详细信息。
1.5.2 wandb记录权重&偏差
Weights & Biases (W&B) 与 YOLOv5 集成,用于训练运行的实时可视化和云记录。这样可以更好的运行比较和自省,以及提高团队的可见性和协作。 pip install wandb来启用W&B,然后正常训练(首次使用时将指导您进行设置)。
训练期间可以在https://wandb.ai/home看到实时更新。 并且您可以创建和分享您的详细 Result Reports。更多详情请查看YOLOv5 Weights & Biases Tutorial。
1.5.3 Local Logging
训练结果使用Tensorboard 和CSV 记录器自动记录到runs/train, 为每一次新的训练创建一个新的目录,如runs/train/exp2,runs/train/exp3等。
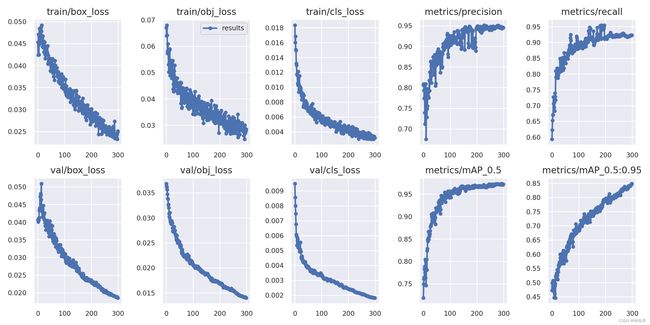
这个目录包括训练和验证统计,mosaics,labels,predictions and mosaics数据增强,以及包括precision-recall (PR)曲线和混淆矩阵这些指标和图表。
结果文件results.csv在每个epoch后更新,然后results.png在训练完成后绘制为(下图)。您还可以results.csv手动绘制任何文件:
from utils.plots import plot_results
plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'
1.6 使用Roboflow训练自定义数据 NEW
Roboflow 能使你在自己的数据集上轻松地组织,标记,和预处理一个高质量的数据集. Roboflow也能够轻松地建立一个active learning pipeline, 与您的团队协作改进数据集,并使用roboflow pip包直接集成到您的模型构建工作流程中。
自定义训练示例: How to Train YOLOv5 On a Custom Dataset
自定义训练Notebook: Open In Colab
二、Kaggle——海星目标检测比赛
参考我另一篇帖子《Kaggle——海星目标检测比赛》
三、paddle学习赛——钢铁目标检测(VOC数据集转yolo格式)
参考《飞桨新人赛:钢铁缺陷检测挑战赛-第2名方案》、《『浙大软院夏令营』-钢铁缺陷检测》、《飞桨新人赛:钢铁缺陷检测挑战赛-第3名方案》。
3.1 赛事简介
- 比赛地址:https://aistudio.baidu.com/aistudio/competition/detail/114/0/introduction
- 赛题介绍:本次比赛为图像目标识别比赛,要求参赛选手识别出钢铁表面出现缺陷的位置,并给出锚点框的坐标,同时对不同的缺陷进行分类。
- 数据简介:本数据集来自NEU表面缺陷检测数据集,收集了6种典型的热轧带钢表面缺陷,即氧化铁皮压入(RS)、斑块(Pa)、开裂(Cr)、点蚀(PS)、夹杂(In)和划痕(Sc)。下图为六种典型表面缺陷的示例,每幅图像的分辨率为200 * 200像素。
- 训练集图片1400张,测试集图片400张
提交内容及格式:
- 结果文件命名:submission.csv(否则无法成功提交)
- 结果文件格式:.csv(否则无法成功提交)
- 结果文件内容:submission.csv结果文件需包含多行记录,每行包括4个字段,内容示例如下:
image_id bbox category_id confidence
1400 [0, 0, 0, 0] 0 1
各字段含义如下:
- image_id(int): 图片id
- bbox(list[float]): 检测框坐标(XMin, YMin, XMax, YMax)
- category_id: 缺陷所属类别(int),类别对应字典为:{‘ crazing’:0,’inclusion’:1, ’pitted_surface’:2, ,’scratches’:3,’patches’:4,’rolled-in_scale’:5}
- confidence(float): 置信度
备注: 每一行记录1个检测框,并给出对应的category_id;同张图片中检测到的多个检测框,需分别记录在不同的行内。
3.2 导入相关库
import numpy as np
from tqdm.notebook import tqdm
tqdm.pandas()
import pandas as pd
import os
import cv2
import matplotlib.pyplot as plt
import glob
import shutil
import sys
sys.path.append('../input/paddleirondetection')
from joblib import Parallel, delayed
from IPython.display import display
3.3 数据预处理
3.3.1 将数据集移动到work下的dataset文件夹
- 此时路径为输出文件夹根目录,即
/kaggle/working - 新建dataset文件夹,将原训练集图片移动到dataset下,重命名为images
- 原xml标注文件移动到dataset下,重命名为Annotations
- 测试集移动到dataset
!mkdir dataset
!cp -r ../input/paddleirondetection/test/test dataset
!cp -r ../input/paddleirondetection/train/train/IMAGES dataset # 直接在
!cp -r ../input/paddleirondetection/train/train/ANNOTATIONS dataset
!mv ./dataset/ANNOTATIONS ./dataset/Annotations
!mv ./dataset/IMAGES ./dataset/images
!ls dataset/images
3.3.2 用pandas处理图片名和xml文件名
# 遍历图片和标注文件夹,将所有文件后缀正确的文件添加到列表中
import os
import pandas as pd
ls_xml,ls_image=[],[]
for xml in os.listdir('../input/paddleirondetection/train/train/ANNOTATIONS'):
if xml.split('.')[1]=='xml':
ls_xml.append(xml)
for image in os.listdir('../input/paddleirondetection/train/train/IMAGES'):
if image.split('.')[1]=='jpg':
ls_image.append(image)
df=pd.DataFrame(ls_image,columns=['image'])
df.sort_values('image',inplace=True)
df=df.reset_index(drop=True)
s=pd.Series(ls_xml).sort_values().reset_index(drop=True)
df['xml']=s
df.head(3)
image xml
0 0.jpg 0.xml
1 1.jpg 1.xml
2 10.jpg 10.xml
写入label_list.txt文件,echo -e表示碰到转义符('\n’等)按对应特殊字符处理。(这个是以前VOC数据集用的,可忽略)
!echo -e "crazing\ninclusion\npitted_surface\nscratches\npatches\nrolled-in_scale" > dataset/label_list.txt
!cat dataset/label_list.txt
crazing
inclusion
pitted_surface
scratches
patches
rolled-in_scale
3.3.3 生成yolov5格式的标注文件
- rootpath是Annotations的上一个目录
- main函数中的list可以从目录读取,也可以从df读取
- list=df.xml.values
- list=os.listdir(xmlpath)
- voc格式数据集标注框是以
[xmin,ymin,xmax,ymax]表示 - 最终在dataset/labels文件夹下,生成的txt标注文件格式是:
cls,[x_center,y_center,w,h],且是归一化之后的结果。(将x_center和标注框宽度w除以图像宽度,将y_center与标注框高度h除以图像高度。这样xywh的值域都是[0,1])
5 0.6075 0.14250000000000002 0.775 0.165
5 0.505 0.6825 0.79 0.525
以下转换代码来自github上的objectDetectionDatasets项目:
#!pip install mmcv
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
classes = ['crazing','inclusion','pitted_surface','scratches','patches','rolled-in_scale']
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
if w>=1:
w=0.99
if h>=1:
h=0.99
return (x,y,w,h)
def convert_annotation(rootpath,xmlname):
xmlpath = rootpath + '/Annotations'
xmlfile = os.path.join(xmlpath,xmlname)
with open(xmlfile, "r", encoding='UTF-8') as in_file:
txtname = xmlname[:-4]+'.txt' # 生成对应的txt文件名
print(txtname)
