ICLR2022系列解读之二:基于自适应邻居发现的人脸聚类的方法 Ada-NETS
本文解读我们ICLR2022上发表的论文《Ada-NETS:Face Clustering via Adaptive Neighbour Discovery in the Structure Space》。本文介绍了在结构空间中基于自适应邻居发现的人脸聚类的方法,该工作已被 ICLR2022 接收。
论文地址:Ada-NETS: Face Clustering via Adaptive Neighbour Discovery in the Structure Space
开源代码:https://github.com/Thomas-wyh/Ada-NETS
一、背景
互联网上存在大量以人脸为主的图片,有需求将这些图片按照 ID 关联到一起,目的是为了方便理解和管理这些人脸图片。在解决这个需求过程中,抽象出了一个基本的任务:就是人脸聚类。
谈到人脸聚类,首先看一下聚类的含义。给定一个特征集合 V={v1,v2,⋯,vi,⋯,vN|vi∈RD} ,聚类任务给每一个特征向量 vi 赋予一个分组标签。需要特别说明的是:这里任务的输入是已经抽取好的特征向量。除了满足以上特征,人脸聚类任务往往具有数据量大,精度要求高等特点。
当前处理人脸聚类的方法大致分为两种:传统聚类方法和 GCN-based 的聚类方法。传统聚类方法大都对数据的分布有假设要求(比如:k-means 要求数据分布是凸的等),而现实世界的数据分布都是复杂的,往往不能完全满足这些假设,所以这些方法很可能得到 suboptimal 的结果;而且人脸聚类一般都是大规模聚类,迭代式的更新的聚类方法,在时效上也难以满足要求。近几年来GCN-based 人脸聚类逐渐兴起,并且每年都在取得 SOTA 的效果。GCN-based 的方法大致过程是这样的:首先给每个节点寻找 topK 近邻,认为存在topK近邻关系的节点之间存在一条边,通过这样的方法来构建出 graph,然后通过图卷积方法对节点特征进行增强,在 head 的部分使用点分类或者边分类的方法判断节点间是否有边连接,然后通过传递归并的方法将可以相互达到节点分为一组,从而得到最终的聚类结果。本文介绍的方法归属于第二类。
1. 问题与难点
1.1 问题
当前 GCN-based 的人脸聚类方法中都面临着一个很大的问题,就是当前使用的 graph 上充斥着噪声边。所谓噪声边就是一条边连接两个不同类别的节点。如下图(b)所示:灰色的边是正确的边,它连接两个相同的节点,而红色的边连接两个不同类别的节点,属于噪声边。当前主流方法在构图上,通过在节点的特征空间中进行搜索来选择topK 近邻,给有topK近邻关系的节点间构造一条边。但是在现实世界中,特征表示并不总是可靠,使用特征搜索得到的topK近邻当中存在着各种False Positive,即 一个节点与probe 节点并非同一类但是却属于probe节点的topK近邻。那么在基于这个 k NN构造图的时候,噪声边就会随之而来。噪声边的问题是普遍存在的,它的占比不容忽视:之前的方法所使用的图中,存在38.23%的噪声边。因此这些方法不能直接使用GCN的结果,还要借助density-based 连接或亲密度判定等后处理的方法。如下图(b)所示,v1 节点连接着5条边,其中3条是红色的噪声边2条是灰色的正确边。试想在GCN的信息传递过程中, v1 节点的特征就会被非同类节点的特征所污染,从而噪声最后特征表达效果的下降。因此,噪声边的影响也是不容忽视的。但是,当前在人脸聚类领域的研究中,还没有专门处理噪声边的研究。

1.2 难点
上一小节已经明确了噪声边的问题,但是进一步分析发现,这个问题并不好解决。处理它存在两大难点:(1)如下图(c)所示:现实世界中的节点特征表达能力总是有限的,仅仅依靠节点的特征,很难准确判定两个节点间是否应该连接边。(2)如下图(d)所示:确定到底给每个节点连接多少条边这件事也是很困难的。如果每个节点连接的边太少,那么在GCN阶段就不能进行充分的特征传播。如果每个节点连接的边太多,那么肯定会带来过多的噪声边。虽然诸如 Clusformer[1] 、GAT[2]等方法通过 attention mechanism 来降低噪声边的权重,但是现实世界中节点间的边分布是很复杂的,很难基于节点间的特征来找一个可靠的模式。

