全网最全解析ALipy:主动学习的Python工具箱
研途漫漫,关注小曾,入股不亏,小曾与你共勉进步。今天主要分享来自南京航空航天大学计算机科学与技术学院模式分析与机器智能工信部重点实验室所开源的用于主动学习的Python工具库-ALipy
文章目录
- ALipy--Python中的主动学习
-
- ALipy的特点
- ALipy的模块
- ALipy的安装
- ALipy特殊设置
- ALipy实现的算法
- 具体代码实现过程
-
- ALipy 入门
-
- 主动学习实验统一框架
- ALipy中的模块
-
- 管理标记和未标记索引
- 拆分数据
- 使用预定义的策略来选样本
- 更新测试模型
- 高级指南
-
- 高级封装用法
-
- ToolBox--初始化一个对象获取任何工具
- AIExperiment--几行代码运行AL算法示例
- alipy中的工具类
ALipy–Python中的主动学习
ALiPy 提供了一个基于模块的主动学习框架实现,允许用户方便地评估、比较和分析主动学习方法的性能。它实现了 20 多种算法,还支持用户在不同设置下轻松实现自己的方法。
ALipy的特点
- 模型无关:分类模型没有限制。可以根据需要在 sklearn 中使用 SVM 或在 tensorflow 中使用深度模型。
- 模块独立:可以自由修改工具箱的一个或多个模块,而不会影响其他模块。
- 在不继承任何东西的情况下实现自己的算法:用户定义的函数几乎没有限制,例如参数或名称
- 支持的变体设置:嘈杂的预言机、多标签、成本效益、特征查询等
- 强大的工具:中间结果保存和加载;多线程;实验结果分析等
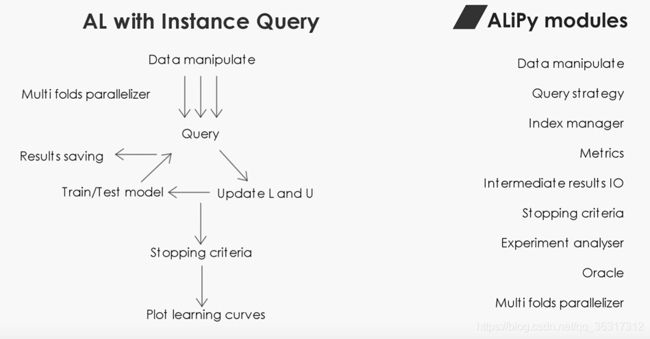
ALipy的模块
将主动学习实现分解为多个组件,开发了基于多个模块的ALipy ,每个模块对应一个主动学习过程的组成部分。

| 模块组件 | 基本功能 |
|---|---|
| alipy.data manipulate | 提供数据预处理和分区的基本功能 |
| alipy.query strategy | 由25种常用的查询策略组成 |
| alipy.index.IndexCollection | 有助于对已标记和未标记示例的索引进行管理 |
| alipy.metric | 提供多个标准来评估模型性能 |
| alipy.experiment.state and alipy.experiment.state io | 有助于在每次查询后保存中间结果,并可以从断点恢复程序 |
| alipy.experiment.stopping criteria | 实现了一些常用的停止条件 |
| alipy.oracle | 支持不同的Oracle设置 |
| alipy.experiment.experiment analyser | 提供了实验结果的采集、处理和可视化功能 |
| alipy.utils.multi thread | 提供了k倍实验的并行实现 |
以上模块都是独立设计实现的。这样,不同部分之间的代码可以不受限制地实现。此外,每个独立的模块都可以由用户自己的实现替换,在每个模块中,我们还提供了高度的灵活性,使工具箱能够适应不同的设置。
实例选择的AL实现框架
Noisy Oracles的AL实现框架

不同成本数据集的AL实现框架

实例查询的AL实现框架

ALipy的安装
alipy 的依赖:Python >=3.4
基本库 numpy scipy scikit-learn matplotlib prettytable
主要有两种安装方案:pip安装 和 源码构建
pip安装(三选一)
- 从 PyPI 安装 alipy(推荐):
sudo pip install alipy
- pip install 在主目录中:
pip install --user alipy