txtpath = rootpath + '/labels' # 生成的.txt文件会被保存在worktxt目录下
if not os.path.exists(txtpath):
os.makedirs(txtpath)
txtfile = os.path.join(txtpath,txtname)
with open(txtfile, "w+" ,encoding='UTF-8') as out_file:
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
out_file.truncate()
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
rootpath='dataset'
xmlpath=rootpath+'/Annotations'
list=df.xml.values
for i in range(0,len(list)) :
path = os.path.join(xmlpath,list[i]) # 判断Annotations下是否是xml文件或XML文件
if ('.xml' in path)or('.XML' in path):
convert_annotation(rootpath,list[i])
print('done', i)
else:
print('not xml file',i)
!cat dataset/labels/0.txt
5 0.6075 0.14250000000000002 0.775 0.165
5 0.505 0.6825 0.79 0.525
!ls ../dataset
Annotations images label_list.txt labels test
3.4 使用yolov5进行训练
3.4.1 安装yolov5
安装完之后路径是working/yolov5
!git clone https://github.com/ultralytics/yolov5 # clone
%cd yolov5
%pip install -qr requirements.txt # install
from yolov5 import utils
display = utils.notebook_init() # check
YOLOv5 v6.2-181-g8a19437 Python-3.7.12 torch-1.11.0 CUDA:0 (Tesla P100-PCIE-16GB, 16281MiB)
Setup complete ✅ (2 CPUs, 15.6 GB RAM, 3884.4/4030.6 GB disk)
3.4.2 yolov5训练函数说明
- 生成train.txt和val.txt
gbr.yaml内容为:yaml: names: - crazing - inclusion - pitted_surface - scratches - patches - rolled-in_scale nc: 6 path: /kaggle/working/ # dataset的上一级目录,绝对路径 train: /kaggle/working/train.txt # train.txt绝对路径,好像也可以用相对路径 val: /kaggle/working/val.txt- train.txt是划分好的训练集图片的相对地址(相对于path的地址)
with open('dataset/label_list.txt','r') as file:
labels=[x.split('\n')[0] for x in file.readlines()]
labels
['crazing',
'inclusion',
'pitted_surface',
'scratches',
'patches',
'rolled-in_scale']
- 生成gbr.yaml,用于训练时指定数据读取
import yaml
shuffle_df=df.sample(frac=1)
train_df=shuffle_df[:1200]
val_df=shuffle_df[1200:]
cwd='/kaggle/working/' # 数据集(dataset)的上一级目录
with open(os.path.join( cwd ,'train.txt'), 'w') as f:
for path in train_df.image.tolist():
f.write('./dataset/images/'+path+'\n') # txt文件写的是图片相对于cwd的地址
with open(os.path.join(cwd , 'val.txt'), 'w') as f:
for path in val_df.image.tolist():
f.write('./dataset/images/'+path+'\n')
with open(os.path.join( cwd ,'trainval.txt'), 'w') as f:
for path in df.image.tolist():
f.write('./dataset/images/'+path+'\n') # txt文件写的是图片相对于cwd的地址
data = dict(
path = '/kaggle/working/',
train = os.path.join( cwd , 'train.txt') ,
val = os.path.join( cwd , 'val.txt' ),
nc = 6,
names = labels,
)
with open(os.path.join( cwd , 'gbr.yaml'), 'w') as outfile:
yaml.dump(data, outfile, default_flow_style=False)
f = open(os.path.join( cwd , 'gbr.yaml'), 'r')
print('\nyaml:')
print(f.read())
!head -n 3 ../train.txt
输出结果:
yaml:
names:
- crazing
- inclusion
- pitted_surface
- scratches
- patches
- rolled-in_scale
nc: 6
path: /kaggle/working/
train: /kaggle/working/train.txt
val: /kaggle/working/val.txt
./dataset/images/354.jpg
./dataset/images/13.jpg
./dataset/images/1395.jpg
3.4.3 固定随机种子,设置超参数
import torch
def set_seeds(seed):
torch.manual_seed(seed) # 固定随机种子(CPU)
if torch.cuda.is_available(): # 固定随机种子(GPU)
torch.cuda.manual_seed(seed) # 为当前GPU设置
torch.cuda.manual_seed_all(seed) # 为所有GPU设置
np.random.seed(seed) # 保证后续使用random函数时,产生固定的随机数
torch.backends.cudnn.deterministic = True # 固定网络结构
set_seeds(106)
# 这么写是后面设置wandb输出文件夹时懒得复制一遍PROJECT和NAME,其实也可以不写这一段
DIM = 256 # img_size
MODEL = 'yolov5s6'
PROJECT = 'paddle-iron-detection' # w&b in yolov5
NAME = f'{MODEL}-dim{DIM}-epoch{EPOCHS}' # w&b for yolov5
NAME
'yolov5s6-dim224-epoch20'
3.4.4 启动wandb跟踪训练结果
- 可使用github账号注册wandb,点击右上角自己的头像,下拉菜单中选择settings,在设置页下面可以看到API keys
!wandb.login(key=api_key)可直接启动wandb,- 也可以将API keys添加到kaggle的notebook中,这样每次启动wandb时就不用复制API keys了。方法如下:
- 在notebook上方菜单栏Add-ons添加Secrets:(label写WANDB,value就是你的API keys)
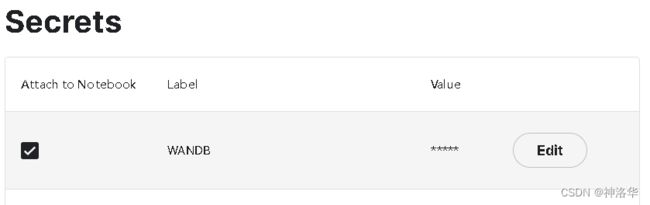
- 输入以下代码启动wandb:(因为API keys加了入环境里面,所以提示你不要分享代码)
- 在notebook上方菜单栏Add-ons添加Secrets:(label写WANDB,value就是你的API keys)
import wandb
try:
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
api_key = user_secrets.get_secret("WANDB")
wandb.login(key=api_key)
anonymous = None
except:
wandb.login(anonymous='must')
print('To use your W&B account,\nGo to Add-ons -> Secrets and provide your W&B access token. Use the Label name as WANDB. \nGet your W&B access token from here: https://wandb.ai/authorize')
wandb: WARNING If you're specifying your api key in code, ensure this code is not shared publicly.
wandb: WARNING Consider setting the WANDB_API_KEY environment variable, or running `wandb login` from the command line.