为了解决第一个难点,判断两个节点间是否连边的试试,每个节点附近的节点也被考虑了进来,因为他们可以提供更多的信息。而对于第二个难点,每个节点到底需要连接多少条边,这个结果也可以从该节点周围的特征分布模式中提取出来,而不是使用一个手工设计的“一刀切”式的全局参数。基于这些方法,本文提出了 Adaptive Neighbour discovEry in the strucTure Space (Ada-NETS) 来处理 GCN-based 方法中的人脸聚类问题。在 Ada-NETS 中,首先将每个节点从特征空间映射到结构空间中,在结构空间中,每个节点感知到了它周围节点间的关系,从而编码了更多的信息而有更好的特征表示。其次,Ada-NETS 中还提出了一个 候选邻居质量评估准则( candidate neighbours quality criterion ),它可以直接评估一个节点的候选邻居质量,然后一个自适应过滤器可以在这个准则的指导下直接学习出哪一个候选邻居才是好的邻居。通过这样的方法,可以构造出一个又干净又丰富的graph,然后GCN-based 的人脸聚类在这张图上完成。
二、方法
首先,如下图(I),这些待聚类的节点各自寻找自己的 k NN,然后通过一个 ϕ 函数将节点映射到结构空间中,在结构空间中节点间的距离分布将会更加合理。然后如下图(II),基于候选邻居质量评估标准给每个节点选取出最好的候选邻居,并通过自适应过滤器来学习这个模式。如下图(III)中,在得到节点间的边关系后就可以构造一张大图,经过GCN 进行在图上进行特征传播,在训练阶段使用 一个修改版的 hingle loss,将同类节点拉近不同类节点拉远,在推理阶段可以直接获得基于 GCN增强后的节点特征,然后使用一个距离阈值就可以将这些节点划分为不同的簇,从而完成聚类的任务。
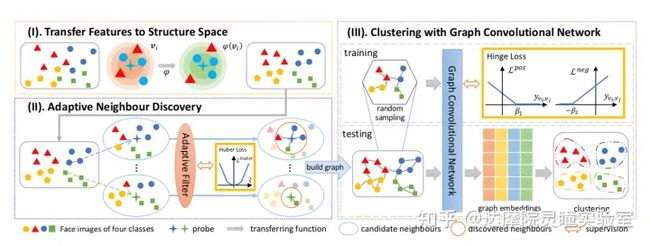
1、结构空间
几乎之前的所有方法在构造边的时候,都只使用两个节点间基于深度特征的相似度特征。但是他们忽略了聚类本身是一个离线任务,在聚类的时候,所有的样本都是可以使用的。节点间的相似度可以通过考虑结构信息而进一步增强,这里的结构信息就是节点间邻居关系。如下公式所示:
vis=φ(vi|V),∀i∈{1,2,⋯,N}.
在给定整个数据集的条件下,节点 vi 通过一个 ϕ 函数映射到结构空间,得到节点 vis 。但是ϕ函数并不好求解,于是在核函数思想的启发下,本文通过通过定义的方式可以直接得到结构空间中,两个节点间的相似度,如下公式所示:
LHinge=Lneg+λLpos,where Lpos=1‖li=lj‖∑li=lj[β1−yvi,vj]+, Lneg=maxli≠lj[β2+yvi,vj]+,
本文将结构空间中的两个节点间相似度定义为 η 余弦相似度和 1−η 的杰卡德相似度之和。其中杰卡德相似度的算法,本文借鉴了 zhong 等人[3]的 common-neighbour-based metric 的计算方法。杰卡德相似度通过计算公共邻居的方式,从而捕获到了节点分布的结构信息,从而增强了节点间相似度表达。
2、自适应近邻发现
几乎之前所有的方法给每个节点选择要连接的邻居节点时,都是通过一个手工设定的超参( k NN)或者一个相似度阈值。显然这种一刀切的方法会陷入过多过少都有问题的两难中。
Ada-NETS 提出了自适应邻居发现模块来解决这个难点。这个模块包含两部分:一个是候选邻居质量判定准则,一个是自适应过滤器。首先,介绍一下候选邻居质量判定准则。一个好的邻居集合,应该是这样的:邻居集合中的大部分节点与中心节点属于同一类,即要足够干净 clean;同时,还要求这个邻居集合要尽可能全面,包含各种类型的邻居,即要足够丰富 rich。借鉴信息检索中的思想,cleaness 对应着检索中的precision,richness 对应检索中的 recall。既干净又丰富,对应着precision 和 recall 的一个balance。因此借鉴 Fβ−score 的形式本文定义了质量准则:
Q(j)=Fβj=(1+β2)PrjRcjβ2Prj+Rcj
Q(j) 是截止到第 j 个邻居为止的邻居集合的质量。 Q 值越大,邻居质量越高。
如下图所示,对于一个节点vi ,将它的邻居按照相似度从大到小进行排列,然后依次计算截止到各个为止上的 Q 值,得到一条 Q曲线,选取 Q 曲线的峰值位置为 koff 。自适应过滤器的输入是候选邻居集合的特征矩阵,学习目标就是峰值的位置(如图中最优位置是 koff=3 ,它就是要学习的目标)。这里为了更好的捕获序列特征,自适应过滤器采用一个 bi-LSTM 实现。目标函数使用了 Huber Loss。在推理阶段,峰值之前的节点全部保留作为邻居,分值之后的节点全部移除,由此得到预测的候选邻居集合。