- 从 github 存储库 pip install 获取最新源:
pip install git+https://github.com/NUAA-AL/alipy.git
源码构建
- 将alipy 克隆到本地目录,cd 到 ALiPy 文件夹并运行安装命令:
cd ALiPy
sudo python setup.py install
- 从主目录中的源代码构建和安装:
python setup.py install --user
- Unix/Linux 上的所有用户从源构建和安装:
python setup.py build
ALipy特殊设置
ALipy最显著的特征是低耦合性,很容易在其他特殊环境下进行实验。
| 主动学习设置 | 简介 |
|---|---|
| AL with Noisy Oracles | 有时可能返回错误的标签 |
| AL for Multi-Label Data | 一个实例同时关联多个标签 |
| AL with Different Costs | 查询不同标签的成本可能不同 |
| AL by Querying Features | 选择要查询的实例的缺失功能 |
| AL with Novel Query Types | 查询实例的其他类型信息,而不是查询实例的标签 |
| AL for Large Scale Tasks | 大数据中的主动学习 |
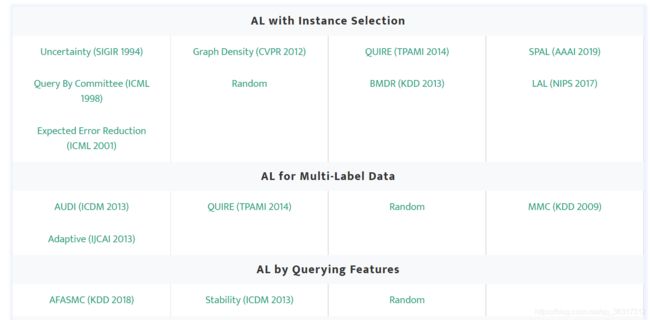
ALipy实现的算法
ALiPy针对不同的主动学习设置提供了20多种高级算法

具体代码实现过程
在代码实现这块主要分为Alipy入门和高级指南
ALipy 入门
将展示一个简单的示例,以使用 alipy 中的工具自定义主动学习实验,先介绍一下主动学习实验的统一框架,接下来介绍alipy中对应的工具。
主动学习实验统一框架

1、例如得到一个具有形状的特征矩阵X [n_samples, n_features] 和对应的具有形状 [n_samples] 【如果不容易得到特定的特征矩阵,可以只对实例的索引进行操作】,将数据拆分为训练/测试集进行实验。数据分区应该随机重复几次。在主动学习中,应该进一步将训练集拆分为初始标记集和未标记池以供查询。请注意,在大多数主动学习设置中,最初标记的集合通常很小。
2、可以开始对每个实验折叠的查询过程并记录其结果。在每次查询迭代中,都会查询一个未标记数据的子集并将其添加到标记集中;之后,模型将根据更新的标签集重新训练并测试以评估查询。
3、所有折叠完成后,可以通过平均每个折叠的性能曲线来获得该查询策略的学习曲线。
ALipy中的模块
-
使用 alipy.query_strategy 调用传统和最先进的方法。
-
使用 alipy.index.IndexCollection 来管理标记索引和未标记索引。
-
使用 alipy.metric 来计算您的模型性能。
-
使用 alipy.experiment.state 和 alipy.experiment.state_io 保存每次查询后的中间结果,并从断点处恢复程序。
-
使用 alipy.experiment.stopping_criteria 来获取一些示例停止标准。
-
使用 alipy.experiment.experiment_analysisr 来收集、处理和可视化您的实验结果。
为有经验的用户提供一个使用 alipy 实现实验的完整示例。然后,我们将单独解释代码,并介绍上述工具中的常用方法。
import copy
from sklearn.datasets import load_iris
from alipy import ToolBox
X, y = load_iris(return_X_y=True)
alibox = ToolBox(X=X, y=y, query_type='AllLabels', saving_path='.')