wandb: Appending key for api.wandb.ai to your netrc file: /root/.netrc
四、 yolov5训练
4.1 yolov5s训练
4.1.1 VOC.yaml训练20个epoch
(实验发现img=256比默认640效果更好)
!python train.py --img 256 --batch 16 --epochs 20 --optimizer Adam \
--data ../gbr.yaml --hyp data/hyps/hyp.VOC.yaml\
--weights yolov5s.pt --project {project} --name {name}
Model summary: 157 layers, 7026307 parameters, 0 gradients, 15.8 GFLOPs
Class Images Instances P R mAP50 mAP50-95: 100% 7/7 [00:02<00:00, 3.08it/s]
all 200 420 0.644 0.672 0.689 0.321
crazing 200 83 0.515 0.325 0.361 0.112
inclusion 200 90 0.604 0.711 0.755 0.349
pitted_surface 200 48 0.829 0.792 0.8 0.415
scratches 200 59 0.828 0.831 0.9 0.398
patches 200 64 0.65 0.953 0.91 0.483
rolled-in_scale 200 76 0.436 0.421 0.408 0.17
Results saved to paddle-iron-detection/yolov5s6-dim224-epoch20
3.5.2 训练结果可视化
这些训练结果都代表啥,可以查看《yolov5 训练结果解析》
- 查看训练结果
import pandas as pd
result=pd.read_csv('paddle-iron-detection/yolov5s6-dim224-epoch20/results.csv')
result
- 打开wandb网站,查看试验跟踪结果:
点击wandb主页面,选择project下面自己的项目
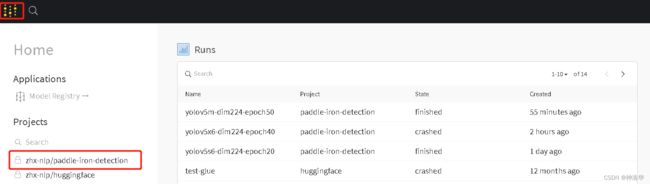
点进去就可以看到下面这张图:(loss result)
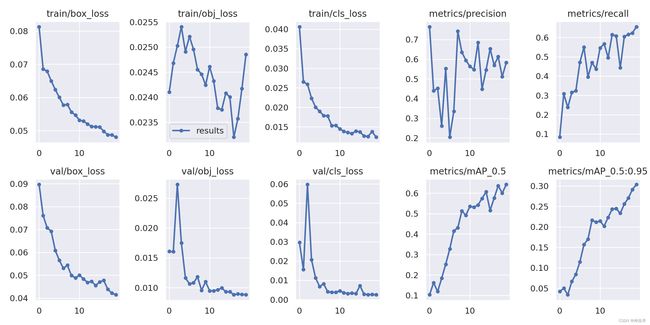
如果在主页点进去某一个runs
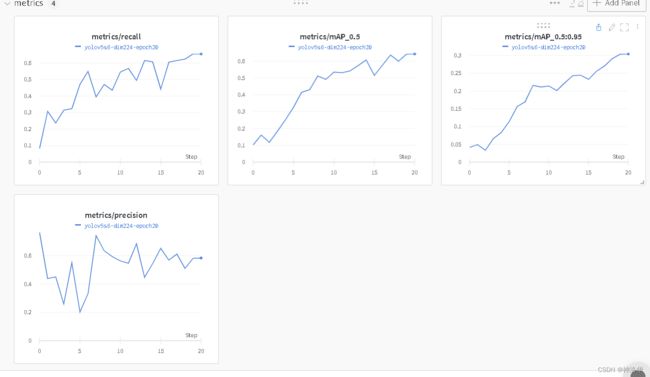
就无法显示上面的图片,只有这个runs的结果,比如metirc:
- 设定wandb输出文件夹,用于可视化展示
OUTPUT_DIR = '{}/{}'.format(PROJECT, NAME)
!ls {OUTPUT_DIR}
F1_curve.png results.png
PR_curve.png train_batch0.jpg
P_curve.png train_batch1.jpg
R_curve.png train_batch2.jpg
confusion_matrix.png val_batch0_labels.jpg
events.out.tfevents.1664736500.2cd00906b272.888.0 val_batch0_pred.jpg
hyp.yaml val_batch1_labels.jpg
labels.jpg val_batch1_pred.jpg
labels_correlogram.jpg val_batch2_labels.jpg
opt.yaml val_batch2_pred.jpg
results.csv weights
- 查看类别分布:
# 这是另一个比赛的图,仅做展示。这个cells的输出我删了,懒得再跑一次了
plt.figure(figsize = (10,10))
plt.axis('off')
plt.imshow(plt.imread(f'{OUTPUT_DIR}/labels_correlogram.jpg'));
- 查看3个bacth的图片:
# Wandb界面的Mosaics(yolov5s6-dim3000-fold1)
import matplotlib.pyplot as plt
plt.figure(figsize = (10, 10))
plt.imshow(plt.imread(f'{OUTPUT_DIR}/train_batch0.jpg'))
plt.figure(figsize = (10, 10))
plt.imshow(plt.imread(f'{OUTPUT_DIR}/train_batch1.jpg'))
plt.figure(figsize = (10, 10))
plt.imshow(plt.imread(f'{OUTPUT_DIR}/train_batch2.jpg'))



- 真实框和预测框对比:
fig, ax = plt.subplots(3, 2, figsize = (2*9,3*5), constrained_layout = True)
for row in range(3):
ax[row][0].imshow(plt.imread(f'{OUTPUT_DIR}/val_batch{row}_labels.jpg'))
ax[row][0].set_xticks([])
ax[row][0].set_yticks([])
ax[row][0].set_title(f'{OUTPUT_DIR}/val_batch{row}_labels.jpg', fontsize = 12)
ax[row][1].imshow(plt.imread(f'{OUTPUT_DIR}/val_batch{row}_pred.jpg'))
ax[row][1].set_xticks([])
ax[row][1].set_yticks([])
ax[row][1].set_title(f'{OUTPUT_DIR}/val_batch{row}_pred.jpg', fontsize = 12)
plt.show()
可以看到,还是有很多没预测出来,也有一些预测框有偏差的。
4.1.2 Objects365.yamll训练20个epoch,结果有提升
Model summary: 157 layers, 7026307 parameters, 0 gradients, 15.8 GFLOPs
Class Images Instances P R mAP50 mAP50-95: 100% 7/7 [00:02<00:00, 2.80it/s]
all 200 420 0.694 0.728 0.745 0.381
crazing 200 83 0.498 0.359 0.391 0.125
inclusion 200 90 0.638 0.706 0.761 0.371
pitted_surface 200 48 0.881 0.792 0.829 0.468
scratches 200 59 0.854 0.894 0.95 0.511
patches 200 64 0.775 0.984 0.947 0.563
rolled-in_scale 200 76 0.518 0.632 0.592 0.247
4.1.3 其它尝试:平衡明暗度
观察发现,数据集明暗程度相差很多,利用直方图均衡化,平衡图像的明暗度。
# 处理测试集图片
test_path = '../dataset/test/IMAGES'
test_path1 = test_path+'_equ'
os.makedirs(test_path1,exist_ok=1)
for i in os.listdir(test_path):
underexpose = cv2.imread(os.path.join(test_path,i))
equalizeUnder = np.zeros(underexpose.shape, underexpose.dtype)
equalizeUnder[:, :, 0] = cv2.equalizeHist(underexpose[:, :, 0])
equalizeUnder[:, :, 1] = cv2.equalizeHist(underexpose[:, :, 1])
equalizeUnder[:, :, 2] = cv2.equalizeHist(underexpose[:, :, 2])
cv2.imwrite(os.path.join(test_path1,i),equalizeUnder)
# 处理训练集图片
train_path = '../dataset/images'
train_path1 = test_path+'_equ'
os.makedirs(train_path1,exist_ok=1)
for i in os.listdir(train_path):
underexpose = cv2.imread(os.path.join(train_path,i))
equalizeUnder = np.zeros(underexpose.shape, underexpose.dtype)
equalizeUnder[:, :, 0] = cv2.equalizeHist(underexpose[:, :, 0])
equalizeUnder[:, :, 1] = cv2.equalizeHist(underexpose[:, :, 1])
equalizeUnder[:, :, 2] = cv2.equalizeHist(underexpose[:, :, 2])
cv2.imwrite(os.path.join(train_path1,i),equalizeUnder)
# 将处理后的训练集和测试集、标注文件夹、labels文件夹都移动到新文件夹dataset_equ
!mkdir ../dataset_equ
# 移动训练集
!mv ../dataset/images_equ/ ../dataset_equ
!mv ../dataset/test/IMAGES_equ/ ../dataset_equ
# 移动测试集
!mv ../dataset_equ/images_equ ../dataset_equ/images
# 移动标注文件,其实是voc格式的标注,已经没用了
!mv ../dataset/Annotations ../dataset_equ
# 移动lables
!cp -r ../dataset/labels ../dataset_equ
!ls ../dataset_equ
