skip-gram word2vec代码实现
2013年,《Distributed Representations of Words and Phrases and their Compositionality》提出训练词向量模型Word2vec的方法,即CBOW和Skip-gram。CBOW是根据上下文词预测中心词,Skip-gram是根据中心词预测周围词。相对来说Skip-gram训练出的Word2vec模型较好,可以参考word2vec中cbow 与 skip-gram的比较。
1. Skip-gram
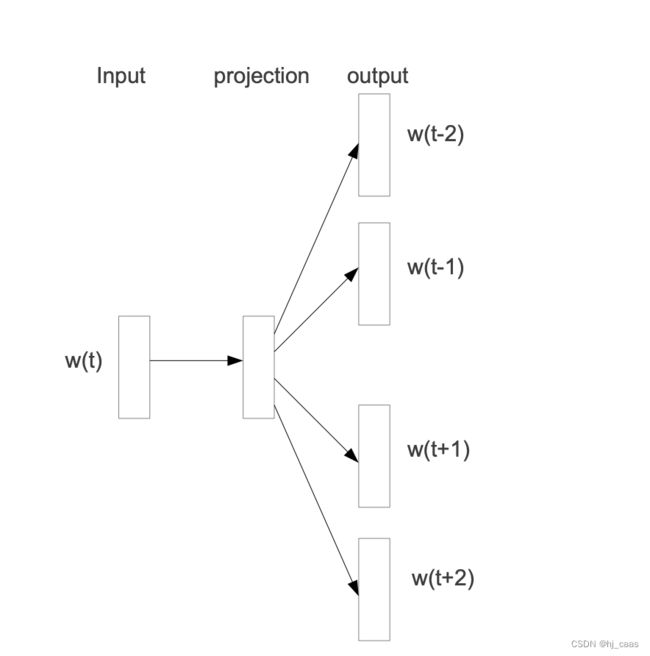
Skip-gram方法利用神经网络模型,分成输入层,隐层,输出层,在隐层没有使用激活函数,只有线性函数,模型结构如图所示,具体代码实现如下所示。
2. 代码实现
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
#skip-gram word2vec
class Word2Vec(nn.Module):
def __init__(self,vocab_size,embedding_size):
super(Word2Vec, self).__init__()
self.W = nn.Linear(vocab_size, embedding_size, bias=False) # vocab_size:词表大小,embedding_size:维度大小
self.WT = nn.Linear(embedding_size, vocab_size, bias=False)
def forward(self, X):
# X : [batch_size, voc_size]
hidden_layer = self.W(X) # 隐层 : [batch_size, embedding_size] 线性层
output_layer = self.WT(hidden_layer) # 输出层 : [batch_size, voc_size] 输出层
return output_layer
#随机选择训练数据
def random_batch(skip_grams, batch_size, vocab_size):
random_inputs = []
random_labels = []
random_index = np.random.choice(range(len(skip_grams)), batch_size, replace=False)
for i in random_index:
random_inputs.append(np.eye(vocab_size)[skip_grams[i][0]]) # target
random_labels.append(skip_grams[i][1])
return random_inputs, random_labels
#生成skip-gram
def skip_grams_fun(sentences,word_dict):
skip_grams = []
word_sequence = " ".join(sentences).split()
for i in range(1, len(word_sequence) - 1):
target = word_dict[word_sequence[i]]
context = [word_dict[word_sequence[i - 1]], word_dict[word_sequence[i + 1]]]
for w in context:
skip_grams.append([target, w])
return skip_grams
if __name__ == '__main__':
batch_size = 2 #批量大小
embedding_size = 2 #向量维度大小
#文本
sentences = ["apple banana fruit", "banana orange fruit", "orange banana fruit",
"dog cat animal", "cat monkey animal", "monkey dog animal"]
word_sequence = " ".join(sentences).split()
word_list = " ".join(sentences).split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)} #词典
vocab_size = len(word_list) #词典大小
skip_grams = []
skip_grams1 = skip_grams_fun(sentences[:3],word_dict)
skip_grams2 = skip_grams_fun(sentences[3:],word_dict)
skip_grams.extend(skip_grams1)
skip_grams.extend(skip_grams2)
model = Word2Vec(vocab_size,embedding_size)
criterion = nn.CrossEntropyLoss() #交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=0.001) #优化器
for epoch in range(10000):
input_batch, target_batch = random_batch(skip_grams, batch_size, vocab_size)
input_batch = torch.Tensor(input_batch) #类型转换
target_batch = torch.LongTensor(target_batch)
optimizer.zero_grad()
output = model(input_batch) # 输出 : [batch_size, voc_size]
loss = criterion(output, target_batch)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()
for i, label in enumerate(word_list):
W, WT = model.parameters()
x, y = W[0][i].item(), W[1][i].item()
plt.scatter(x, y)
plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.show()