# 拆分数据
alibox.split_AL(test_ratio=0.3, initial_label_rate=0.1, split_count=10)
# 使用默认的逻辑回归分类器
model = alibox.get_default_model()
# 成本预算是50次查询
stopping_criterion = alibox.get_stopping_criterion('num_of_queries', 50)
# 使用预定义的策略
uncertainStrategy = alibox.get_query_strategy(strategy_name='QueryInstanceUncertainty')
unc_result = []
for round in range(10):
# 获取单折实验的数据拆分
train_idx, test_idx, label_ind, unlab_ind = alibox.get_split(round)
# 获取单折实验的中间结果 saver
saver = alibox.get_stateio(round)
# 设置初始性能点
model.fit(X=X[label_ind.index, :], y=y[label_ind.index])
pred = model.predict(X[test_idx, :])
accuracy = alibox.calc_performance_metric(y_true=y[test_idx],
y_pred=pred,
performance_metric='accuracy_score')
saver.set_initial_point(accuracy)
while not stopping_criterion.is_stop():
# 根据查询策略选择Uind的子集
# 传递与proba_predict方法任何sklearn模型是确定
select_ind = uncertainStrategy.select(label_ind, unlab_ind, model=model, batch_size=1)
# 或传递你的proba 预测结果
# prob_pred = model.predict_proba(x[unlab_ind])
# select_ind = uncertainStrategy.select_by_prediction_mat(unlabel_index=unlab_ind, predict=prob_pred, batch_size=1)
label_ind.update(select_ind)
unlab_ind.difference_update(select_ind)
# 根据您使用的模型更新模型和计算性能模型
model.fit(X=X[label_ind.index, :], y=y[label_ind.index])
pred = model.predict(X[test_idx, :])
accuracy = alibox.calc_performance_metric(y_true=y[test_idx],
y_pred=pred,
performance_metric='accuracy_score')
# 将中间结果保存到文件
st = alibox.State(select_index=select_ind, performance=accuracy)
saver.add_state(st)
saver.save()
# 将当前进度传递给停止标准对象
stopping_criterion.update_information(saver)
# 重置在停止准则对象进度
stopping_criterion.reset()
unc_result.append(copy.deepcopy(saver))
analyser = alibox.get_experiment_analyser(x_axis='num_of_queries')
analyser.add_method(method_name='uncertainty', method_results=unc_result)
print(analyser)
analyser.plot_learning_curves(title='Example of AL', std_area=True)
对于每一个模块,创建一个ToolBox对象并制定实验的查询类型(查询一个实例的所有标签)
form alipy import ToolBOX
#初始化,无需传递冗余参数即可通过 ToolBox 对象获取所有可用工具
alibox = ToolBox(X = X ,y = y ,query_type = 'AllLabels')
管理标记和未标记索引
alipy.index.IndexCollection 是一个类似列表的容器,用于管理您的标记和未标记索引。可以通过传递 list 或 numpy.ndarray 对象轻松创建 IndexCollection 对象。
a = [1,2,3]
a_ind = alibox.IndexCollection(a)
# Or create by importing the module
from alipy.index import IndexCollection
a_ind = IndexCollection(a)
IndexCollection 常用的方法有:
-
a_ind.index 用于获取矩阵索引的索引列表类型。
-
a_ind.update() 用于向 IndexCollection 对象添加一批索引。
-
a_ind.difference_update() 用于从 IndexCollection 对象中删除一批索引
拆分数据
按工具箱对象拆分数据有两种方法。
- 您可以 alibox.split_AL() 通过指定一些选项来分割数据:
alibox.split_AL(test_ratio=0.3, initial_label_rate=0.1, split_count=10)
