ICCV2021 还在用大量数据暴力train模型?主动学习,教你选出数据集中最有价值的样本...
关注公众号,发现CV技术之美
0
写在前面
主动学习(Active learning)旨在通过只在数据集上选择信息最丰富的样本来降低标记成本。现有的工作很少涉及到目标检测的主动学习。目前仅有的一些目标检测主动学习方法大多基于多个模型或是分类方法的直接扩展,因此只使用分类头来估计图像的信息量。
本文提出了一种新的目标检测的深度主动学习方法,依赖于混合密度网络,估计每个定位头和分类头输出的概率分布。作者明确地估计了单个模型的单一正向传递中的偶然(aleatoric)不确定性 和认知(epistemic)不确定性 。
本文的方法使用一个评分函数,聚合两个head的这两种类型的不确定性,以获得每个图像的信息性得分。作者在PSCAL VOC和MSCOCO数据集上证明了本文方法的有效性。
1
论文和代码地址

Active Learning for Deep Object Detection via Probabilistic Modeling
论文地址:https://arxiv.org/abs/2103.16130
代码地址:未开源
2
Motivation
深度检测网络的性能取决于标记数据的大小。在此基础上,研究人员探索策略,选择数据集中信息最丰富的样本进行标记,称为主动学习。通常,这是通过设计一个计算网络不确定性的评分函数来实现的。
一般来说,预测不确定性被分解为偶然和认知不确定性。前者是指数据中固有的噪声(如传感器噪声),或者遮挡、缺乏视觉特征造成的信息缺失 (也就是数据本身的不确定性)。后者是指由于缺乏模型知识而引起的不确定性 (也就是由于模型没有学好产生的不确定性),与训练数据的密度成反比。
建模和区分这两种类型的不确定性在主动学习中非常重要,因为它允许深度学习模型了解它们的局限性,即识别样本中的可疑预测(偶然不确定性),并识别不类似于训练集的样本(认知不确定性)。目前仅有的一些目标检测主动学习方法大多基于多个模型或是分类方法的直接扩展,因此只使用分类头来估计图像的信息量。
本文提出了一种新的用于目标检测的主动学习方法。作者的方法使用单个模型和单次正向传递,与基于多个模型的方法相比,显著降低了计算成本。尽管如此,作者的方法还是达到了很高的精度。为了做到这一点,作者充分利用了定位和分类的偶然和认知不确定性。

如上图所示,本文的方法是一个混合密度网络,该网络学习每个head输出的高斯混合模型(GMM)来计算偶然和认知不确定性。为了有效地训练网络,作者提出了一个损失函数,作为不一致数据的正则化器,从而生成更鲁棒的模型。
本文的方法通过聚合图像中包含的每个对象的所有定位和分类的不确定性来估计每个图像的信息量得分。作者通过实验表明,利用来自分类和定位中的两种不确定性是提高准确性的关键因素。
本文的方法优于基于单模型的方法,并且与使用多模型的方法相比,本文的方法依旧产生了相似的精度,同时显著降低了计算成本。
3
方法
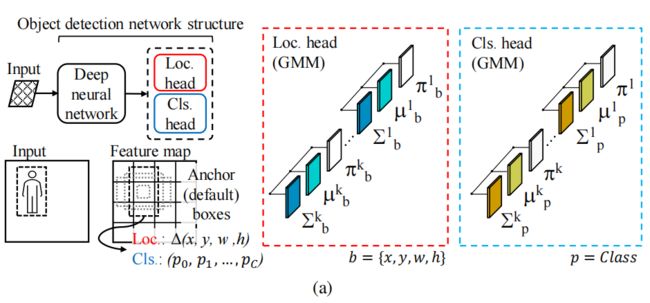
如上图所示,本文的方法的关键新颖之处在于设计神经网络的输出层来预测概率分布,而不是预测网络的每个输出的单个值。
为此,作者提出使用一个混合密度网络,其中网络的输出由一组GMM的参数组成:平均的µ、方差和GMM的第k个分量的混合权重π。给定这些参数,就可以估计最终的偶然和认知不确定性:
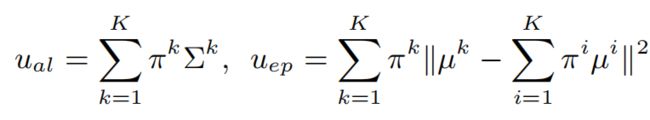
其中,K是GMM中组件的数量。
3.1. Object detection with mixture modeling
Localization
在目标检测中,边界框b由其中心(x和y)的坐标、其宽度(w)和高度(h)来定义。在本文中,作者的混合模型不是预测一个确定性值,而是预测了每个边界框的3组参数:均值,方差,混合权重,如下所示:
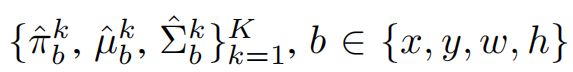
边界框中每个坐标的带有K个模型的GMM的参数如下:

其中,π是每个组件的混合权重,µ是边界框的每个输出的预测值,Σ是每个坐标的方差,表示其偶然不确定性。作者使用softmax函数将π保持在概率空间中,并使用Sigmoid函数来满足方差的正性约束。
Localization loss
传统的边界框回归损失,即smooth L1损失,只考虑了预测的边界框和GT的坐标。因此,它不能考虑边界框的模糊性(偶然不确定性)。为了训练混合密度网络的定位,作者提出了一种基于负对数似然损失的定位损失。
本文的损失使GMM的参数回归到anchor box的中心(x、y)、宽度(w)和高度(h)的偏移量:
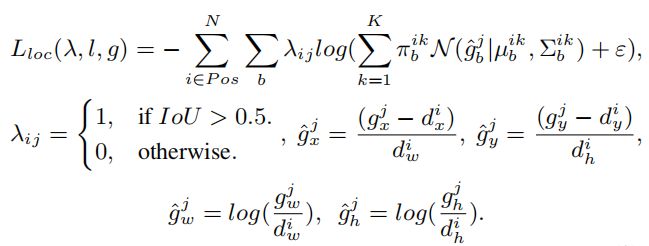
其中l为预测边界框,N为正匹配数,为第j个GT box,λ为第i个anchor与第j个GT box是否匹配的指示函数,在实验中,ε=e−9。
Classification
对于目标检测的分类头,本文的方法估计了每个类的均值µ和方差,以及GMM的每个混合权重π。首先跟上一节一样,先对网络输出的值进行预处理,然后利用高斯噪声和方差对µ,得到第i个bounding box的类概率分布:
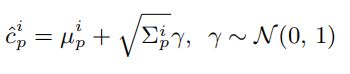
Classification loss
为了训练混合密度网络进行分类,作者提出了一个考虑Anchor Box与GT Box的损失函数,并考虑了 hard negative mining。更准确地说,作者将分类损失表示为和,分别代表代表正样本和负样本的贡献:
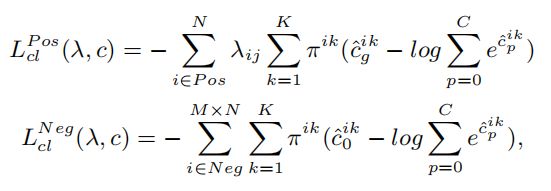
其中C为类数,0表示背景类,N为正匹配数,M为难负例挖掘比例。作者没有使用所有的负匹配,而是混合分类损失对它们进行分类,并选择前M×N个作为最终的负匹配进行训练。
Final loss
作者将使用混合密度网络训练目标检测器的总体损失函数定义为:
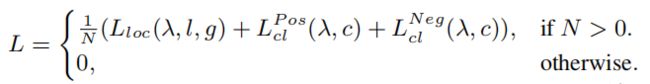
其中,N是正匹配的数量。
在推理时,可以通过将混合模型的K个分量相加,计算每个类的置信分数和边界框的坐标如下:
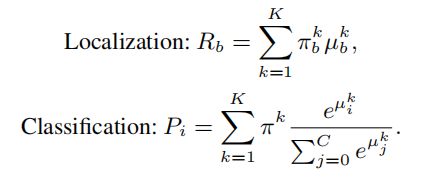
3.2. Improving parameter efficiency
为了预测输出值的概率分布,本文的方法涉及到修改网络的最后一层,从而导致参数数量的增加,特别是在分类头。
更准确地说,对于大小为F×F的输出特征图,使用C类、D个anchor和每个边界框使用4个坐标定义,新层中估计K个具有3个参数的组件的GMM的参数量为:
定位:,分类:。可以看到分类头中的参数数量与类的数量成正比。

因此,作者希望通过减少分类头中参数的数量来提高算法的效率。如上图所示,作者放宽了估计方差的问题,每个类的概率直接通过下面的公式得到:
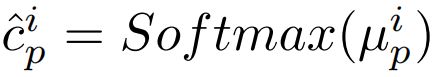
然后只用这个值去估计偶然不确定性:
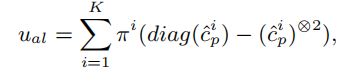

其中是一个对角矩阵。
最后,对提高参数效率的模型训练分类损失进行修改如下:
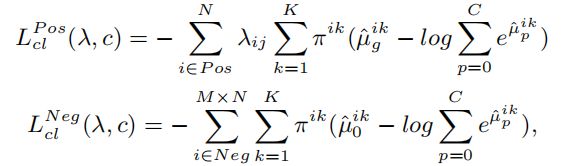
3.3. Scoring function
主动学习中的评分函数为每张图像提供一个值,表示其信息量。本文的评分函数通过聚合图像中每个边界框的每个参数的所有偶然和认知不确定性值来估计图像的信息量。
具体来说,设是一组图像的不确定性值集合(偶然不确定性或认知不确定性),其中是第i幅图像中第j个对象的不确定性。对于定位任务,是4个边界框输出上的最大值。
我们首先使用z-score归一化µσ对这些值进行归一化,以避免边界框坐标的值是无界的以及图像的每个不确定性可能有不同的值域范围等问题。然后,图像中每个检测目标的最大不确定性为整张图片的不确定性。
利用上述算法,我们就获得了每个图像的四种不同的归一化不确定性值:分类和定位的认知不确定性和偶然不确定性。剩下的部分是把这些分数汇总成一个分数。作者发现,采用最大值的方式来聚合这些值效果最好。
4
实验
4.1. Object detection with mixture modeling
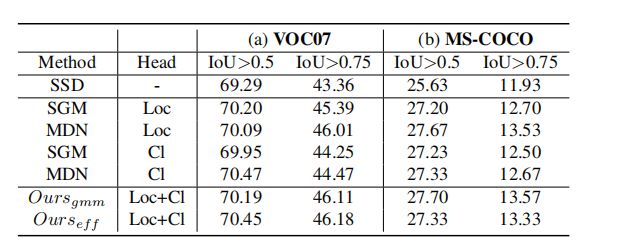
上表分别总结了本文对VOC07和MS-COCO进行的实验结果。所有包含概率建模的网络在两个数据集上都优于SSD。