移动完后,需要重新写一下gbr.yaml文件
import yaml
cwd='/kaggle/working/' # 数据集(dataset)的上一级目录
with open(os.path.join(cwd,'train_equ.txt'), 'w') as f:
for path in train_df.image.tolist():
f.write('./dataset_equ/images/'+path+'\n') # txt文件写的是图片相对于cwd的地址
with open(os.path.join(cwd ,'val_equ.txt'), 'w') as f:
for path in val_df.image.tolist():
f.write('./dataset_equ/images/'+path+'\n')
data = dict(
path = '/kaggle/working/',
train = os.path.join(cwd,'train_equ.txt') ,
val = os.path.join(cwd,'val_equ.txt' ),
nc = 6,
names = labels,
)
with open(os.path.join( cwd , 'gbr_equ.yaml'), 'w') as outfile:
yaml.dump(data, outfile, default_flow_style=False)
f = open(os.path.join( cwd , 'gbr_equ.yaml'), 'r')
print('\nyaml:')
print(f.read())
!head -n 3 ../train_equ.txt
!python train.py --img 256 --batch 16 --epochs 20 --optimizer Adam \
--data ../gbr_equ.yaml --hyp data/hyps/hyp.Objects365.yaml\
--weights yolov5s.pt --project {project} --name yolov5s-obj-adam20-equ
结果并不好:
Class Images Instances P R mAP50 mAP50-95: 100% 7/7 [00:02<00:00, 2.66it/s]
all 200 420 0.57 0.648 0.651 0.328
crazing 200 83 0.472 0.265 0.329 0.105
inclusion 200 90 0.543 0.711 0.705 0.328
pitted_surface 200 48 0.685 0.816 0.832 0.527
scratches 200 59 0.761 0.701 0.787 0.377
patches 200 64 0.644 0.922 0.898 0.522
rolled-in_scale 200 76 0.314 0.474 0.354 0.109
4.2 yolov5x训练
4.2.1 训练100个epoch
PROJECT = 'paddle-iron-detection' # w&b in yolov5
!python train.py --img 256 --data ../gbr.yaml --hyp data/hyps/hyp.Objects365.yaml\
--weights yolov5x.pt --project {project} --name yolov5x-default \
--patience 20 --epoch 100 --cache
patience20表示20个epoch内模型都没有优化就会停止训练。cache表示图片会先加载到内存再训练,可以加快训练速度。
训练花了一小时,第98个epoch效果最好,提升了一点。
Class Images Instances P R mAP50 mAP50-95: 100% 7/7 [00:03<00:00, 2.24it/s]
all 200 420 0.765 0.753 0.794 0.445
crazing 200 83 0.509 0.449 0.455 0.163
inclusion 200 90 0.709 0.8 0.85 0.456
pitted_surface 200 48 0.923 0.833 0.883 0.541
scratches 200 59 0.945 0.873 0.975 0.536
patches 200 64 0.845 0.969 0.941 0.672
rolled-in_scale 200 76 0.659 0.592 0.662 0.301
- 直接推理提交,结果是score=36(没有用augment)
- 加入验证集,lr=0.1*lr,训练20epoch,每个epoch都保存模型(gbr_all.yaml就是把train.txt换成trainval.txt)
!python train.py --img 256 --data ../gbr_all.yaml --hyp data/hyps/hyp.Objects365.yaml\
--weights paddle-iron6/yolov5x-default/weights/best.pt --project {project} --name yolov5x-120 \
--epoch 20 --save-period 1
第19个epoch效果最好,进行推理,提交后分数37.74。
!python detect.py --weights paddle-iron6/yolov5x-1203/weights/best.pt --augment\
--img 256 --conf 0.3 --source ../dataset/test/IMAGES --save-txt --save-conf
4.2.2 其它尝试
- 修改错误标签
标注图片剪裁之后查看,发现有些标签应该是标注错误,在对应的txt文件里修改后训练,效果更差。(不明白为啥还变差了)
import xml.etree.ElementTree as ET
from pathlib import Path
import random
# 原图片、标签文件、裁剪图片路径
img_path = 'dataset/IMAGES'
xml_path = 'train/ANNOTATIONS'
obj_img_path = 'train/clip'
if os.path.exists(obj_img_path) :
print(f'{obj_img_path} is exist')
else:
os.mkdir(obj_img_path) # 裁剪目录要先创建,不然后面在此目录接着创建子目录会报错
# 声明一个空字典用于储存裁剪图片的类别及其数量
clip= {}
# 把原图片裁剪后,按类别新建文件夹保存,并在该类别下按顺序编号
for img_file in os.listdir(img_path):
if img_file[-4:] in ['.png', '.jpg']: # 判断文件是否为图片格式
img_filename = os.path.join(img_path, img_file) # 将图片路径与图片名进行拼接,例如‘train/IMAGES\0.jpg’
img_cv = cv2.imread(img_filename) # 读取图片
img_name = (os.path.splitext(img_file)[0]) # 图片索引,如“000.png” 图片名为“000”
xml_name = xml_path + '\\' + '%s.xml' % img_name # 完整的标签路径名,例如‘train/ANNOTATIONS\0.xml’
if os.path.exists(xml_name): # 判断与图片同名的标签是否存在,因为图片不一定每张都打标
root = ET.parse(xml_name).getroot() # 利用ET读取xml文件
for obj in root.iter('object'): # 遍历所有目标框
name = obj.find('name').text # 获取目标框名称,即label名
xmlbox = obj.find('bndbox') # 找到框目标
x0 = xmlbox.find('xmin').text # 将框目标的四个顶点坐标取出
y0 = xmlbox.find('ymin').text
x1 = xmlbox.find('xmax').text
y1 = xmlbox.find('ymax').text
obj_img = img_cv[int(y0):int(y1), int(x0):int(x1)] # cv2裁剪出目标框中的图片
clip.setdefault(name, 0) # 判断字典中有无当前name对应的类别,无则新建
clip[name] += 1 # 当前类别对应数量 + 1
my_file = Path(obj_img_path + '/' + name) # 判断当前name对应的类别有无文件夹
if 1 - my_file.is_dir(): # 无则新建
os.mkdir(str(obj_img_path + '/' + str(name)))
# 保存裁剪图片,图片命名4位,不足补0
#cv2.imwrite(obj_img_path + '/' + name + '/' + '%04d' % (clip[name]) + '.jpg',obj_img) # 按顺序命名裁剪图片
# 裁剪图片名为原图片名+顺序名
cv2.imwrite(obj_img_path + '/' + name + '/' + img_name+'_'+ '%04d' % (clip[name])+'.jpg',obj_img)

可以明显看到有些标签是错的。
- 多尺度训练(设置
--multi-scale),结果变差了
多尺度训练是指设置几种不同的图片输入尺度,训练时每隔一定iterations随机选取一种尺度训练,能够在一定程度上提高检测模型对物体大小的鲁棒性。 - 启用加权图像策略(
--image-weights),结果也变差了。
主要是为了解决样本不平衡问题。开启后会对于上一轮训练效果不好的图片,在下一轮中增加一些权重 - 在100epoch基础上,只训练0和5这两类物体。
0和5这两类错误率太高,重新读取标注的txt文件,只选取有0或者5这两类的图片进行训练,且标注的txt文件,去掉它标注框。结果训练不理想,感觉是哪里写错了。
4.3 从头训练
4.3.1 yolov5l从头训练,hyp.scratch-med