上面的代码将数据集随机拆分为训练、测试、标记、未标记集 10 次 - 可以使用自己的split函数,在初始化ToolBox对象时设置train_idx、test_idx、label_idx、unlabel_idx的索引
train_idx, test_idx, label_idx, unlabel_idx = my_own_split_fun(X, y)
alibox = alipy.ToolBox(X=X, y=y, query_type='AllLabels', train_idx=train_idx, test_idx=test_idx, label_idx=label_idx, unlabel_idx=unlabel_idx)
使用预定义的策略来选样本
主动学习的核心算法之一可能是查询策略。
可以通过只提供策略名称从 alipy.ToolBox 对象中获取查询策略对象:
uncertainStrategy = alibox.get_query_strategy(strategy_name='QueryInstanceUncertainty')
使用 alipy.IndexCollection 来管理您的索引,标记的索引容器是 Lind ,未标记的容器是Uind 预定义策略的示例用法可能是这样的(提供列表类型即可):
select_ind = uncertainStrategy.select(label_index=Lind,
unlabel_index=Uind,
batch_size=1)
更新测试模型
可用功能'accuracy_score' 、 'roc_auc_score' 、 'get_fps_tps_thresholds' 、 'hamming_loss' 、 'one_error' 、 'coverage_error' 、 'label_ranking_loss' 、 'label_ranking_average_precision_score'
有两种方法可以使用它们:
- 导入 模块并调用工具函数: alipy.metrics
from alipy.metric import accuracy_score
acc = accuracy_score(y_true=y, y_pred=model.predict(X))
- calc_performance_metric() ToolBox 对象的使用 方法:
acc = alibox.calc_performance_metric(y_true=y, y_pred=model.predict(X),
performance_metric='accuracy_score')
高级指南
高级封装用法
ToolBox–初始化一个对象获取任何工具
ToolBox之前也提到过,是一个提供所有可用工具类的类。可以在不通过 ToolBox 对象传递冗余参数的情况下获取它们。
1、初始化ToolBox对象
#可用的查询类型有 ['AllLabels', 'PartLabels', 'Features'] ,查询一个实例所有标签
from sklearn.datasets import load_iris
from alipy import ToolBox
X, y = load_iris(return_X_y=True)
alibox = ToolBox(X=X, y=y, query_type='AllLabels', saving_path='.')
2、获取默认模型
ALiPy 提供了具有默认参数的 Logistic 回归模型,该模型由 sklearn 实现
lr_model = alipy.get_default_model()
#训练测试模型
lr_model.fit(X, y)
pred = lr_model.predict(X)
# get probabilistic output
pred = lr_model.predict_proba(X)
3、拆分数据
#通过用alibox.split_AL() 指定一些选项来分割数据:
alibox.split_AL(test_ratio=0.3, initial_label_rate=0.1, split_count=10)
4、创建 IndexCollection 对象
#alipy.index.IndexCollection 是 alipy 中用于索引管理的工具类。
a = [1,2,3]
a_ind = alibox.IndexCollection(a)
5、获取 Oracle 和 Repository 对象
Toolbox 类提供了 clean oracle 的 初始化
#如果需要通过特征向量进行查询,可以通过设置 query_by_example=True 来实现这个目标
clean_oracle = alibox.get_clean_oracle(query_by_example=False, cost_mat=None)
#获取作为 保存查询信息的工具的 存储库 ,您可以调用 get_repository(round, instance_flag=False)
alibox.get_repository(round=0, instance_flag=False)
6、获取 State & StateIO 对象
#alipy.experiment.StateIO object 是一个用于保存和加载中间结果的类
saver = alibox.get_stateio(round=1)
#在StateIO对象中添加查询时,需要使用一个State对象,它是一个类似dict的容器来保存一个查询的一些必要信息(当前迭代的状态),例如成本、性能、选定的索引等。
st = alibox.State(select_index=select_ind, performance=accuracy,
cost=cost, queried_label=queried_label)
7、获取预定义的 QueryStrategy 对象
之前也提到过,就简单的介绍一下
QBCStrategy = alibox 。get_query_strategy ( strategy_name = 'QueryInstanceQBC' )