上图展示了一些对于不准确检测的偶然不确定性和认知不确定性的例子。在这些例子中,即使预测是错误的,不确定性值似乎也不相关,这表明每个不确定性都可以独立预测不准确的结果。
从这些结果中,作者得出了一个结论:本文的方法不仅计算了单个模型的单次正向传递的不确定性,而且提高了检测网络的性能。
4.2. Active learning evaluation
Scoring aggregation function
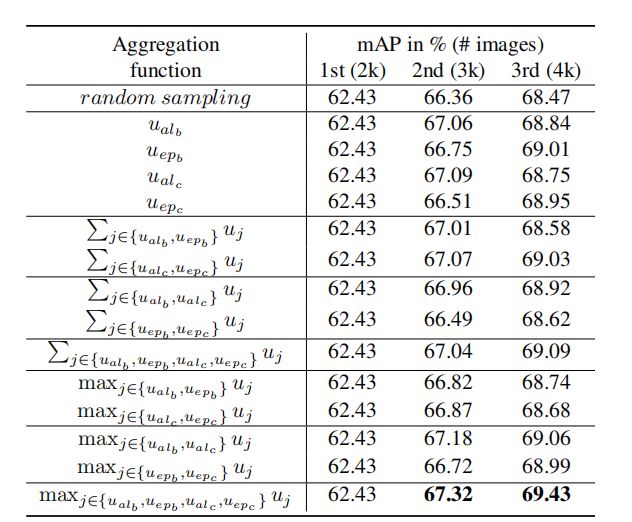
上表比较了平均函数的不同聚合方式,可以看出,求最大值的方式是最好的。
Comparison to SOTA on VOC07
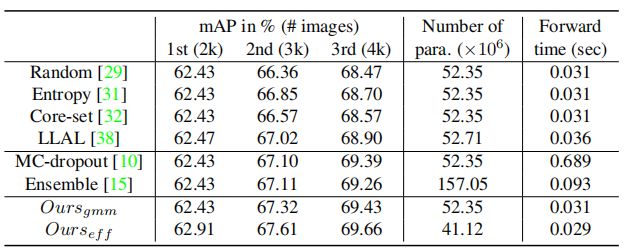
上表总结了本文的主动学习方法的结果和计算成本。这些结果表明,尽管有较低的计算成本,本文提出的方法与以前的工作相比提高了主动学习采样性能。
Comparison to SOTA on VOC07+12

从(a)中可以看出,本文的方法优于所有其他基于单模型的方法。从(b)中可以看出,在准确性而言,本文的方法的性能与集成相当。

本文的方法需要的计算成本明显低于集成的方法。
Comparison to SOTA on MS-COCO
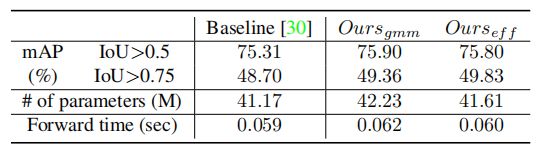
在COCO数据集上 ,上表总结了本文的方法与主动学习方法相比的主动学习性能和计算成本。
4.3. Scalability and dataset transferability
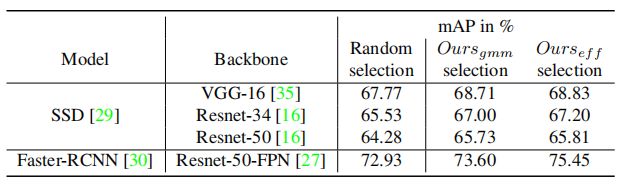
上表展示了本文的评分函数和混合密度模型创建在不同数据集和检测器上的可迁移性。
5
总结
在本文中,作者提出了一种新的目标检测的深度主动学习方法。在单个模型的一次正向传递中,依赖于混合密度网络来估计定位和分类任务的两种不确定性,并在评分函数中对信息量进行评分。
本文的混合建模和评分函数在精度和计算成本方面取得了显著的改进。此外,作者还在不同数据集和不同网络架构上,证明了本文方法的可迁移性。
作者介绍
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV
END,入群备注:目标检测