!python train.py --img 256 --batch 16 --epochs 50 --weights=None\
--data /kaggle/working/gbr.yaml --hyp data/hyps/hyp.scratch-med.yaml\
--project kaggle-iron --name yolov5l-scratch --cfg models/yolov5l.yaml
YOLOv5l summary: 267 layers, 46135203 parameters, 0 gradients, 107.7 GFLOPs
Class Images Instances P R mAP50
all 200 473 0.573 0.672 0.67 0.323
crazing 200 66 0.433 0.227 0.324 0.0922
inclusion 200 127 0.647 0.748 0.741 0.325
pitted_surface 200 33 0.674 0.727 0.759 0.475
scratches 200 68 0.519 0.809 0.745 0.303
patches 200 120 0.738 0.925 0.924 0.535
rolled-in_scale 200 59 0.424 0.598 0.525 0.21
4.3.1 yolov5l从头训练,hyp.scratch-low
YOLOv5l summary: 267 layers, 46135203 parameters, 0 gradients, 107.7 GFLOPs
Class Images Instances P R mAP50
all 200 473 0.703 0.679 0.732 0.358
crazing 200 66 0.793 0.303 0.511 0.162
inclusion 200 127 0.671 0.756 0.755 0.349
pitted_surface 200 33 0.737 0.697 0.741 0.446
scratches 200 68 0.626 0.824 0.84 0.395
patches 200 120 0.853 0.917 0.936 0.563
rolled-in_scale 200 59 0.537 0.576 0.606 0.229
3.7 测试集推理
《yolov5 --save-txt 生成的txt怎么设置为覆盖而不是追加到txt中》
3.7.1 测试集上推理
--save-txt --save-conf:表示预测结果保存为txt,且保存置信度分数
!python detect.py --weights paddle-iron-detection/yolov5m-dim224-epoch50/weights/best.pt\
--img 224 --conf 0.25 --source ../dataset/test/IMAGES --save-txt --save-conf
- 查看推理图片:
最终结果保存在
yolov5runs/detect下,每跑一次模型生成一个exp文件夹。我跑了三次,所以结果在runs/detect/exp3/,txt文件在runs/detect/exp3/labels
display.Image(filename='runs/detect/exp3/1401.jpg', width=300)

2. 查看推理结果(txt文件)
!cat runs/detect/exp3/labels/1401.txt
1 0.7825 0.5775 0.205 0.775 0.478262
- yolo中txt文件的说明:
YOLO模型,会直接把每张图片标注的标签信息保存到一个txt文件中。txt信息说明:- 每个txt是一张图片的预测结果,txt文件中每一行是一个标注框
- 默认只有class(以索引表示)和bbox坐标。bbox坐标格式是yolo格式,即
[x_center,y_center,w,h],且被归一化((将x_center和w除以图像宽度,将y_center与h除以图像高度。这样xywh的值域都是[0,1])) - 如果设置
-save-conf会在bbox后面保存置信度结果
3.7.2 生成比赛结果
需要按照题目要求的格式处理预测结果。
- 遍历txt文件,按格式读取到pandas
一开始没有注意数据格式问题,怎么保存csv bbox的逗号都没了,折腾了一天
import pandas as pd
import numpy as np
result_list = []
for name in os.listdir('dataset/test/IMAGES'): # 遍历测试集图片
idx=name.split('.')[0] # 图片索引
txt_name = 'uns/detect/exp3/labels/'+idx+'.txt'
try: # 如果这张图片有预测到结果,就写入以下信息
with open(txt_name, 'r') as f:
predicts = f.readlines() # 从txt文本读取的是字符串格式,要转为对应的数字格式
for predict in predicts:
pred=predict.split(' ')
cls=pred[0]
bbox=[float(x) for x in pred[1:5]]
score=pred[5].rstrip() # 去掉右侧换行符
result_list.append([idx,bbox,cls,score])
except: # 如果没有预测到检测框,就只返回idx
result_list.append([idx])
df= pd.DataFrame(result_list,columns=['image_id','bbox','category_id','confidence'])
df.head()
image_id bbox category_id confidence
0 1400 None None None
1 1401 [0.7825, 0.5775, 0.205, 0.775] 1 0.478262
2 1402 [0.785, 0.5, 0.42, 1] 2 0.419653
3 1402 [0.445, 0.4875, 0.84, 0.975] 2 0.437668
4 1403 [0.3675, 0.5, 0.165, 1] 3 0.765889
- 填补缺失值,有些图片没检测到,直接用前/后一个数据进行填充
# 第一张图可最后一张图都缺失,所以向前向后都填充一次
df=df.fillna(method='ffill')
df=df.fillna(method='bfill')
- 转换数据格式
# pd.to_numeric也可以将series里面可以转换为数字的值转为数字,不能转换的可以保留原格式/设为缺失值/报错
df.image_id=pd.to_numeric(df.image_id,errors='ignore')
df.category_id=df.category_id.astype('int')
df.confidence=df.confidence.astype('float')
df.info()
0 image_id 982 non-null int64
1 bbox 982 non-null object
2 category_id 982 non-null int32
3 confidence 982 non-null float64
dtypes: float64(1), int32(1), int64(1), object(1)
定义yolo2voc函数,用于将YOLO格式预测框转为比赛要的VOC格式
代码来自github上的bbox包,用法可参考《kaggle——海星目标检测比赛》帖子中的3.4章节:生成标注文件
# 打印可以看到测试集图片尺寸都是200,200
from PIL import Image
for i,name in enumerate(os.listdir('dataset/test/IMAGES')):
img_name='dataset/test/IMAGES/'+name
image = Image.open(img_name)
print(image.size)
def yolo2voc(bboxes, height=200, width=200):
"""
yolo => [xmid, ymid, w, h] (normalized)
voc => [x1, y1, x2, y1]
"""
# bboxes = bboxes.copy().astype(float) # otherwise all value will be 0 as voc_pascal dtype is np.int
bboxes[..., 0::2] *= width
bboxes[..., 1::2] *= height
bboxes[..., 0:2] -= bboxes[..., 2:4]/2
bboxes[..., 2:4] += bboxes[..., 0:2]
return bboxes
# yolog格式预测框转为voc格式预测框
df.bbox=df.bbox.apply(lambda x: yolo2voc(np.array(x).astype(np.float32)))
"""
转完格式后,bbox是array格式,直接保存csv文件,bbox这一列没有逗号,我也不知道为啥会这样,坑死我了
必须转为list格式,bbox在保存csv时,列表中才有逗号,不然就是[0.0 3.0 200.0 67.0]的格式
"""
df.bbox=df.bbox.apply(lambda x:list(x))
# 比赛提交的csv文件,不需要index,但必须有列名,否则报错异常
df.to_csv('submission.csv',index=None,header=None)
四、训练PASCL VOC2012数据集(以前写的教程,可以不看,数据预处理写的太麻烦了)
4.1 下载数据集和yolov5
4.1.1 安装yolov5并下载VOC2012数据集
#clone yolov5安装依赖
!git clone https://github.com/ultralytics/yolov5
%cd yolov5
!pip install -r requirements.txt
#在data目录下下载PASCAL VOC2012数据集并解压
!mkdir my_dataset
%cd my_dataset
!wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
!tar -xvf VOCtrainval_11-May-2012.tar
#切换回yolov5主目录
%cd ..