8、计算性能
#使用 calc_performance_metric() ToolBox 对象方法的例子 :
acc = alibox.calc_performance_metric(y_true=y, y_pred=model.predict(X),
performance_metric='accuracy_score')
9、获取停止条件对象
alipy 实现了一些常用的停止标准:
- 没有可用的未标记样本(默认)
- 达到预设查询次数
- 达到预设的成本限制
- 未标记池的预设百分比已标记
- 达到预设运行时间(CPU时间)
# [None, 'num_of_queries', 'cost_limit', 'percent_of_unlabel', 'time_limit'] 五选一
stopping_criterion = alibox.get_stopping_criterion(stopping_criteria='num_of_queries', value=50)
10、获取实验分析器
#使用alipy.experiment.Analyser 工具类
analyser = alibox.get_experiment_analyser(x_axis='num_of_queries')
11、获取 aceThreading 对象
#alipy.utils.aceThreading 是一个类来并行你的 k-fold 实验并打印每个线程的状态。
acethread = alibox.get_ace_threading ()
12、保存和加载 ToolBox 对象
#保存
alibox.save()
#加载
alibox = ToolBox.load('./al_settings.pkl')
AIExperiment–几行代码运行AL算法示例
ALipy 提供了一个类,封装了各种工具,直接实现主动学习的主循环【alipy.experient.Alneatent】
备注:AlExament只支持最常用的场景–查询一个实例的所有标签。
代码实现
# 初始化 & 函数 模型参数是分类模型对象,满足 scikit-learn API
from sklearn.datasets import load_iris
from alipy.experiment.al_experiment import AlExperiment
X, y = load_iris(return_X_y=True)
al = AlExperiment(X, y, stopping_criteria='num_of_queries', stopping_value=50)
#使用内置函数生成新的拆分
al.split_AL()
#已经实现经典和先进的查询策略,将名称传递set_query_Strategy()函数即可
#可用策略名称列表包括['QueryInstanceQBC', 'QueryInstanceUncertainty', 'QueryRandom', 'QureyExpectedErrorReduction', 'QueryInstanceGraphDensity', 'QueryInstanceQUIRE', 'QueryInstanceBMDR', 'QueryInstanceSPAL', 'QueryInstanceLAL']
# 注意,GraphDensity和Quire方法需要额外的参数
al.set_query_strategy(strategy="QueryInstanceUncertainty", measure='least_confident')
#设置性能指标,ALiPy已经实现了许多经典的性能度量标准,使用set_performance_metric函数即可
#['accuracy_score', 'roc_auc_score', 'get_fps_tps_thresholds', 'hamming_loss','one_error', 'coverage_error', 'label_ranking_loss', 'label_ranking_average_precision_score', 'zero_one_loss']
al.set_performance_metric('accuracy_score')
#开始实验 ,默认k次主动学习在多线程中运行
al.start_query(multi_thread=True)
#得到实验结果
#可以通过al.get_Example_Result().获取k次实验的k个StateIO对象列表的结果,也可以通过al.lot_Learning_curve(title=None)绘制k次实验的学习曲线
al.plot_learning_curve()

alipy中的工具类
对于某一个模块不太会或者有疑问的同学,可以直接访问这个地址:http://parnec.nuaa.edu.cn/_upload/tpl/02/db/731/template731/pages/huangsj/alipy/advanced_guideline.html
会对每个模块具体使用方法进行详细介绍与解析


如果觉得这篇文章对你有帮助的话,希望能够点个关注,评论、收藏,谢谢
还请关注小曾,入股不亏,我会把我研究生学习过程中的点点滴滴记录下来,大家一起共勉!
论文已经上传:https://download.csdn.net/download/qq_36317312/19698302
GitHub链接:https://github.com/NUAA-AL/alipy
ALipy网站链接:http://parnec.nuaa.edu.cn/_upload/tpl/02/db/731/template731/pages/huangsj/alipy/index.html
在整理期间也看了因吉的文章,也收获不小,感兴趣可以看一下https://blog.csdn.net/weixin_44575152/article/details/100783835