3、聚类过程
在使用了结构空间与自适应邻居发现之后,可以定义发现的邻居关系为:
Ns(vi,k)={vij|vij∈N(vi,k),Indj≤k^off}
其中Indj代表节点 vij 的在使用 κ(vi,vij) 相似度从大到小排序后的位次。基于这个集合关系,可以构建一个 干净且丰富的graph,图的邻接矩阵表示如下:
Aij={1,vi∈Ns(vj,k) or vj∈Ns(vi,k),0,otherwise.
然后在这个精心构造的图上,采用图卷积的方式进行信息传播。在训练阶段,使用一个修正版的hingle loss,将同类节点拉近,不同类节点拉远。
LHinge=Lneg+λLpos,where Lpos=1‖li=lj‖∑li=lj[β1−yvi,vj]+, Lneg=maxli≠lj[β2+yvi,vj]+,
在测试阶段直接获取GCN增强后的特征,然后使用一个阈值进行分组,完成聚类的任务。
三、实验分析
1、效果实验
本文首先在 MS-Celeb-1M 上进行实验验证。将 MS-Celeb-1M 切分为10份(part0~part9),选取其中一份进行训练,另外几份进行测试。分别使用 Pairwise F-score FP 和 Bcubed F-score FB 进行评测。
从下表可以看出,从第一列 584K 评测集上,Ada-NETS相对于之前的 SOTA有明显提升( FP 从91.97提升到92.79, FB 从90.21提升到91.40)。当随着评测集规模增大,聚类任务变得更难,虽然 Ada-NETS 的指标呈现下降趋势,但是和之前的SOTA 方法相比,在数据规模维度上依然保持优势。

另外,Ada-NETS 还有其它对象聚类的潜能,本文分别在 服饰聚类(DeepFashion数据集)和人员聚类(ReID领域最大的数据集 MSMT17)上进行验证,结果如表2中,可以看出从不同的聚类对象的维度评价,Ada-NETS 依然保持其优势。

2、消融实验
2.1 结构空间与自适应邻居发现模块的分析
表3中的SNR列代表信噪比,信噪比越高,图越清洁。可以看出 结构空间和自适应邻居都没有引入的时候, SNR=1.62 ,对应的聚类指标 FP 只能到 77.17;加上结构空间后, SNR=2.37 ,对应的聚类指标 FP 可以提升到 81.49;而只加上自适应邻居发现模块后, SNR=13.85 ,对应的聚类指标 FP 到达89.29。当两个模块都加上后, SNR=21.67 ,对应的聚类指标也可以达到92.79。从表3中可以看出, SNR 越高,聚类指标越高。两个模块对比,自适应邻居发现模块贡献更大,而结构空间的引入,可以进一步释放自适应邻居发现模块的效果。
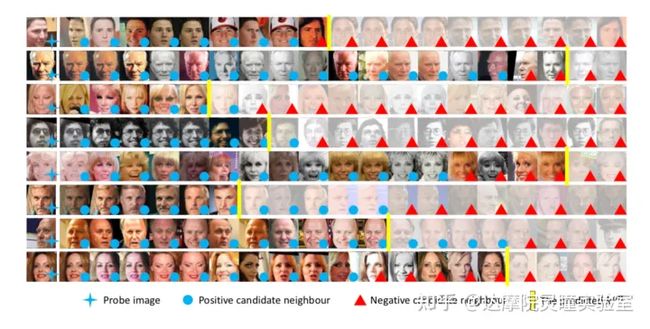
下图展示自适应过滤器的效果。每一行代表一个节点及其搜索到的候选邻居。最左边一列是probe节点,后面是其候选邻居。右下角有蓝色圆圈的表示与probe是同一个类别,右下角有红色三角代表和probe节点不同类别。黄色的竖线代表自适应过滤器的输出。在构建graph的时候,黄色竖线之后的候选邻居会被移除。从下图可以看出,在使用候选邻居质量准则指导的自适应过滤器的情况下,可以得到一个相对合理的输出。
2.2 候选邻居质量评估准则的分析
在候选邻居质量评估准则中,一个超参数 β ,本文经验性选择 ,,β∈{0.5,1.0,2.0} 分别在特征空间和结构空间进行分析。从表4中可以看出:
- 在每一行,无论是在特征空间还是在结构空间,在使用了 自适应邻居发现之后, Qafter相对于Qbefore 都有较为明显的提升。并且,在结构空间中的提升更为明显;
- 从 聚类效果可以看出, Q 越高聚类指标越好 (第一行与第四行,第二行与第五行,第三行与第六行 对比);
- 可以看出 β=0.5 的时候有一个综合最优的效果。
需要说明的是,这个模块中,为了减少自适应滤波器在拟合 koff 上的误差干扰结论分析,表4中构图时候使用的 koff 均为ground truth 的结果。
2.2.1 多种自适应过滤器的设计分析
表5是自适应过滤器的不同设计及其效果。首先, EseqQ 方法直接拟合 Q 曲线上每一个点的值,然后在预测到的序列中选取最优的候选邻居。这个方法要拟合的目标太多,因此又提出了 EparamQ 方法,它首先使用一个二次曲线拟合 Q 曲线,然后再去拟合二次曲线的三个参数,从而降低拟合目标个数。 EclsK 则将求解 koff 的视为一个分类问题, EregK 就是采用回归的方式拟合 koff 。另外,这里也和 GNN 领域经典的GAT 网络做了对比,GAT的attention 模块类似于一种过滤器。从表5中可以看出, EclsK 和 EregK 的方法可以取得最好的效果,其中 EregK 更为简单,而 EclsK 方法还需要调优温度,因此本文选择了 EregK 的方法。