4.1.2 将VOC标注数据转为YOLO标注数据
- 将yolov3_spp的数据转换脚本
trans_voc2yolo.py、calculate_dataset.py、pascal_voc_classes.json都放在my_dataset文件夹下。 (文章最后会直接给出这几个脚本的代码) - 切换到yolov5项目主路径,运行
trans_voc2yolo.py脚本(注意原脚本里面root路径前面应该加一个点.,即’./my_dataset/VOCdevkit’) - 这一步主要是在
my_dataset文件夹下生成yolo格式数据集(my_yolo_dataset)以及my_data_label.names标签文件 - 注意,这一步需要
my_dataset文件夹下的pascal_voc_classes.json(label标签对应json文件)
├── my_yolo_dataset 自定义数据集根目录
│ ├── train 训练集目录
│ │ ├── images 训练集图像目录
│ │ └── labels 训练集标签目录
│ └── val 验证集目录
│ ├── images 验证集图像目录
│ └── labels 验证集标签目录
- 生成的my_data_label.names标签文件格式如下:(如果没有该文件,可以自己手动编辑一个txt文档,然后重命名为.names格式即可)
aeroplane
bicycle
bird
boat
bottle
bus
...
import os
assert os.path.exists('my_dataset/VOCdevkit/VOC2012/JPEGImages')
#原脚本几处路径由data改为my_dataset
#更改coco数据集保存路径save_file_root = "./my_dataset/my_yolo_dataset"
!python my_dataset/trans_voc2yolo.py
translate train file...: 100% 5717/5717 [00:03<00:00, 1884.45it/s]
translate val file...: 100% 5823/5823 [00:03<00:00, 1799.45it/s]
4.1.3 根据摆放好的数据集信息生成一系列相关准备文件
- 使用calculate_dataset.py脚本生成my_train_data.txt文件、my_val_data.txt文件以及my_data.data文件,这里不需要并生成新的my_yolov3.cfg文件,相关代码注释掉就行
- 执行脚本前,需要根据自己的路径修改相关参数
- 生成的文件都在yolov5/my_dataset/my_yolo_dataset下
train_annotation_dir = "./my_yolo_dataset/train/labels"
val_annotation_dir = "./my_yolo_dataset/val/labels"
classes_label = "./my_data_label.names"
...
...
train_txt_path = "my_train_data.txt"
val_txt_path = "my_val_data.txt"
...
create_data_data("my_data.data", classes_label, train_txt_path, val_txt_path, classes_info)
%cd my_dataset
!python calculate_dataset.py
4.2 修改配置文件
4.2.1 修改coco.yaml文件
复制data下coco.yaml文件,重命名为myvoc2coco.yaml,打开修改路径和names
%cd ..
%cp data/coco.yaml data/myvoc2coco.yaml
/content/yolov5
#读取my_data_label.names文件,转为列表打印出来。这就是label_list,将myvoc2coco.yaml的names那一行内容改为这个label_list
ls=[]
with open('dataset/my_data_label.names','r') as f:
lines = f.readlines()
for line in lines:
line=line.strip("\n")#去除末尾的换行符
txt=str(line)#拆分为两个元素,再对每个元素实行类型转换
ls.append(txt)
print(ls)
['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
/myvoc2coco.yaml 修改如下:
path: my_dataset # dataset root dir
train: my_train_data.txt # train images
val: my_val_data.txt # val images
test: test-dev2017.txt #没有测试不需要改
# Classes
nc: 20 # number of classes
names: ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] # class names
4.2.2 修改yolov5s.yaml
将类别数nc=80改为20
4.2.3 修改train.py
上面两个修改之后,运行时还是会报错Overriding model.yaml nc=80 with nc=20。还是说模型中设定的分类类别与你自己在.yaml文件中配置的nc数值不匹配(明明yaml文件已经改了)
修改train.py,拉到下面
-
weights:初始化模型权重文件是yolov5s.pt
-
cfg:配置文件是默认为空,但看其help是help=‘model.yaml path’说明其是指向模型的.yaml文件的。所以这里改为’models/yolov5s.yaml’
-
data:是指数据的一些路径,类别个数和类别名称等设置,如coco128.yaml
-
hyp:是一些超参数的设置,如果你清楚的话,可以改动。
-
epochs:是训练的轮数,默认是300轮。
-
batch-size:每一批数据的多少,如果你的显存小,就将这个数值设置的小一点。
4.2.4 PyYAML报错
报错requirements: PyYAML>=5.3.1 not found and is required by YOLOv5, attempting auto-update... 以及
yaml.reader.ReaderError: unacceptable character #x1f680: special characters are not allowed
in "data/hyps/hyp.scratch-low.yaml", position 9
运行以下代码就行
!pip install --ignore-installed PyYAML
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting PyYAML
Using cached PyYAML-6.0-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_12_x86_64.manylinux2010_x86_64.whl (596 kB)
Installing collected packages: PyYAML
Successfully installed PyYAML-6.0
4.3 开始训练
4.3.1 开始训练
下面就可以开始愉快的训练啦。之前yolov3_spp训练3个epoch是30min左右,yolov5这次花了13min,快了一倍。(不知道跟colab有没有关系,官方说colab每次分配的GPU会不一样)
%cd ..
!python train.py --img 640 --batch 16 --epochs 3 --data myvoc2coco.yaml --weights yolov5s.pt
/content/yolov5
[34m[1mtrain: [0mweights=yolov5s.pt, cfg=models/yolov5s.yaml, data=myvoc2coco.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=3, batch_size=16, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs/train, name=exp, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest
[34m[1mgithub: [0mup to date with https://github.com/ultralytics/yolov5 ✅
YOLOv5 v6.1-383-g3d47fc6 Python-3.7.13 torch-1.12.0+cu113 CUDA:0 (Tesla T4, 15110MiB)
[34m[1mhyperparameters: [0mlr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
[34m[1mWeights & Biases: [0mrun 'pip install wandb' to automatically track and visualize YOLOv5 runs in Weights & Biases
[34m[1mClearML: [0mrun 'pip install clearml' to automatically track, visualize and remotely train YOLOv5 runs in ClearML
[34m[1mTensorBoard: [0mStart with 'tensorboard --logdir runs/train', view at http://localhost:6006/
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 67425 models.yolo.Detect [20, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
YOLOv5s summary: 270 layers, 7073569 parameters, 7073569 gradients, 16.1 GFLOPs
Transferred 342/349 items from yolov5s.pt
[34m[1mAMP: [0mchecks passed ✅
[34m[1moptimizer:[0m SGD(lr=0.01) with parameter groups 57 weight(decay=0.0), 60 weight(decay=0.0005), 60 bias
[34m[1malbumentations: [0mBlur(always_apply=False, p=0.01, blur_limit=(3, 7)), MedianBlur(always_apply=False, p=0.01, blur_limit=(3, 7)), ToGray(always_apply=False, p=0.01), CLAHE(always_apply=False, p=0.01, clip_limit=(1, 4.0), tile_grid_size=(8, 8))
[34m[1mtrain: [0mScanning '/content/yolov5/my_dataset/my_train_data' images and labels...5717 found, 0 missing, 0 empty, 0 corrupt: 100% 5717/5717 [00:06<00:00, 831.41it/s]
[34m[1mtrain: [0mNew cache created: /content/yolov5/my_dataset/my_train_data.cache
[34m[1mval: [0mScanning '/content/yolov5/my_dataset/my_val_data' images and labels...5823 found, 0 missing, 0 empty, 0 corrupt: 100% 5823/5823 [00:04<00:00, 1236.37it/s]
[34m[1mval: [0mNew cache created: /content/yolov5/my_dataset/my_val_data.cache
Plotting labels to runs/train/exp2/labels.jpg...