2.3 候选邻居个数 K 的敏感度分析
如下图(a)所示,本文分别对比了在不同候选邻居个数下 k NN构图方法,结构域中的 k NN构图,使用相似度阈值的构图方法,使用相似度链的构图方法以及使用 Ada-NETS 的构图方法在不同候选邻居超参 K 下的效果表现。图(a)中可以看出:
- 红色曲线随着候选邻居个数增大,聚类效果相对稳定。而其它各种构图方法,对于候选邻居的选择非常敏感;
- 还可以看出,最优的指标由红色曲线的Ada-NETS 方法取得,因为它对于邻居个数的选择是 instance-wise 的,其它方法无论怎样调整 K 值,因为都是 dataset-level 的一刀切,因此不能得到最优效果。

2.4 特征质量分析
在 GCN-based 聚类中,GCN 用于产出更好的节点特征用于聚类。好的构图可以产出更好的特征,从而有更好聚类效果。本文随机选取10亿对样本,做出他们在不同方法下ROC曲线如上图(b),可以看出图中蓝线是原始特征的ROC曲线,绿色的曲线是使用了GCN 进行特征增强的,橙色的曲线使用了自适应邻居发现模块,而最上面红色的曲线是同时使用了 自适应邻居发现模块和结构域。可以看出Ada-NETS的方法可以产出最好的特征。图 (c) 是选取部分节点特征分布的可视化。可以定性地看出,使用了 Ada-NETS 之后,特征的分布在变得更加合理与紧凑,利于阈值划分聚类。另外,有了更好的特征,本文还进一步使用 Ada-NETS 的方法获取更好的特征效果。图表10所示,在第一轮 Ada-NETS的基础上,使用更好的特征作为输入,还可以进一步提升聚类的效果,在 584K的评测集上, FP 可以从 92.79进一步提升到93.74。

四、结论
本文提出了一种新颖的GCN-based人脸聚类方法——Ada-NETS——来处理建立图时候的噪声边的问题。在Ada-NETS中,首先将特征转换为结构空间,以提高相似性度量的准确性。然后采用自适应邻域过滤的方法,在启发式候选邻居质量准则的指导下,自适应地寻找所有样本的邻居集合。基于发现的邻居关系,构建了一个干净且丰富的图作为GCN的输入,在人脸、衣服和人员聚类任务上取得了当前SOTA的效果。
Reference
[1] Nguyen X B, Bui D T, Duong C N, et al. Clusformer: A transformer based clustering approach to unsupervised large-scale face and visual landmark recognition[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 10847-10856.
[2] Velikovi P , Cucurull G , Casanova A , et al. Graph Attention Networks[J]. 2017.
[3] Zhong Z, Zheng L, Cao D, et al. Re-ranking person re-identification with k-reciprocal encoding[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1318-1327.