[34m[1mAutoAnchor: [0m4.04 anchors/target, 1.000 Best Possible Recall (BPR). Current anchors are a good fit to dataset ✅
Image sizes 640 train, 640 val
Using 2 dataloader workers
Logging results to [1mruns/train/exp2[0m
Starting training for 3 epochs...
Epoch gpu_mem box obj cls labels img_size
0/2 3.72G 0.07408 0.03976 0.05901 33 640: 100% 358/358 [03:02<00:00, 1.96it/s]
Class Images Labels P R [email protected] [email protected]:.95: 100% 182/182 [01:03<00:00, 2.86it/s]
all 5823 15787 0.495 0.461 0.431 0.207
Epoch gpu_mem box obj cls labels img_size
1/2 6.26G 0.05159 0.03403 0.03152 37 640: 100% 358/358 [02:50<00:00, 2.10it/s]
Class Images Labels P R [email protected] [email protected]:.95: 100% 182/182 [01:01<00:00, 2.98it/s]
all 5823 15787 0.637 0.597 0.625 0.336
Epoch gpu_mem box obj cls labels img_size
2/2 6.26G 0.04695 0.03366 0.02354 44 640: 100% 358/358 [02:50<00:00, 2.10it/s]
Class Images Labels P R [email protected] [email protected]:.95: 100% 182/182 [00:59<00:00, 3.07it/s]
all 5823 15787 0.716 0.633 0.69 0.409
3 epochs completed in 0.198 hours.
Optimizer stripped from runs/train/exp2/weights/last.pt, 14.5MB
Optimizer stripped from runs/train/exp2/weights/best.pt, 14.5MB
Validating runs/train/exp2/weights/best.pt...
Fusing layers...
YOLOv5s summary: 213 layers, 7064065 parameters, 0 gradients, 15.9 GFLOPs
Class Images Labels P R [email protected] [email protected]:.95: 100% 182/182 [01:04<00:00, 2.81it/s]
all 5823 15787 0.715 0.634 0.69 0.409
aeroplane 5823 484 0.769 0.652 0.727 0.364
bicycle 5823 380 0.714 0.708 0.732 0.442
bird 5823 629 0.728 0.596 0.662 0.366
boat 5823 491 0.493 0.483 0.451 0.211
bottle 5823 733 0.554 0.574 0.563 0.317
bus 5823 320 0.793 0.722 0.773 0.557
car 5823 1173 0.696 0.72 0.773 0.453
cat 5823 618 0.788 0.759 0.801 0.499
chair 5823 1449 0.666 0.549 0.618 0.373
cow 5823 347 0.696 0.585 0.672 0.408
diningtable 5823 374 0.801 0.476 0.584 0.278
dog 5823 773 0.826 0.597 0.761 0.501
horse 5823 373 0.783 0.705 0.783 0.502
motorbike 5823 376 0.704 0.737 0.759 0.443
person 5823 5110 0.761 0.803 0.837 0.519
pottedplant 5823 542 0.459 0.506 0.467 0.231
sheep 5823 485 0.72 0.636 0.695 0.423
sofa 5823 387 0.721 0.475 0.608 0.352
train 5823 329 0.879 0.748 0.823 0.509
tvmonitor 5823 414 0.742 0.652 0.712 0.431
Results saved to [1mruns/train/exp2[0m
4.3.2 voc2coco数据转换脚本trans_voc2yolo.py、calculate_dataset.py和pascal_voc_classes.json
下面给的都是yolov3_spp原版的转换脚本。要是按我上面用yolov5运行,跟上面说的一样改路径就行。
pascal_voc_classes.json:
{
"aeroplane": 1,
"bicycle": 2,
"bird": 3,
"boat": 4,
"bottle": 5,
"bus": 6,
"car": 7,
"cat": 8,
"chair": 9,
"cow": 10,
"diningtable": 11,
"dog": 12,
"horse": 13,
"motorbike": 14,
"person": 15,
"pottedplant": 16,
"sheep": 17,
"sofa": 18,
"train": 19,
"tvmonitor": 20
}
trans_voc2yolo.py原版脚本:
"""
本脚本有两个功能:
1.将voc数据集标注信息(.xml)转为yolo标注格式(.txt),并将图像文件复制到相应文件夹
2.根据json标签文件,生成对应names标签(my_data_label.names)
"""
import os
from tqdm import tqdm
from lxml import etree
import json
import shutil
# voc数据集根目录以及版本
voc_root = "/data/VOCdevkit"
voc_version = "VOC2012"
# 转换的训练集以及验证集对应txt文件
train_txt = "train.txt"
val_txt = "val.txt"
# 转换后的文件保存目录
save_file_root = "./my_yolo_dataset"
# label标签对应json文件
label_json_path = './data/pascal_voc_classes.json'
# 拼接出voc的images目录,xml目录,txt目录
voc_images_path = os.path.join(voc_root, voc_version, "JPEGImages")
voc_xml_path = os.path.join(voc_root, voc_version, "Annotations")
train_txt_path = os.path.join(voc_root, voc_version, "ImageSets", "Main", train_txt)
val_txt_path = os.path.join(voc_root, voc_version, "ImageSets", "Main", val_txt)
# 检查文件/文件夹都是否存在
assert os.path.exists(voc_images_path), "VOC images path not exist..."
assert os.path.exists(voc_xml_path), "VOC xml path not exist..."
assert os.path.exists(train_txt_path), "VOC train txt file not exist..."
assert os.path.exists(val_txt_path), "VOC val txt file not exist..."
assert os.path.exists(label_json_path), "label_json_path does not exist..."
if os.path.exists(save_file_root) is False:
os.makedirs(save_file_root)
def parse_xml_to_dict(xml):
"""
将xml文件解析成字典形式,参考tensorflow的recursive_parse_xml_to_dict
Args:
xml: xml tree obtained by parsing XML file contents using lxml.etree
Returns:
Python dictionary holding XML contents.
"""
if len(xml) == 0: # 遍历到底层,直接返回tag对应的信息
return {xml.tag: xml.text}
result = {}
for child in xml:
child_result = parse_xml_to_dict(child) # 递归遍历标签信息
if child.tag != 'object':
result[child.tag] = child_result[child.tag]
else:
if child.tag not in result: # 因为object可能有多个,所以需要放入列表里
result[child.tag] = []
result[child.tag].append(child_result[child.tag])
return {xml.tag: result}
def translate_info(file_names: list, save_root: str, class_dict: dict, train_val='train'):
"""
将对应xml文件信息转为yolo中使用的txt文件信息
:param file_names:
:param save_root:
:param class_dict:
:param train_val:
:return:
"""
save_txt_path = os.path.join(save_root, train_val, "labels")
if os.path.exists(save_txt_path) is False:
os.makedirs(save_txt_path)
save_images_path = os.path.join(save_root, train_val, "images")
if os.path.exists(save_images_path) is False:
os.makedirs(save_images_path)
for file in tqdm(file_names, desc="translate {} file...".format(train_val)):
# 检查下图像文件是否存在
img_path = os.path.join(voc_images_path, file + ".jpg")
assert os.path.exists(img_path), "file:{} not exist...".format(img_path)
# 检查xml文件是否存在
xml_path = os.path.join(voc_xml_path, file + ".xml")
assert os.path.exists(xml_path), "file:{} not exist...".format(xml_path)
# read xml
with open(xml_path) as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = parse_xml_to_dict(xml)["annotation"]
img_height = int(data["size"]["height"])
img_width = int(data["size"]["width"])
# write object info into txt
assert "object" in data.keys(), "file: '{}' lack of object key.".format(xml_path)
if len(data["object"]) == 0:
# 如果xml文件中没有目标就直接忽略该样本
print("Warning: in '{}' xml, there are no objects.".format(xml_path))
continue
with open(os.path.join(save_txt_path, file + ".txt"), "w") as f:
for index, obj in enumerate(data["object"]):
# 获取每个object的box信息
xmin = float(obj["bndbox"]["xmin"])
xmax = float(obj["bndbox"]["xmax"])
ymin = float(obj["bndbox"]["ymin"])
ymax = float(obj["bndbox"]["ymax"])
class_name = obj["name"]
class_index = class_dict[class_name] - 1 # 目标id从0开始
# 进一步检查数据,有的标注信息中可能有w或h为0的情况,这样的数据会导致计算回归loss为nan
if xmax <= xmin or ymax <= ymin:
print("Warning: in '{}' xml, there are some bbox w/h <=0".format(xml_path))
continue
# 将box信息转换到yolo格式
xcenter = xmin + (xmax - xmin) / 2
ycenter = ymin + (ymax - ymin) / 2
w = xmax - xmin
h = ymax - ymin
# 绝对坐标转相对坐标,保存6位小数
xcenter = round(xcenter / img_width, 6)
ycenter = round(ycenter / img_height, 6)
w = round(w / img_width, 6)
h = round(h / img_height, 6)
info = [str(i) for i in [class_index, xcenter, ycenter, w, h]]
if index == 0:
f.write(" ".join(info))
else:
f.write("\n" + " ".join(info))
# copy image into save_images_path
path_copy_to = os.path.join(save_images_path, img_path.split(os.sep)[-1])
if os.path.exists(path_copy_to) is False:
shutil.copyfile(img_path, path_copy_to)
def create_class_names(class_dict: dict):
keys = class_dict.keys()
with open("./data/my_data_label.names", "w") as w:
for index, k in enumerate(keys):
if index + 1 == len(keys):
w.write(k)
else:
w.write(k + "\n")
def main():
# read class_indict
json_file = open(label_json_path, 'r')
class_dict = json.load(json_file)
# 读取train.txt中的所有行信息,删除空行
with open(train_txt_path, "r") as r:
train_file_names = [i for i in r.read().splitlines() if len(i.strip()) > 0]
# voc信息转yolo,并将图像文件复制到相应文件夹
translate_info(train_file_names, save_file_root, class_dict, "train")
# 读取val.txt中的所有行信息,删除空行
with open(val_txt_path, "r") as r:
val_file_names = [i for i in r.read().splitlines() if len(i.strip()) > 0]
# voc信息转yolo,并将图像文件复制到相应文件夹
translate_info(val_file_names, save_file_root, class_dict, "val")
# 创建my_data_label.names文件
create_class_names(class_dict)
if __name__ == "__main__":
main()
calculate_dataset.py原版脚本:
"""
该脚本有3个功能:
1.统计训练集和验证集的数据并生成相应.txt文件
2.创建data.data文件,记录classes个数, train以及val数据集文件(.txt)路径和label.names文件路径
3.根据yolov3-spp.cfg创建my_yolov3.cfg文件修改其中的predictor filters以及yolo classes参数(这两个参数是根据类别数改变的)
"""
import os
train_annotation_dir = "./my_yolo_dataset/train/labels"
val_annotation_dir = "./my_yolo_dataset/val/labels"
classes_label = "./data/my_data_label.names"
cfg_path = "./cfg/yolov3-spp.cfg"
assert os.path.exists(train_annotation_dir), "train_annotation_dir not exist!"
assert os.path.exists(val_annotation_dir), "val_annotation_dir not exist!"
assert os.path.exists(classes_label), "classes_label not exist!"
assert os.path.exists(cfg_path), "cfg_path not exist!"
def calculate_data_txt(txt_path, dataset_dir):
# create my_data.txt file that record image list
with open(txt_path, "w") as w:
for file_name in os.listdir(dataset_dir):
if file_name == "classes.txt":
continue
img_path = os.path.join(dataset_dir.replace("labels", "images"),
file_name.split(".")[0]) + ".jpg"
line = img_path + "\n"
assert os.path.exists(img_path), "file:{} not exist!".format(img_path)
w.write(line)
def create_data_data(create_data_path, label_path, train_path, val_path, classes_info):
# create my_data.data file that record classes, train, valid and names info.
# shutil.copyfile(label_path, "./data/my_data_label.names")
with open(create_data_path, "w") as w:
w.write("classes={}".format(len(classes_info)) + "\n") # 记录类别个数
w.write("train={}".format(train_path) + "\n") # 记录训练集对应txt文件路径
w.write("valid={}".format(val_path) + "\n") # 记录验证集对应txt文件路径
w.write("names=data/my_data_label.names" + "\n") # 记录label.names文件路径
def change_and_create_cfg_file(classes_info, save_cfg_path="./cfg/my_yolov3.cfg"):
# create my_yolov3.cfg file changed predictor filters and yolo classes param.
# this operation only deal with yolov3-spp.cfg
filters_lines = [636, 722, 809]
classes_lines = [643, 729, 816]
cfg_lines = open(cfg_path, "r").readlines()
for i in filters_lines:
assert "filters" in cfg_lines[i-1], "filters param is not in line:{}".format(i-1)
output_num = (5 + len(classes_info)) * 3
cfg_lines[i-1] = "filters={}\n".format(output_num)
for i in classes_lines:
assert "classes" in cfg_lines[i-1], "classes param is not in line:{}".format(i-1)
cfg_lines[i-1] = "classes={}\n".format(len(classes_info))
with open(save_cfg_path, "w") as w:
w.writelines(cfg_lines)
def main():
# 统计训练集和验证集的数据并生成相应txt文件
train_txt_path = "data/my_train_data.txt"
val_txt_path = "data/my_val_data.txt"
calculate_data_txt(train_txt_path, train_annotation_dir)
calculate_data_txt(val_txt_path, val_annotation_dir)
classes_info = [line.strip() for line in open(classes_label, "r").readlines() if len(line.strip()) > 0]
# 创建data.data文件,记录classes个数, train以及val数据集文件(.txt)路径和label.names文件路径
create_data_data("./data/my_data.data", classes_label, train_txt_path, val_txt_path, classes_info)
# 根据yolov3-spp.cfg创建my_yolov3.cfg文件修改其中的predictor filters以及yolo classes参数(这两个参数是根据类别数改变的)
change_and_create_cfg_file(classes_info)
if __name__ == '__main__':
main()